Omni-Flow: A Unified Workflow Orchestration and Distributed KV Cache Sharing Framework for Multimodal Inference
Pith reviewed 2026-07-01 04:10 UTC · model grok-4.3
The pith
Omni-Flow provides a three-layer abstraction for unified orchestration, data transmission, and KV cache sharing across multimodal inference workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
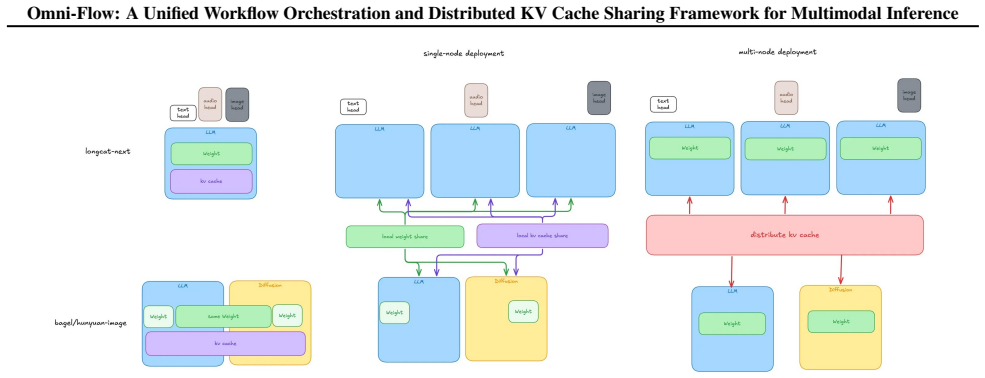
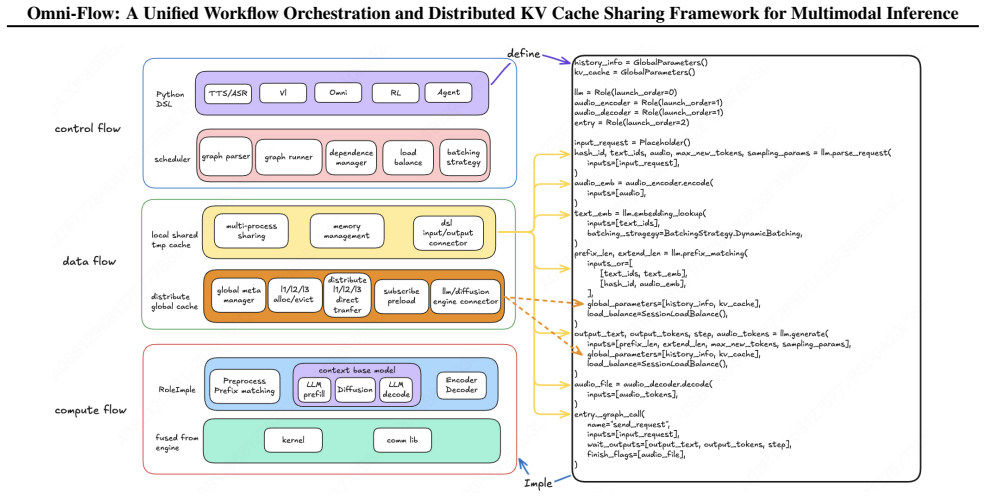
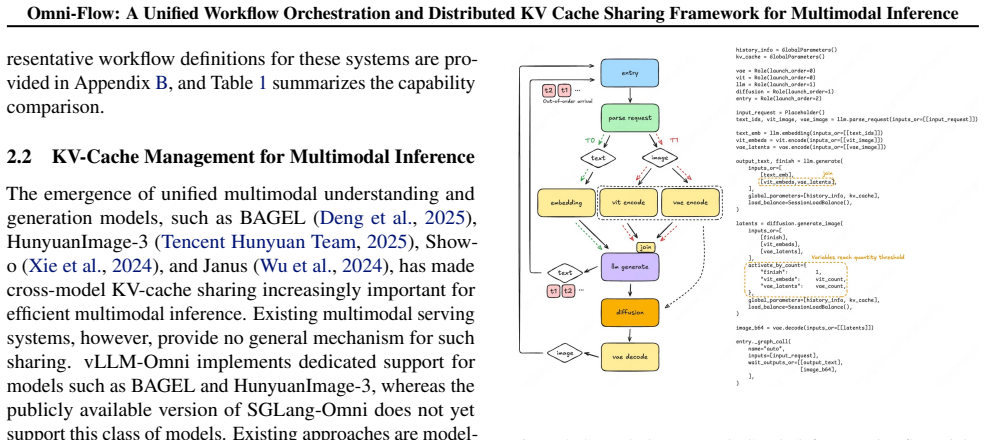
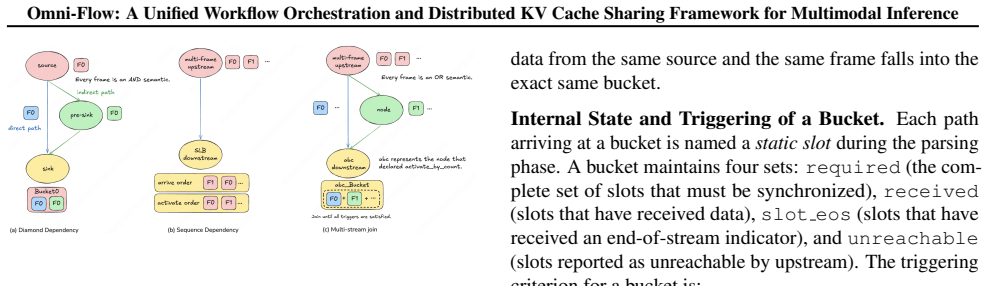
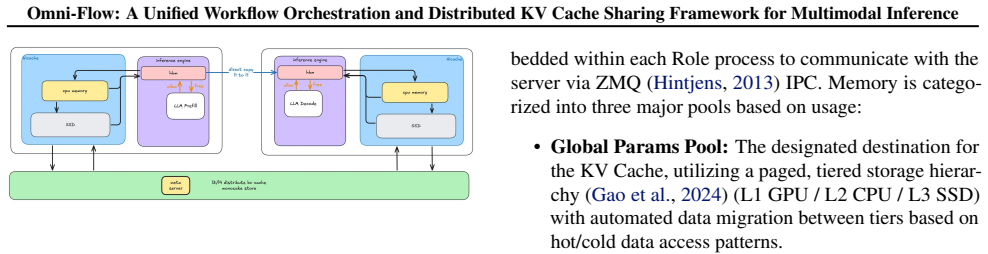
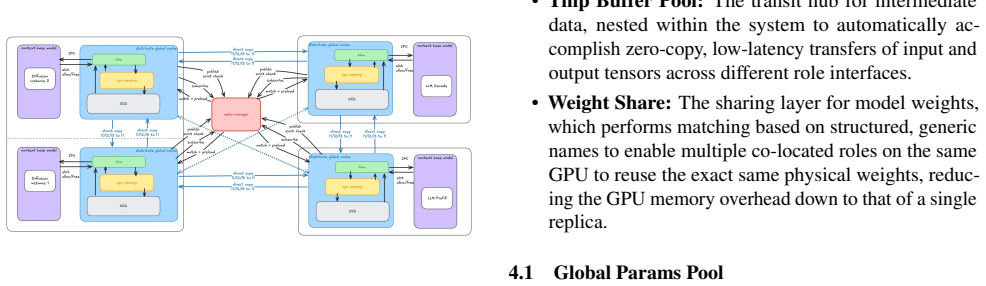
Omni-Flow is presented as a distributed scheduling framework for multimodal inference that employs a three-layer abstraction: the Control Flow layer defines workflows via a Python DSL supporting static DAGs and dynamic routing with service discovery and load balancing; the Data Flow layer supplies a distributed KV cache abstraction with allocation and direct cross-role transmission over zero-copy channels in a GPU/CPU/SSD hierarchy; the Compute Flow layer handles multimodal prefix matching and KV reuse through a unified SGLang interface that allows diffusion models to reuse LLM forward paths under unified parallel semantics.
What carries the argument
The three-layer abstraction (Control Flow via Python DSL, Data Flow via distributed KV cache with three-tier paged storage, Compute Flow via unified SGLang interface) that turns heterogeneous multimodal units into a single dataflow graph.
If this is right
- Heterogeneous computing units with complex dependencies can be orchestrated into a single dataflow graph that supports both static DAGs and dynamic routing.
- Massive intermediate tensors can be transmitted efficiently across processes and nodes using zero-copy low-latency channels in a three-tier storage hierarchy.
- KV caches and model weights can be shared across roles to eliminate redundant GPU memory usage in multi-turn dialogues and complex pipelines.
- Diffusion models can directly reuse the LLM forward path and sampling logic under unified parallel semantics.
- New models can be integrated with lower cost because orchestration logic is no longer tightly coupled to specific model types.
Where Pith is reading between the lines
- The approach might reduce the engineering effort needed to prototype new multimodal applications that combine language and vision models.
- It could encourage inference systems to treat KV cache management as a first-class distributed service rather than model-specific logic.
- Resource scheduling in cloud or cluster environments for mixed LLM and diffusion workloads might become more automated if the load-balancing strategies generalize.
- Similar layering could be tested on other heterogeneous compute patterns, such as combining multiple vision models or adding audio components.
Load-bearing premise
A single Python DSL combined with a unified SGLang interface can orchestrate heterogeneous models and enable KV reuse without introducing unacceptable latency or correctness issues during real deployments.
What would settle it
Measure end-to-end latency, memory footprint, and output correctness when running the HunyuanImage-3 image generation pipeline or LongCat-Next dialogue system under Omni-Flow versus independent model deployments on the same hardware.
Figures

read the original abstract
As large language model (LLM) inference evolves from text-only to multimodal paradigms, inference systems face three challenges: (1) flexible orchestration of multimodal workflows, where heterogeneous computing units exhibit complex dependencies and concurrent control; (2) efficient transmission of massive intermediate data across processes and nodes, with tensors flowing at high speed among heterogeneous roles; and (3) efficient sharing of KV caches and model weights across roles to eliminate redundant GPU memory. Existing solutions deploy LLMs and diffusion models independently, lacking a system-level abstraction for multimodal pipelines; this scatters orchestration logic, tightly couples transmission paths to specific models, and incurs high cost to integrate new models. To address these challenges, we present Omni-Flow, a distributed scheduling framework for multimodal inference through a three-layer abstraction. The Control Flow layer defines workflows via a Python DSL, orchestrating heterogeneous units into a unified dataflow graph that supports static DAGs and dynamic routing, with built-in service discovery and diverse load-balancing strategies. The Data Flow layer provides a distributed KV cache abstraction beyond prefill/decode separation, unifying allocation and enabling direct cross-role transmission across a three-tier paged storage hierarchy (GPU/CPU/SSD) over zero-copy, low-latency channels. The Compute Flow layer supports complex multimodal prefix matching for KV reuse across multi-turn dialogues, and takes over KV cache and sampling logic via a unified SGLang interface, letting diffusion models directly reuse the LLM forward path under unified parallel semantics. We demonstrate that Omni-Flow supports diverse heterogeneous scenarios with a consistent programming model, including omni-modal dialogue (LongCat-Next) and complex image generation pipelines (HunyuanImage-3).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Omni-Flow, a distributed scheduling framework for multimodal inference organized in three layers. The Control Flow layer uses a Python DSL to orchestrate heterogeneous computing units into unified dataflow graphs supporting static DAGs and dynamic routing with service discovery and load balancing. The Data Flow layer supplies a distributed KV cache abstraction with three-tier paged storage (GPU/CPU/SSD) enabling zero-copy cross-role transmission. The Compute Flow layer introduces a unified SGLang interface for complex multimodal prefix matching and KV reuse, allowing diffusion models to reuse LLM forward paths under unified parallel semantics. The work claims to support diverse scenarios including omni-modal dialogue (LongCat-Next) and image generation pipelines (HunyuanImage-3) with a consistent programming model.
Significance. If the three-layer abstractions can be shown to deliver the claimed orchestration flexibility, zero-copy transmission, and cross-model KV reuse without unacceptable overhead or correctness loss, the framework would address a genuine systems gap in multimodal inference by reducing redundant GPU memory and simplifying integration of new models. The consistent Python DSL programming model is a potentially valuable contribution for heterogeneous workflows if empirically validated.
major comments (2)
- [Abstract] Abstract (Compute Flow layer description): The claim that diffusion models can 'directly reuse the LLM forward path under unified parallel semantics' via the SGLang interface is load-bearing for the 'eliminate redundant GPU memory' and 'consistent programming model' benefits, yet the manuscript supplies no description of how token-level KV states map to diffusion latent states, how sampling logic is overridden, or how synchronization is handled across heterogeneous roles.
- [Abstract] Abstract (overall evaluation): The central claims of efficient transmission, KV sharing, and support for diverse heterogeneous scenarios rest entirely on architectural description; no latency, throughput, memory, or correctness measurements, ablations, or comparisons to independent LLM/diffusion deployments are provided, rendering the performance and generality assertions unverifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for greater technical detail and empirical support. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (Compute Flow layer description): The claim that diffusion models can 'directly reuse the LLM forward path under unified parallel semantics' via the SGLang interface is load-bearing for the 'eliminate redundant GPU memory' and 'consistent programming model' benefits, yet the manuscript supplies no description of how token-level KV states map to diffusion latent states, how sampling logic is overridden, or how synchronization is handled across heterogeneous roles.
Authors: We agree the claim is central and that the provided manuscript text does not include the requested low-level mapping, sampling override, or synchronization details. The Compute Flow description remains at the interface level. We will add a dedicated subsection (with pseudocode and state-transition diagrams) explaining the KV-to-latent adaptation, sampling logic override, and cross-role synchronization protocol. revision: yes
-
Referee: [Abstract] Abstract (overall evaluation): The central claims of efficient transmission, KV sharing, and support for diverse heterogeneous scenarios rest entirely on architectural description; no latency, throughput, memory, or correctness measurements, ablations, or comparisons to independent LLM/diffusion deployments are provided, rendering the performance and generality assertions unverifiable.
Authors: The current manuscript emphasizes the three-layer architecture and programming model, illustrating applicability via the LongCat-Next and HunyuanImage-3 case studies without controlled quantitative benchmarks. We acknowledge that this leaves the efficiency and generality claims unverified. We will add a new Evaluation section containing latency/throughput/memory measurements, ablations on each layer, and direct comparisons against independent LLM and diffusion deployments. revision: yes
Circularity Check
No circularity: systems description with no derivations or fitted quantities
full rationale
The paper is a systems engineering description of a three-layer orchestration framework (Control Flow via Python DSL, Data Flow via distributed KV cache, Compute Flow via unified SGLang). No equations, parameters, predictions, or derivation chains appear in the abstract or provided text. Claims rest on implementation details and demonstrations (LongCat-Next, HunyuanImage-3) rather than any reduction of outputs to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are load-bearing for any mathematical result. This is the expected finding for a non-equation-based systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , pages =
2023
-
[2]
SGLang: Efficient Execution of Structured Language Model Programs
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E. and Barrett, Clark and Sheng, Ying , year =. 2312.07104 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2023 , howpublished =
2023
-
[4]
2025 , howpublished =
2025
-
[5]
Yu, Gyeong-In and Jeong, Joo Seong and Kim, Geon-Woo and Kim, Soojeong and Chun, Byung-Gon , booktitle =
-
[6]
2022 , publisher =
Aminabadi, Reza Yazdani and Rajbhandari, Samyam and Awan, Ammar Ahmad and Li, Cheng and Li, Du and Zheng, Elton and Ruwase, Olatunji and Smith, Shaden and Zhang, Minjia and Rasley, Jeff and He, Yuxiong , booktitle =. 2022 , publisher =
2022
-
[7]
International Conference on Machine Learning , pages =
Sheng, Ying and Zheng, Lianmin and Yuan, Binhang and Li, Zhuohan and Ryabinin, Max and Chen, Beidi and Liang, Percy and R. International Conference on Machine Learning , pages =. 2023 , organization =
2023
-
[8]
Cost-Efficient Large Language Model Serving for Multi-turn Conversations with
Gao, Bin and He, Zhuomin and Sharma, Puru and Kang, Qingxuan and Jevdjic, Djordje and Deng, Junbo and Yang, Xingkun and Yu, Zhou and Zuo, Pengfei , booktitle =. Cost-Efficient Large Language Model Serving for Multi-turn Conversations with. 2024 , eprint =
2024
-
[9]
Lee, Wonbeom and Lee, Jungi and Seo, Junghwan and Sim, Jaewoong , booktitle =
-
[10]
Yang, Yifei and Ma, Hanjiang and Yin, Shichao and Wen, Zining and Li, Yuning and Chen, Jiawei , year =. 2410.18517 , archivePrefix =
-
[11]
Qin, Ruoyu and Li, Zheming and He, Weiran and Zhang, Mingxing and Wu, Yongwei and Zheng, Weimin and Xu, Xinran , year =. 2407.00079 , archivePrefix =
-
[12]
2024 , publisher =
Liu, Yuhan and Li, Hanchen and Cheng, Yihua and Ray, Siddhant and Huang, Yuyang and Zhang, Qizheng and Du, Kuntai and Yao, Jiayi and Lu, Shan and Ananthanarayanan, Ganesh and Maire, Michael and Hoffmann, Henry and Holtzman, Ari and Jiang, Junchen , booktitle =. 2024 , publisher =
2024
-
[13]
Srivatsa, Vikranth and He, Zijian and Abhyankar, Reyna and Li, Dongming and Zhang, Yiying , year =. 2407.00023 , archivePrefix =
-
[14]
2025 , eprint =
Kimi k1.5: Scaling Reinforcement Learning with. 2025 , eprint =
2025
-
[15]
2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA) , pages =
Patel, Pratyush and Choukse, Esha and Zhang, Chaojie and Shah, Aashaka and Goiri,. 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA) , pages =. 2024 , organization =
2024
-
[16]
Zhong, Yinmin and Liu, Shengyu and Chen, Junda and Hu, Jianbo and Zhu, Yibo and Liu, Xuanzhe and Jin, Xin and Zhang, Hao , year =. 2401.09670 , archivePrefix =
-
[17]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Agrawal, Amey and Kedia, Nitin and Panwar, Ashish and Mohan, Jayashree and Kwatra, Nipun and Gulavani, Bhargav S. and Tumanov, Alexey and Ramjee, Ramachandran , year =. Taming Throughput-Latency Tradeoff in. 2403.02310 , archivePrefix =
-
[18]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , year =. 2307.09288 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
2023 , eprint =
Gemini: A Family of Highly Capable Multimodal Models , author =. 2023 , eprint =
2023
-
[20]
2025 , eprint =
Emerging Properties in Unified Multimodal Pretraining , author =. 2025 , eprint =
2025
-
[21]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie, Jinheng and Mao, Weijia and Bai, Zechen and Zhang, David Junhao and Wang, Weihao and Lin, Kevin Qinghong and Gu, Yuchao and Chen, Zhijie and Yang, Zhenheng and Shou, Mike Zheng , year =. 2408.12528 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
2024 , eprint =
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation , author =. 2024 , eprint =
2024
-
[23]
2023 , eprint =
Visual Instruction Tuning , author =. 2023 , eprint =
2023
-
[24]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others , year =. 2312.14238 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Advances in Neural Information Processing Systems , volume =
Denoising Diffusion Probabilistic Models , author =. Advances in Neural Information Processing Systems , volume =
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
High-Resolution Image Synthesis with Latent Diffusion Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Scalable Diffusion Models with Transformers , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[28]
2023 , eprint =
Podell, Dustin and English, Zion and Lacey, Kyle and Blattmann, Andreas and Dockhorn, Tim and M. 2023 , eprint =
2023
-
[29]
2024 , howpublished =
2024
-
[30]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems , volume =
-
[31]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, Tri , year =. 2307.08691 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Advances in Neural Information Processing Systems , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , volume =
-
[33]
2023 , eprint =
Ainslie, Joshua and Lee-Thorp, James and de Jong, Michiel and Zemlyanskiy, Yury and Lebr. 2023 , eprint =
2023
-
[34]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Shoeybi, Mohammad and Patwary, Mostofa and Puri, Rajarshi and LeGresley, Patrick and Casper, Jared and Catanzaro, Bryan , year =. Megatron-. 1909.08053 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[35]
and others , booktitle =
Zheng, Lianmin and Li, Zhuohan and Zhang, Hao and Zhuang, Yonghao and Chen, Zhifeng and Huang, Yanping and Wang, Yida and Xu, Yuanzhong and Zhuo, Danyang and Xing, Eric P. and others , booktitle =
-
[36]
Advances in Neural Information Processing Systems , volume =
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism , author =. Advances in Neural Information Processing Systems , volume =
-
[37]
and Stoica, Ion , booktitle =
Moritz, Philipp and Nishihara, Robert and Wang, Stephanie and Tumanov, Alexey and Liaw, Richard and Liang, Eric and Elibol, Melih and Yang, Zongheng and Paul, William and Jordan, Michael I. and Stoica, Ion , booktitle =. Ray: A Distributed Framework for Emerging
-
[38]
Chase, Harrison , year =
-
[39]
Proceedings of the 14th Python in Science Conference , pages =
Dask: Parallel Computation with Blocked algorithms and Task Scheduling , author =. Proceedings of the 14th Python in Science Conference , pages =
-
[40]
2024 , publisher =
Gangidi, Adithya and Miao, Rui and Zheng, Shengbao and Bondu, Sai Jayesh and Goes, Guilherme and Morsy, Hany and Puri, Rohit and Riftadi, Mohammad and Shetty, Ashmitha Jeevaraj and Yang, Jingyi and Zhang, Shuqiang and Fernandez, Mikel Jimenez and Gandham, Shashidhar and Zeng, Hongyi , booktitle =. 2024 , publisher =
2024
-
[41]
2016 , howpublished =
2016
-
[42]
2014 , organization =
Einziger, Gil and Friedman, Roy , booktitle =. 2014 , organization =
2014
- [43]
-
[44]
2024 , eprint =
Alizadeh, Keivan and Mirzadeh, Iman and Belenko, Dmitry and Khatamifard, Karen and Cho, Minsik and Del Mundo, Carlo C and Rastegari, Mohammad and Farajtabar, Mehrdad , booktitle =. 2024 , eprint =
2024
-
[45]
An Image is Worth
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and others , booktitle =. An Image is Worth
-
[46]
International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. International Conference on Machine Learning , pages =. 2021 , organization =
2021
-
[47]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Sigmoid Loss for Language Image Pre-Training , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =. 2023 , eprint =
2023
-
[48]
2022 , eprint =
Robust Speech Recognition via Large-Scale Weak Supervision , author =. 2022 , eprint =
2022
-
[49]
Du, Zhihao and Chen, Qian and Zhang, Shiliang and Hu, Kai and Lu, Heng and Yang, Yexin and Hu, Hangrui and Zheng, Siqi and Guo, Yue and Wang, Ziyang and others , year =. 2407.05407 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
2024 , eprint =
Llumnix: Dynamic Scheduling for Large Language Model Serving , author =. 2024 , eprint =
2024
-
[51]
2023 , eprint =
Frantar, Elias and Ashkboos, Saleh and Hoefler, Torsten and Alistarh, Dan , booktitle =. 2023 , eprint =
2023
-
[52]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Dang, Xingyu and Han, Song , year =. 2306.00978 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
2024 , eprint =
Mixtral of Experts , author =. 2024 , eprint =
2024
-
[54]
Journal of Machine Learning Research , volume =
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author =. Journal of Machine Learning Research , volume =
-
[55]
2023 , eprint =
Accelerating Large Language Model Decoding with Speculative Sampling , author =. 2023 , eprint =
2023
-
[56]
and Chen, Deming and Dao, Tri , booktitle =
Cai, Tianle and Li, Yuhong and Geng, Zhengyang and Peng, Hongwu and Lee, Jason D. and Chen, Deming and Dao, Tri , booktitle =
-
[57]
Auto-Encoding Variational Bayes
Auto-Encoding Variational Bayes , author =. International Conference on Learning Representations , year =. 1312.6114 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
2022 , eprint =
Training Language Models to Follow Instructions with Human Feedback , author =. 2022 , eprint =
2022
-
[59]
How continuous batching enables
Anyscale , year =. How continuous batching enables
-
[60]
2009 , howpublished =
2009
-
[61]
Hintjens, Pieter , year =
-
[62]
2020 , eprint =
Longformer: The Long-Document Transformer , author =. 2020 , eprint =
2020
-
[63]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Su, Jianlin and Lu, Yu and Pan, Shengfeng and Murtadha, Ahmed and Wen, Bo and Liu, Yunfeng , year =. 2104.09864 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.