Learning Robot Visual Navigation in Crowds via Intention-Aware Scene Representations
Pith reviewed 2026-06-25 19:04 UTC · model grok-4.3
The pith
Robot crowd navigation improves when visual observations are used to infer pedestrian intentions via attention encoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
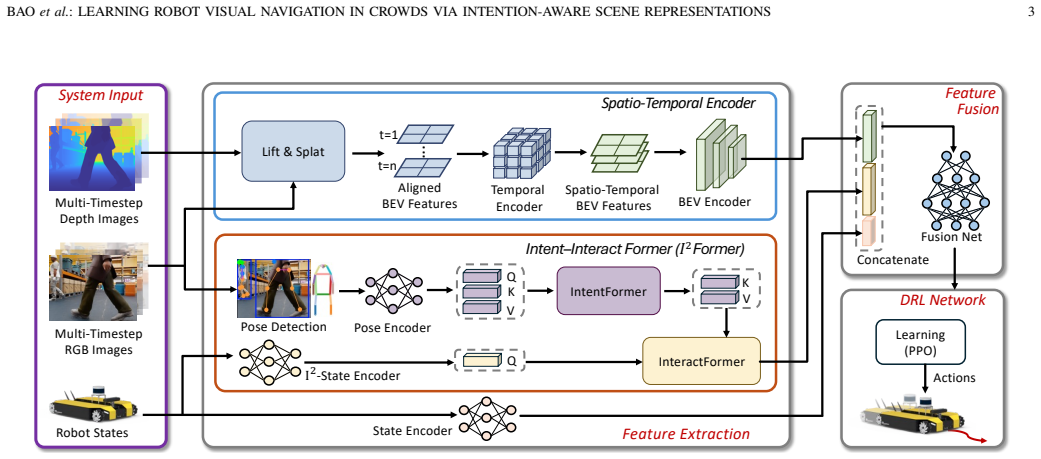
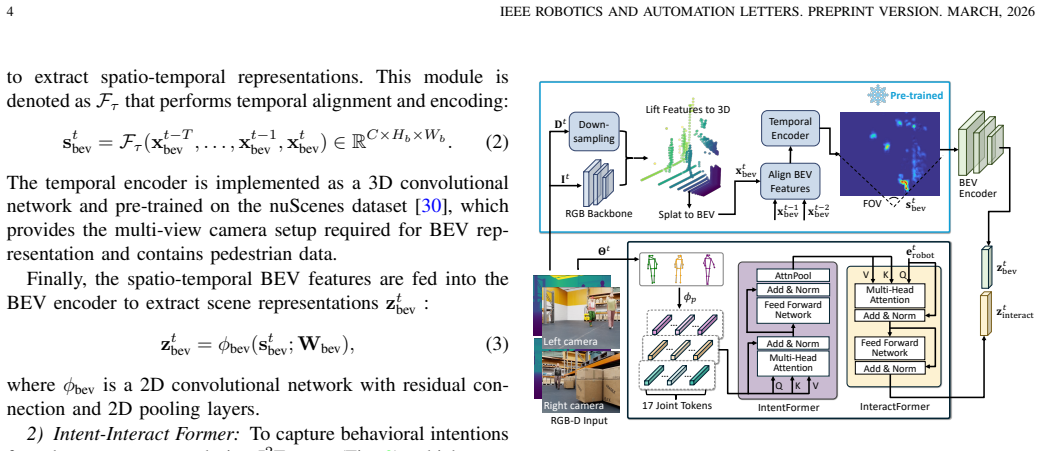
The paper claims that encoding behavioral and structural context from egocentric visual observations with a spatio-temporal encoder for occupancy features and the Intent-Interact Former for inferring motion intentions from human poses creates a compact state embedding that enables superior DRL policy training for crowd navigation compared to baselines using limited representations.
What carries the argument
The Intent-Interact Former (I² Former), an attention-based module that encodes human poses to infer pedestrians' motion intentions, together with a spatio-temporal encoder for scene occupancy features.
Load-bearing premise
Egocentric visual observations provide rich enough behavioral and structural context to reliably infer motion intentions and support effective DRL policy learning.
What would settle it
A scenario or test case where the visual input leads to incorrect intention inference, such as deceptive human poses, resulting in navigation failure despite the method's training.
Figures

read the original abstract
Robot crowd navigation requires the ability to infer human intentions while accounting for the structural constraints of the environment. Currently, deep reinforcement learning (DRL) provides a promising method for learning navigation policies that understand human intentions. However, most of them rely on limited scene representations, treating pedestrians as simple 2D points and ignoring rich visual cues from both humans and the environment. To address this issue, we introduce iCrowdNav, a novel visual crowd navigation method with intention-aware scene representations, to encode behavioral and structural context from egocentric visual observations. Our method employs two key components: a spatio-temporal encoder for extracting occupancy features of the scene, and Intent-Interact Former (I$^2$ Former), an attention-based module that encodes human poses to infer pedestrians' motion intentions. These features are integrated into a compact state embedding that supports effective DRL policy training. Extensive experiments show that our method achieves superior performance over baselines, and real-world deployment demonstrates vision-based crowd navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes iCrowdNav, a visual crowd navigation method that encodes behavioral and structural context from egocentric visual observations via a spatio-temporal encoder for occupancy features and the attention-based Intent-Interact Former (I² Former) module to infer pedestrians' motion intentions from human poses. These are fused into a compact state embedding for DRL policy training. The abstract claims that extensive experiments demonstrate superior performance over baselines and that real-world deployment validates vision-based crowd navigation.
Significance. If the empirical results hold with proper validation, the work could meaningfully advance DRL-based visual navigation by showing the value of intention-aware representations over simpler point-based or occupancy encodings. The focus on egocentric visuals for both humans and environment is a reasonable direction. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described.
major comments (2)
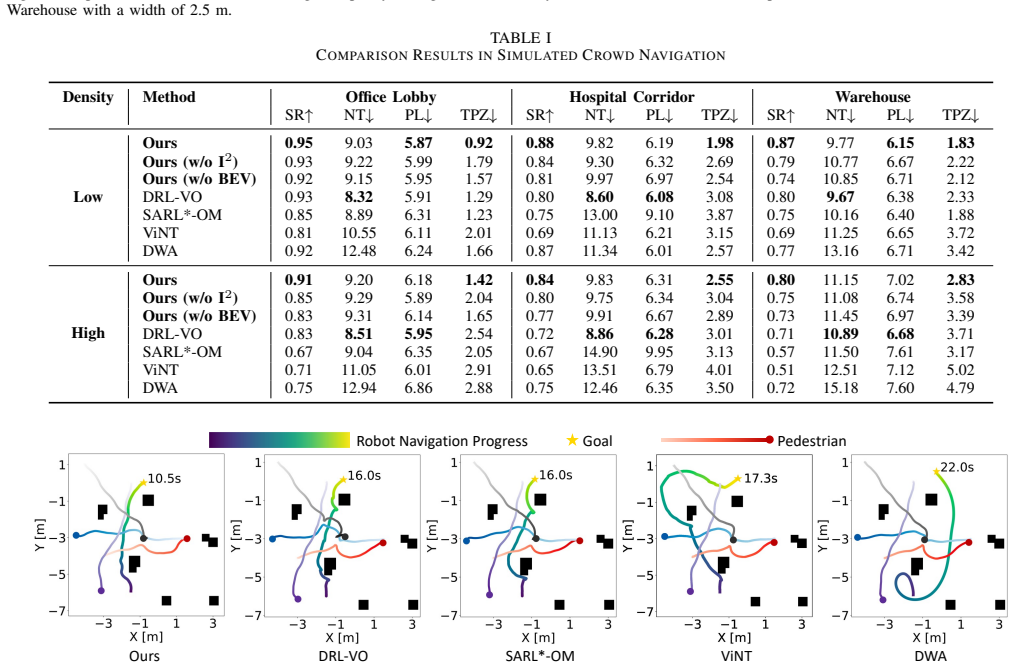
- [Abstract] Abstract: the central claim that 'extensive experiments show that our method achieves superior performance over baselines' supplies no quantitative metrics, baseline descriptions, experiment protocols, success rates, or error analysis, rendering the claim unverifiable from the provided text.
- [Abstract] Abstract / I² Former description: no isolated metric (e.g., intention prediction error vs. future pedestrian positions/velocities or ablation against a generic spatio-temporal encoder) is reported to show that the attention mechanism extracts motion-intention signals rather than merely increasing feature dimensionality; this is load-bearing for attributing gains to the intention-aware component.
minor comments (1)
- [Abstract] Abstract: the I² Former acronym is used before its expansion is given.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the claims would be strengthened by including quantitative details and will revise the abstract accordingly. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'extensive experiments show that our method achieves superior performance over baselines' supplies no quantitative metrics, baseline descriptions, experiment protocols, success rates, or error analysis, rendering the claim unverifiable from the provided text.
Authors: We agree that the abstract as written does not include specific quantitative metrics or protocol details, which limits verifiability. In the revised manuscript we will update the abstract to incorporate key results from the experiments section, including representative success rates, collision rates, and a concise description of the main baselines and evaluation protocol. revision: yes
-
Referee: [Abstract] Abstract / I² Former description: no isolated metric (e.g., intention prediction error vs. future pedestrian positions/velocities or ablation against a generic spatio-temporal encoder) is reported to show that the attention mechanism extracts motion-intention signals rather than merely increasing feature dimensionality; this is load-bearing for attributing gains to the intention-aware component.
Authors: The full manuscript contains ablation studies that isolate the contribution of the I² Former module to overall navigation performance. However, we acknowledge that a direct metric of intention prediction accuracy (e.g., error against future positions or velocities) is not reported. To strengthen attribution of gains to the intention-aware component, we will add such an isolated evaluation in the revised version. revision: yes
Circularity Check
No circularity; method description contains no derivations or fitted predictions
full rationale
The paper describes an empirical DRL-based navigation method using a spatio-temporal encoder and I² Former attention module on visual observations, with performance evaluated via experiments against baselines. No equations, parameter-fitting steps, or first-principles derivations appear in the provided text that could reduce by construction to inputs, self-citations, or renamed patterns. Claims rest on external experimental outcomes rather than any internal derivation chain, making the work self-contained against the listed circularity criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fapp: Fast and adaptive perception and planning for uavs in dynamic cluttered environments,
M. Luet al., “Fapp: Fast and adaptive perception and planning for uavs in dynamic cluttered environments,”IEEE Transactions on Robotics, vol. 41, pp. 871–886, 2025
2025
-
[2]
Rpf-search: Field-based search for robot person follow- ing in unknown dynamic environments,
H. Yeet al., “Rpf-search: Field-based search for robot person follow- ing in unknown dynamic environments,”IEEE/ASME Transactions on Mechatronics, pp. 1–12, 2025
2025
-
[3]
Namr-rrt: Neural adaptive motion planning for mobile robots in dynamic environments,
Z. Sunet al., “Namr-rrt: Neural adaptive motion planning for mobile robots in dynamic environments,”IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 13 087–13 100, 2025
2025
-
[4]
A dual closed-loop control strategy for human-following robots respecting social space,
J. Penget al., “A dual closed-loop control strategy for human-following robots respecting social space,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 11 252–11 258
2024
-
[5]
Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning,
C. Chenet al., “Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning,” in2019 international conference on robotics and automation (ICRA). IEEE, 2019, pp. 6015– 6022
2019
-
[6]
Motion planning among dynamic, decision-making agents with deep reinforcement learning,
M. Everett, Y . F. Chen, and J. P. How, “Motion planning among dynamic, decision-making agents with deep reinforcement learning,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 3052–3059
2018
-
[7]
Intention aware robot crowd navigation with attention- based interaction graph,
S. Liuet al., “Intention aware robot crowd navigation with attention- based interaction graph,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 12 015–12 021
2023
-
[8]
Socially compliant robot navi- gation in crowded environment by human behavior resemblance using deep reinforcement learning,
S. S. Samsani and M. S. Muhammad, “Socially compliant robot navi- gation in crowded environment by human behavior resemblance using deep reinforcement learning,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 5223–5230, 2021
2021
-
[9]
Robot navigation in crowded environments using deep reinforcement learning,
L. Liuet al., “Robot navigation in crowded environments using deep reinforcement learning,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 5671–5677
2020
-
[10]
Drl-vo: Learning to navigate through crowded dy- namic scenes using velocity obstacles,
Z. Xie and P. Dames, “Drl-vo: Learning to navigate through crowded dy- namic scenes using velocity obstacles,”IEEE Transactions on Robotics, vol. 39, no. 4, pp. 2700–2719, 2023
2023
-
[11]
Navdreams: Towards camera-only rl navigation among humans,
D. Dugaset al., “Navdreams: Towards camera-only rl navigation among humans,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 2504–2511
2022
-
[12]
Vision-centric bev perception: A survey,
Y . Maet al., “Vision-centric bev perception: A survey,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 10 978–10 997, 2024
2024
-
[13]
Robots that can see: Leveraging human pose for trajectory prediction,
T. Salzmannet al., “Robots that can see: Leveraging human pose for trajectory prediction,”IEEE Robotics and Automation Letters, vol. 8, no. 11, pp. 7090–7097, 2023
2023
-
[14]
Social-pose: Enhancing trajectory prediction with human body pose,
Y . Gao, S. Saadatnejad, and A. Alahi, “Social-pose: Enhancing trajectory prediction with human body pose,”IEEE Transactions on Intelligent Transportation Systems, 2025
2025
-
[15]
A survey on socially aware robot navigation: Taxonomy and future challenges,
P. T. Singamaneniet al., “A survey on socially aware robot navigation: Taxonomy and future challenges,”The International Journal of Robotics Research, vol. 43, no. 10, pp. 1533–1572, 2024
2024
-
[16]
Vlm-social-nav: Socially aware robot navigation through scoring using vision-language models,
D. Songet al., “Vlm-social-nav: Socially aware robot navigation through scoring using vision-language models,”IEEE Robotics and Automation Letters, 2024
2024
-
[17]
Social-llava: Enhancing robot navigation through human-language reasoning in social spaces,
A. Payandehet al., “Social-llava: Enhancing robot navigation through human-language reasoning in social spaces,”arXiv preprint arXiv:2501.09024, 2024
arXiv 2024
-
[18]
Gson: A group-based social navigation framework with large multimodal model,
S. Luoet al., “Gson: A group-based social navigation framework with large multimodal model,”IEEE Robotics and Automation Letters, 2025
2025
-
[19]
Social force model for pedestrian dynamics,
D. Helbing and P. Molnar, “Social force model for pedestrian dynamics,” Physical review E, vol. 51, no. 5, p. 4282, 1995
1995
-
[20]
The dynamic window approach to collision avoidance,
D. Fox, W. Burgard, and S. Thrun, “The dynamic window approach to collision avoidance,”IEEE robotics & automation magazine, vol. 4, no. 1, pp. 23–33, 2002
2002
-
[21]
Human-behaviour-based social locomotion model im- proves the humanization of social robots,
C. Zhouet al., “Human-behaviour-based social locomotion model im- proves the humanization of social robots,”Nature Machine Intelligence, vol. 4, no. 11, pp. 1040–1052, 2022
2022
-
[22]
Crowd-aware robot navigation for pedestrians with mul- tiple collision avoidance strategies via map-based deep reinforcement learning,
S. Yaoet al., “Crowd-aware robot navigation for pedestrians with mul- tiple collision avoidance strategies via map-based deep reinforcement learning,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 8144–8150
2021
-
[23]
Learning world transition model for socially aware robot navigation,
Y . Cuiet al., “Learning world transition model for socially aware robot navigation,” in2021 IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 9262–9268
2021
-
[24]
Rmrl: Robot navigation in crowd environments with risk map-based deep reinforcement learning,
H. Yanget al., “Rmrl: Robot navigation in crowd environments with risk map-based deep reinforcement learning,”IEEE Robotics and Automation Letters, vol. 8, no. 12, pp. 7930–7937, 2023
2023
-
[25]
Collision avoidance among dense heterogeneous agents using deep reinforcement learning,
K. Zhuet al., “Collision avoidance among dense heterogeneous agents using deep reinforcement learning,”IEEE Robotics and Automation Letters, vol. 8, no. 1, pp. 57–64, 2023
2023
-
[26]
Learning local planners for human-aware navi- gation in indoor environments,
R. Guldenringet al., “Learning local planners for human-aware navi- gation in indoor environments,” in2020 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 6053–6060
2020
-
[27]
Bevnav: Robot autonomous navigation via spatial- temporal contrastive learning in bird’s-eye view,
J. Jianget al., “Bevnav: Robot autonomous navigation via spatial- temporal contrastive learning in bird’s-eye view,”IEEE Robotics and Automation Letters, 2024
2024
-
[28]
Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras,
A. Huet al., “Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 273–15 282
2021
-
[29]
Deep residual learning for image recognition,
K. Heet al., “Deep residual learning for image recognition,” inProceed- ings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[30]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesaret al., “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[31]
Ultralytics yolov8,
G. Jocher, A. Chaurasia, and J. Qiu, “Ultralytics yolov8,” 2023. [Online]. Available: https://github.com/ultralytics/ultralytics
2023
-
[32]
Proximal policy optimization algorithms,
J. Schulmanet al., “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[33]
Navrl: Learning safe flight in dynamic environments,
Z. Xuet al., “Navrl: Learning safe flight in dynamic environments,” IEEE Robotics and Automation Letters, 2025
2025
-
[34]
Characterizing the complexity of social robot navigation scenarios,
A. Stratton, K. Hauser, and C. Mavrogiannis, “Characterizing the complexity of social robot navigation scenarios,”IEEE Robotics and Automation Letters, 2024
2024
-
[35]
ViNT: A foundation model for visual navigation,
D. Shahet al., “ViNT: A foundation model for visual navigation,” in 7th Annual Conference on Robot Learning, 2023. [Online]. Available: https://arxiv.org/abs/2306.14846
arXiv 2023
-
[36]
Optimal path planning using generalized voronoi graph and multiple potential functions,
J. Wang and M. Q.-H. Meng, “Optimal path planning using generalized voronoi graph and multiple potential functions,”IEEE transactions on industrial electronics, vol. 67, no. 12, pp. 10 621–10 630, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.