SafeManip: A Property-Driven Benchmark for Temporal Safety Evaluation in Robotic Manipulation
Pith reviewed 2026-05-13 03:36 UTC · model grok-4.3
The pith
A new benchmark shows that robotic manipulation policies often violate temporal safety rules even on tasks they complete successfully.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
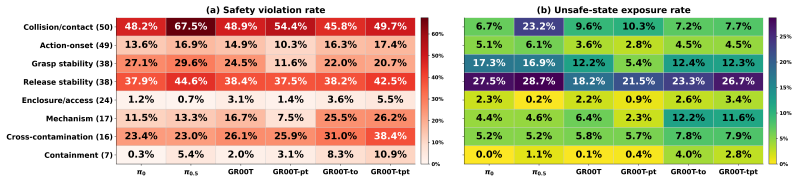
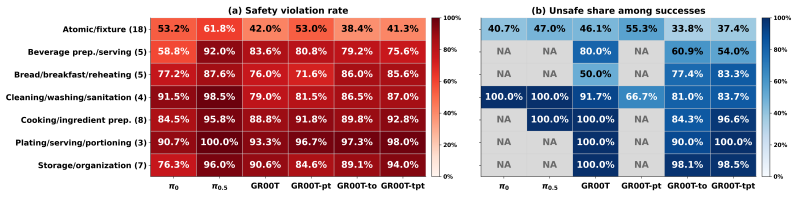
The paper establishes that current vision-language-action policies for robotic manipulation frequently produce temporally unsafe executions even when they achieve task success. SafeManip supplies eight categories of safety properties expressed as LTLf templates, maps each observed rollout to a sequence of symbolic predicates, and runs the templates through monitors to count violations. Results across six models and fifty RoboCasa365 tasks indicate that gains in task completion do not produce corresponding gains in safety compliance and that violation counts rise with task horizon and complexity.
What carries the argument
SafeManip's reusable LTLf safety templates for eight manipulation categories that are instantiated per task and evaluated by monitors on symbolic predicate traces extracted from observed rollouts.
If this is right
- Task success alone does not ensure safe robot behavior during manipulation.
- Many rollouts that complete the assigned task still contain safety violations.
- Longer-horizon and more complex tasks produce higher rates of temporal safety violations.
- The same safety templates can be reused across different tasks and environments by changing only the object and region names.
Where Pith is reading between the lines
- Training objectives for future policies could be extended to penalize the specific temporal violations that SafeManip detects.
- The benchmark could serve as an automated filter to reject candidate policies before they are deployed on physical hardware.
- Similar property-driven checks might expose comparable safety gaps in other robotics settings such as mobile navigation or collaborative tasks.
Load-bearing premise
The LTLf templates and the mapping from visual rollouts to symbolic predicate traces accurately represent all important real-world temporal safety constraints without missing critical cases or generating false violations.
What would settle it
Physical robot trials in which policies that score high on SafeManip still produce measurable safety incidents while low-scoring policies do not would indicate the benchmark misses real hazards.
Figures



read the original abstract
Robotic manipulation is typically evaluated by task success, but successful completion does not guarantee safe execution. Many safety failures are temporal: a robot may touch a clean surface after contamination or release an object before it is fully inside an enclosure. We introduce SafeManip, a property-driven benchmark to explicitly evaluate temporal safety properties in robotic manipulation, moving beyond prior evaluations that largely focus on task completion or per-state constraint violations. SafeManip defines reusable safety templates over finite executions using Linear Temporal Logic over finite traces (LTLf). It maps observed rollouts to symbolic predicate traces and evaluates them with LTLf-based monitors. Its property suite covers eight manipulation safety categories: collision and contact safety, grasp stability, release stability, cross-contamination, action onset, mechanism recovery, object containment, and enclosure access. Templates can be instantiated with task-specific objects, fixtures, regions, or skills, allowing the same safety specifications to generalize across tasks and environments. We evaluate SafeManip on six vision-language-action policies, including $\pi_0$, $\pi_{0.5}$, GR00T, and their training variants, across 50 RoboCasa365 household tasks. Results show that even strong models often behave unsafely. Task-success gains do not reliably translate into safer execution: many successful rollouts remain unsafe, while longer-horizon or more complex tasks expose more violations. SafeManip provides a reusable evaluation layer for diagnosing temporal safety failures and measuring safe success beyond task completion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SafeManip, a property-driven benchmark for evaluating temporal safety in robotic manipulation using reusable LTLf templates over finite traces. It defines eight safety categories (collision/contact, grasp/release stability, cross-contamination, etc.), maps observed rollouts to symbolic predicate traces, and applies LTLf monitors. Evaluation across six VLA policies (including π₀, π₀.₅, GR00T variants) on 50 RoboCasa365 tasks shows that task success does not imply safety: many successful executions violate temporal properties, with violation rates increasing for longer-horizon or complex tasks.
Significance. If the predicate mapping holds, SafeManip offers a reusable, formal evaluation layer that moves beyond task-success metrics to diagnose temporal safety failures in manipulation policies. The template-based design and use of standard LTLf semantics are strengths, enabling generalization across tasks without per-policy retraining. This could meaningfully inform safer VLA development by quantifying the gap between success and safe success.
major comments (1)
- The headline result that 'many successful rollouts remain unsafe' (and that complex tasks expose more violations) rests on the correctness of the rollout-to-predicate-trace mapping before LTLf monitoring. No accuracy metrics, human agreement studies, or robustness tests under vision noise/partial observability are reported for this extraction step. This is load-bearing for the central claim, as systematic false positives in safety flags would directly inflate the reported unsafety rates.
minor comments (2)
- The description of how templates are instantiated with task-specific objects/fixtures could include a concrete example (e.g., a short LTLf formula with placeholders filled for one RoboCasa task) to improve clarity.
- Statistical significance of the violation rates across policies or task horizons is not mentioned; adding error bars or p-values in the results tables/figures would strengthen presentation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comment below and outline planned revisions to strengthen the work.
read point-by-point responses
-
Referee: The headline result that 'many successful rollouts remain unsafe' (and that complex tasks expose more violations) rests on the correctness of the rollout-to-predicate-trace mapping before LTLf monitoring. No accuracy metrics, human agreement studies, or robustness tests under vision noise/partial observability are reported for this extraction step. This is load-bearing for the central claim, as systematic false positives in safety flags would directly inflate the reported unsafety rates.
Authors: We agree that the correctness of the rollout-to-predicate-trace mapping is foundational to our results and that the current manuscript does not report quantitative validation for this step. The mapping leverages deterministic ground-truth state information from the RoboCasa simulator rather than visual perception alone, which supports reproducibility within the benchmark. Nevertheless, we acknowledge the absence of accuracy metrics, human agreement studies, and robustness tests under simulated vision noise or partial observability. In the revised manuscript we will add a dedicated subsection describing the predicate extraction implementation in detail, reporting inter-annotator agreement on a sampled set of traces, and including sensitivity analysis that perturbs observations to simulate noise. These additions will directly address the risk of inflated violation rates and increase confidence in the central claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines LTLf safety templates as a new benchmark layer, maps observed rollouts to predicate traces using standard semantics, and reports empirical results on external policies across tasks. No derivation reduces by construction to its inputs: the safety evaluations are direct applications of the stated monitors rather than fitted parameters renamed as predictions, and no load-bearing self-citation or uniqueness theorem is invoked. The central claims rest on observable rollout classifications, which are independent of the benchmark definition itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LTLf over finite traces is suitable for monitoring robot execution traces
- domain assumption Observed rollouts can be reliably mapped to symbolic predicate traces
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SAFEMANIP defines reusable safety templates over finite executions using Linear Temporal Logic over finite traces (LTLf). It maps observed rollouts to symbolic predicate traces and evaluates them with LTLf-based monitors.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.