Enhancing BEST-RQ Pseudo-Label Quality through Online Refinement for Automatic Speech Recognition
Pith reviewed 2026-07-01 06:48 UTC · model grok-4.3
The pith
Three modifications to BEST-RQ's online quantizer raise pseudo-label quality and cut word error rate by 12 percent on LibriSpeech test-other.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
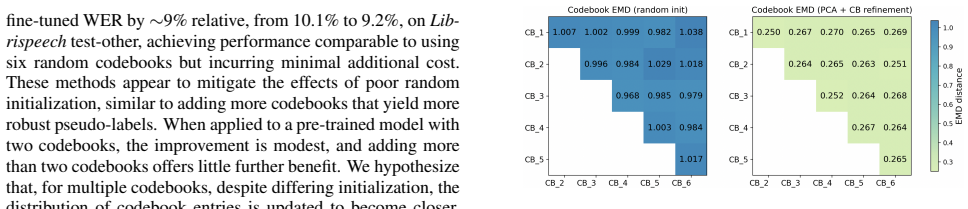
BEST-RQ generates pseudo-labels using a fixed online quantization scheme. Replacing the quantizer's linear projection with PCA, updating the codebook through iterative refinement, and adding an extra codebook updated by distillation together raise the quality of these labels. Pre-training on LibriSpeech 960 hours followed by fine-tuning on 100 hours of supervised data then yields a 12 percent relative WER reduction on the test-other set, moving from 10.1 percent to 8.8 percent.
What carries the argument
The enhanced online quantization scheme that substitutes PCA for the linear projection, performs iterative codebook refinement, and maintains a second distilled codebook to produce higher-quality pseudo-labels.
If this is right
- The modified quantizer supplies pseudo-labels that support stronger fine-tuned ASR models on the same amount of labeled data.
- The three changes preserve the simplicity of single-pass online training while narrowing the supervision gap to iterative offline methods.
- The improvements are measured after pre-training on 960 hours and fine-tuning on 100 hours of LibriSpeech, indicating the scheme works under standard data splits.
- Enabling all three modifications together produces the full 12 percent relative WER reduction; partial combinations yield smaller gains.
Where Pith is reading between the lines
- The PCA substitution hints that learned linear projections may be replaceable by classical dimensionality reduction in other quantization-based speech models.
- The distillation step for the second codebook could be tested on larger unlabeled corpora to check whether the quality gain scales with data volume.
- Because the method stays fully online, it may combine more easily with streaming or continual pre-training setups than offline label refinement pipelines.
Load-bearing premise
The observed word error rate reduction is produced by the three listed changes to the quantizer and codebooks rather than by unmentioned differences in training procedure, seeds, or hyperparameters.
What would settle it
Re-running the exact baseline BEST-RQ and the three-modification version with identical training schedules, random seeds, and hyperparameter settings and obtaining no WER difference on test-other would show the modifications are not responsible for the reported gain.
Figures

read the original abstract
BEST-RQ is a simple and effective self-supervised training method for speech representation learning that performs well on automatic speech recognition (ASR) tasks. It generates pseudolabels using a fixed online quantization scheme, which simplifies training but provides weaker supervision than HuBERT-style models that iteratively refine pseudo-labels. In this work, we improve online pseudo-label generation while preserving simplicity. We propose three modifications: replacing the quantizer's linear projection with Principal Component Analysis (PCA), updating the codebook via iterative codebook refinement, and introducing an additional codebook updated via codebook distillation. We pre-train on the LibriSpeech 960-hour dataset and fine-tune using 100 hours of supervised LibriSpeech data. With all three modifications enabled, we achieve a 12% relative reduction in word error rate (WER) on the LibriSpeech test-other set, improving from 10.1% to 8.8%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes three modifications to BEST-RQ for improving online pseudo-label quality in self-supervised speech pre-training: replacing the quantizer's linear projection with PCA, adding iterative codebook refinement, and introducing a distilled codebook. Pre-training is performed on LibriSpeech 960h with fine-tuning on 100h supervised data, yielding a claimed 12% relative WER reduction on LibriSpeech test-other (10.1% to 8.8%).
Significance. If the WER gain is shown to be caused by the three modifications under controlled conditions, the work would offer a lightweight way to strengthen online quantization without adopting full iterative refinement as in HuBERT, potentially aiding efficient ASR pre-training pipelines.
major comments (2)
- [Abstract] Abstract: the headline result (10.1% o 8.8% WER) is presented as caused by the three modifications, yet the abstract supplies no ablation table, no statement that the baseline was re-run under identical optimizer/LR/batch/seed conditions, and no statistical significance. This directly undermines attribution of the observed gain.
- [Results] Results section (presumed): without explicit confirmation that training procedure, data ordering, and random seeds were held fixed between the reported baseline and the three-modification system, the central empirical claim cannot be verified. Self-supervised speech training is known to be sensitive to these factors.
minor comments (1)
- [Abstract] Abstract: the phrase 'with all three modifications enabled' is used without reporting the individual or cumulative contributions of each change.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental attribution and controls. We address each major comment below and will revise the manuscript to improve clarity on these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline result (10.1% o 8.8% WER) is presented as caused by the three modifications, yet the abstract supplies no ablation table, no statement that the baseline was re-run under identical optimizer/LR/batch/seed conditions, and no statistical significance. This directly undermines attribution of the observed gain.
Authors: We agree the abstract is concise and would benefit from explicit context on attribution. The results section of the manuscript presents ablation studies isolating the effect of each modification (PCA projection, iterative refinement, and distillation). The 10.1% baseline reflects a re-implementation of BEST-RQ using identical optimizer, learning rate, batch size, and random seed. We will revise the abstract to reference the ablations and state that all comparisons use matched conditions. Statistical significance across multiple seeds was not computed; we can incorporate this in the revision if needed. revision: yes
-
Referee: [Results] Results section (presumed): without explicit confirmation that training procedure, data ordering, and random seeds were held fixed between the reported baseline and the three-modification system, the central empirical claim cannot be verified. Self-supervised speech training is known to be sensitive to these factors.
Authors: All experiments used identical training procedures, data ordering (via fixed data loader seeds), and the same random seed for initialization and training to ensure controlled comparison. We will add an explicit statement in the experimental setup section confirming these controls. revision: yes
Circularity Check
No circularity: empirical WER result on public benchmark with no derivation chain
full rationale
The paper's central claim is an empirical measurement: pre-training with three modifications to BEST-RQ (PCA projection, iterative refinement, distilled codebook) yields 10.1% → 8.8% WER on LibriSpeech test-other after fine-tuning on 100h supervised data. No equations, predictions, or first-principles derivations are presented that could reduce to fitted inputs or self-citations by construction. The result is a direct benchmark comparison; any confounding from training details would be an experimental-control issue, not circularity in a derivation. Self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In recent years, different SSL approaches have been proposed for the speech domain and achieved state-of-the-art performance on the down- stream ASR tasks [2, 3, 4, 5, 6, 7, 8, 9]
Introduction Self-supervised learning (SSL) can learn rich and generalizable representations from large amounts of unlabeled data by gen- erating pseudo-labels from the data itself [1]. In recent years, different SSL approaches have been proposed for the speech domain and achieved state-of-the-art performance on the down- stream ASR tasks [2, 3, 4, 5, 6, ...
-
[2]
Enhancing BEST-RQ Pseudo-Label Quality through Online Refinement for Automatic Speech Recognition
Online Pseudo-Label Refinement 2.1. BEST-RQ BEST-RQ [8] trains a model to predict masked speech segments using discrete labels derived from a fixed random projection- based quantizer. Specifically, the quantizer maps speech inputs through a randomly initialized projection matrix and assigns them to the nearest entry in a randomly generated codebook. Both ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Specifically, given N codebooks, N independent quantization targets are generated, and the model employs N softmax layers to predict them
Related Work The authors of [11] propose a simple approach that uses mul- tiple codebooks instead of a single one. Specifically, given N codebooks, N independent quantization targets are generated, and the model employs N softmax layers to predict them. The loss for each prediction is then scaled by a factor of 1 N . This formulation effectively ensembles...
-
[4]
Setup We use BEST-RQ [8] for unsupervised pre-training and use an implementation based on [22]
Experiments 4.1. Setup We use BEST-RQ [8] for unsupervised pre-training and use an implementation based on [22]. The encoder consists of a VGG front-end and 12 Conformer [17] blocks. We use 80- dimensional log-Mel filterbank features with a 10ms frame shift as input. The features are normalized to zero mean and unit variance, as a lack of normalization ma...
2048
-
[5]
All experiments are implemented in RETURNN [29], which we use for both pre-training and supervised train- ing
as prediction targets and train with Connectionist Tempo- ral Classification (CTC) [28], both for fine-tuning and training from scratch. All experiments are implemented in RETURNN [29], which we use for both pre-training and supervised train- ing. During inference, we perform Viterbi decoding with a 4- gram word-level language model using RASR [30]. For i...
2026
-
[6]
Conclusion In this work, we introduced three effective approaches to en- hance the quantizer in BEST-RQ and refine the generation of pseudo-labels. Our experimental results demonstrate that these optimizations achieve a∼12% (from 10.1% to 8.8%) relative improvement onLibrispeechtest-other while adding minimal additional pre-training cost. These findings h...
-
[7]
Acknowledgments This work was partially supported by the project RESCALE within the programAI Lighthouse Projects for the Environment, Climate, Nature and Resourcesfunded by the Federal Ministry for the Environment, Nature Conservation, Nuclear Safety and Consumer Protection (BMUV), funding IDs: 67KI32006A and 67KI32006B
-
[8]
All technical content, experiments, analyses, and conclusions were produced and verified by the authors
Generative AI Use Disclosure Generative AI tools were used for language editing, grammar correction, code assistance, and improving the readability of the manuscript. All technical content, experiments, analyses, and conclusions were produced and verified by the authors
-
[9]
A Survey on Self-Supervised Learning: Algorithms, Applica- tions, and Future Trends,
J. Gui, T. Chen, J. Zhang, Q. Cao, Z. Sun, H. Luo, and D. Tao, “A Survey on Self-Supervised Learning: Algorithms, Applica- tions, and Future Trends,”IEEE Trans. Pattern Anal. Mach. In- tell., vol. 46, no. 12, pp. 9052–9071, 2024
2024
-
[10]
Wav2vec: Unsupervised Pre-Training for Speech Recognition,
S. Schneider, A. Baevski, R. Collobert, and M. Auli, “Wav2vec: Unsupervised Pre-Training for Speech Recognition,” inInter- speech, Graz, Austria, Sep. 2019, pp. 3465–3469
2019
-
[11]
Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Represen- tations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Represen- tations,” inNeurIPS, virtual, Dec. 2020
2020
-
[12]
HuBERT: Self-Supervised Speech Represen- tation Learning by Masked Prediction of Hidden Units,
W. Hsu, B. Bolte, Y . H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “HuBERT: Self-Supervised Speech Represen- tation Learning by Masked Prediction of Hidden Units,”IEEE ACM Trans. Audio Speech Lang. Process., vol. 29, pp. 3451– 3460, 2021
2021
-
[13]
W2v-BERT: Combining Contrastive Learning and Masked Lan- guage Modeling for Self-Supervised Speech Pre-Training,
Y . Chung, Y . Zhang, W. Han, C. Chiu, J. Qin, R. Pang, and Y . Wu, “W2v-BERT: Combining Contrastive Learning and Masked Lan- guage Modeling for Self-Supervised Speech Pre-Training,” in ASRU, Cartagena, Colombia, Dec. 2021, pp. 244–250
2021
-
[14]
data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language,
A. Baevski, W. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language,” inICML, Baltimore, Maryland, USA, Jul. 2022, pp. 1298–1312
2022
-
[15]
Efficient Self- supervised Learning with Contextualized Target Representations for Vision, Speech and Language,
A. Baevski, A. Babu, W. Hsu, and M. Auli, “Efficient Self- supervised Learning with Contextualized Target Representations for Vision, Speech and Language,” inICML, Honolulu, Hawaii, USA, Jul. 2023, pp. 1416–1429
2023
-
[16]
Self-supervised Learning with Random-projection Quantizer for Speech Recogni- tion,
C. Chiu, J. Qin, Y . Zhang, J. Yu, and Y . Wu, “Self-supervised Learning with Random-projection Quantizer for Speech Recogni- tion,” inICML, Baltimore, Maryland, USA, Jul. 2022, pp. 3915– 3924
2022
-
[17]
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, and et al., “WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing,”IEEE J. Sel. Top. Signal Process., vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[18]
Di- noSR: Self-Distillation and Online Clustering for Self-supervised Speech Representation Learning,
A. H. Liu, H. Chang, M. Auli, W. Hsu, and J. R. Glass, “Di- noSR: Self-Distillation and Online Clustering for Self-supervised Speech Representation Learning,” inNeurIPS, New Orleans, LA, USA, Dec. 2023
2023
-
[19]
Google USM: Scaling Au- tomatic Speech Recognition Beyond 100 Languages,
Y . Zhang, W. Han, J. Qin, and et al., “Google USM: Scaling Au- tomatic Speech Recognition Beyond 100 Languages,”CoRR, vol. abs/2303.01037, 2023
-
[20]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, and et al., “The Llama 3 Herd of Models,”CoRR, vol. abs/2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
SpeechVerse: A Large-scale Generalizable Audio Language Model,
N. Das, S. Dingliwal, S. Ronanki, and et al., “SpeechVerse: A Large-scale Generalizable Audio Language Model,”CoRR, vol. abs/2405.08295, 2024
-
[22]
M-BEST-RQ: A Multi-Channel Speech Foundation Model for Smart Glasses,
Y . Yang, D. Raj, J. Lin, N. Moritz, J. Jia, and et al., “M-BEST-RQ: A Multi-Channel Speech Foundation Model for Smart Glasses,” inICASSP, Hyderabad, India, Apr. 2025, pp. 1–5
2025
-
[23]
ASTRA: Aligning Speech and Text Represen- tations for Asr without Sampling,
N. Gaur, R. Agrawal, G. Wang, P. Haghani, A. Rosenberg, and B. Ramabhadran, “ASTRA: Aligning Speech and Text Represen- tations for Asr without Sampling,” inInterspeech, Kos, Greece, Sep. 2024
2024
-
[24]
BERT: Pre- training of Deep Bidirectional Transformers for Language Un- derstanding,
J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of Deep Bidirectional Transformers for Language Un- derstanding,” inNAACL, Minneapolis, MN, USA, Jul. 2019, pp. 4171–4186
2019
-
[25]
Conformer: Convolution-augmented Transformer for Speech Recognition,
A. Gulati, J. Qin, C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition,” in Interspeech, Shanghai, China, Oct. 2020, pp. 5036–5040
2020
-
[26]
Incremental learning for robust visual tracking,
D. A. Ross, J. Lim, R.-S. Lin, and M.-H. Yang, “Incremental learning for robust visual tracking,”International journal of com- puter vision, vol. 77, no. 1, pp. 125–141, 2008
2008
-
[27]
Iterative refinement, not training objec- tive, makes HuBERT behave differently from wav2vec 2.0,
R. Huo and E. Dunbar, “Iterative refinement, not training objec- tive, makes HuBERT behave differently from wav2vec 2.0,” in Interspeech, Rotterdam, Netherlands, Aug. 2025, pp. 261–265
2025
-
[28]
Op- timized Self-supervised Training with BEST-RQ for Speech Recognition,
I. Baumann, D. Wagner, K. Riedhammer, and T. Bocklet, “Op- timized Self-supervised Training with BEST-RQ for Speech Recognition,” inICASSP, Hyderabad, India, Apr. 2025, pp. 1–5
2025
-
[29]
BiRQ: Bi-Level Self-Labeling Random Quantization for Self-Supervised Speech Recognition,
L. Jiang, X. Cui, B. Kingsbury, T. Chen, and L. Chen, “BiRQ: Bi-Level Self-Labeling Random Quantization for Self-Supervised Speech Recognition,”CoRR, vol. abs/2509.15430, 2025
-
[30]
Open Im- plementation and Study of Best-RQ for Speech Processing,
R. Whetten, T. Parcollet, M. Dinarelli, and Y . Est `eve, “Open Im- plementation and Study of Best-RQ for Speech Processing,” in ICASSP workshop, Seoul, Republic of Korea, Apr. 2024, pp. 460– 464
2024
-
[31]
Self-Attention with Relative Position Representations,
P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-Attention with Relative Position Representations,” inNAACL, New Orleans, Louisiana, USA, Jun. 2018, pp. 464–468
2018
-
[32]
Lib- rispeech: An ASR corpus based on Public Domain Audio Books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An ASR corpus based on Public Domain Audio Books,” inICASSP, South Brisbane, Queensland, Australia, Apr. 2015, pp. 5206–5210
2015
-
[33]
Libri-Light: A Benchmark for ASR with Limited or No Super- vision,
J. Kahn, M. Rivi `ere, W. Zheng, E. Kharitonov, Q. Xu, and et al., “Libri-Light: A Benchmark for ASR with Limited or No Super- vision,” inICASSP, Barcelona, Spain, May 2020, pp. 7669–7673
2020
-
[34]
The RWTH Asr System for Ted-Lium Release 2: Improving Hybrid Hmm With Specaugment,
W. Zhou, W. Michel, K. Irie, M. Kitza, R. Schl ¨uter, and H. Ney, “The RWTH Asr System for Ted-Lium Release 2: Improving Hybrid Hmm With Specaugment,” inICASSP, Barcelona, Spain, May 2020, pp. 7839–7843
2020
-
[35]
Phoneme Based Neural Transducer for Large V ocabulary Speech Recognition,
W. Zhou, S. Berger, R. Schl ¨uter, and H. Ney, “Phoneme Based Neural Transducer for Large V ocabulary Speech Recognition,” in ICASSP, Toronto, Canada, Jun. 2021, pp. 5644–5648
2021
-
[36]
Con- nectionist Temporal Classification: Labelling Unsegmented Se- quence Data with Recurrent Neural Networks,
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Con- nectionist Temporal Classification: Labelling Unsegmented Se- quence Data with Recurrent Neural Networks,” inICML, Pitts- burgh, Pennsylvania, USA, Jun. 2006, pp. 369–376
2006
-
[37]
RETURNN as a Generic Flexible Neural Toolkit with Application to Translation and Speech Recognition,
A. Zeyer, T. Alkhouli, and H. Ney, “RETURNN as a Generic Flexible Neural Toolkit with Application to Translation and Speech Recognition,” inACL, Melbourne, Australia, Jul. 2018, pp. 128–133
2018
-
[38]
RASR/NN: The RWTH neural network toolkit for speech recog- nition,
S. Wiesler, A. Richard, P. Golik, R. Schl ¨uter, and H. Ney, “RASR/NN: The RWTH neural network toolkit for speech recog- nition,” inICASSP, Florence, Italy, May 2014, pp. 3281–3285
2014
-
[39]
Cross-Modal Alignment With Optimal Transport For CTC-Based ASR,
X. Lu, P. Shen, Y .Tsao, and H. Kawai, “Cross-Modal Alignment With Optimal Transport For CTC-Based ASR,” inASRU, Taipei, Taiwan, Dec. 2023, pp. 1–7
2023
-
[40]
Layer-Wise Analysis of a Self- Supervised Speech Representation Model,
A. Pasad, J. Chou, and et al., “Layer-Wise Analysis of a Self- Supervised Speech Representation Model,” inASRU, Cartagena, Colombia, Dec. 2021, pp. 914–921
2021
-
[41]
Unsupervised Speech Recognition,
A. Baevski, W. Hsu, A. Conneau, and M. Auli, “Unsupervised Speech Recognition,” inNeurIPS, virtual, Dec. 2021, pp. 27 826– 27 839
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.