FusionAccel: A General Re-configurable Deep Learning Inference Accelerator on FPGA for Convolutional Neural Networks
Pith reviewed 2026-05-25 08:53 UTC · model grok-4.3
The pith
FusionAccel is a scalable RTL-based CNN accelerator on FPGA that matches Caffe-CPU outputs and supports pre-compilation reconstruction plus runtime reconfiguration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
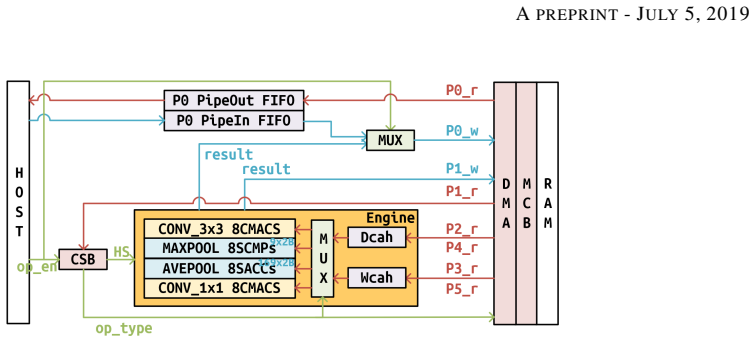
FusionAccel is a scalable convolutional neural network accelerator hardware architecture with supporting software. It can adapt to different network structures and can be reconstructed before compilation and reconfigured at runtime. This paper realizes this RTL convolutional neural network accelerator design and functional verifications on a Xilinx Spartan-6 FPGA. The result is identical to that of Caffe-CPU. Since the entire project is based on RTL, it can be migrated to ASIC after replacing some FPGA-specific IPs.
What carries the argument
The RTL convolutional neural network accelerator design that enables scalability across network structures through pre-compilation reconstruction and runtime reconfiguration.
If this is right
- The accelerator handles varying CNN structures without requiring a full redesign for each new network.
- Pre-compilation reconstruction and runtime reconfiguration together allow the same hardware to serve multiple models.
- RTL implementation produces results identical to Caffe-CPU on the tested FPGA.
- The design can be ported to ASIC by swapping only FPGA-specific IP blocks.
Where Pith is reading between the lines
- Users could treat the RTL template as a starting point and change only configuration parameters rather than rewrite accelerator logic for new CNNs.
- If the reconfiguration mechanism scales to larger or deeper networks, the same FPGA bitstream could support model updates in deployed systems without hardware replacement.
- Matching Caffe-CPU outputs opens the possibility of using the accelerator as a drop-in replacement in existing Caffe-based workflows for edge inference.
Load-bearing premise
Functional verification on one Spartan-6 FPGA with outputs matching Caffe-CPU is enough to prove the design works correctly for arbitrary CNN structures and can move to ASIC after only minor IP changes.
What would settle it
Running the accelerator on a CNN structure different from those used in verification and obtaining outputs that differ from Caffe-CPU would show the adaptability claim does not hold.
Figures




































read the original abstract
The deep learning accelerator is one of the methods to accelerate deep learning network computations, which is mainly based on convolutional neural network acceleration. To address the fact that concurrent convolutional neural network accelerators are not solely open-source and the exclusiveness of platforms, FusionAccel, a scalable convolutional neural network accelerator hardware architecture with supporting software is proposed. It can adapt to different network structures and can be reconstructed before compilation and reconfigured at runtime. This paper realizes this RTL convolutional neural network accelerator design and functional verifications on a Xilinx Spartan-6 FPGA. The result is identical to that of Caffe-CPU. Since the entire project is based on RTL, it can be migrated to ASIC after replacing some FPGA-specific IPs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FusionAccel, a scalable and re-configurable RTL-based CNN inference accelerator architecture with supporting software. It claims the design adapts to different network structures via pre-compilation reconstruction and runtime reconfiguration, has been implemented and functionally verified on a Xilinx Spartan-6 FPGA with results identical to Caffe-CPU, and can be migrated to ASIC after replacing FPGA-specific IPs.
Significance. If the verification and generality claims hold, the work would supply an open RTL design for CNN acceleration that is adaptable across networks and potentially portable to ASIC, addressing the noted scarcity of open-source, non-platform-exclusive accelerators.
major comments (3)
- [Abstract] Abstract: the central claim that 'the result is identical to that of Caffe-CPU' is load-bearing for correctness and generality but supplies no test networks, layer coverage (padding modes, strides, batch-norm, activations), error metrics, or exclusion criteria.
- [Abstract] Abstract: the portability assertion ('migrated to ASIC after replacing some FPGA-specific IPs') is untested and lacks any discussion of which IPs are replaced or why FPGA timing/resource assumptions would survive the substitution.
- [Abstract] Abstract: no quantitative resource utilization, latency, or throughput figures are reported, which is required to substantiate the 'scalable' and 'general' claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. The points raised correctly identify areas where the manuscript provides insufficient supporting detail for its central claims. We will revise the abstract and add material to the main text to address each issue.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the result is identical to that of Caffe-CPU' is load-bearing for correctness and generality but supplies no test networks, layer coverage (padding modes, strides, batch-norm, activations), error metrics, or exclusion criteria.
Authors: We agree that the abstract does not supply these details. We will revise the abstract to name the networks used for verification and state the error metric (exact integer match). The experiments section will be expanded to list supported layer parameters and any exclusions. revision: yes
-
Referee: [Abstract] Abstract: the portability assertion ('migrated to ASIC after replacing some FPGA-specific IPs') is untested and lacks any discussion of which IPs are replaced or why FPGA timing/resource assumptions would survive the substitution.
Authors: The referee is correct that the claim is untested. We will qualify or remove the assertion in the abstract and add a short discussion section noting the specific FPGA IPs (e.g., memory and clock primitives) that would require replacement, together with the need for separate ASIC timing closure. revision: yes
-
Referee: [Abstract] Abstract: no quantitative resource utilization, latency, or throughput figures are reported, which is required to substantiate the 'scalable' and 'general' claims.
Authors: We agree that quantitative figures are required. The implementation section will be updated to include explicit resource counts, latency, and throughput numbers measured on the Spartan-6 device; these will also be summarized in the revised abstract. revision: yes
Circularity Check
No circularity: implementation verified against independent external benchmark
full rationale
The paper presents an RTL hardware architecture for CNN inference, implemented and functionally verified on a Xilinx Spartan-6 FPGA with outputs matching Caffe-CPU. No equations, fitted parameters, predictions, or self-citations appear in the text. The central claim rests on direct comparison to an external reference implementation rather than any derivation that reduces to its own inputs by construction. This matches the default expectation of a self-contained engineering result with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient methods and hardware for de ep learning
Song Han and B Dally. Efficient methods and hardware for de ep learning. University Lecture, 2017
work page 2017
-
[2]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, and Kurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer paramet ers and< 0.5 mb model size. arXiv preprint 25 A PREPRINT - J ULY 5, 2019 arXiv:1602.07360, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
Nn-x-a hardware accelerator for conv olutional neural networks
Vinayak A Gokhale. Nn-x-a hardware accelerator for conv olutional neural networks. 2014
work page 2014
-
[4]
Squeezenext: Hardware-aware neural network design
Amir Gholami, Kiseok Kwon, Bichen Wu, Zizheng Tai, Xiang yu Y ue, Peter Jin, Sicheng Zhao, and Kurt Keutzer. Squeezenext: Hardware-aware neural network design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition W orkshops, pages 1638–1647, 2018
work page 2018
-
[5]
Bichen Wu, Forrest Iandola, Peter H Jin, and Kurt Keutzer . Squeezedet: Unified, small, low power fully con- volutional neural networks for real-time object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition W orkshops, pages 129–137, 2017
work page 2017
-
[6]
Eie: efficient inference engine on compressed deep neural networ k
Song Han, Xingyu Liu, Huizi Mao, Jing Pu, Ardavan Pedram, Mark A Horowitz, and William J Dally. Eie: efficient inference engine on compressed deep neural networ k. In 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA) , pages 243–254. IEEE, 2016
work page 2016
-
[7]
Origami: A 803-gop/s/w convolutional network accelerator
Lukas Cavigelli and Luca Benini. Origami: A 803-gop/s/w convolutional network accelerator. IEEE Transac- tions on Circuits and Systems for Video T echnology, 27(11):2461–2475, 2016
work page 2016
-
[8]
Towards a universal fpga matrix-vector multiplication architec- ture
Srinidhi Kestur, John D Davis, and Eric S Chung. Towards a universal fpga matrix-vector multiplication architec- ture. In 2012 IEEE 20th International Symposium on Field-Programma ble Custom Computing Machines , pages 9–16. IEEE, 2012
work page 2012
-
[9]
Cnp: An fpga-based processor for convolu- tional networks
Clément Farabet, Cyril Poulet, Jefferson Y Han, and Y ann LeCun. Cnp: An fpga-based processor for convolu- tional networks. In 2009 International Conference on Field Programmable Logic and Applications, pages 32–37. IEEE, 2009
work page 2009
-
[10]
Neuflow: A runtime reconfigurable dataflow processor for vision
Clément Farabet, Berin Martini, Benoit Corda, Polina A kselrod, Eugenio Culurciello, and Y ann LeCun. Neuflow: A runtime reconfigurable dataflow processor for vision. In CVPR W orkshops, pages 109–116, 2011
work page 2011
-
[11]
Hardware-oriented Approximation of Convolutional Neural Networks
Philipp Gysel, Mohammad Motamedi, and Soheil Ghiasi. H ardware-oriented approximation of convolutional neural networks. arXiv preprint arXiv:1604.03168, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Nvdla primer, nvdla documentatio n
NVIDIA Corporation. Nvdla primer, nvdla documentatio n. https://nvdla.org/primer.html. Accessed March 6, 2019
work page 2019
-
[13]
Chaidnn, hls based deep neural network acce lerator library for xilinx ultrascale+ mpsocs
Xilinx Inc. Chaidnn, hls based deep neural network acce lerator library for xilinx ultrascale+ mpsocs. https://github.com/Xilinx/CHaiDNN. Accessed March 6, 2019
work page 2019
-
[14]
Opal Kelly Incorporated. Xem6310. https://opalkelly.com/products/xem6310. Accessed March 6, 2019
work page 2019
-
[15]
Mec: memory-efficient conv olution for deep neural network
Minsik Cho and Daniel Brand. Mec: memory-efficient conv olution for deep neural network. In Proceedings of the 34th International Conference on Machine Learning-V olume 70, pages 815–824. JMLR. org, 2017. 26
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.