FlowDPG: Deterministic Policy Gradient on Flow Matching Policies for Real-World Manipulation
Pith reviewed 2026-06-26 10:48 UTC · model grok-4.3
The pith
FlowDPG enables deterministic policy gradient on flow matching policies by distilling critic gradients into the velocity field at training time, bypassing backpropagation through the ODE.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
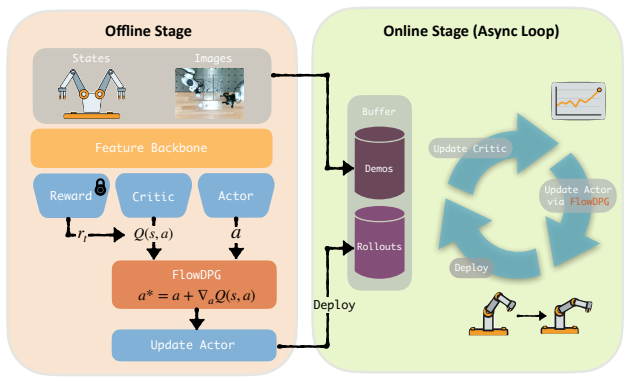
FlowDPG is a DDPG-style algorithm for flow matching policies that distills the critic gradient directly into the velocity field at training time, combining a demonstration-driven velocity that preserves feasibility with a critic-driven correction that improves value; this yields a BPTT-free update whose direction approximates vanilla deterministic policy gradient under three stated approximations and produces a 92 percent success rate on a long-horizon dual-arm AirPods assembly task.
What carries the argument
The BPTT-free distillation framework that injects the critic gradient into the flow velocity field during training, producing a combined vector of demonstration-driven velocity and critic-driven correction.
If this is right
- Flow matching policies become compatible with standard deterministic policy gradient updates without numerical fragility from ODE backpropagation.
- The method supports direct use of critic signals to refine demonstration-initialized flows on long-horizon real-world tasks.
- The three-approximation link shows that the distilled update direction remains close to the true deterministic policy gradient.
- The approach outperforms value-conditioning, auxiliary adaptation, and adjoint-based critic methods on the reported dual-arm assembly benchmark.
Where Pith is reading between the lines
- The same distillation idea could be tested on other continuous normalizing flow or diffusion policies that currently rely on expensive trajectory derivatives.
- Because the correction is added only at training time, the final deployed policy remains a pure flow model that can be executed in a single forward pass.
- The reliance on demonstration data for the base velocity suggests the method may generalize best in settings where a modest amount of expert data is already available.
Load-bearing premise
Distilling the critic gradient into the velocity field produces stable policy improvement that is equivalent to vanilla deterministic policy gradient under the three approximations, without needing full backpropagation through the ODE.
What would settle it
A controlled comparison in which FlowDPG produces no policy improvement or lower success rates than methods that perform full BPTT on the same flow matching policy and task would falsify the central claim.
Figures


read the original abstract
Real-world reinforcement learning for robotic manipulation remains challenging, and this difficulty is amplified for flow matching policies: applying policy gradient methods to these policies is fundamentally limited by the need to backpropagate through time(BPTT) along the multi-step ODE that maps noise to actions, which is computationally prohibitive and numerically fragile. We propose FlowDPG, a DDPG-style method specifically designed for flow matching policies that distills the critic gradient into the velocity field at training time, bypassing BPTT entirely. Intuitively, FlowDPG combines two complementary vectors: the demonstration-driven velocity that keeps the action feasible, and the critic-driven correction that steers it toward higher value. Our contributions are threefold: (1) a BPTT-free distillation framework that enables stable DDPG-style policy improvement on flow matching policies, (2) a formal connection between the FlowDPG update direction and vanilla Deterministic Policy Gradient via three explicit approximations, and (3) real-world validation on a long-horizon, multi-stage, dual-arm AirPods assembly task, where FlowDPG attains a 92% end-to-end success rate, substantially outperforming recent RL methods spanning value-conditioning, auxiliary-module adaptation, and adjoint-based critic-gradient approaches. Videos and more results are provided on the project page https://flowdpg.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FlowDPG, a DDPG-style algorithm for flow-matching policies that distills the critic gradient into the velocity field during training, thereby avoiding backpropagation through the multi-step ODE. It claims a formal equivalence to vanilla deterministic policy gradient under three explicit approximations, and reports a 92% end-to-end success rate on a long-horizon dual-arm AirPods assembly task that substantially exceeds recent value-conditioning, auxiliary-adaptation, and adjoint-based baselines.
Significance. If the three approximations can be shown to hold with quantifiable error bounds and the empirical gains are reproduced with standard controls, the method would provide a practical route to stable critic-driven improvement for flow-based policies on real hardware without the numerical fragility of BPTT. The real-world dual-arm result on a multi-stage task would then constitute a meaningful data point for the community.
major comments (3)
- [formal connection / contribution (2)] The formal connection to vanilla DPG is stated to rest on three explicit approximations, yet the manuscript supplies neither the precise statements of these approximations nor any quantitative assessment of their validity on long-horizon, high-dimensional trajectories; without this, the claim that the distilled update direction is equivalent (and therefore inherits DPG’s convergence properties) cannot be evaluated.
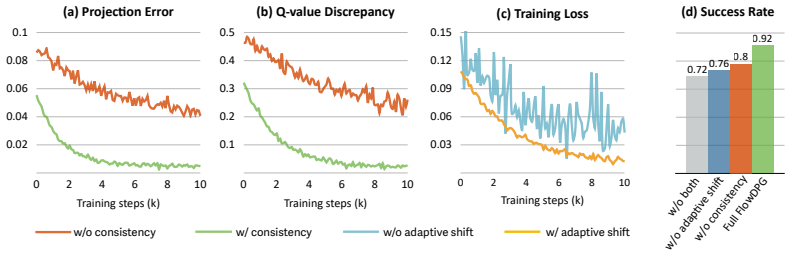
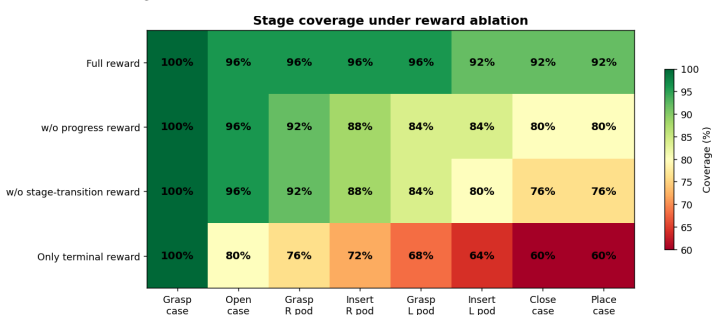
- [real-world experiments] The experimental section reports a 92% success rate but provides no error bars across seeds, no ablation isolating the critic-distillation term from the demonstration-driven velocity, and no verification that the three approximations remain accurate across the multi-stage horizon; these omissions make it impossible to attribute the performance gain to the proposed mechanism rather than to the base flow-matching policy.
- [method / training procedure] The claim that FlowDPG bypasses BPTT while remaining stable is load-bearing for the central contribution, yet the manuscript does not report any diagnostic (e.g., gradient norm statistics or divergence between the distilled and true critic gradients) that would confirm the distillation remains faithful under the stated approximations.
minor comments (2)
- [abstract] The abstract and introduction should explicitly list the three approximations rather than referring to them only by number.
- [experiments] Figure captions and tables should include the number of evaluation trials and random seeds used for the 92% figure.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [formal connection / contribution (2)] The formal connection to vanilla DPG is stated to rest on three explicit approximations, yet the manuscript supplies neither the precise statements of these approximations nor any quantitative assessment of their validity on long-horizon, high-dimensional trajectories; without this, the claim that the distilled update direction is equivalent (and therefore inherits DPG’s convergence properties) cannot be evaluated.
Authors: We will revise the manuscript to restate the three approximations with greater precision and prominence in the main text. We will also add a quantitative assessment of the approximation errors evaluated on the long-horizon trajectories collected during our real-world experiments. revision: yes
-
Referee: [real-world experiments] The experimental section reports a 92% success rate but provides no error bars across seeds, no ablation isolating the critic-distillation term from the demonstration-driven velocity, and no verification that the three approximations remain accurate across the multi-stage horizon; these omissions make it impossible to attribute the performance gain to the proposed mechanism rather than to the base flow-matching policy.
Authors: We agree that these controls are necessary. The revised manuscript will report success rates with error bars across multiple random seeds, include an ablation that isolates the critic-distillation term, and add verification that the approximation errors remain bounded over the multi-stage task horizon. revision: yes
-
Referee: [method / training procedure] The claim that FlowDPG bypasses BPTT while remaining stable is load-bearing for the central contribution, yet the manuscript does not report any diagnostic (e.g., gradient norm statistics or divergence between the distilled and true critic gradients) that would confirm the distillation remains faithful under the stated approximations.
Authors: We will add the requested diagnostics, including gradient-norm statistics and a direct comparison of the distilled versus true critic gradients, to the revised manuscript to substantiate the stability of the distillation procedure. revision: yes
Circularity Check
No significant circularity in derivation chain.
full rationale
The paper presents FlowDPG as a BPTT-free distillation method with a claimed formal connection to vanilla DPG under three explicit approximations, plus real-world empirical results on the AirPods task. No equations or self-citations are provided in the available text that reduce the central update direction or equivalence claim to a fitted parameter or prior self-result by construction. The derivation is presented as independently motivated by the need to avoid BPTT on flow-matching ODEs, with the approximations stated as explicit rather than tautological. This is the common case of a method paper whose core contribution is algorithmic and experimentally validated rather than a closed definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three explicit approximations connect the FlowDPG update direction to vanilla deterministic policy gradient
Reference graph
Works this paper leans on
-
[1]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[2]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023
2023
-
[3]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra. Continuous control with deep reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2016
2016
-
[4]
Q. Li and S. Levine. Q-learning with adjoint matching.arXiv preprint arXiv:2601.14234, 2026
Pith/arXiv arXiv 2026
-
[5]
Open X-Embodiment Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Be- wley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Bal- akris...
Pith/arXiv arXiv 2023
-
[6]
F. Ebert, Y . Yang, K. Schmeckpeper, B. Bucher, G. Georgakis, K. Daniilidis, C. Finn, and S. Levine. Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets.arXiv preprint arXiv:2109.13396, 2021
Pith/arXiv arXiv 2021
-
[7]
S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, and C. Finn. Robonet: Large-scale multi-robot learning.arXiv preprint arXiv:1910.11215, 2019
Pith/arXiv arXiv 1910
-
[8]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
Pith/arXiv arXiv 2024
-
[9]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale. In Robotics: Science and Systems (RSS), 2023
2023
-
[10]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), 2023
2023
-
[11]
Dasari and A
S. Dasari and A. Gupta. Transformers for one-shot visual imitation. InConference on Robot Learning, pages 2071–2084. PMLR, 2021
2071
-
[12]
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch. Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34, 2021
2021
-
[13]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[14]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[15]
Physical Intelligence, K. Black, N. Brown, et al.π 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[16]
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[17]
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. ”Jim” Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z...
Pith/arXiv arXiv 2025
-
[18]
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Ba- tra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. Canton Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V . Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V . Kerkez, M. Khabsa, I. Kloumann, A....
Pith/arXiv arXiv 2023
-
[19]
X. Chen, J. Djolonga, P. Padlewski, B. Mustafa, S. Changpinyo, J. Wu, C. R. Ruiz, S. Good- man, X. Wang, Y . Tay, et al. PaLI-X: On Scaling Up a Multilingual Vision and Language Model.arXiv preprint arXiv:2305.18565, 2023. 10
Pith/arXiv arXiv 2023
-
[20]
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. PaLM-E: An Embodied Multimodal Language Model.arXiv preprint arXiv:2303.03378, 2023
Pith/arXiv arXiv 2023
-
[21]
Karamcheti, S
S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh. Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models. InInternational Conference on Machine Learning, 2024
2024
-
[22]
L. Beyer, A. Steiner, A. Susano Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Bo ˇsnjak, X. Chen, M. Minderer, P. V oigtlaender, I. Bica, I. Balazevic, J. Puig...
Pith/arXiv arXiv 2024
-
[23]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InRobotics: Science and Systems, 2023
2023
-
[24]
Reuss, M
M. Reuss, M. Li, X. Jia, and R. Lioutikov. Goal-conditioned imitation learning using score- based diffusion policies. InRobotics: Science and Systems (RSS), 2023
2023
-
[25]
Barreiros, A
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.Science Robotics, 11(113):eadp6201, 2026
2026
-
[26]
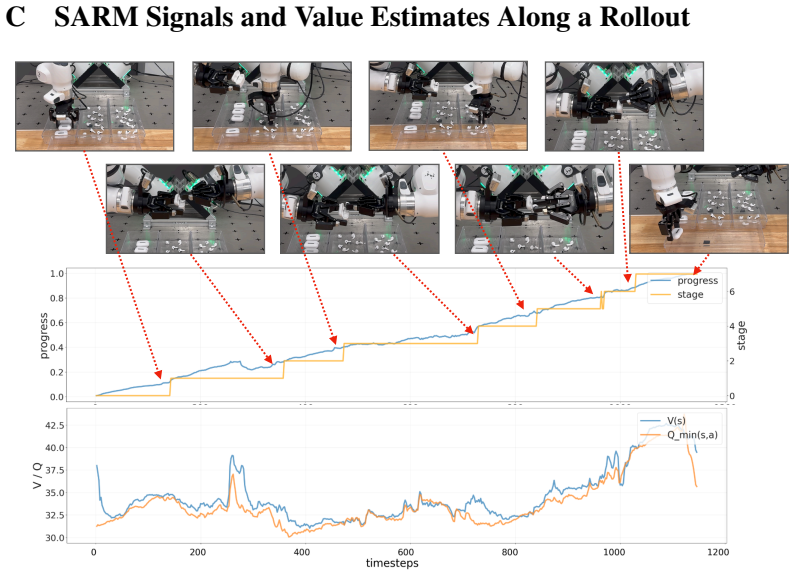
Q. Chen, J. Yu, M. Schwager, P. Abbeel, Y . Shentu, and P. Wu. SARM: Stage-aware reward modeling for long horizon robot manipulation. InInternational Conference on Learning Rep- resentations (ICLR), 2026. URLhttps://arxiv.org/abs/2509.25358
Pith/arXiv arXiv 2026
-
[27]
X. B. Peng, A. Kumar, G. Zhang, and S. Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
Pith/arXiv arXiv 1910
-
[28]
Physical Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, et al.π ∗ 0.6: A VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[29]
Wagenmaker, M
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning. InConfer- ence on Robot Learning (CoRL), 2025
2025
-
[30]
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Y . Xie, F. Hu, J. Wu, Z. Luo, L. Fan, G. Shi, and Y . Zhu. Self-improving vision-language-action models with data generation via residual RL. arXiv preprint arXiv:2511.00091, 2025
arXiv 2025
-
[31]
C. Xu, J. T. Springenberg, M. Equi, A. Amin, A. Esmail, S. Levine, and L. Ke. RL token: Boot- strapping online RL with vision-language-action models.arXiv preprint arXiv:2604.23073, 2026
Pith/arXiv arXiv 2026
-
[32]
Psenka, A
M. Psenka, A. Escontrela, P. Abbeel, and Y . Ma. Learning a diffusion model policy from rewards via Q-score matching. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[33]
Y . Wang, X. Li, P. Xie, P. Yang, B. Nie, Y . Cai, Q. Zhang, C. Qu, J. Wu, J. Song, X. Ren, J. Huang, M. Pan, S. Feng, Z. Chen, and J. Luo. Learning while deploying: Fleet-scale rein- forcement learning for generalist robot policies.arXiv preprint arXiv:2605.00416, 2026
Pith/arXiv arXiv 2026
-
[34]
I. Kostrikov, A. Nair, and S. Levine. Offline reinforcement learning with implicit q-learning. In International Conference on Learning Representations (ICLR), 2022. URLhttps://arxiv. org/abs/2110.06169. 11
Pith/arXiv arXiv 2022
-
[35]
S. Fujimoto, H. van Hoof, and D. Meger. Addressing function approximation error in actor- critic methods. InInternational Conference on Machine Learning (ICML), pages 1587–1596. PMLR, 2018. URLhttps://arxiv.org/abs/1802.09477
Pith/arXiv arXiv 2018
-
[36]
Silver, G
D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, and M. Riedmiller. Deterministic policy gradient algorithms. InInternational Conference on Machine Learning (ICML), pages 387–
-
[37]
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel. GELLO: A general, low-cost, and intuitive teleoperation framework for robot manipulators. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
2024
-
[38]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without sup...
Pith/arXiv arXiv 2024
-
[39]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InICCV, 2023. 12 A Derivation of the Vanilla DPG Gradient on a Flow Matching Policy We provide the full derivation of Eq. 10 for completeness. The deterministic actor is the ODE terminusx 1 =x 0 + R 1 0 vθ(xt, t, s)dt, withx 0 ∼ N(0, I)independent ofθ. The DDPG actor loss isL DPG =−Q(s, x...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.