ProsoCodec: Prosody-Oriented Speech Codec for Voice Conversion
Pith reviewed 2026-06-26 11:47 UTC · model grok-4.3
The pith
Conditioning encoder and decoder on text and speaker embeddings directs a speech codec's discrete bottleneck to capture only residual prosody.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
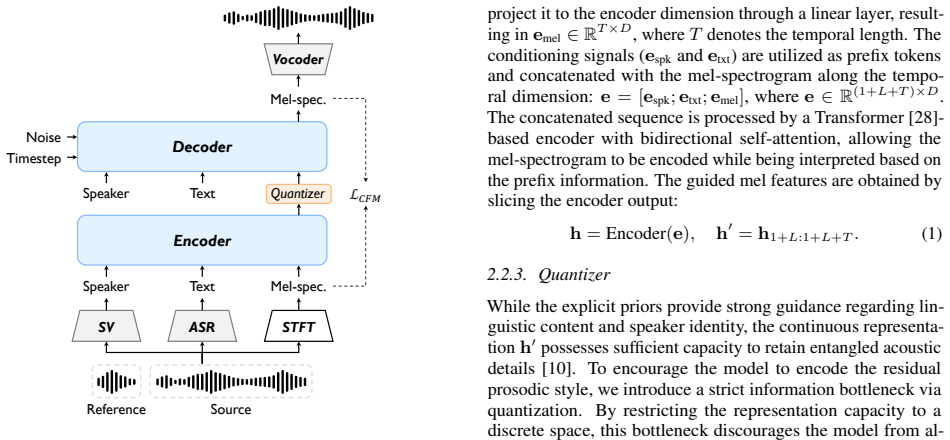
ProsoCodec models prosody as a conditional residual rather than as a disentangled stream. By conditioning both the encoder and decoder on text and speaker embeddings as prefix tokens, the discrete bottleneck is encouraged to capture prosodic variation not explained by content and speaker. Training on the low-frequency mel band together with paired same-speaker utterances further preserves prosody, yielding improved prosody preservation and reduced source-timbre leakage in voice conversion.
What carries the argument
Prefix-token conditioning of the encoder and decoder on text and speaker embeddings, which forces the discrete bottleneck to encode residual prosody.
If this is right
- Voice conversion systems can retain prosody more faithfully without explicit disentanglement of streams.
- Source-speaker timbre leaks less into the converted output.
- The same conditioning principle supports other prosody-transfer tasks that rely on discrete speech codes.
Where Pith is reading between the lines
- The method may extend naturally to multilingual or cross-lingual voice conversion where content and speaker cues must be isolated from language-specific prosody.
- Pairing the codec with text-to-speech pipelines could allow finer prosody control at inference time by reusing the same prefix conditioning.
- Testing whether the residual codes remain stable under changes in recording conditions would clarify how much of the captured variation is truly prosodic.
Load-bearing premise
Conditioning the encoder and decoder on text and speaker embeddings will cause the discrete bottleneck to capture only prosodic variation not explained by content and speaker.
What would settle it
An ablation that removes the text and speaker prefix conditioning yet still shows equivalent prosody preservation and timbre leakage in voice conversion experiments.
Figures
read the original abstract
Neural speech codecs efficiently compress speech and have become a foundation for speech generation, but they are typically learned as holistic representations that intertwine linguistic content, speaker identity, and prosody. While this design is effective for zero-shot voice cloning, it hinders downstream tasks that require prosody preservation or transfer, such as voice conversion. To address this, we introduce ProsoCodec, a prosody-oriented speech codec that models prosody as a conditional residual rather than as a disentangled stream. Specifically, by conditioning both the encoder and decoder on text and speaker embeddings as prefix tokens, the discrete bottleneck is encouraged to capture prosodic variation not explained by content and speaker. To further preserve prosody, we use the low-frequency mel band and train the model on paired same-speaker utterances. Experiments on voice conversion show improved prosody preservation and reduced source-timbre leakage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ProsoCodec, a prosody-oriented neural speech codec that conditions both the encoder and decoder on text and speaker embeddings as prefix tokens so that the discrete bottleneck encodes only residual prosodic variation not explained by content or speaker. Additional design choices include restricting input to the low-frequency mel band and training on paired same-speaker utterances. Voice-conversion experiments are reported to demonstrate improved prosody preservation together with reduced source-timbre leakage.
Significance. If the prefix-conditioning mechanism reliably isolates prosody, the approach would offer a practical alternative to full disentanglement for prosody-transfer tasks and could strengthen the utility of discrete codecs in downstream speech generation pipelines.
major comments (2)
- [Abstract] Abstract: the claim of 'improved prosody preservation and reduced source-timbre leakage' is stated without any quantitative metrics, baselines, dataset sizes, or statistical details, rendering the experimental support impossible to evaluate.
- [Method] Method section (conditioning mechanism): the central claim that prefix tokens on text and speaker embeddings cause the discrete codes to capture only unexplained prosody rests on the unverified assumption that these embeddings fully account for all non-prosodic factors; no ablation studies, residual mutual-information measurements, or regression analyses are described to quantify residual entanglement with style, recording artifacts, or other confounders.
minor comments (1)
- [Abstract] The abstract would benefit from a concise statement of the key numerical results (e.g., prosody metrics and timbre-leakage scores) to allow readers to gauge the magnitude of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point to the major comments below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'improved prosody preservation and reduced source-timbre leakage' is stated without any quantitative metrics, baselines, dataset sizes, or statistical details, rendering the experimental support impossible to evaluate.
Authors: We agree that the abstract would be strengthened by quantitative details. In the revised manuscript we will add the key metrics from the voice-conversion experiments (prosody similarity and timbre-leakage scores), the dataset sizes, and the main baselines. revision: yes
-
Referee: [Method] Method section (conditioning mechanism): the central claim that prefix tokens on text and speaker embeddings cause the discrete codes to capture only unexplained prosody rests on the unverified assumption that these embeddings fully account for all non-prosodic factors; no ablation studies, residual mutual-information measurements, or regression analyses are described to quantify residual entanglement with style, recording artifacts, or other confounders.
Authors: The prefix-conditioning design is motivated by the premise that text and speaker embeddings capture linguistic content and identity, leaving prosodic variation as the residual. While the current manuscript does not contain explicit mutual-information or regression analyses, the voice-conversion results provide empirical evidence of improved prosody preservation and reduced timbre leakage. We will add a short discussion of possible residual confounders in the revised version. revision: partial
Circularity Check
No circularity: design choice, not self-referential derivation.
full rationale
The paper describes an architectural decision to condition encoder/decoder on text and speaker prefix tokens so that the discrete codes capture residual prosody. This is an explicit modeling assumption (an ansatz) rather than a derivation or prediction that reduces to its own inputs by construction. No equations appear in the abstract or described claims, no fitted parameters are renamed as predictions, and no self-citation chain is invoked to justify uniqueness. The reported improvements are empirical outcomes from voice-conversion experiments, not tautological restatements of the conditioning. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Recent advancements in zero-shot speech generation and voice cloning have demonstrated remarkable capabilities in producing high-fidelity speech from brief reference prompts [ 1, 2, 3, 4]. Much of this progress has been driven by neural speech codecs [5, 6], which discretize continuous speech into compact tokens, serving as the foundation for...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Method 2.1. Overview Given a source utterance and a reference utterance, our voice conversion framework aims to generate speech that preserves the linguistic content and prosodic style of the source while adopt- ing the speaker timbre of the reference. Both waveforms are separately encoded by the encoder of ProsoCodec and quantized into discrete token seq...
-
[3]
Datasets Our model is trained on the LibriTTS [37] dataset, which com- prises 585 hours of 24 kHz read speech from 2,456 speakers
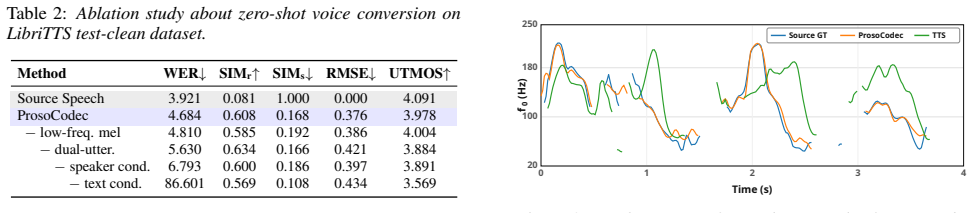
Experiments 3.1. Datasets Our model is trained on the LibriTTS [37] dataset, which com- prises 585 hours of 24 kHz read speech from 2,456 speakers. To evaluate its performance, we utilize the LibriTTStest-clean and test-other splits, alongside the VCTK dataset [38] for assessing out-of-domain generalization. From each evaluation set, we randomly sample 1,...
-
[4]
Comparisons with Previous Methods We compare ProsoCodec with several state-of-the-art open- source voice conversion models
Results 4.1. Comparisons with Previous Methods We compare ProsoCodec with several state-of-the-art open- source voice conversion models. In particular, we employ DDDM-VC [30], HierSpeech++ [ 32], and Vevo [ 10], which are resynthesis-based models that utilize decomposed speech attributes; UniAudio [31], an LLM-based unified audio gener- ation framework bu...
-
[5]
Conclusion In this paper, we presented ProsoCodec, a prosody-oriented speech codec designed for high-fidelity zero-shot voice conver- sion. Explicitly conditioned on linguistic content and speaker identity, our model effectively captures residual prosodic varia- tions without compromising speaker-conditioned nuances and expressiveness. We further introduc...
-
[6]
Acknowledgments This work was supported by Institute of Information & commu- nications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT, RS-2025-02263977, Develop- ment of Communication Platform supporting User Anonymiza- tion and Finger Spelling-Based Input Interface for Protecting the Privacy of Deaf Individuals)
2025
-
[7]
Generative AI Use Disclosure Generative AI tools were used only for editing and polishing this manuscript and were not used for producing any significant part of the manuscript
-
[8]
Neural codec language models are zero-shot text to speech synthesizers,
S. Chen, C. Wang, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Neural codec language models are zero-shot text to speech synthesizers,”IEEE/ACM Trans. on Audio, Speech, and Language Processing, 2025
2025
-
[9]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
P. Anastassiou, J. Chen, J. Chen, Y . Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gaoet al., “Seed-tts: A family of high-quality versatile speech generation models,”arXiv preprint arXiv:2406.02430, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Autoregressive speech synthesis without vector quantization,
L. Meng, L. Zhou, S. Liu, S. Chen, B. Han, S. Hu, Y . Liu, J. Li, S. Zhao, X. Wuet al., “Autoregressive speech synthesis without vector quantization,” inProc. ACL, 2025
2025
-
[11]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Z. Du, C. Gao, Y . Wang, F. Yu, T. Zhao, H. Wang, X. Lv, H. Wang, C. Ni, X. Shiet al., “Cosyvoice 3: Towards in-the- wild speech generation via scaling-up and post-training,”arXiv preprint arXiv:2505.17589, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
High fidelity neural audio compression,
A. D´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”Trans. on Machine Learning Research, 2023
2023
-
[13]
Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,
S. Ji, Z. Jiang, W. Wang, Y . Chen, M. Fang, J. Zuo, Q. Yang, X. Cheng, Z. Wang, R. Liet al., “Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,” in Proc. ICLR, 2025
2025
-
[14]
V oice- craft: Zero-shot speech editing and text-to-speech in the wild,
P. Peng, P.-Y . Huang, D. Li, A. Mohamed, and D. Harwath, “V oice- craft: Zero-shot speech editing and text-to-speech in the wild,” in Proc. ACL, 2024
2024
-
[15]
Llasa: Scaling train-time and inference-time compute for llama-based speech synthesis,
Z. Ye, X. Zhu, C.-M. Chan, X. Wang, X. Tan, J. Lei, Y . Peng, H. Liu, Y . Jin, Z. Daiet al., “Llasa: Scaling train-time and inference-time compute for llama-based speech synthesis,”arXiv preprint arXiv:2502.04128, 2025
-
[16]
Naturalspeech 3: Zero-shot speech syn- thesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tanget al., “Naturalspeech 3: Zero-shot speech syn- thesis with factorized codec and diffusion models,” inProc. ICML, 2024
2024
-
[17]
Vevo: Controllable zero-shot voice imitation with self-supervised disentanglement,
X. Zhang, X. Zhang, K. Peng, Z. Tang, V . Manohar, Y . Liu, J. Hwang, D. Li, Y . Wang, J. Chanet al., “Vevo: Controllable zero-shot voice imitation with self-supervised disentanglement,” in Proc. ICLR, 2025
2025
-
[18]
One-shot voice conversion using star-gan,
R. Wang, Y . Ding, L. Li, and C. Fan, “One-shot voice conversion using star-gan,” inProc. ICASSP, 2020
2020
-
[19]
Speech resynthesis from discrete disentangled self-supervised representations,
A. Polyak, Y . Adi, J. Copet, E. Kharitonov, K. Lakhotia, W.-N. Hsu, A. Mohamed, and E. Dupoux, “Speech resynthesis from discrete disentangled self-supervised representations,” inProc. Interspeech, 2021
2021
-
[20]
Neural analysis and synthesis: Reconstructing speech from self-supervised representations,
H.-S. Choi, J. Lee, W. Kim, J. Lee, H. Heo, and K. Lee, “Neural analysis and synthesis: Reconstructing speech from self-supervised representations,” inNeurIPS, 2021
2021
-
[21]
Unsupervised speech decomposition via triple information bottle- neck,
K. Qian, Y . Zhang, S. Chang, M. Hasegawa-Johnson, and D. Cox, “Unsupervised speech decomposition via triple information bottle- neck,” inProc. ICML, 2020
2020
-
[22]
Towards end-to- end prosody transfer for expressive speech synthesis with tacotron,
R. Skerry-Ryan, E. Battenberg, Y . Xiao, Y . Wang, D. Stanton, J. Shor, R. Weiss, R. Clark, and R. A. Saurous, “Towards end-to- end prosody transfer for expressive speech synthesis with tacotron,” inProc. ICML, 2018
2018
-
[23]
Disentanglement of prosody representations via diffusion models and scheduled gradient reversal,
L. Qu, C. Weber, W. Wang, J. Jin, Y . Gao, T. Li, and S. Wermter, “Disentanglement of prosody representations via diffusion models and scheduled gradient reversal,”IEEE Trans. Neural Networks and Learning Systems, 2025
2025
-
[24]
Single-codec: Single-codebook speech codec towards high-performance speech generation,
H. Li, L. Xue, H. Guo, X. Zhu, Y . Lv, L. Xie, Y . Chen, H. Yin, and Z. Li, “Single-codec: Single-codebook speech codec towards high-performance speech generation,” inProc. Interspeech, 2024
2024
-
[25]
Scaling transformers for low-bitrate high-quality speech coding,
J. D. Parker, A. Smirnov, J. Pons, C. Carr, Z. Zukowski, Z. Evans, and X. Liu, “Scaling transformers for low-bitrate high-quality speech coding,” inProc. ICLR, 2025
2025
-
[26]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProc. ICML, 2023
2023
-
[27]
X. Shi, X. Wang, Z. Guo, Y . Wang, P. Zhang, X. Zhang, Z. Guo, H. Hao, Y . Xi, B. Yanget al., “Qwen3-asr technical report,”arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, 2022
2022
-
[29]
Cam++: A fast and efficient network for speaker verification using context- aware masking,
H. Wang, S. Zheng, Y . Chen, L. Cheng, and Q. Chen, “Cam++: A fast and efficient network for speaker verification using context- aware masking,” inProc. Interspeech, 2023
2023
-
[30]
Tadi- codec: Text-aware diffusion speech tokenizer for speech language modeling,
Y . Wang, D. Chen, X. Zhang, J. Zhang, J. Li, and Z. Wu, “Tadi- codec: Text-aware diffusion speech tokenizer for speech language modeling,” inNeurIPS, 2025
2025
-
[31]
Scaling speech tokenizers with diffusion autoencoders,
Y . Wang, Z. Tang, Y . Wang, A. Hinsvark, Y . Liu, Y . Li, K. Peng, J. Ao, M. Ma, M. Seltzeret al., “Scaling speech tokenizers with diffusion autoencoders,” inProc. ICLR, 2025
2025
-
[32]
Prosospeech: Enhancing prosody with quantized vector pre-training in text-to-speech,
Y . Ren, M. Lei, Z. Huang, S. Zhang, Q. Chen, Z. Yan, and Z. Zhao, “Prosospeech: Enhancing prosody with quantized vector pre-training in text-to-speech,” inProc. ICASSP, 2022
2022
-
[33]
Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias,
Z. Jiang, Y . Ren, Z. Ye, J. Liu, C. Zhang, Q. Yang, S. Ji, R. Huang, C. Wang, X. Yinet al., “Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias,”arXiv preprint arXiv:2306.03509, 2023
-
[34]
A unified neural codec language model for selective editable text to speech generation,
H. Pei, S. Liu, Y . Liu, J. Yu, Y . Qian, G. Huang, S. Zhao, and Y . Lu, “A unified neural codec language model for selective editable text to speech generation,”arXiv preprint arXiv:2601.12480, 2026
-
[35]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inNeurIPS, 2017
2017
-
[36]
Image and video tokeniza- tion with binary spherical quantization,
Y . Zhao, Y . Xiong, and P. Kr¨ahenb¨uhl, “Image and video tokeniza- tion with binary spherical quantization,” inProc. ICLR, 2025
2025
-
[37]
Dddm-vc: Decoupled denoising diffusion models with disentangled representation and prior mixup for verified robust voice conversion,
H.-Y . Choi, S.-H. Lee, and S.-W. Lee, “Dddm-vc: Decoupled denoising diffusion models with disentangled representation and prior mixup for verified robust voice conversion,” inProc. AAAI, 2024
2024
-
[38]
Uniaudio: An audio foundation model toward universal audio generation,
D. Yang, J. Tian, X. Tan, R. Huang, S. Liu, X. Chang, J. Shi, S. Zhao, J. Bian, X. Wuet al., “Uniaudio: An audio foundation model toward universal audio generation,” inProc. ICML, 2024
2024
-
[39]
Hierspeech++: Bridging the gap between semantic and acoustic representation of speech by hierarchical variational inference for zero-shot speech synthesis,
S.-H. Lee, H.-Y . Choi, S.-B. Kim, and S.-W. Lee, “Hierspeech++: Bridging the gap between semantic and acoustic representation of speech by hierarchical variational inference for zero-shot speech synthesis,”IEEE Trans. Neural Networks and Learning Systems, 2025
2025
-
[40]
Zero-shot voice conversion with diffusion transformers,
S. Liu, “Zero-shot voice conversion with diffusion transformers,” arXiv preprint arXiv:2411.09943, 2024
-
[41]
Scalable diffusion models with transform- ers,
W. Peebles and S. Xie, “Scalable diffusion models with transform- ers,” inProc. ICCV, 2023
2023
-
[42]
V oice- box: Text-guided multilingual universal speech generation at scale,
M. Le, A. Vyas, B. Shi, B. Karrer, L. Sari, R. Moritz, M. Williamson, V . Manohar, Y . Adi, J. Mahadeokaret al., “V oice- box: Text-guided multilingual universal speech generation at scale,” inNeurIPS, 2023
2023
-
[43]
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. Zhao, K. Yu, and X. Chen, “F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,” inProc. ACL, 2025
2025
-
[44]
Libritts: A corpus derived from librispeech for text- to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text- to-speech,” inProc. Interspeech, 2019
2019
-
[45]
Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92),
J. Yamagishi, C. Veaux, and K. MacDonald, “Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92),” 2019
2019
-
[46]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inProc. ICLR, 2019
2019
-
[47]
V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis,
H. Siuzdak, “V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis,” in Proc. ICLR, 2024
2024
-
[48]
Speechbertscore: Reference-aware automatic evaluation of speech generation leveraging nlp evaluation metrics,
T. Saeki, S. Maiti, S. Takamichi, S. Watanabe, and H. Saruwatari, “Speechbertscore: Reference-aware automatic evaluation of speech generation leveraging nlp evaluation metrics,” inProc. Interspeech, 2024
2024
-
[49]
A high-performance fundamental frequency estimator from speech signals,
M. Morise, “A high-performance fundamental frequency estimator from speech signals,” inProc. Interspeech, 2017
2017
-
[50]
Utmos: Utokyo-sarulab system for voicemos chal- lenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos chal- lenge 2022,” inProc. Interspeech, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.