Towards Fast Domain Adaptation and Fine-Grained User Simulation for Evaluating Conversational Recommender Systems
Pith reviewed 2026-06-26 07:11 UTC · model grok-4.3
The pith
AdaptSim uses automatic prompt generation and open actions to adapt user simulators across domains for reliable CRS evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AdaptSim is an adaptive user simulator that employs automatic prompt generation and an open action mechanism to model realistic user behavior across domains, paired with a think-then-respond strategy for fine-grained style control and a BFS-based turn-level pairwise comparison framework for comprehensive CRS evaluation.
What carries the argument
AdaptSim's combination of automatic prompt generation, open action mechanism, think-then-respond response generation, and BFS-based turn-level pairwise comparison framework.
If this is right
- CRSs can be assessed for core capabilities and robustness using simulations that transfer across domains without per-domain redesign.
- User modeling captures subtle linguistic styles and shifting preferences through controlled generation rather than fixed templates.
- Evaluation moves beyond single-turn metrics to structured turn-level comparisons that expose interaction weaknesses.
- The simulator reduces reliance on domain experts for prompt engineering when testing new recommendation settings.
Where Pith is reading between the lines
- The same adaptation mechanism could support rapid prototyping of CRSs for emerging product categories where real user data is scarce.
- Generated dialogues might serve as synthetic training data to improve the underlying recommender models themselves.
- The BFS comparison structure could extend to evaluating other multi-turn dialogue systems such as task-oriented chatbots.
- Combining the open action space with reinforcement learning might allow the simulator to evolve preferences over longer sessions.
Load-bearing premise
Automatic prompt generation combined with an open action mechanism will produce realistic, unbiased user behavior that transfers to novel domains without manual tuning or evaluation-invalidating artifacts.
What would settle it
Human evaluators in a blind test rate AdaptSim dialogues as substantially less realistic than real user conversations, or the BFS framework ranks known strong CRSs below weaker ones across multiple runs.
Figures
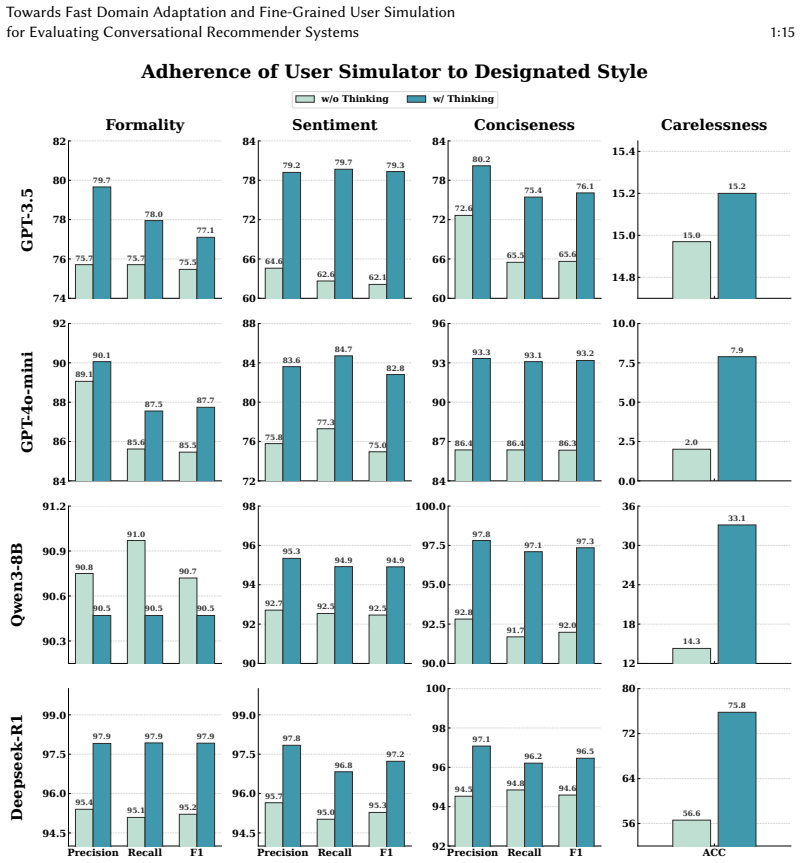


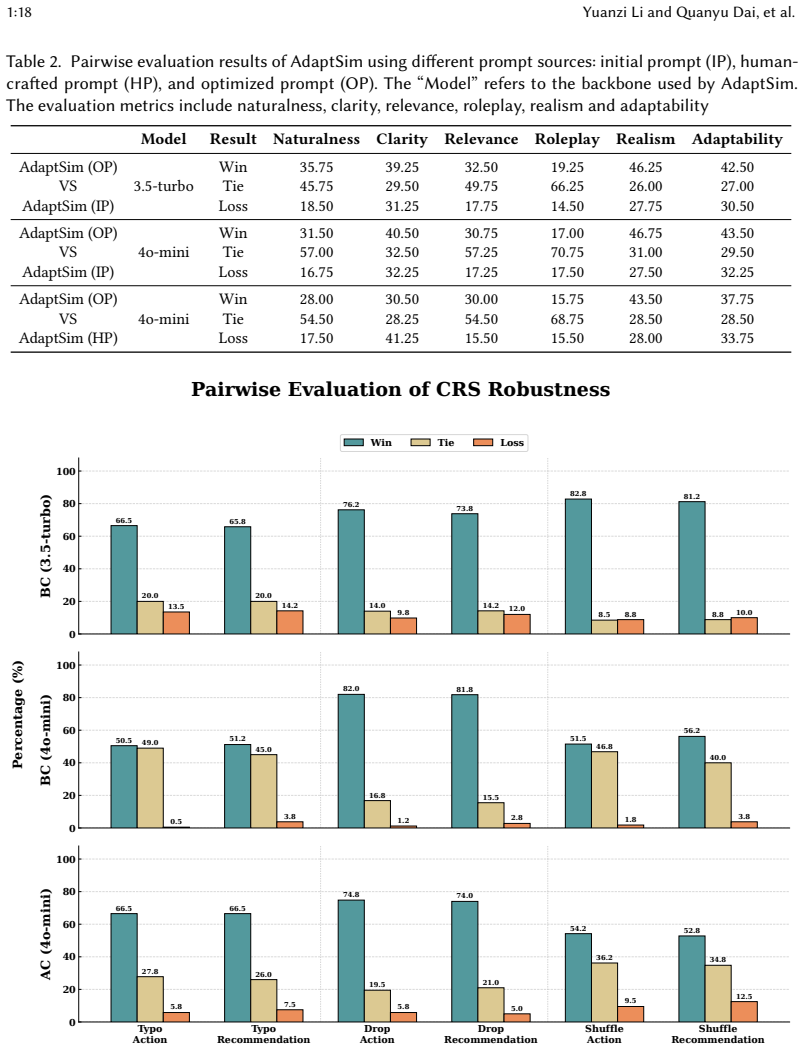
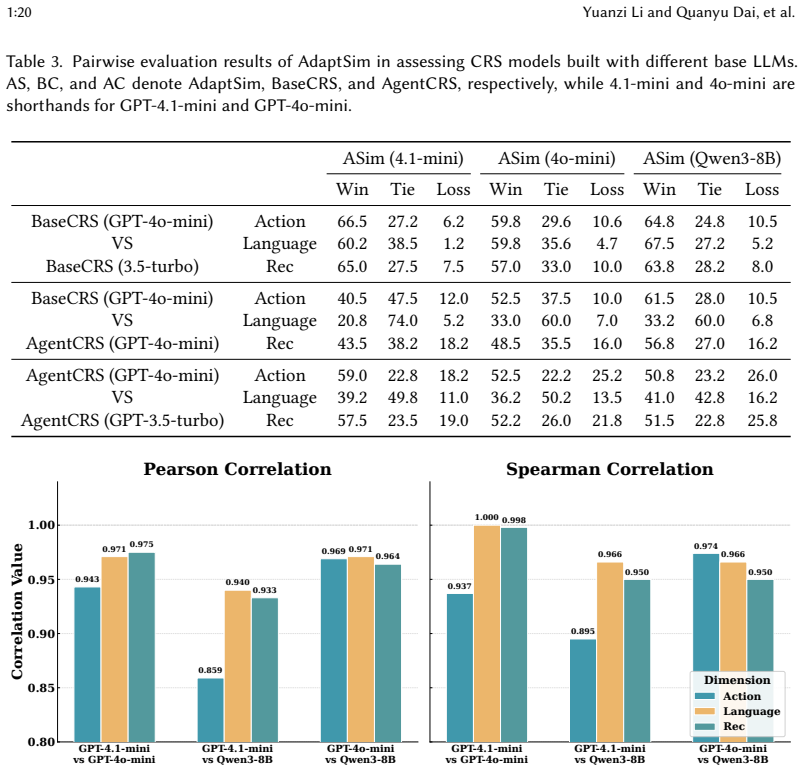










read the original abstract
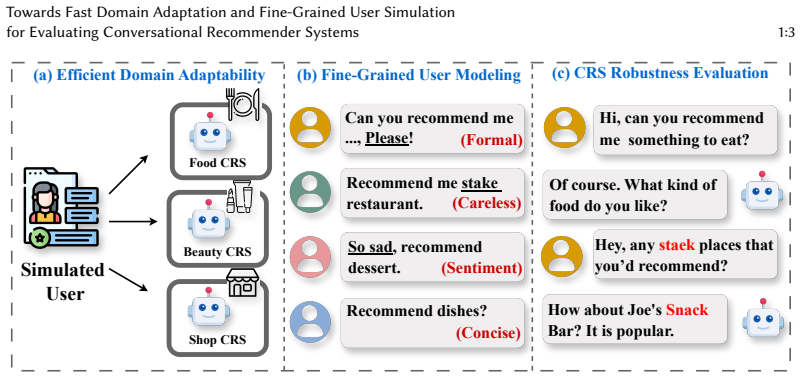
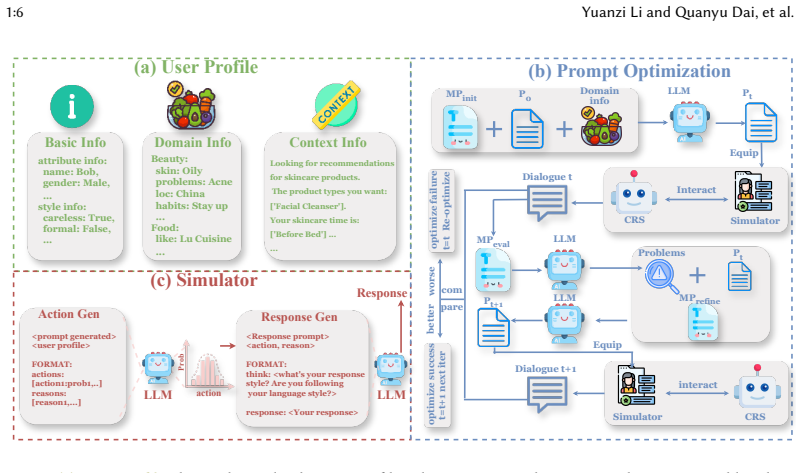
Conversational Recommender Systems (CRSs) enhance user experience through multi-turn interactions, yet evaluating their performance remains challenging. While Large Language Model (LLM) based user simulators are effective, they suffer from three key limitations: (1) Lack of Domain Adaptability: Reliance on fixed prompts and predefined action spaces hinders transfer to novel domains; (2) Limited User Modeling: Inability to accurately replicate subtle linguistic styles and dynamic preferences; (3) Insufficient Evaluation Validity: Existing simulators fail to adequately assess fundamental capabilities and system robustness. To overcome these, we propose AdaptSim, an Adaptive domain and automatic prompt tuning User Simulator. AdaptSim offers an efficient framework for evaluating CRSs by enabling realistic behavior modeling and diverse style generation. It leverages automatic prompt generation and an open action mechanism to reduce manual effort and improve cross-domain flexibility. For response generation, we employ controlled text generation with a "think-then-respond" strategy for fine-grained control over language style. For CRS evaluation, AdaptSim incorporates a novel Breadth-First Search (BFS)-based, turn-level pairwise comparison framework for comprehensive assessment. Extensive experiments across three domains and four LLMs demonstrate that AdaptSim generates realistic dialogues, enabling a highly effective and reliable evaluation of CRS capabilities and robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AdaptSim, an adaptive user simulator for conversational recommender systems that uses automatic prompt generation and an open action mechanism to address limitations in domain adaptability, user modeling, and evaluation validity. It introduces a 'think-then-respond' strategy for controlled response generation and a novel BFS-based turn-level pairwise comparison framework for CRS evaluation. Experiments across three domains and four LLMs are presented to support claims of realistic dialogue generation and reliable assessment of CRS capabilities and robustness.
Significance. If the central claims on realism and lack of simulator artifacts hold, the work would offer a meaningful advance in CRS evaluation by reducing manual prompt and action-space engineering while enabling cross-domain transfer. The automatic prompt tuning and BFS framework represent potentially useful methodological contributions for scalable assessment.
major comments (2)
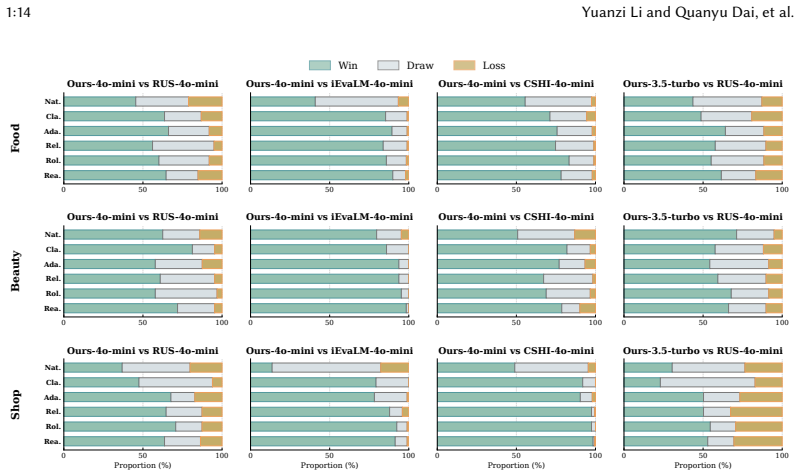
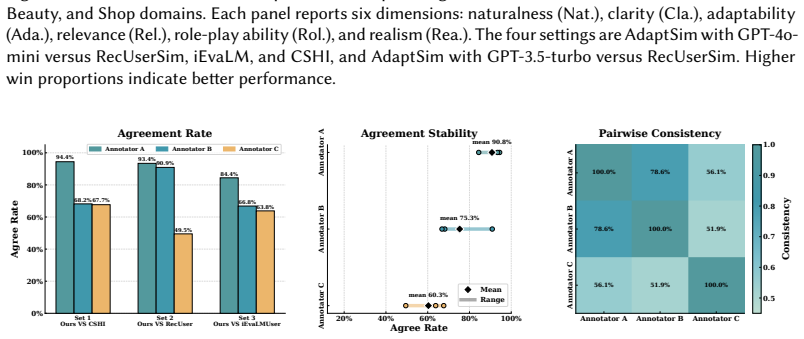
- [§5 (Experiments)] §5 (Experiments): The claim that AdaptSim 'generates realistic dialogues' enabling 'highly effective and reliable evaluation' lacks reported quantitative metrics for realism (e.g., human judgment scores, divergence from logged user actions), baseline comparisons with statistical significance, or ablation on post-hoc prompt tuning choices; without these, the central effectiveness claim cannot be assessed.
- [§4.3 (Open action mechanism)] §4.3 (Open action mechanism): The open action space is presented as removing bias from predefined constraints, yet no validation (e.g., comparison of action distributions to real-user logs or sensitivity analysis) rules out LLM-induced artifacts in action sequences; this is load-bearing for the BFS pairwise comparisons, as any systematic simulator bias would render cross-CRS differences uninterpretable.
minor comments (2)
- [Abstract] Abstract: The three limitations are listed but the mapping from each limitation to the corresponding AdaptSim component could be stated more explicitly for clarity.
- [§3 (Response generation)] §3 (Response generation): The 'think-then-respond' strategy is described at a high level; adding a short pseudocode snippet or example prompt template would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical validation of realism claims and the open action mechanism. We address each major comment below, agreeing where revisions are warranted while noting limitations on data availability.
read point-by-point responses
-
Referee: [§5 (Experiments)] The claim that AdaptSim 'generates realistic dialogues' enabling 'highly effective and reliable evaluation' lacks reported quantitative metrics for realism (e.g., human judgment scores, divergence from logged user actions), baseline comparisons with statistical significance, or ablation on post-hoc prompt tuning choices; without these, the central effectiveness claim cannot be assessed.
Authors: We acknowledge that the experiments in the current manuscript rely primarily on cross-domain and cross-LLM results to support effectiveness, without direct quantitative realism metrics such as human judgment scores or statistical significance tests against baselines. We will revise Section 5 to include human evaluation scores for dialogue realism, statistical tests for comparisons, and ablations on prompt tuning choices to better substantiate the claims. revision: yes
-
Referee: [§4.3 (Open action mechanism)] The open action space is presented as removing bias from predefined constraints, yet no validation (e.g., comparison of action distributions to real-user logs or sensitivity analysis) rules out LLM-induced artifacts in action sequences; this is load-bearing for the BFS pairwise comparisons, as any systematic simulator bias would render cross-CRS differences uninterpretable.
Authors: We agree that validation is essential for the open action mechanism given its role in the BFS framework. We will add sensitivity analysis on action sequence distributions in the revision to check for potential artifacts. Direct comparison to real-user logs is not feasible, as such logs are unavailable for the novel domains evaluated. revision: partial
- Direct comparison of action distributions to real-user logs, as no such logs are available for the domains tested.
Circularity Check
No significant circularity detected
full rationale
The paper introduces AdaptSim via automatic prompt generation, open action mechanism, controlled text generation with think-then-respond, and a BFS-based turn-level pairwise comparison for CRS evaluation. No equations, fitted parameters, or predictions are described that reduce by construction to inputs. The derivation chain relies on the proposed mechanisms and cross-domain experiments for validation rather than self-definition, fitted-input renaming, or load-bearing self-citations. The evaluation framework is presented as independent of simulator parameters, consistent with the reader's assessment of score 2.0 as the upper bound for minor issues.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. 2024. A survey on evaluation of large language models. ACM transactions on intelligent systems and technology 15, 3 (2024), 1–45
2024
-
[2]
Luyu Chen, Quanyu Dai, Zeyu Zhang, Xueyang Feng, Mingyu Zhang, Pengcheng Tang, Xu Chen, Yue Zhu, and Zhen- hua Dong. 2025. RecUserSim: A Realistic and Diverse User Simulator for Evaluating Conversational Recommender Systems. In Companion Proceedings of the ACM on Web Conference 2025 . 133–142
2025
-
[3]
Jiabao Fang, Shen Gao, Pengjie Ren, Xiuying Chen, Suzan Verberne, and Zhaochun Ren. 2024. A multi-agent conver- sational recommender system. arXiv preprint arXiv:2402.01135 (2024)
arXiv 2024
-
[4]
Chongming Gao, Wenqiang Lei, Xiangnan He, Maarten De Rijke, and Tat-Seng Chua. 2021. Advances and challenges in conversational recommender systems: A survey. AI open 2 (2021), 100–126
2021
-
[6]
Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. 2023. Chat-rec: Towards interac- tive and explainable llms-augmented recommender system. arXiv preprint arXiv:2303.14524 (2023)
arXiv 2023
-
[7]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
Pith/arXiv arXiv 2025
-
[8]
Zhankui He, Zhouhang Xie, Rahul Jha, Harald Steck, Dawen Liang, Yesu Feng, Bodhisattwa Prasad Majumder, Nathan Kallus, and Julian McAuley. 2023. Large language models as zero-shot conversational recommenders. In Proceedings of the 32nd ACM international conference on information and knowledge management . 720–730
2023
-
[9]
Xu Huang, Jianxun Lian, Yuxuan Lei, Jing Yao, Defu Lian, and Xing Xie. 2023. Recommender ai agent: Integrating large language models for interactive recommendations. arXiv preprint arXiv:2308.16505 (2023)
arXiv 2023
-
[10]
Rolf Jagerman, Ilya Markov, and Maarten de Rijke. 2019. When people change their mind: Off-policy evaluation in non-stationary recommendation environments. In Proceedings of the twelfth ACM international conference on web search and data mining . 447–455
2019
-
[11]
Dietmar Jannach, Ahtsham Manzoor, Wanling Cai, and Li Chen. 2021. A survey on conversational recommender systems. ACM Computing Surveys (CSUR) 54, 5 (2021), 1–36
2021
-
[12]
Dietmar Jannach, Ahtsham Manzoor, Wanling Cai, and Li Chen. 2021. A Survey on Conversational Recommender Systems. ACM Comput. Surv. 54, 5 (2021)
2021
-
[13]
David C. Knill and Alexandre Pouget. 2004. The Bayesian brain: the role of uncertainty in neural coding and compu- tation. Trends in Neurosciences 27, 12 (2004), 712–719. https://doi.org/10.1016/j.tins.2004.10.007
-
[14]
Wenqiang Lei, Gangyi Zhang, Xiangnan He, Yisong Miao, Xiang Wang, Liang Chen, and Tat-Seng Chua. 2020. Inter- active path reasoning on graph for conversational recommendation. In Proceedings of the 26th ACM SIGKDD interna- tional conference on knowledge discovery & data mining . 2073–2083
2020
-
[15]
Lei Li, Yongfeng Zhang, Dugang Liu, and Li Chen. 2023. Large language models for generative recommendation: A survey and visionary discussions. arXiv preprint arXiv:2309.01157 (2023)
arXiv 2023
-
[16]
Qingquan Li, Shaoyu Dou, Kailai Shao, Chao Chen, and Haixiang Hu. 2025. Evaluating Scoring Bias in LLM-as-a-Judge. arXiv preprint arXiv:2506.22316 (2025)
Pith/arXiv arXiv 2025
-
[17]
Xun Liang, Hanyu Wang, Yezhaohui Wang, Shichao Song, Jiawei Yang, Simin Niu, Jie Hu, Dan Liu, Shunyu Yao, Feiyu Xiong, and Zhiyu Li. 2024. Controllable Text Generation for Large Language Models: A Survey. arXiv:2408.12599 [cs.CL] https://arxiv.org/abs/2408.12599
arXiv 2024
-
[18]
Lizi Liao, Ryuichi Takanobu, Yunshan Ma, Xun Yang, Minlie Huang, and Tat-Seng Chua. 2019. Deep conversational recommender in travel. arXiv preprint arXiv:1907.00710 (2019)
Pith/arXiv arXiv 2019
-
[19]
Yuanxing Liu, Wei-Nan Zhang, Yifan Chen, Yuchi Zhang, Haopeng Bai, Fan Feng, Hengbin Cui, Yongbin Li, and Wanxiang Che. 2023. Conversational recommender system and large language model are made for each other in E-commerce pre-sales dialogue. arXiv preprint arXiv:2310.14626 (2023)
arXiv 2023
-
[20]
Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. 2023. Automatic prompt optimization with” gradient descent” and beam search. arXiv preprint arXiv:2305.03495 (2023)
arXiv 2023
-
[21]
Gregory Schraw and David Moshman. 1995. Metacognitive Theories. Educational Psychology Review 7 (12 1995), 351–371. https://doi.org/10.1007/BF02212307
-
[22]
Yueming Sun and Yi Zhang. 2018. Conversational recommender system. In The 41st international acm sigir conference on research & development in information retrieval . 235–244
2018
-
[23]
Tuhina Tripathi, Manya Wadhwa, Greg Durrett, and Scott Niekum. 2025. Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation. arXiv preprint arXiv:2504.14716 (2025)
arXiv 2025
-
[24]
Xiaolei Wang, Xinyu Tang, Wayne Xin Zhao, Jingyuan Wang, and Ji-Rong Wen. 2023. Rethinking the evaluation for conversational recommendation in the era of large language models. arXiv preprint arXiv:2305.13112 (2023). ACM Trans. Inf. Syst., Vol. 1, No. 1, Article 1. Publication date: January 2025. Towards Fast Domain Adaptation and Fine-Grained User Simula...
arXiv 2023
-
[25]
Xiaolei Wang, Kun Zhou, Ji-Rong Wen, and Wayne Xin Zhao. 2022. Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’22) . ACM, 1929–1937. https://doi.org/10.1145/3534678.3539382
-
[26]
Hanwei Xu, Yujun Chen, Yulun Du, Nan Shao, Yanggang Wang, Haiyu Li, and Zhilin Yang. 2022. Gps: Genetic prompt search for efficient few-shot learning. arXiv preprint arXiv:2210.17041 (2022)
arXiv 2022
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
Pith/arXiv arXiv 2025
-
[28]
Muchen Yang, Moxin Li, Yongle Li, Zijun Chen, Chongming Gao, Junqi Zhang, Yangyang Li, and Fuli Feng. 2024. Dual-Phase Accelerated Prompt Optimization. arXiv preprint arXiv:2406.13443 (2024)
arXiv 2024
-
[29]
Lechen Zhang, Tolga Ergen, Lajanugen Logeswaran, Moontae Lee, and David Jurgens. 2024. Sprig: Improving large language model performance by system prompt optimization. arXiv preprint arXiv:2410.14826 (2024)
Pith/arXiv arXiv 2024
-
[30]
Shuo Zhang and Krisztian Balog. 2020. Evaluating conversational recommender systems via user simulation. In Proceedings of the 26th acm sigkdd international conference on knowledge discovery & data mining . 1512–1520
2020
-
[31]
Xiaoyu Zhang, Ruobing Xie, Yougang Lyu, Xin Xin, Pengjie Ren, Mingfei Liang, Bo Zhang, Zhanhui Kang, Maarten de Rijke, and Zhaochun Ren. 2024. Towards empathetic conversational recommender systems. In Proceedings of the 18th ACM Conference on Recommender Systems . 84–93
2024
-
[32]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems 36 (2023), 46595–46623
2023
-
[33]
Kun Zhou, Wayne Xin Zhao, Shuqing Bian, Yuanhang Zhou, Ji-Rong Wen, and Jingsong Yu. 2020. Improving conver- sational recommender systems via knowledge graph based semantic fusion. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining . 1006–1014
2020
-
[34]
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2022. Large language models are human-level prompt engineers. In The eleventh international conference on learning repre- sentations
2022
-
[35]
Lixi Zhu, Xiaowen Huang, and Jitao Sang. 2024. How reliable is your simulator? analysis on the limitations of current llm-based user simulators for conversational recommendation. In Companion Proceedings of the ACM Web Conference
2024
-
[36]
Lixi Zhu, Xiaowen Huang, and Jitao Sang. 2024. A LLM-based Controllable, Scalable, Human-Involved User Simulator Framework for Conversational Recommender Systems. arXiv: 2405.08035 [cs.HC] https://arxiv.org/abs/2405.08035
arXiv 2024
-
[37]
Lixi Zhu, Xiaowen Huang, and Jitao Sang. 2025. A llm-based controllable, scalable, human-involved user simulator framework for conversational recommender systems. In Proceedings of the ACM on Web Conference 2025 . 4653–4661. ACM Trans. Inf. Syst., Vol. 1, No. 1, Article 1. Publication date: January 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.