Deterministic access to global viral sequence data enables robust agentic scientific discovery
Pith reviewed 2026-06-27 22:27 UTC · model grok-4.3
The pith
A deterministic retrieval framework for viral genomes raises AI agent accuracy from 17% to at least 90%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
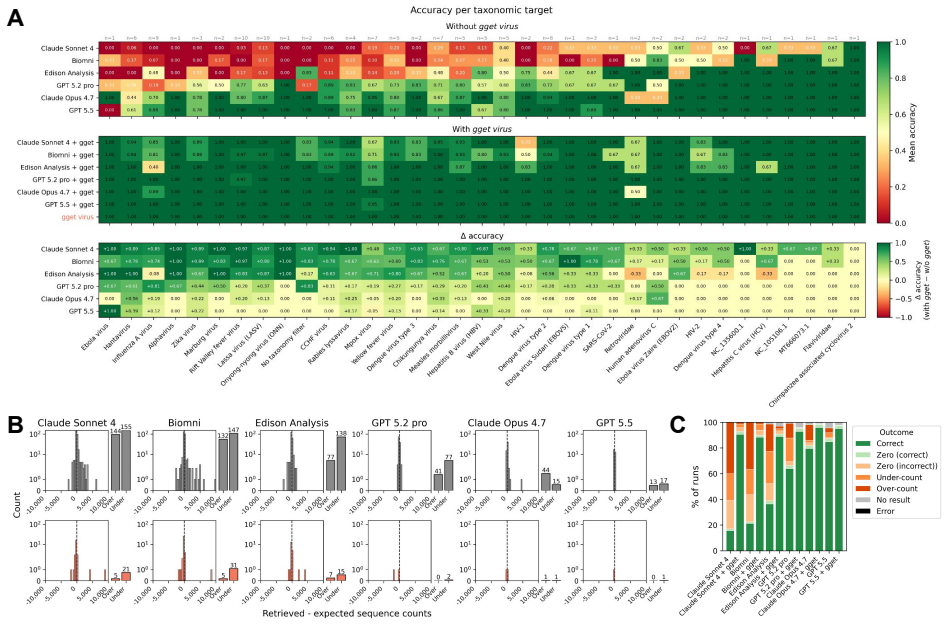
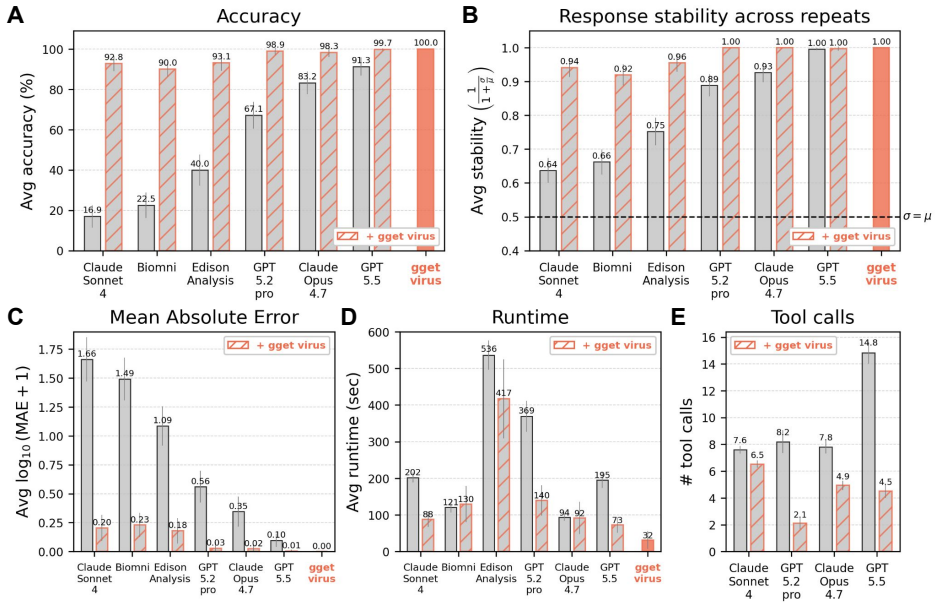
Instructing autonomous AI systems to use gget virus increased accuracy to at least 90.0% across all evaluated systems and up to 99.7% for GPT-5.5, improved response stability to 0.92-1.00, reduced error magnitude, and generally decreased runtime and tool calls.
What carries the argument
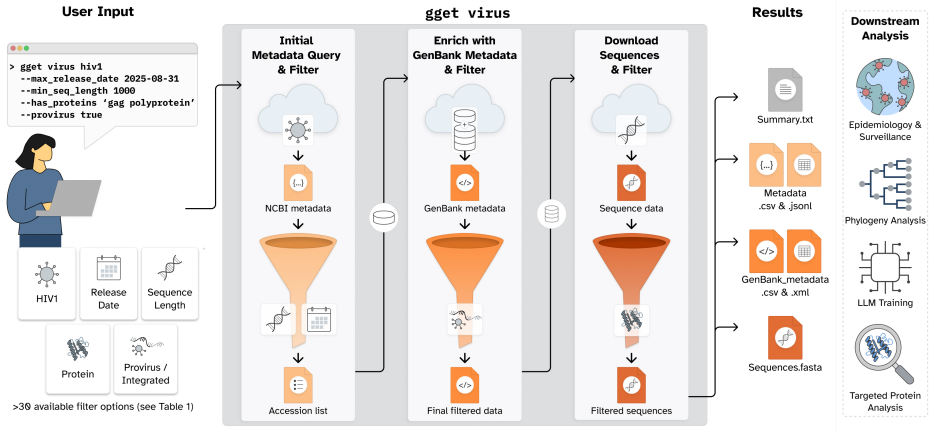
gget virus, a deterministic query framework that formalizes NCBI Virus-style filtering as a reproducible programmatic system by staging retrieval, applying metadata constraints before sequence download, and retrieving structured GenBank records.
If this is right
- AI agents can complete viral data retrieval tasks without introducing consequential errors into downstream analyses.
- High-volume queries transfer more than 98% less data while still returning exact matches.
- Both human users and AI systems gain a single reproducible layer for viral genomics workflows.
- Frontier models that already perform better still receive large further gains from the dedicated retrieval tool.
Where Pith is reading between the lines
- Comparable deterministic interfaces for other public biology databases could make agentic workflows reliable outside viruses.
- Outbreak surveillance teams could embed the same layer so AI assistants accelerate genomic analysis without manual oversight.
- Benchmarks that include queries about newly sequenced or poorly annotated pathogens would test whether the accuracy gains generalize.
Load-bearing premise
The manually curated benchmark of 120 queries spanning diverse pathogens, taxonomic levels, and metadata filters is representative of the real-world retrieval tasks that matter for viral genomics and outbreak response.
What would settle it
Running the same AI systems on a fresh set of 120 queries drawn from recent outbreak investigations that were never seen during benchmark construction and measuring whether accuracy stays above 90%.
Figures
read the original abstract
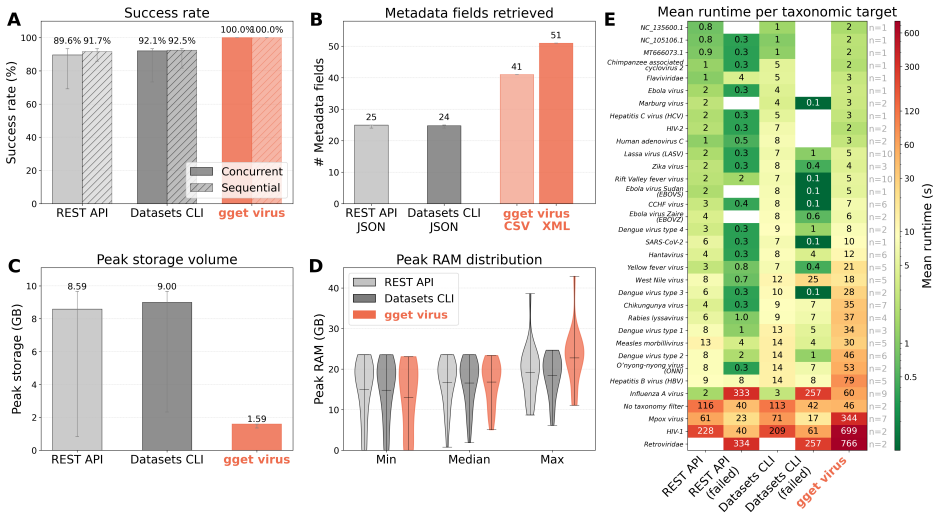
Public viral genome resources such as the National Center for Biotechnology Information (NCBI) Virus database are central to outbreak response, evolutionary analysis, vaccine design, and genomic surveillance. Yet many high-value retrieval workflows remain optimized for interactive use rather than deterministic, reproducible programmatic interfaces. This creates a challenge for Large Language Model (LLM)-based scientific agents, where errors in metadata interpretation, filtering logic, or retrieval can propagate into incorrect datasets. To evaluate agentic viral data retrieval, we built VirBench, a manually curated benchmark of 120 queries spanning diverse pathogens, taxonomic levels, and metadata filters. When autonomous AI systems, including Biomni, Claude, GPT, and Edison Analysis, were tasked with these queries without a dedicated retrieval layer, performance varied widely: mean accuracy ranged from 16.9% for Claude Sonnet 4 to 91.3% for GPT-5.5, with newer frontier models showing progress but residual errors remaining consequential. To address this, we built gget virus, a deterministic query framework that formalizes NCBI Virus-style filtering as a reproducible programmatic system. By staging retrieval, applying metadata constraints before sequence download, and retrieving structured GenBank records, gget virus reduces data transfer by more than 98% for high-volume queries while preserving exact-match semantics. Instructing autonomous AI systems to use gget virus increased accuracy to at least 90.0% across all evaluated systems and up to 99.7% for GPT-5.5, improved response stability to 0.92-1.00, reduced error magnitude, and generally decreased runtime and tool calls. Together, this work establishes deterministic data access as critical infrastructure for reliable agentic science and provides a reproducible retrieval layer for robust human- and AI-driven viral genomics workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that many LLM-based scientific agents struggle with accurate retrieval from the NCBI Virus database due to errors in metadata interpretation and filtering. To address this, the authors introduce VirBench, a manually curated set of 120 queries spanning pathogens, taxonomic levels, and metadata filters, and gget virus, a deterministic programmatic retrieval layer that stages metadata constraints before sequence download. Experiments show baseline accuracies ranging from 16.9% (Claude Sonnet 4) to 91.3% (GPT-5.5) rising to at least 90% (up to 99.7% for GPT-5.5) when agents are instructed to use gget virus, with gains in stability (0.92-1.00), reduced error magnitude, and often lower runtime and tool calls.
Significance. If the benchmark results generalize, the work demonstrates that providing a reproducible, low-error retrieval interface can substantially improve the reliability of autonomous agents for viral genomics tasks central to outbreak response and surveillance. The emphasis on deterministic access as infrastructure for agentic science is a timely contribution, and the reduction in data transfer (>98% for high-volume queries) while preserving exact-match semantics is a practical engineering strength.
major comments (2)
- [Abstract / Methods (VirBench)] Abstract and Methods (VirBench description): The central claim that gget virus enables 'robust agentic scientific discovery' rests on performance gains measured exclusively on the 120-query VirBench benchmark. No information is supplied on the curation protocol (e.g., blinding, stratification by query complexity or taxonomic edge cases, validation against NCBI usage logs or external corpora), making it impossible to determine whether the reported lift (16.9–91.3% → ≥90%) reflects a general property of the retrieval layer or an artifact of the test distribution.
- [Results (performance metrics)] Results (accuracy and stability metrics): The abstract reports concrete accuracy, stability (0.92-1.00), and runtime numbers but supplies no definition of 'accuracy,' 'error magnitude,' or the statistical tests used to compare conditions. Without these details or verification that gget virus exactly reproduces NCBI semantics on held-out queries, the magnitude of improvement cannot be independently assessed.
minor comments (1)
- [Abstract] The abstract states that gget virus 'formalizes NCBI Virus-style filtering' but does not specify which NCBI API endpoints or metadata fields are supported versus omitted; a short table or enumerated list would clarify the scope.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for major revision. We address the two major comments point-by-point below. We agree that additional details are needed and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Methods (VirBench)] Abstract and Methods (VirBench description): The central claim that gget virus enables 'robust agentic scientific discovery' rests on performance gains measured exclusively on the 120-query VirBench benchmark. No information is supplied on the curation protocol (e.g., blinding, stratification by query complexity or taxonomic edge cases, validation against NCBI usage logs or external corpora), making it impossible to determine whether the reported lift (16.9–91.3% → ≥90%) reflects a general property of the retrieval layer or an artifact of the test distribution.
Authors: We acknowledge that the manuscript provides only a high-level description of VirBench as 'manually curated' without detailing the curation protocol. We will add a dedicated Methods subsection describing query selection criteria (covering pathogens, taxonomic ranks, and metadata filters), with examples of included edge cases. We did not perform formal blinding, explicit stratification by complexity, or validation against NCBI usage logs/external corpora; this will be stated explicitly as a limitation. The benchmark was constructed to reflect common viral genomics retrieval tasks, but the added transparency will allow readers to evaluate whether results generalize beyond the test distribution. revision: yes
-
Referee: [Results (performance metrics)] Results (accuracy and stability metrics): The abstract reports concrete accuracy, stability (0.92-1.00), and runtime numbers but supplies no definition of 'accuracy,' 'error magnitude,' or the statistical tests used to compare conditions. Without these details or verification that gget virus exactly reproduces NCBI semantics on held-out queries, the magnitude of improvement cannot be independently assessed.
Authors: We agree that explicit definitions and verification details are absent. We will revise the Results section to define accuracy as the fraction of queries for which the retrieved sequence set exactly matches the set expected under the query's metadata constraints per NCBI Virus semantics; error magnitude as the absolute count of extraneous or missing sequences; and stability as the fraction of repeated runs producing identical outputs. We will specify the statistical tests employed (e.g., paired non-parametric tests for accuracy and runtime comparisons). We will also add a verification subsection confirming that gget virus reproduces NCBI semantics on a held-out query set. These additions will enable independent assessment of the reported gains. revision: yes
Circularity Check
No significant circularity; evaluation is external to tool definition
full rationale
The paper introduces VirBench as an independently manually curated set of 120 queries and measures gget virus performance against it as an external benchmark. No equations, fitted parameters, or self-citations are used to derive the accuracy gains; the reported improvements (16.9–91.3% baseline to ≥90%) are direct empirical measurements on the stated test set. The central claim does not reduce to a self-definition, renamed result, or load-bearing self-citation chain. The benchmark's representativeness is an external-validity question, not a circularity issue within the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption NCBI Virus database metadata is accurate and sufficient for the filtering operations implemented in gget virus
invented entities (1)
-
gget virus
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Genbank.Nucleic acids research, 46(D1):D41–D47, 2018
Dennis A Benson, Mark Cavanaugh, Karen Clark, Ilene Karsch-Mizrachi, James Ostell, Kim D Pruitt, and Eric W Sayers. Genbank.Nucleic acids research, 46(D1):D41–D47, 2018
2018
-
[2]
Ncbi viral genomes resource.Nucleic acids research, 43(D1):D571–D577, 2015
J Rodney Brister, Danso Ako-Adjei, Yiming Bao, and Olga Blinkova. Ncbi viral genomes resource.Nucleic acids research, 43(D1):D571–D577, 2015
2015
-
[3]
The international nu- cleotide sequence database collaboration.Nucleic acids research, 39(suppl 1):D15–D18, 2010
Guy Cochrane, International Nucleotide Sequence Database Collaboration, Ilene Karsch- Mizrachi, International Nucleotide Sequence Database Collaboration, Yasukazu Nakamura, and International Nucleotide Sequence Database Collaboration. The international nu- cleotide sequence database collaboration.Nucleic acids research, 39(suppl 1):D15–D18, 2010
2010
-
[4]
The euro- pean nucleotide archive.Nucleic acids research, 39(suppl 1):D28–D31, 2010
Rasko Leinonen, Ruth Akhtar, Ewan Birney, Lawrence Bower, Ana Cerdeno-T´ arraga, Ying Cheng, Iain Cleland, Nadeem Faruque, Neil Goodgame, Richard Gibson, et al. The euro- pean nucleotide archive.Nucleic acids research, 39(suppl 1):D28–D31, 2010
2010
-
[5]
Dna data bank of japan (ddbj) for genome scale research in life science.Nucleic acids research, 30(1):27–30, 2002
Yoshio Tateno, Tadashi Imanishi, Satoru Miyazaki, Kaoru Fukami-Kobayashi, Naruya Saitou, Hideaki Sugawara, and Takashi Gojobori. Dna data bank of japan (ddbj) for genome scale research in life science.Nucleic acids research, 30(1):27–30, 2002
2002
-
[6]
Carter, Xin Zhou, Matthew Wheeler, Jonathan A
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, Di Yin, Shruti Marwaha, Jennefer N. Carter, Xin Zhou, Matthew Wheeler, Jonathan A. Bernstein, Mengdi Wang, Peng He, Jingtian Zhou, Michael Snyder, Le Cong, Aviv Regev, and Jure Leskovec. Biomni: A general-purpose biomedical ai agent.bi...
2025
-
[7]
Landsness, Daniel L
Ludovico Mitchener, Angela Yiu, Benjamin Chang, Mathieu Bourdenx, Tyler Nadolski, Arvis Sulovari, Eric C. Landsness, Daniel L. Barabasi, Siddharth Narayanan, Nicky Evans, Shriya Reddy, Martha Foiani, Aizad Kamal, Leah P. Shriver, Fang Cao, Asmamaw T. Wassie, Jon M. Laurent, Edwin Melville-Green, Mayk Caldas, Albert Bou, Kaleigh F. Roberts, Sladjana Zagora...
2025
-
[8]
Rapid development and field evaluation of a portable crispr-based assay for mpox during the 2025 sierra leone outbreak.medRxiv, page 2025.10.08.25337506, 2025
Nisha Gopal, Tsion Abay, Carolyn Payne, Michael Gomez, Maariam Manjia Rogers, Ibrahim Umaru Fofanah, Tiangay PMS Kallon, Mohamed S Kamara, Ho-Jun Suk, John Demby Sandi, et al. Rapid development and field evaluation of a portable crispr-based assay for mpox during the 2025 sierra leone outbreak.medRxiv, page 2025.10.08.25337506, 2025
2025
-
[9]
Establishing methods to monitor influenza (a) h5n1 virus in dairy cattle milk, massachusetts, usa
Elyse Stachler, Andreas Gnirke, Kyle McMahon, Michael Gomez, Liam Stenson, Charelisse Guevara-Reyes, Hannah Knoll, Toni Hill, Sellers Hill, Katelyn S Messer, et al. Establishing methods to monitor influenza (a) h5n1 virus in dairy cattle milk, massachusetts, usa. Emerging infectious diseases, 31(Suppl 1):S70, 2025
2025
-
[10]
Introducing edison analysis, 2025
Ludovico Mitchener, Jon Laurent, Angela Yiu, Arvis Sulovari, Conor Igoe, and Alex An- donian. Introducing edison analysis, 2025. Accessed: 2026-02-15
2025
-
[11]
Bayesian phylogenetic and phylodynamic data integration using beast 1.10.Virus evolution, 4(1):vey016, 2018
Marc A Suchard, Philippe Lemey, Guy Baele, Daniel L Ayres, Alexei J Drummond, and Andrew Rambaut. Bayesian phylogenetic and phylodynamic data integration using beast 1.10.Virus evolution, 4(1):vey016, 2018
2018
-
[12]
Nextstrain: real-time tracking of pathogen evolution.Bioinformatics, 34(23):4121–4123, 2018
James Hadfield, Colin Megill, Sidney M Bell, John Huddleston, Barney Potter, Charlton Callender, Pavel Sagulenko, Trevor Bedford, and Richard A Neher. Nextstrain: real-time tracking of pathogen evolution.Bioinformatics, 34(23):4121–4123, 2018
2018
-
[13]
Tracking virus outbreaks in the twenty-first century.Nature microbiology, 4(1):10–19, 2019
Nathan D Grubaugh, Jason T Ladner, Philippe Lemey, Oliver G Pybus, Andrew Rambaut, Edward C Holmes, and Kristian G Andersen. Tracking virus outbreaks in the twenty-first century.Nature microbiology, 4(1):10–19, 2019
2019
-
[14]
Pandemics: spend on surveillance, not prediction, 2018
Edward C Holmes, Andrew Rambaut, and Kristian G Andersen. Pandemics: spend on surveillance, not prediction, 2018
2018
-
[15]
Recommendations on data sharing in hiv drug resistance research
Seth C Inzaule, Mark J Siedner, Susan J Little, Santiago Avila-Rios, Alisen Ayitewala, Ronald J Bosch, Vincent Calvez, Francesca Ceccherini-Silberstein, Charlotte Charpentier, Diane Descamps, et al. Recommendations on data sharing in hiv drug resistance research. PLoS medicine, 20(9):e1004293, 2023
2023
-
[16]
Evaluating variant effect prediction across viruses
Sarah Gurev, Noor Youssef, Navami Jain, Aarushi Mehrotra, Sarrah Rose Mikhail Leung, Abigail Jackson, and Debora Marks. Evaluating variant effect prediction across viruses. bioRxiv, page 2025.08.04.668549, 2025
2025
-
[17]
Learning from prepandemic data to forecast viral escape.Nature, 622(7984):818–825, 2023
Nicole N Thadani, Sarah Gurev, Pascal Notin, Noor Youssef, Nathan J Rollins, Daniel Ritter, Chris Sander, Yarin Gal, and Debora S Marks. Learning from prepandemic data to forecast viral escape.Nature, 622(7984):818–825, 2023
2023
-
[18]
Want to track pandemic variants faster? fix the bioinformatics bottleneck.Nature, 591(7848):30– 33, 2021
Emma B Hodcroft, Nicola De Maio, Rob Lanfear, Duncan R MacCannell, Bui Quang Minh, Heiko A Schmidt, Alexandros Stamatakis, Nick Goldman, and Christophe Dessimoz. Want to track pandemic variants faster? fix the bioinformatics bottleneck.Nature, 591(7848):30– 33, 2021. 16
2021
-
[19]
Mpoxradar: a worldwide mpxv genomic surveillance dashboard.Nucleic Acids Research, 51(W1):W331–W337, 05 2023
Ferdous Nasri, Kunaphas Kongkitimanon, Alice Wittig, Jorge S´ anchez Cort´ es, Annika Brinkmann, Andreas Nitsche, Anna-Juliane Schmachtenberg, Bernhard Y Renard, and Stephan Fuchs. Mpoxradar: a worldwide mpxv genomic surveillance dashboard.Nucleic Acids Research, 51(W1):W331–W337, 05 2023
2023
-
[20]
Challenges and opportunities for global genomic surveillance strategies in the covid-19 era.Viruses, 14(11):2532, 2022
Ted Ling-Hu, Estefany Rios-Guzman, Ramon Lorenzo-Redondo, Egon A Ozer, and Judd F Hultquist. Challenges and opportunities for global genomic surveillance strategies in the covid-19 era.Viruses, 14(11):2532, 2022
2022
-
[21]
Unlocking capacities of genomics for the covid-19 response and future pandemics.Nature Methods, 19(4):374–380, 2022
Sergey Knyazev, Karishma Chhugani, Varuni Sarwal, Ram Ayyala, Harman Singh, Smruthi Karthikeyan, Dhrithi Deshpande, Pelin Icer Baykal, Zoia Comarova, Angela Lu, et al. Unlocking capacities of genomics for the covid-19 response and future pandemics.Nature Methods, 19(4):374–380, 2022
2022
-
[22]
Ai and biosecurity: The need for governance.Science, 385(6711):831–833, 2024
Doni Bloomfield, Jaspreet Pannu, Alex W Zhu, Madelena Y Ng, Ashley Lewis, Eran Ben- david, Steven M Asch, Tina Hernandez-Boussard, Anita Cicero, and Tom Inglesby. Ai and biosecurity: The need for governance.Science, 385(6711):831–833, 2024
2024
-
[23]
Without safeguards, ai-biology integration risks accelerating future pan- demics.Frontiers in Microbiology, 16:1734561, 2026
Dianzhuo Wang, Marian Huot, Zechen Zhang, Kaiyi Jiang, Eugene I Shakhnovich, and Kevin M Esvelt. Without safeguards, ai-biology integration risks accelerating future pan- demics.Frontiers in Microbiology, 16:1734561, 2026
2026
-
[24]
Efficient querying of genomic reference databases with gget.Bioinformatics, 39(1):btac836, 2023
Laura Luebbert and Lior Pachter. Efficient querying of genomic reference databases with gget.Bioinformatics, 39(1):btac836, 2023
2023
-
[25]
Nuala A O’Leary, Eric Cox, J Bradley Holmes, W Ray Anderson, Robert Falk, Vichet Hem, Mirian TN Tsuchiya, Gregory D Schuler, Xuan Zhang, John Torcivia, et al. Exploring and retrieving sequence and metadata for species across the tree of life with NCBI datasets. Scientific data, 11(1):732, 2024. 17 S1 Supplementary Information Supplementary Figures 18 Tabl...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.