RISE: Relay Inference and Online Scheduling for Efficient Edge-Device Collaborative Diffusion Model Services
Pith reviewed 2026-06-26 23:35 UTC · model grok-4.3
The pith
A relay mechanism lets large edge models pass intermediate latents to small device models after early denoising steps, yielding up to 2.1 times speedup with no quality loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
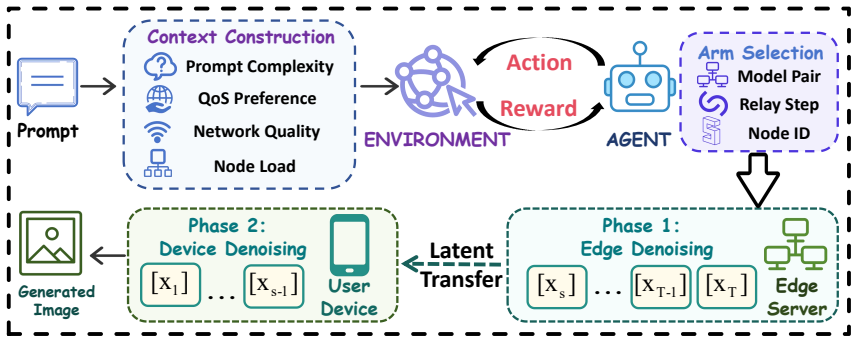
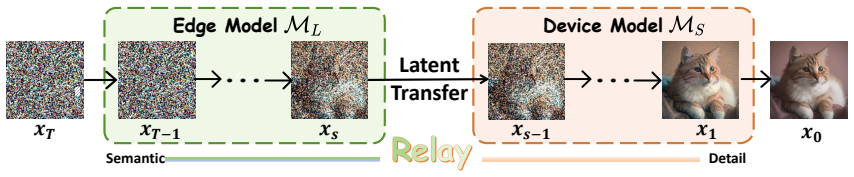
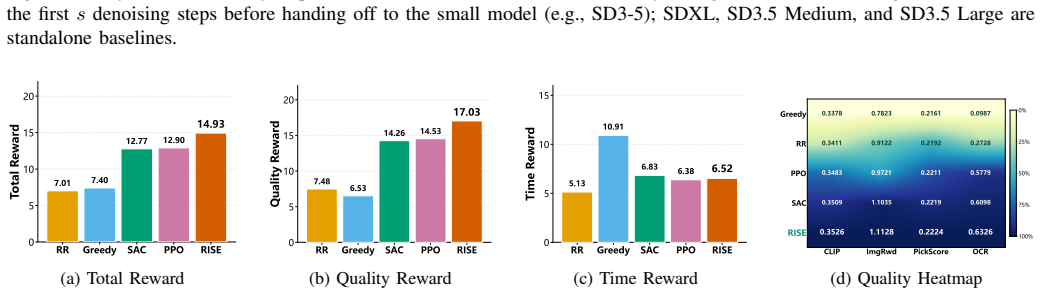
RISE's training-free relay exploits the shared latent space within a model family: the edge model executes the initial denoising steps that determine overall semantics, then transfers the intermediate latent to the device-side model for the remaining refinement steps; a contextual bandit scheduler selects the relay configuration on the fly using prompt complexity, user preferences, network quality, and node loads. The resulting service delivers up to 2.1 times speedup while matching full-model output quality.
What carries the argument
The training-free relay mechanism that hands off the intermediate latent after early denoising steps, enabled by minimal deviation in latent intensity within a model family.
If this is right
- Diffusion services can meet diverse quality and latency targets by dynamically allocating early semantic steps to the edge and later refinement to the device.
- The same scheduler can adapt relay choices to changing network conditions or device loads without requiring model retraining.
- Full semantic coherence is retained because the large model still controls the steps that fix global structure.
- Mixed workloads can be served from a single deployment rather than maintaining separate edge-only and device-only pipelines.
Where Pith is reading between the lines
- The approach may generalize to other diffusion-based tasks such as video or 3D generation if their latent spaces show comparable stability across model sizes.
- Keeping later denoising steps on the device could reduce the amount of user data leaving the local device, with possible privacy benefits.
- Model families with more than two sizes could form deeper relay chains, passing the latent through intermediate sizes as load or network conditions change.
Load-bearing premise
Latent intensity exhibits minimal deviation after a model handoff, allowing the early and late denoising stages to be performed by different-sized models without quality drop.
What would settle it
An experiment that measures the change in final image quality or latent statistics when the relay handoff occurs at the same step count but with deliberately mismatched models from outside the family, and finds a clear drop compared with the single-model baseline.
Figures



read the original abstract
Text-to-image diffusion models are increasingly deployed at the network edge to serve heterogeneous workloads with diverse quality and latency requirements. However, existing deployment strategies choose either large edge-side models with high fidelity but high latency or lightweight device-side models that offer speed at the cost of semantic coherence. Moreover, these approaches rarely split the denoising workload between models of different sizes across edge servers and user devices. To bridge this gap, we propose RISE, a method for edge-device diffusion model services that combines relay inference with online scheduling. Driven by the finding that the latent intensity exhibits minimal deviation after a model handoff, RISE uses a training-free relay mechanism that exploits the shared latent space within a model family: the large model on the edge handles the early denoising steps that shape semantic structure, then passes the intermediate latent to a small device-side model for detail refinement. To deploy this mechanism as a practical service, a contextual bandit scheduler selects the best relay configuration based on prompt complexity, user preferences, network quality and real-time node loads. Experiments on two benchmarks show that RISE's relay mechanism achieves up to 2.1$\times$ speedup while preserving full-model quality, and its context-aware scheduler effectively balances quality and latency under mixed workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RISE for edge-device collaborative text-to-image diffusion services. It introduces a training-free relay where a large edge model performs early denoising steps that shape semantics and hands off the intermediate latent to a smaller device model for refinement, justified by the empirical claim that latent intensity shows minimal deviation after handoff within a model family. A contextual bandit scheduler then selects relay configurations online using prompt complexity, user preferences, network quality, and node loads. Experiments on two benchmarks are reported to achieve up to 2.1× speedup while preserving full-model quality and to balance quality-latency tradeoffs under mixed workloads.
Significance. If the minimal-deviation assumption is shown to hold robustly, the training-free relay plus online scheduler would offer a practical way to split denoising workloads across heterogeneous edge and device hardware without retraining, addressing a real deployment gap between high-fidelity edge models and fast but lower-quality device models. The choice of a standard contextual bandit for the scheduler is a strength, as it enables adaptation without additional learned components.
major comments (3)
- [Abstract and §3] Abstract and §3 (Relay Inference): The entire quality-preservation guarantee and the 2.1× speedup claim rest on the unquantified assertion that 'the latent intensity exhibits minimal deviation after a model handoff.' No definition of intensity is given, no L2 distances, variance statistics, or perceptual metrics are reported, and no ablation across model families or prompt complexities appears. This single assumption is load-bearing; without it the handoff can inject uncorrectable semantic errors.
- [§5] §5 (Experiments): The abstract states that 'experiments on two benchmarks show' the speedup and quality results, yet supplies no baseline descriptions, model families/sizes, number of prompts or runs, statistical tests, or exclusion criteria. This prevents verification of whether the reported 2.1× figure is robust or comparable to prior edge-device splitting methods.
- [§4] §4 (Scheduler): The contextual bandit selects configurations that presuppose reliable relay outcomes. No analysis is provided of how the reward function or regret bounds behave if the minimal-deviation condition is violated on some prompts, which directly affects the claimed balance of quality and latency under mixed workloads.
minor comments (2)
- [Abstract] The abstract uses LaTeX '2.1$\times$' but the surrounding text should spell out the unit for clarity in the first occurrence.
- [§3] Notation for 'latent intensity' should be introduced with a symbol or equation even if the quantity is only used empirically.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below. Where the comments correctly identify gaps in quantification or reporting, we commit to revisions that add the requested analysis and details without altering the core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Relay Inference): The entire quality-preservation guarantee and the 2.1× speedup claim rest on the unquantified assertion that 'the latent intensity exhibits minimal deviation after a model handoff.' No definition of intensity is given, no L2 distances, variance statistics, or perceptual metrics are reported, and no ablation across model families or prompt complexities appears. This single assumption is load-bearing; without it the handoff can inject uncorrectable semantic errors.
Authors: We agree that the current manuscript presents the minimal-deviation observation as an empirical finding without sufficient quantitative backing. In the revision we will (i) provide an explicit definition of latent intensity (the L2 norm of the latent tensor at each timestep), (ii) report L2 distances, per-channel variance, and LPIPS perceptual distances between relay handoff latents and the corresponding full-model latents on the same prompts, and (iii) add ablations across two model families (Stable Diffusion 1.5/2.1) and prompt complexity strata. These additions will directly substantiate or qualify the handoff assumption. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract states that 'experiments on two benchmarks show' the speedup and quality results, yet supplies no baseline descriptions, model families/sizes, number of prompts or runs, statistical tests, or exclusion criteria. This prevents verification of whether the reported 2.1× figure is robust or comparable to prior edge-device splitting methods.
Authors: We acknowledge the lack of experimental detail. The revised §5 will explicitly list: (a) all baselines (full edge model, full device model, static split at fixed timestep, and two prior edge-device partitioning methods), (b) exact model families and parameter counts, (c) number of prompts per benchmark and total runs (with seed reporting), (d) statistical tests (paired t-tests and bootstrap confidence intervals), and (e) any exclusion criteria. This will enable direct comparison and reproducibility assessment of the 2.1× claim. revision: yes
-
Referee: [§4] §4 (Scheduler): The contextual bandit selects configurations that presuppose reliable relay outcomes. No analysis is provided of how the reward function or regret bounds behave if the minimal-deviation condition is violated on some prompts, which directly affects the claimed balance of quality and latency under mixed workloads.
Authors: The scheduler is intentionally lightweight and relies on observed outcomes rather than an explicit model of the deviation condition. Nevertheless, we will add a sensitivity study that injects controlled latent perturbations (simulating violation cases) into the reward signal and reports resulting changes in cumulative regret and quality-latency Pareto front under mixed workloads. This will quantify robustness without requiring changes to the bandit formulation itself. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper's central mechanism rests on an empirical observation ('latent intensity exhibits minimal deviation after a model handoff') presented as an input finding rather than a derived result, with the relay and scheduler described as direct applications of that observation and a standard contextual bandit. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems appear in the provided text that would reduce any claim to its own inputs by construction. The reported speedups and quality preservation are framed as experimental outcomes, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption latent intensity exhibits minimal deviation after a model handoff
Reference graph
Works this paper leans on
-
[1]
Toward resource- efficient collaboration of large AI models in mobile edge networks,
P. Li, L. Qian, D. Niyato, S. Mao, and Y . Wu, “Toward resource- efficient collaboration of large AI models in mobile edge networks,” IEEE Network, vol. 40, no. 3, pp. 51-59, 2026
2026
-
[2]
Speculative decoding and beyond: An in-depth survey of techniques,
Y . Hu, Z. Liu, Z. Dong, T. Peng, B. McDanel, and S. Q. Zhang, “Speculative decoding and beyond: An in-depth survey of techniques,” arXiv preprint arXiv:2502.19732, 2025
arXiv 2025
-
[3]
Decoding speculative decoding,
M. Yan, S. Agarwal, and S. Venkataraman, “Decoding speculative decoding,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 6460–6473
2025
-
[4]
Dssd: Efficient edge-device llm deployment and collaborative inference via distributed split speculative decoding,
J. NING, C. ZHENG, and T. Yang, “Dssd: Efficient edge-device llm deployment and collaborative inference via distributed split speculative decoding,” inICML 2025 Workshop on Machine Learning for Wireless Communication and Networks (ML4Wireless)
2025
-
[5]
Sdxl: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” inThe Twelfth International Confer- ence on Learning Representations (ICLR), 2024
2024
-
[6]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first International Conference on Machine Learning (ICML), 2024
2024
-
[7]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[8]
Consistency models made easy,
Z. Geng, A. Pokle, W. Luo, J. Lin, and J. Z. Kolter, “Consistency models made easy,” inThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[9]
Snapgen: Taming high- resolution text-to-image models for mobile devices with efficient ar- chitectures and training,
J. Chen, D. Hu, X. Huang, H. Coskun, A. Sahni, A. Gupta, A. Goyal, D. Lahiri, R. Singh, Y . Idelbayevet al., “Snapgen: Taming high- resolution text-to-image models for mobile devices with efficient ar- chitectures and training,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 7997–8008
2025
-
[10]
Pfeife: Automatic pipeline parallelism for pytorch,
H. Y . Jhoo, C.-K. Hur, and N. P. Lopes, “Pfeife: Automatic pipeline parallelism for pytorch,” inForty-second International Conference on Machine Learning (ICML), 2025
2025
-
[11]
Diffusion models on the edge: Challenges, optimizations, and applications,
D. Zheng, “Diffusion models on the edge: Challenges, optimizations, and applications,”arXiv preprint arXiv:2504.15298, 2025
arXiv 2025
-
[12]
Progressive knowledge distillation of stable diffusion xl using layer level loss,
Y . Gupta, V . V . Jaddipal, H. Prabhala, S. Paul, and P. V on Platen, “Progressive knowledge distillation of stable diffusion xl using layer level loss,”arXiv preprint arXiv:2401.02677, 2024
arXiv 2024
-
[13]
Mobile video diffusion,
H. Ben Yahia, D. Korzhenkov, I. Lelekas, A. Ghodrati, and A. Habibian, “Mobile video diffusion,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 19 450–19 460
2025
-
[14]
Iot–edge splitting with pruned early-exit cnns for adaptive inference,
G. Korol and A. C. S. Beck, “Iot–edge splitting with pruned early-exit cnns for adaptive inference,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2025
2025
-
[15]
Relay diffusion: Unifying diffusion process across resolutions for image synthesis,
J. Teng, W. Zheng, M. Ding, W. Hong, J. Wangni, Z. Yang, and J. Tang, “Relay diffusion: Unifying diffusion process across resolutions for image synthesis,” inThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[16]
Cogview3: Finer and faster text-to-image generation via relay diffusion,
W. Zheng, J. Teng, Z. Yang, W. Wang, J. Chen, X. Gu, Y . Dong, M. Ding, and J. Tang, “Cogview3: Finer and faster text-to-image generation via relay diffusion,” inEuropean Conference on Computer Vision (ECCV). Springer, 2024, pp. 1–22
2024
-
[17]
Ce-collm: Efficient and adaptive large language models through cloud-edge collaboration,
H. Jin and Y . Wu, “Ce-collm: Efficient and adaptive large language models through cloud-edge collaboration,” in2025 IEEE International Conference on Web Services (ICWS). IEEE, 2025, pp. 316–323
2025
-
[18]
Percep- tion prioritized training of diffusion models,
J. Choi, J. Lee, C. Shin, S. Kim, H. Kim, and S. Yoon, “Percep- tion prioritized training of diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 472–11 481
2022
-
[19]
Faster diffusion via temporal attention decomposition,
H. Liu, W. Zhang, J. Xie, F. Faccio, M. Xu, T. Xiang, M. Z. Shou, J.-M. Perez-Rua, and J. Schmidhuber, “Faster diffusion via temporal attention decomposition,”arXiv preprint arXiv:2404.02747, 2024
arXiv 2024
-
[20]
ediff-i: Text-to-image diffu- sion models with an ensemble of expert denoisers,
Y . Balaji, S. Nah, X. Huang, A. Vahdat, J. Song, Q. Zhang, K. Kreis, M. Aittala, T. Aila, S. Laineet al., “ediff-i: Text-to-image diffu- sion models with an ensemble of expert denoisers,”arXiv preprint arXiv:2211.01324, 2022
Pith/arXiv arXiv 2022
-
[21]
Online request scheduling for quality-aware diffusion-based aigc services,
H. Yang, Y . Zheng, L. Jiao, Y . Xu, and Z. Li, “Online request scheduling for quality-aware diffusion-based aigc services,”IEEE Transactions on Networking, 2025
2025
-
[22]
Enhancing aigc service efficiency with adaptive multi-edge collaboration in a distributed system,
C. Xu, J. Guo, J. Zeng, H. Qiu, T. Wang, X. Chu, and J. Cao, “Enhancing aigc service efficiency with adaptive multi-edge collaboration in a distributed system,”IEEE Transactions on Services Computing, 2025
2025
-
[23]
An extensive investigation on lyapunov optimization-based task offloading techniques in multi-access edge computing,
V . R. Verma, Pushkar, B. kumar, A. Verma, V . Sharma, and P. K. Tri- pathi, “An extensive investigation on lyapunov optimization-based task offloading techniques in multi-access edge computing,”SN Computer Science, vol. 6, no. 6, p. 603, 2025
2025
-
[24]
Prox- imal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[25]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational Conference on Machine Learning (ICML). Pmlr, 2018, pp. 1861–1870
2018
-
[26]
Eat: Qos-aware edge-collaborative aigc task scheduling via attention- guided diffusion reinforcement learning,
Z. Xu, Z. Tang, J. Lou, Z. Yao, X. Xie, T. Wang, Y . Wang, and W. Jia, “Eat: Qos-aware edge-collaborative aigc task scheduling via attention- guided diffusion reinforcement learning,”IEEE Transactions on Mobile Computing, 2026
2026
-
[27]
T-stitch: Accelerating sampling in pre-trained diffu- sion models with trajectory stitching,
Z. Pan, B. Zhuang, D.-A. Huang, W. Nie, Z. Yu, C. Xiao, J. Cai, and A. Anandkumar, “T-stitch: Accelerating sampling in pre-trained diffu- sion models with trajectory stitching,” inThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[28]
Inference-time diffusion model distillation,
G. Y . Park, S. W. Lee, and J. C. Ye, “Inference-time diffusion model distillation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 4049–4058
2025
-
[29]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[30]
Deepcache: Accelerating diffusion models for free,
X. Ma, G. Fang, and X. Wang, “Deepcache: Accelerating diffusion models for free,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 15 762–15 772
2024
-
[31]
BWCache: Accelerating video diffusion transformers through block-wise caching,
H. Cui, Z. Tang, Z. Xu, Z. Yao, W. Zeng, and W. Jia, “BWCache: Accelerating video diffusion transformers through block-wise caching,” arXiv preprint arXiv:2509.13789, 2025
arXiv 2025
-
[32]
Enhancing conditional diffusion model robustness in inference with optimal combination factor,
W. Xu, X. Zhu, and X. Li, “Enhancing conditional diffusion model robustness in inference with optimal combination factor,” in2025 IEEE International Conference on Web Services (ICWS). IEEE, 2025, pp. 661–672
2025
-
[33]
Dynamic model and node selection for collaborative inference of large/small models in vehicular networks,
M. Zheng, Z. Lu, Q. Duan, B. Huang, and S. Hut, “Dynamic model and node selection for collaborative inference of large/small models in vehicular networks,” in2025 IEEE International Conference on Web Services (ICWS). IEEE, 2025, pp. 232–243
2025
-
[34]
Computation of- floading in the edge-to-cloud compute continuum: a survey of federated architectural solutions,
J. Pournazari, A. Ullah, A. Al-Dubai, and X. Liu, “Computation of- floading in the edge-to-cloud compute continuum: a survey of federated architectural solutions,”Cluster Computing, vol. 28, no. 13, p. 839, 2025
2025
-
[35]
Resource heterogeneity-aware and utilization-enhanced scheduling for deep learning clusters,
A. Sultana, N. Pakka, F. Xu, X. Yuan, L. Chen, and N.-F. Tzeng, “Resource heterogeneity-aware and utilization-enhanced scheduling for deep learning clusters,”IEEE Transactions on Computers, 2026
2026
-
[36]
Empowering edge intelligence: A comprehensive survey on on-device ai models,
X. Wang, Z. Tang, J. Guo, T. Meng, C. Wang, T. Wang, and W. Jia, “Empowering edge intelligence: A comprehensive survey on on-device ai models,”ACM Computing Surveys, vol. 57, no. 9, pp. 1–39, 2025
2025
-
[37]
A contextual-bandit approach to personalized news article recommendation,
L. Li, W. Chu, J. Langford, and R. E. Schapire, “A contextual-bandit approach to personalized news article recommendation,” inProceedings of the 19th international conference on World wide web, 2010, pp. 661– 670
2010
-
[38]
Finite-time analysis of the multiarmed bandit problem,
P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time analysis of the multiarmed bandit problem,”Machine learning, vol. 47, no. 2, pp. 235– 256, 2002
2002
-
[39]
Cloud-edge system for scheduling unpredictable llm requests with combinatorial bandit,
Y . Li, J. Guo, Z. Tang, X. Ding, J. Wang, T. Wang, and W. Jia, “Cloud-edge system for scheduling unpredictable llm requests with combinatorial bandit,”IEEE Transactions on Services Computing, 2025
2025
-
[40]
Enhancing llm qos through cloud-edge collaboration: A diffusion-based multi-agent reinforcement learning approach,
Z. Yao, Z. Tang, W. Yang, and W. Jia, “Enhancing llm qos through cloud-edge collaboration: A diffusion-based multi-agent reinforcement learning approach,”IEEE Transactions on Services Computing, 2025
2025
-
[41]
Flow straight and fast: Learning to generate and transfer data with rectified flow,
X. Liu, C. Gonget al., “Flow straight and fast: Learning to generate and transfer data with rectified flow,” inThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[42]
Diffusiondb: A large-scale prompt gallery dataset for text-to- image generative models,
Z. J. Wang, E. Montoya, D. Munechika, H. Yang, B. Hoover, and D. H. Chau, “Diffusiondb: A large-scale prompt gallery dataset for text-to- image generative models,” inProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), 2023, pp. 893–911
2023
-
[43]
Character-aware models improve visual text rendering,
R. Liu, D. Garrette, C. Saharia, W. Chan, A. Roberts, S. Narang, I. Blok, R. Mical, M. Norouzi, and N. Constant, “Character-aware models improve visual text rendering,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 16 270–16 297
2023
-
[44]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning (ICML). PmLR, 2021, pp. 8748– 8763
2021
-
[45]
Imagereward: Learning and evaluating human preferences for text-to- image generation,
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong, “Imagereward: Learning and evaluating human preferences for text-to- image generation,”Advances in Neural Information Processing Systems, vol. 36, pp. 15 903–15 935, 2023
2023
-
[46]
Pick-a-pic: An open dataset of user preferences for text-to-image generation,
Y . Kirstain, A. Polyak, U. Singer, S. Matiana, J. Penna, and O. Levy, “Pick-a-pic: An open dataset of user preferences for text-to-image generation,”Advances in neural information processing systems, vol. 36, pp. 36 652–36 663, 2023
2023
-
[47]
Laion- 5b: An open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsmanet al., “Laion- 5b: An open large-scale dataset for training next generation image-text models,”Advances in neural information processing systems, vol. 35, pp. 25 278–25 294, 2022
2022
-
[48]
Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition,
S. Fang, H. Xie, Y . Wang, Z. Mao, and Y . Zhang, “Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 7098–7107
2021
-
[49]
Faster diffusion through temporal attention decomposition,
H. Liu, W. Zhang, J. Xie, F. Faccio, M. Xu, T. Xiang, M. Z. Shou, J.- M. Perez-Rua, and J. Schmidhuber, “Faster diffusion through temporal attention decomposition,”Transactions on Machine Learning Research, 2025
2025
-
[50]
Sada: Stability-guided adaptive diffusion acceleration,
T. Jiang, Y . Wang, H. Ye, Z. Shao, J. Sun, J. Zhang, Z. Chen, J. Zhang, Y . Chen, and H. Li, “Sada: Stability-guided adaptive diffusion acceleration,”arXiv preprint arXiv:2507.17135, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.