Slipstream: Locality-Aware Graph Index Construction for Streaming Approximate Nearest Neighbor Search
Pith reviewed 2026-06-28 08:42 UTC · model grok-4.3
The pith
Slipstream accelerates streaming approximate nearest neighbor search by starting each new insertion from candidates found during the previous insertion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
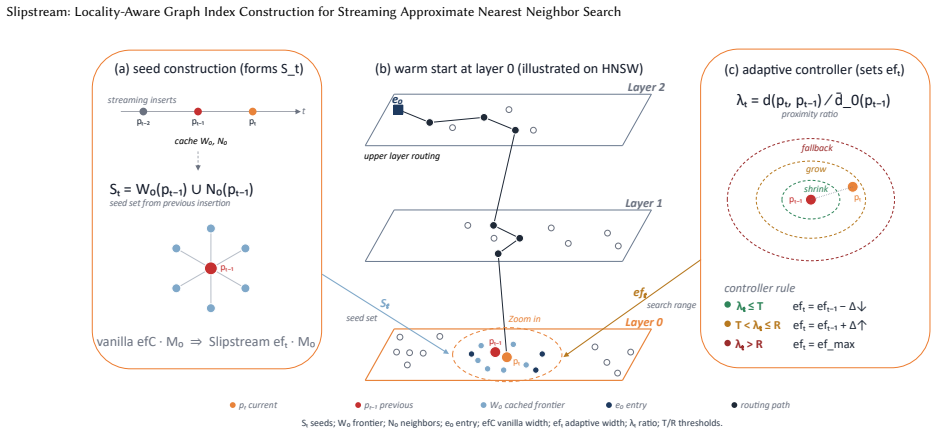
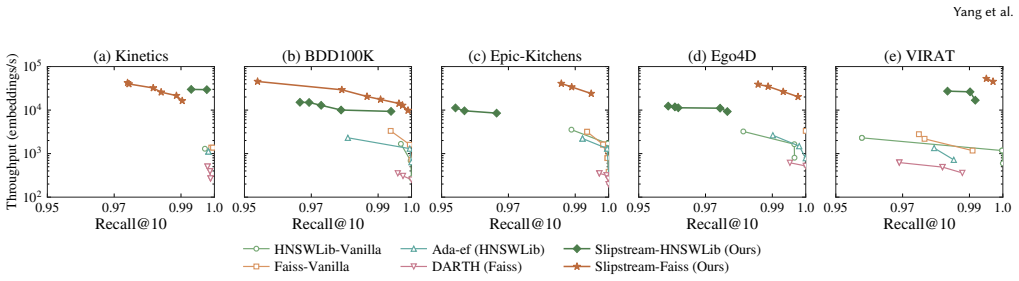
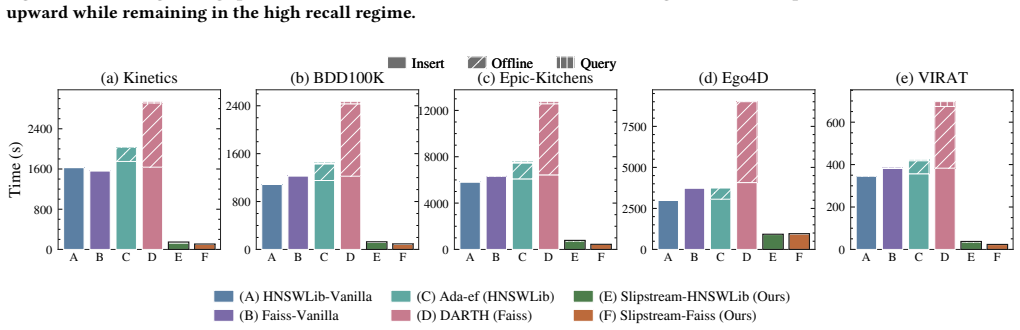
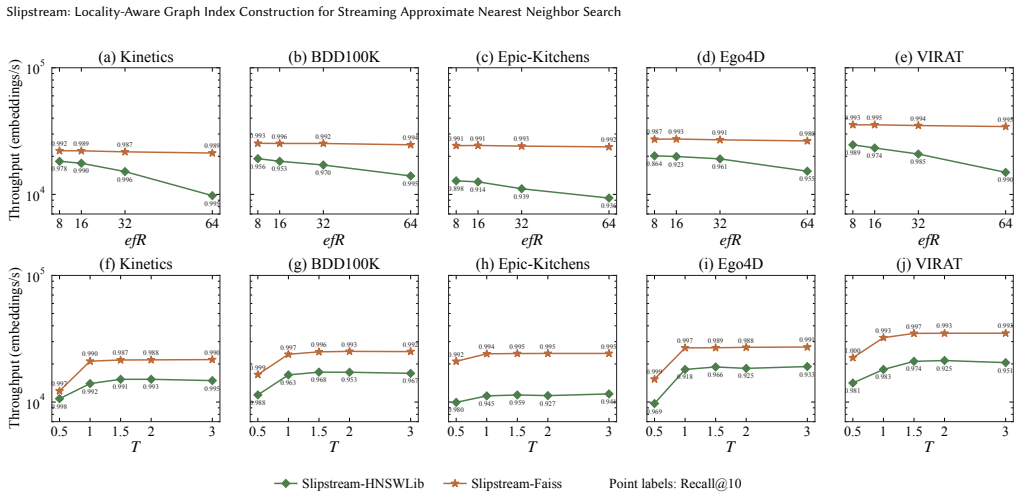
Slipstream exploits the continuity in vector streams so that a newly arrived point begins its neighbor search from candidates identified during the immediately preceding insertion rather than from the entry point. An adaptive controller then narrows or widens the candidate set according to the observed stability of the stream. The approach is backed by an abstract model that characterizes performance and derives theoretical bounds, and empirical tests in Faiss and HNSWLib show up to 30.8 times higher end-to-end throughput at no less than 0.95 recall@10 across five streaming datasets.
What carries the argument
Reuse of prior-insertion candidates as starting points, modulated by an adaptive controller that responds to stream stability.
If this is right
- Throughput improves by up to 30.8 times over standard insertion methods.
- Recall at 10 remains at least 0.95.
- The technique integrates into existing libraries such as Faiss and HNSWLib.
- Performance is characterized by an abstract model with theoretical bounds.
- It applies across five different streaming vector datasets.
Where Pith is reading between the lines
- The same locality principle could apply to other index structures that rely on repeated searches during updates.
- Sudden changes in data distribution might require more aggressive adaptation of the controller to maintain gains.
- The model might allow pre-tuning of parameters for expected stream characteristics without extensive testing.
- Energy use in continuous data ingestion systems could decrease proportionally to the throughput increase.
Load-bearing premise
The incoming vectors arrive with sufficient locality or continuity that candidates from one insertion are still useful starting points for the next.
What would settle it
Measure insertion times and recall on a deliberately randomized vector stream that lacks locality; if gains disappear or recall falls below target, the core premise fails.
Figures
read the original abstract
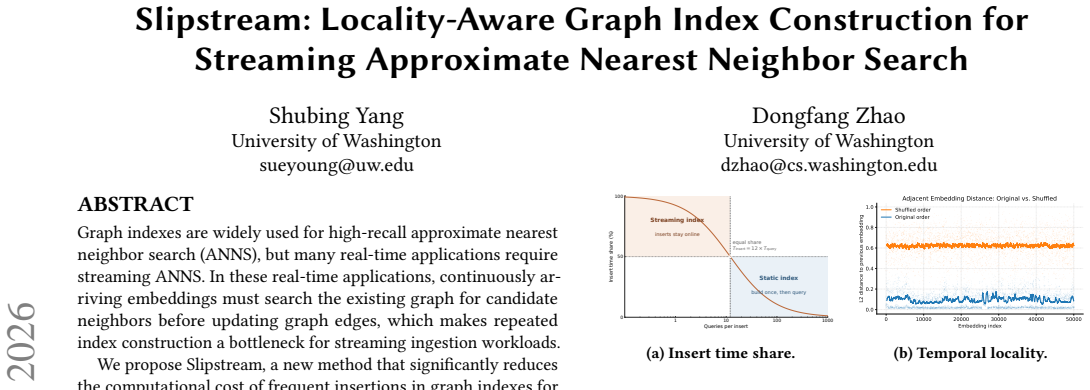
Graph indexes are widely used for high-recall approximate nearest neighbor search (ANNS), but many real-time applications require streaming ANNS. In these real-time applications, continuously arriving embeddings must search the existing graph for candidate neighbors before updating graph edges, which makes repeated index construction a bottleneck for streaming ingestion workloads. We propose Slipstream, a new method that significantly reduces the computational cost of frequent insertions in graph indexes for ANNS. The core idea of Slipstream is exploiting the continuity in vector streams: the newly arrived point starts from promising candidates found during the previous insertion rather than searching from the entry point. More technically, Slipstream evaluates distinct subsets of starting candidates followed by an adaptive controller that narrows or widens the range according to the stream's stability. We further show that Slipstream is beyond heuristic: We derive an abstract model to characterize Slipstream's performance and analyze its theoretical bounds. We have implemented Slipstream in two popular open-source libraries (Faiss, HNSWLib) and compared it with four baseline methods on five streaming vector datasets. Experimental results show that Slipstream achieves up to 30.8$\times$ higher end-to-end throughput than baselines while maintaining at least 0.95 recall@10.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Slipstream, a method for efficient graph index construction in streaming ANNS. It exploits continuity in incoming vector streams by initiating searches for new points from candidates identified during the immediately preceding insertion (rather than from the entry point), modulated by an adaptive controller that adjusts search width based on stream stability. An abstract performance model and theoretical bounds are derived to characterize the approach. Slipstream is implemented in Faiss and HNSWLib and evaluated against four baselines on five streaming vector datasets, claiming up to 30.8× higher end-to-end throughput while maintaining ≥0.95 recall@10.
Significance. If the locality assumption holds, the result would offer a practical advance for real-time streaming ANNS workloads by reducing the cost of repeated insertions. Strengths include the implementation in two widely used open-source libraries and evaluation across five datasets; the derivation of an abstract model and theoretical bounds is also a positive contribution that moves beyond pure heuristics.
major comments (1)
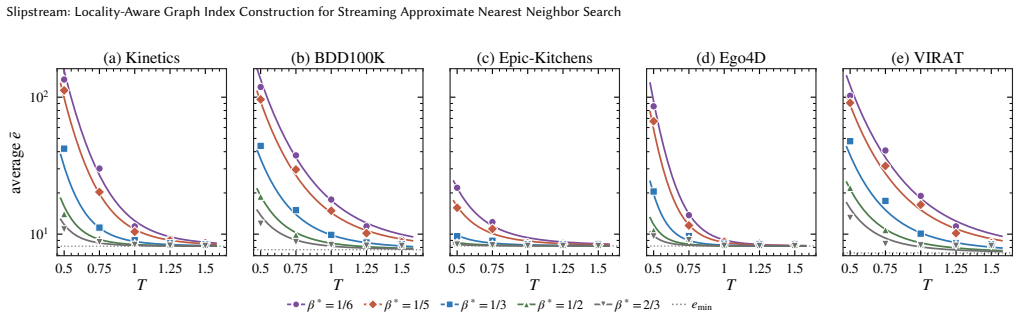
- [Abstract and Experiments] Abstract (performance claim) and Experiments section: the reported 30.8× throughput gain at ≥0.95 recall@10 is conditional on the incoming stream exhibiting sufficient locality/continuity so that prior-insertion candidates remain effective starting points. No ablation on low-locality streams, adversarially ordered streams, or datasets violating this continuity is presented; this assumption is load-bearing for the central claim and its generalizability.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting both the strengths of the work and the importance of clarifying the locality assumption. We address the major comment below and will revise the manuscript to improve the presentation of the assumption's role and its impact on generalizability.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract (performance claim) and Experiments section: the reported 30.8× throughput gain at ≥0.95 recall@10 is conditional on the incoming stream exhibiting sufficient locality/continuity so that prior-insertion candidates remain effective starting points. No ablation on low-locality streams, adversarially ordered streams, or datasets violating this continuity is presented; this assumption is load-bearing for the central claim and its generalizability.
Authors: We agree that the reported gains are conditional on stream locality, as stated in the manuscript's core idea ('exploiting the continuity in vector streams') and the abstract. The adaptive controller is designed to detect instability and fall back toward standard search behavior, but we acknowledge that this was not explicitly validated with ablations on low-locality or adversarially ordered streams. In the revision we will add such experiments (using permuted or shuffled versions of the existing datasets plus one additional low-locality synthetic stream) to quantify degradation and demonstrate the controller's mitigation effect. We will also revise the abstract to explicitly note that the 30.8× figure is the maximum observed under locality-preserving streams while maintaining the ≥0.95 recall@10 target. revision: yes
Circularity Check
No circularity: derivation remains independent of fitted inputs or self-citations
full rationale
The abstract describes deriving an abstract performance model and theoretical bounds for Slipstream after presenting the core locality-exploitation heuristic. No equations, parameter fits, or self-citations are supplied that would reduce any bound or prediction to the input data or to a prior self-citation by construction. The method's claimed advantage rests on an external empirical assumption (stream continuity) that is evaluated on five datasets rather than being tautological with the model itself. Because no load-bearing step collapses to a renaming, a fitted parameter, or an unverified self-citation chain, the derivation chain is self-contained against the supplied text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alexandr Andoni, Piotr Indyk, Thijs Laarhoven, Ilya Razenshteyn, and Ludwig Schmidt. 2015. Practical and optimal LSH for angular distance.Advances in neural information processing systems28 (2015)
2015
-
[2]
Laszlo A. Belady. 1966. A study of replacement algorithms for a virtual-storage computer.IBM Systems journal5, 2 (1966), 78–101
1966
-
[3]
Jon Louis Bentley. 1975. Multidimensional binary search trees used for associative searching.Commun. ACM18, 9 (1975), 509–517. Slipstream: Locality-Aware Graph Index Construction for Streaming Approximate Nearest Neighbor Search
1975
-
[4]
Alina Beygelzimer, Sham Kakade, and John Langford. 2006. Cover trees for nearest neighbor. InProceedings of the 23rd international conference on Machine learning. 97–104
2006
-
[5]
Thomas Brox, Andrés Bruhn, Nils Papenberg, and Joachim Weickert. 2004. High accuracy optical flow estimation based on a theory for warping. InEuropean conference on computer vision. Springer, 25–36
2004
-
[6]
Berkant Barla Cambazoglu, Flavio P Junqueira, Vassilis Plachouras, Scott Bana- chowski, Baoqiu Cui, Swee Lim, and Bill Bridge. 2010. A refreshing perspective of search engine caching. InProceedings of the 19th international conference on World wide web. 181–190
2010
-
[7]
Joao Carreira and Andrew Zisserman. 2017. Quo vadis, action recognition? a new model and the kinetics dataset. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6299–6308
2017
-
[8]
Manos Chatzakis, Yannis Papakonstantinou, and Themis Palpanas. 2025. Darth: Declarative recall through early termination for approximate nearest neighbor search.Proceedings of the ACM on Management of Data3, 4 (2025), 1–26
2025
-
[9]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems. 191–198
2016
-
[10]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. 2020. The EPIC-KITCHENS Dataset: Collection, Challenges and Baselines. arXiv:2005.00343 [cs.CV] https://arxiv.org/abs/2005. 00343
arXiv 2020
-
[11]
Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab S Mirrokni. 2004. Locality- sensitive hashing scheme based on p-stable distributions. InProceedings of the twentieth annual symposium on Computational geometry. 253–262
2004
-
[12]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. (2024). arXiv:2401.08281 [cs.LG]
Pith/arXiv arXiv 2024
-
[13]
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. 2019. Slow- fast networks for video recognition. InProceedings of the IEEE/CVF international conference on computer vision. 6202–6211
2019
-
[14]
Cong Fu and Deng Cai. 2016. Efanna: An extremely fast approximate nearest neighbor search algorithm based on knn graph.arXiv preprint arXiv:1609.07228 (2016)
Pith/arXiv arXiv 2016
-
[15]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2017. Fast approximate nearest neighbor search with the navigating spreading-out graph.arXiv preprint arXiv:1707.00143(2017)
arXiv 2017
-
[16]
Junhao Gan, Jianlin Feng, Qiong Fang, and Wilfred Ng. 2012. Locality-sensitive hashing scheme based on dynamic collision counting. InProceedings of the 2012 ACM SIGMOD international conference on management of data. 541–552
2012
-
[17]
Jianyang Gao and Cheng Long. 2024. Rabitq: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search. Proceedings of the ACM on Management of Data2, 3 (2024), 1–27
2024
-
[18]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2013. Optimized product quantization.IEEE transactions on pattern analysis and machine intelligence36, 4 (2013), 744–755
2013
-
[19]
Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premku- mar Srinivasan, et al. 2023. Filtered-diskann: Graph algorithms for approximate nearest neighbor search with filters. InProceedings of the ACM Web Conference
2023
-
[20]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. 2022. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18995–19012
2022
-
[21]
Rentong Guo, Xiaofan Luan, Long Xiang, Xiao Yan, Xiaomeng Yi, Jigao Luo, Qianya Cheng, Weizhi Xu, Jiarui Luo, Frank Liu, et al. 2022. Manu: a cloud native vector database management system.arXiv preprint arXiv:2206.13843(2022)
arXiv 2022
-
[22]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating large-scale inference with anisotropic vector quantization. InInternational Conference on Machine Learning. PMLR, 3887–3896
2020
-
[23]
Ben Harwood and Tom Drummond. 2016. Fanng: Fast approximate nearest neighbour graphs. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5713–5722
2016
-
[24]
https://docs.pinecone.io/guides/get-started/overview 2026
2026
-
[25]
https://docs.weaviate.io/weaviate 2026
2026
-
[26]
https://qdrant.tech/documentation/ 2026
2026
-
[27]
Qiang Huang, Jianlin Feng, Yikai Zhang, Qiong Fang, and Wilfred Ng. 2015. Query-aware locality-sensitive hashing for approximate nearest neighbor search. Proceedings of the VLDB Endowment9, 1 (2015), 1–12
2015
-
[28]
Stratos Idreos, Stefan Manegold, and Goetz Graefe. 2012. Adaptive indexing in modern database kernels. InProceedings of the 15th International Conference on Extending Database Technology. 566–569
2012
-
[29]
Piotr Indyk and Rajeev Motwani. 1998. Approximate nearest neighbors: towards removing the curse of dimensionality. InProceedings of the Thirtieth Annual ACM Symposium on Theory of Computing(Dallas, Texas, USA)(STOC ’98). Association for Computing Machinery, New York, NY, USA, 604–613. https://doi.org/10. 1145/276698.276876
arXiv 1998
-
[30]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node.Advances in neural information pro- cessing Systems32 (2019)
2019
-
[31]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search.IEEE transactions on pattern analysis and machine intelligence33, 1 (2010), 117–128
2010
-
[32]
Mengxu Jiang, Zhi Yang, Fangyuan Zhang, Guanhao Hou, Jieming Shi, Wenchao Zhou, Feifei Li, and Sibo Wang. 2025. DIGRA: A Dynamic Graph Indexing for Approximate Nearest Neighbor Search with Range Filter.Proceedings of the ACM on Management of Data3, 3 (2025), 1–26
2025
-
[33]
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. 2017. The Kinetics Human Action Video Dataset. arXiv:1705.06950 [cs.CV] https://arxiv.org/abs/1705.06950
Pith/arXiv arXiv 2017
-
[34]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[35]
Guoliang Li, Xuanhe Zhou, Shifu Li, and Bo Gao. 2019. Qtune: A query-aware database tuning system with deep reinforcement learning.Proceedings of the VLDB Endowment12, 12 (2019), 2118–2130
2019
-
[36]
Zhonggen Li, Xiangyu Ke, Yifan Zhu, Bocheng Yu, Baihua Zheng, and Yunjun Gao
-
[37]
Scalable Graph Indexing using GPUs for Approximate Nearest Neighbor Search.Proceedings of the ACM on Management of Data3, 6 (2025), 1–27
2025
-
[38]
Adam Liska, Tomas Kocisky, Elena Gribovskaya, Tayfun Terzi, Eren Sezener, Devang Agrawal, Cyprien De Masson D’Autume, Tim Scholtes, Manzil Zaheer, Susannah Young, et al. 2022. Streamingqa: A benchmark for adaptation to new knowledge over time in question answering models. InInternational Conference on Machine Learning. PMLR, 13604–13622
2022
-
[39]
Duo Lu, Siming Feng, Jonathan Zhou, Franco Solleza, Malte Schwarzkopf, and Uğur Çetintemel. 2025. VectraFlow: Integrating Vectors into Stream Processing. In15th Annual Conference on Innovative Data Systems Research (CIDR’25). To appear. Based on the provided PDF p23-lu. pdf. Amsterdam, The Netherlands
2025
-
[40]
Qin Lv, William Josephson, Zhe Wang, Moses Charikar, and Kai Li. 2007. Multi- probe LSH: efficient indexing for high-dimensional similarity search. InProceed- ings of the 33rd international conference on Very large data bases. 950–961
2007
-
[41]
Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, and Vladimir Krylov
-
[42]
Approximate nearest neighbor algorithm based on navigable small world graphs.Information Systems45 (2014), 61–68
2014
-
[43]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transactions on pattern analysis and machine intelligence42, 4 (2018), 824–836
2018
-
[44]
Magdalen Dobson Manohar, Zheqi Shen, Guy Blelloch, Laxman Dhulipala, Yan Gu, Harsha Vardhan Simhadri, and Yihan Sun. 2024. Parlayann: Scalable and deterministic parallel graph-based approximate nearest neighbor search algo- rithms. InProceedings of the 29th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming. 270–285
2024
-
[45]
Julieta Martinez, Shobhit Zakhmi, Holger H Hoos, and James J Little. 2018. Lsq++: Lower running time and higher recall in multi-codebook quantization. In Proceedings of the European conference on computer vision (ECCV). 491–506
2018
-
[46]
Marius Muja and David G. Lowe. 2009. FAST APPROXIMATE NEAREST NEIGH- BORS WITH AUTOMATIC ALGORITHM CONFIGURATION. InProceedings of the Fourth International Conference on Computer Vision Theory and Appli- cations - Volume 1: VISAPP, (VISIGRAPP 2009). INSTICC, SciTePress, 331–340. https://doi.org/10.5220/0001787803310340
-
[47]
Marius Muja and David G Lowe. 2014. Scalable nearest neighbor algorithms for high dimensional data.IEEE transactions on pattern analysis and machine intelligence36, 11 (2014), 2227–2240
2014
-
[48]
Javier Vargas Munoz, Marcos A Gonçalves, Zanoni Dias, and Ricardo da S Torres
-
[49]
Hierarchical clustering-based graphs for large scale approximate nearest neighbor search.Pattern Recognition96 (2019), 106970
2019
-
[50]
Sangmin Oh, Anthony Hoogs, Amitha Perera, Naresh Cuntoor, Chia-Chih Chen, Jong Taek Lee, Saurajit Mukherjee, Jake K Aggarwal, Hyungtae Lee, Larry Davis, et al. 2011. A large-scale benchmark dataset for event recognition in surveillance video. InCVPR 2011. IEEE, 3153–3160
2011
-
[51]
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. 2023. MemGPT: towards LLMs as operating systems. (2023)
2023
-
[52]
Yu Pan, Jianxin Sun, and Hongfeng Yu. 2023. Lm-diskann: Low memory footprint in disk-native dynamic graph-based ann indexing. In2023 IEEE International Conference on Big Data (BigData). IEEE, 5987–5996
2023
-
[53]
Liana Patel, Peter Kraft, Carlos Guestrin, and Matei Zaharia. 2024. Acorn: Per- formant and predicate-agnostic search over vector embeddings and structured Yang et al. data.Proceedings of the ACM on Management of Data2, 3 (2024), 1–27
2024
-
[54]
Yun Peng, Byron Choi, Tsz Nam Chan, Jianye Yang, and Jianliang Xu. 2023. Efficient approximate nearest neighbor search in multi-dimensional databases. Proceedings of the ACM on Management of Data1, 1 (2023), 1–27
2023
-
[55]
Runwen Qiu and Jing Tang. 2025. Efficient Approximate Nearest Neighbor Search via Hemi-Sphere Centroids Graph.Proceedings of the ACM on Management of Data3, 6 (2025), 1–26
2025
-
[56]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[57]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[58]
Patricia Correia Saraiva, Edleno Silva de Moura, Nivio Ziviani, Wagner Meira, Rodrigo Fonseca, and Berthier Ribeiro-Neto. 2001. Rank-preserving two-level caching for scalable search engines. InProceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval. 51– 58
2001
-
[59]
Chanop Silpa-Anan and Richard Hartley. 2008. Optimised KD-trees for fast image descriptor matching. In2008 IEEE conference on computer vision and pattern recognition. IEEE, 1–8
2008
-
[60]
Aditi Singh, Suhas Jayaram Subramanya, Ravishankar Krishnaswamy, and Har- sha Vardhan Simhadri. 2021. Freshdiskann: A fast and accurate graph-based ann index for streaming similarity search.arXiv preprint arXiv:2105.09613(2021)
arXiv 2021
-
[61]
Sivic and Zisserman. 2003. Video Google: A text retrieval approach to object matching in videos. InProceedings ninth IEEE international conference on computer vision. IEEE, 1470–1477
2003
-
[62]
Yifang Sun, Wei Wang, Jianbin Qin, Ying Zhang, and Xuemin Lin. 2014. SRS: solving c-approximate nearest neighbor queries in high dimensional euclidean space with a tiny index.Proceedings of the VLDB Endowment(2014)
2014
-
[63]
Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc Le, et al. 2024. Freshllms: Refreshing large language models with search engine augmentation. InFindings of the Association for Computational Linguistics: ACL 2024. 13697–13720
2024
-
[64]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A purpose-built vector data management system. InProceedings of the 2021 international conference on management of data. 2614–2627
2021
-
[65]
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. 2016. Temporal segment networks: Towards good practices for deep action recognition. InEuropean conference on computer vision. Springer, 20–36
2016
-
[66]
Mengzhao Wang, Weizhi Xu, Xiaomeng Yi, Songlin Wu, Zhangyang Peng, Xi- angyu Ke, Yunjun Gao, Xiaoliang Xu, Rentong Guo, and Charles Xie. 2024. Star- ling: An i/o-efficient disk-resident graph index framework for high-dimensional vector similarity search on data segment.Proceedings of the ACM on Management of Data2, 1 (2024), 1–27
2024
-
[67]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A com- prehensive survey and experimental comparison of graph-based approximate nearest neighbor search.arXiv preprint arXiv:2101.12631(2021)
arXiv 2021
-
[68]
Chuangxian Wei, Bin Wu, Sheng Wang, Renjie Lou, Chaoqun Zhan, Feifei Li, and Yuanzhe Cai. 2020. AnalyticDB-V: A Hybrid Analytical Engine Towards Query Fusion for Structured and Unstructured Data.Proc. VLDB Endow.13, 12 (2020), 3152–3165
2020
-
[69]
Haike Xu, Magdalen Dobson Manohar, Philip A Bernstein, Badrish Chandramouli, Richard Wen, and Harsha Vardhan Simhadri. 2025. In-place updates of a graph index for streaming approximate nearest neighbor search.arXiv preprint arXiv:2502.13826(2025)
arXiv 2025
-
[70]
Yuming Xu, Hengyu Liang, Jin Li, Shuotao Xu, Qi Chen, Qianxi Zhang, Cheng Li, Ziyue Yang, Fan Yang, Yuqing Yang, et al. 2023. Spfresh: Incremental in-place update for billion-scale vector search. InProceedings of the 29th Symposium on Operating Systems Principles. 545–561
2023
-
[71]
Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. 2018. Graph convolutional neural networks for web-scale recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 974–983
2018
-
[72]
Fisher Yu, Haofeng Chen, Xin Wang, Wenqi Xian, Yingying Chen, Fangchen Liu, Vashisht Madhavan, and Trevor Darrell. 2020. BDD100K: A Diverse Driv- ing Dataset for Heterogeneous Multitask Learning. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2020
-
[73]
Song Yu, Shengyuan Lin, Shufeng Gong, Yongqing Xie, Ruicheng Liu, Yijie Zhou, Ji Sun, Yanfeng Zhang, Guoliang Li, and Ge Yu. 2025. A topology-aware localized update strategy for graph-based ann index.Proceedings of the VLDB Endowment 19, 3 (2025), 495–508
2025
-
[74]
Bohan Zhang, Dana Van Aken, Justin Wang, Tao Dai, Shuli Jiang, Jacky Lao, Siyuan Sheng, Andrew Pavlo, and Geoffrey J Gordon. 2018. A demonstration of the ottertune automatic database management system tuning service.Proceedings of the VLDB Endowment11, 12 (2018), 1910–1913
2018
-
[75]
Chao Zhang and Renée J Miller. 2025. Distribution-Aware Exploration for Adap- tive HNSW Search.arXiv preprint arXiv:2512.06636(2025)
arXiv 2025
-
[76]
Ji Zhang, Yu Liu, Ke Zhou, Guoliang Li, Zhili Xiao, Bin Cheng, Jiashu Xing, Yangtao Wang, Tianheng Cheng, Li Liu, et al. 2019. An end-to-end automatic cloud database tuning system using deep reinforcement learning. InProceedings of the 2019 international conference on management of data. 415–432
2019
-
[77]
Qianxi Zhang, Shuotao Xu, Qi Chen, Guoxin Sui, Jiadong Xie, Zhizhen Cai, Yaoqi Chen, Yinxuan He, Yuqing Yang, Fan Yang, et al . 2023. {VBASE}: Unifying online vector similarity search and relational queries via relaxed monotonicity. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). 377–395
2023
-
[78]
Ziyu Zhang, Yuanhao Wei, Joshua Engels, and Julian Shun. 2025. CleANN: Efficient Full Dynamism in Graph-based Approximate Nearest Neighbor Search. arXiv preprint arXiv:2507.19802(2025)
arXiv 2025
-
[79]
Shurui Zhong, Dingheng Mo, and Siqiang Luo. 2025. Lsm-vec: A large-scale disk-based system for dynamic vector search.arXiv preprint arXiv:2505.17152 (2025)
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.