Convex Hybrid Modeling: An Operator-Based Approach
Pith reviewed 2026-05-25 04:05 UTC · model grok-4.3
The pith
Hybrid models become convex kernel mixtures of interpretable components when re-parameterized via lifted operators on a chosen manifold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By lifting models to canonical operator features on an interpretable manifold, the hybrid learning task reduces to a convex kernel-based mixture of interpretable models whose mixture weights retain physical interpretability.
What carries the argument
Operator-theoretic re-parameterization in lifted (canonical) parameters that expresses the model as a kernel mixture of interpretable components.
If this is right
- Regularization around a reference model yields convex problems that stay close to a physically meaningful baseline.
- Restriction to an interpretable subspace produces convex problems whose solutions remain inside the chosen linear family.
- The lifted manifold formulation converts otherwise non-convex nonlinear constraints into a convex kernel mixture.
- Both static regression and dynamic system identification become tractable under the same convex framework.
Where Pith is reading between the lines
- The kernel-mixture view may allow reuse of existing kernel-learning solvers for hybrid tasks.
- If the lifted features admit a finite basis, the method reduces to ordinary convex regression over an expanded but still interpretable dictionary.
- The same lifting could be tested on control-relevant manifolds such as those defined by conservation laws or steady-state relations.
Load-bearing premise
An interpretable manifold can always be selected so that its lifted operator features keep the overall learning problem convex while preserving physical meaning in the mixture weights.
What would settle it
A concrete counter-example in which any chosen interpretable manifold produces either a non-convex program or mixture weights that lose their physical interpretation.
Figures





read the original abstract
While machine learning can accurately model process systems, models for decision making should also be structurally simple and physically interpretable. In process control, for example, (nearly) linear models are favored than nonlinear ones, promoting the use of operator theory, which ``universally'' represents a nonlinear system by a nonparametric operator. On the other hand, interpretability requires by a ``non-universal'', parametric nonlinear model family satisfying first principles; these constraints tend to complicate the learning procedure. This paper considers hybrid modeling by formulating convex learning problems that account for interpretability systematically and give surrogate models efficiently. Three settings are discussed -- (i) regularization around a particular ``reference model'', (ii) restriction on an ``interpretable subspace'', and more generally, (iii) restriction on a ``interpretable manifold'' that is nonlinearly parameterized. In the more general setting, by introducing an operator-theoretic technique to re-parameterize models in the ``lifted'' parameters (``canonical features'', potentially infinite-dimensional), the system is regarded as a kernel-based mixture of interpretable models. Application to both static and dynamic models are exemplified in numerical studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop three convex formulations for hybrid modeling that systematically incorporate interpretability constraints: (i) regularization around a reference model, (ii) restriction to an interpretable subspace, and (iii) restriction to an interpretable manifold via an operator-theoretic re-parameterization in lifted canonical features (potentially infinite-dimensional). The third setting recasts the model as a kernel-based mixture of interpretable models while preserving convexity by construction. The approach is illustrated on both static and dynamic models through numerical studies.
Significance. If the operator lift indeed delivers convexity without circularity or loss of physical meaning in the mixture weights, the work could provide a principled bridge between nonparametric operator representations and parametric first-principles models, enabling more reliable surrogate models for process control and decision-making where structural simplicity is required.
minor comments (3)
- The abstract states that the lifted parameterization yields a convex problem and retains physical interpretability, but the manuscript should include an explicit low-dimensional example (e.g., a simple nonlinear static map) showing the operator identities and the resulting convex program to make the construction verifiable.
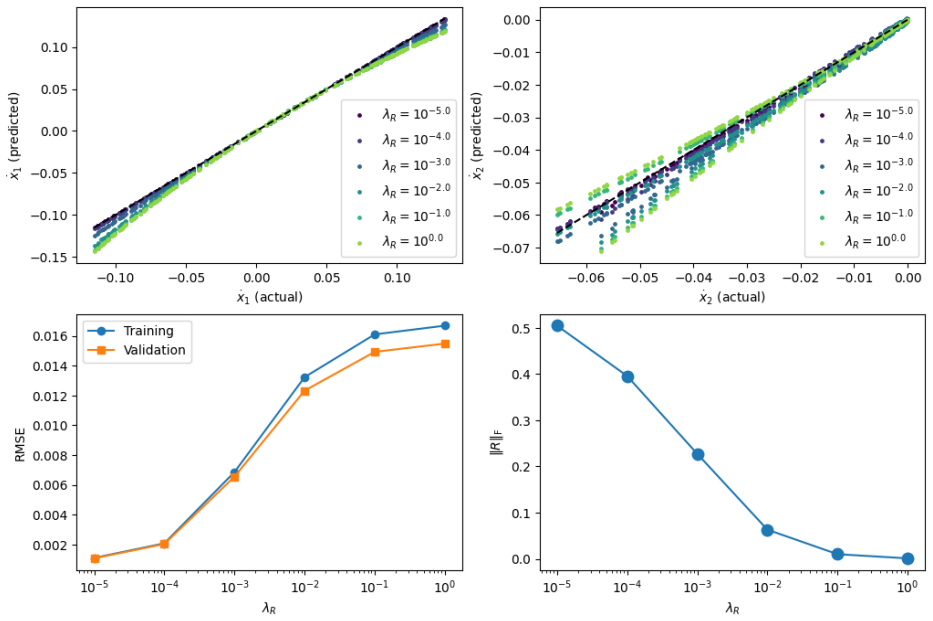
- Numerical studies section: the reported results should include quantitative metrics (e.g., prediction error, constraint violation, solve time) comparing the three convex settings against each other and against a standard non-convex baseline to substantiate the claimed efficiency and interpretability gains.
- The manuscript should clarify the precise sense in which the mixture weights retain 'physical meaning' after the kernel lift, perhaps by relating them back to the original parameters in one of the numerical examples.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript, the recognition of its potential significance in bridging nonparametric operator representations with interpretable parametric models, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The abstract describes a coherent program of three convex formulations (reference regularization, subspace restriction, manifold restriction) achieved via operator-theoretic re-parameterization into lifted canonical features that recasts the model as a kernel-based mixture. No equations, self-citations, or fitted predictions are shown that reduce any claimed prediction or first-principles result to its own inputs by construction. The method is presented as delivering convexity and interpretability by design through the lift, with no load-bearing step that collapses to a self-definitional fit or self-citation chain. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hybridmodelingintheeraofsmartman- ufacturing,
S.Yang,P.Navarathna,S.Ghosh,andB.W.Bequette,“Hybridmodelingintheeraofsmartman- ufacturing,”Comput.Chem.Eng.,vol.140,p.106874,2020
work page 2020
-
[2]
Hybridaimodelsinchem- icalengineering–apurpose-drivenperspective,
A.Chakraborty,S.Serneels,H.Claussen,andV.Venkatasubramanian,“Hybridaimodelsinchem- icalengineering–apurpose-drivenperspective,”Comput.Aid.Chem.Eng.,vol.51,pp.1507–1512, 2022
work page 2022
-
[3]
Accelerating process control and optimization via machine learning: Areview,
I. Mitrai and P. Daoutidis, “Accelerating process control and optimization via machine learning: Areview,”Rev.Chem.Eng.,vol.41,no.4,pp.401–418,2025
work page 2025
-
[4]
A hybrid neural network-first principles approach to process modeling,
D. C. Psichogios and L. H. Ungar, “A hybrid neural network-first principles approach to process modeling,”AIChEJ.,vol.38,no.10,pp.1499–1511,1992
work page 1992
-
[5]
Integrating neural networks with first principlesmodelsfordynamicmodeling,
H.-T. Su, N. Bhat, P. A. Minderman, and T. J. McAvoy, “Integrating neural networks with first principlesmodelsfordynamicmodeling,”inDynamicsandcontrolofchemicalreactors,distillation columnsandbatchprocesses,pp.327–332,Elsevier,1993
work page 1993
-
[6]
Perspectivesontheintegrationbetweenfirst-principlesanddata-drivenmodeling,
W. Bradley, J. Kim, Z. Kilwein, L. Blakely, M. Eydenberg, J. Jalvin, C. Laird, and F. Boukou- vala,“Perspectivesontheintegrationbetweenfirst-principlesanddata-drivenmodeling,”Comput. Chem.Eng.,vol.166,p.107898,2022
work page 2022
-
[7]
P. Shah, S. Pahari, R. Bhavsar, and J. S.-I. Kwon, “Hybrid modeling of first-principles and ma- chinelearning: Astep-by-steptutorialreviewforpracticalimplementation,”Comput.Chem.Eng., vol.194,p.108926,2025
work page 2025
-
[8]
Koopmanoperatordynamicalmodels: Learning, anal- ysisandcontrol,
P.Bevanda, S.Sosnowski, andS.Hirche, “Koopmanoperatordynamicalmodels: Learning, anal- ysisandcontrol,”Ann.Rev.Control,vol.52,pp.197–212,2021
work page 2021
-
[9]
Learningdynamicalsys- tems via Koopman operator regression in reproducing kernel Hilbert spaces,
V.Kostic,P.Novelli,A.Maurer,C.Ciliberto,L.Rosasco,andM.Pontil,“Learningdynamicalsys- tems via Koopman operator regression in reproducing kernel Hilbert spaces,”Adv. Neur. Inform. Process.Syst.,vol.35,pp.4017–4031,2022
work page 2022
-
[10]
Koopmanoperatorsinrobotlearning,
L.Shi,M.Haseli,G.Mamakoukas,D.Bruder,I.Abraham,T.Murphey,J.Cortés,andK.Karydis, “Koopmanoperatorsinrobotlearning,”IEEETrans.Robot.,vol.42,pp.1088–1107,2026
work page 2026
-
[11]
Koopmanoperatorforstabilityanalysis: Theorywithalinear–radialproduct reproducingkernel,
W.TangandX.Ye,“Koopmanoperatorforstabilityanalysis: Theorywithalinear–radialproduct reproducingkernel,”in8thLearn.Dyn.ControlConf.(L4DC),2026. accepted,arXiv:2511.06063
-
[12]
Koopman-basedestimationofLyapunovfunctions: Theoryonareproducing kernelHilbertspace,
W.TangandX.Ye,“Koopman-basedestimationofLyapunovfunctions: Theoryonareproducing kernelHilbertspace,”in45thChin.ControlConf.(CCC),2026. accepted,arXiv:2603.01403
-
[14]
Neural tangent kernel: Convergence and generalization in neuralnetworks,
A. Jacot, F. Gabriel, and C. Hongler, “Neural tangent kernel: Convergence and generalization in neuralnetworks,”Adv.Neur.Inform.Process.Syst.,vol.31,2018
work page 2018
-
[15]
Understanding neural networks with re- producingkernelBanachspaces,
F. Bartolucci, E. De Vito, L. Rosasco, and S. Vigogna, “Understanding neural networks with re- producingkernelBanachspaces,”Appl.Comput.Harmon.Anal.,vol.62,pp.194–236,2023
work page 2023
-
[16]
Accelerating optimization over the space of probability measures,
S. Chen, Q. Li, O. Tse, and S. J. Wright, “Accelerating optimization over the space of probability measures,”J.Mach.Learn.Res.,vol.26,no.31,pp.1–40,2025. 18
work page 2025
-
[17]
On the mathematical foundations of learning,
F. Cucker and S. Smale, “On the mathematical foundations of learning,”Bull. Am. Math. Soc., vol.39,no.1,pp.1–49,2002
work page 2002
-
[18]
F. Cucker and D. X. Zhou,Learning theory: an approximation theory viewpoint. Cambridge Uni- versityPress,2007
work page 2007
- [19]
-
[20]
J.R.ElliottandC.T.Lira,Introductorychemicalengineeringthermodynamics. Pearson,2012
work page 2012
-
[21]
H.Wendland,Scattereddataapproximation. CambridgeUniversityPress,2004
work page 2004
-
[22]
Kernel mean embedding of distributions: Areviewandbeyond,
K. Muandet, K. Fukumizu, B. Sriperumbudur, and B. Schölkopf, “Kernel mean embedding of distributions: Areviewandbeyond,”Found.Trend.Mach.Learn.,vol.10,no.1-2,pp.1–141,2017
work page 2017
-
[23]
EDMD-basedrobustobserversynthesisfornonlinearsystems,
X.YeandW.Tang,“EDMD-basedrobustobserversynthesisfornonlinearsystems,”in65thIEEE Conf.Decis.Control(CDC),IEEE,2026. submitted,arXiv:2509.09812
-
[24]
Resolvent-type data-driven learning of generators for unknowncontinuous-timedynamicalsystems,
Y. Meng, R. Zhou, M. Ornik, and J. Liu, “Resolvent-type data-driven learning of generators for unknowncontinuous-timedynamicalsystems,”IEEETrans.Autom.Control,2026. inpress
work page 2026
-
[25]
CambridgeUniversity Press,2021
C.KravarisandI.K.Kookos,Understandingprocessdynamicsandcontrol. CambridgeUniversity Press,2021
work page 2021
-
[26]
Auniversalformulaforstabilizationwithboundedcontrols,
Y.LinandE.D.Sontag,“Auniversalformulaforstabilizationwithboundedcontrols,”Syst.Control Lett.,vol.16,no.6,pp.393–397,1991
work page 1991
-
[27]
Partition-basedformulationsformixed-integer optimizationoftrainedReLUneuralnetworks,
C.Tsay,J.Kronqvist,A.Thebelt,andR.Misener,“Partition-basedformulationsformixed-integer optimizationoftrainedReLUneuralnetworks,”Adv.Neur.Inform.Process.Syst.,vol.34,pp.3068– 3080,2021
work page 2021
-
[28]
OMLT: Opti- mization&machinelearningtoolkit,
F. Ceccon, J. Jalving, J. Haddad, A. Thebelt, C. Tsay, C. D. Laird, and R. Misener, “OMLT: Opti- mization&machinelearningtoolkit,”J.Mach.Learn.Res.,vol.23,no.349,pp.1–8,2022
work page 2022
-
[29]
Formulating data-driven surrogate models for process optimization,
R. Misener and L. Biegler, “Formulating data-driven surrogate models for process optimization,” Comput.Chem.Eng.,vol.179,p.108411,2023
work page 2023
-
[30]
Deeplearningforuniversallinearembeddingsofnonlin- eardynamics,
B.Lusch,J.N.Kutz,andS.L.Brunton,“Deeplearningforuniversallinearembeddingsofnonlin- eardynamics,”NatureCommun.,vol.9,no.1,p.4950,2018. 19
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.