When can a neural operator replace a coarse solve? Architectural principles for two-level preconditioning
Pith reviewed 2026-05-20 01:54 UTC · model grok-4.3
The pith
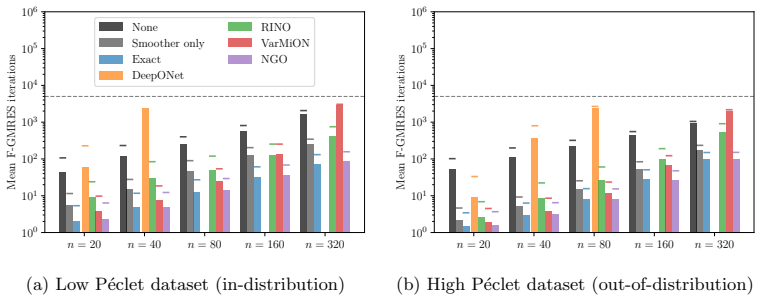
The Neural Green's Operator serves as a Galerkin-type coarse-space correction that matches the iteration count of an exact coarse solve on diffusion and advection-diffusion problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
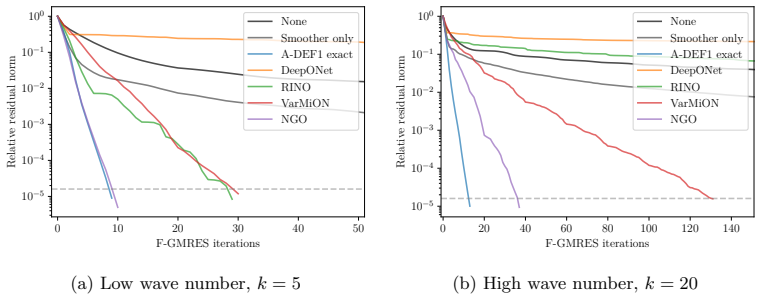
Used as a coarse-space correction, the Neural Green's Operator matches the iteration count of an exact coarse solve on diffusion and advection-diffusion problems. Architectures that deviate from integrating inputs against the output basis produce structurally non-symmetric preconditioned spectra, breakdown of preconditioned conjugate gradients on self-adjoint problems, and stagnation on non-self-adjoint ones. The principle generalises: integrating inputs against the basis used for the output is what allows a neural operator to serve as a Galerkin-type coarse-space correction. Fixed-size learned coarse spaces fail at high Helmholtz wave numbers as a property of the basis rather than the model
What carries the argument
Neural Green's Operator (NGO), a DeepONet variant that discretises inputs by integration against the output basis and treats source terms linearly, thereby functioning as a symmetry-preserving Galerkin projection inside the preconditioner.
If this is right
- The NGO preserves the symmetry needed for conjugate-gradient convergence on self-adjoint diffusion problems.
- It avoids iteration stagnation on non-self-adjoint advection-diffusion operators.
- The observed failure of fixed-size learned coarse spaces at high Helmholtz wave numbers traces to the choice of basis rather than network capacity.
- The basis-integration principle applies to any neural operator intended for Galerkin-type coarse corrections.
Where Pith is reading between the lines
- The same architectural rule could be tested on three-dimensional domains or problems with jumping coefficients to check whether training cost remains modest.
- Retraining the NGO on a modest set of representative operators might allow reuse across families of similar PDEs without per-instance retraining.
- Pairing the NGO with an adaptive or multiscale basis could mitigate the high-wave-number breakdown observed with fixed bases.
- The principle might extend to other numerical roles for neural operators, such as time integrators or nonlinear residual corrections.
Load-bearing premise
Once trained, the neural operator continues to act as a Galerkin projection that preserves the symmetry and spectral properties required by the outer Krylov solver even at high wave numbers or on non-self-adjoint operators.
What would settle it
Apply the two-level preconditioner using the trained Neural Green's Operator to a self-adjoint diffusion problem and check whether the number of preconditioned conjugate-gradient iterations equals or exceeds the count obtained with an exact coarse solve.
Figures




















read the original abstract
Neural operators are increasingly used as drop-in accelerators inside classical numerical methods, but it is rarely clear which architectural ingredients matter for which role. We answer this question for one important role: the coarse-space correction inside a two-level preconditioner for discretised linear partial differential equations. By systematically varying four DeepONet-like architectures along two design axes - input discretisation (sampling versus integration against a basis) and source-term linearity - we show that the favourable corner of this 2$\times$2 design is occupied by a single architecture, the Neural Green's Operator (NGO), and that moving away from it produces predictable failure modes: structurally non-symmetric preconditioned spectra, breakdown of preconditioned conjugate gradients on self-adjoint problems, and stagnation on non-self-adjoint ones. Used as a coarse-space correction, the NGO matches the iteration count of an exact coarse solve on diffusion and advection-diffusion problems. We also characterise the failure of fixed-size learned coarse spaces at high Helmholtz wave numbers, isolating it as a property of the basis rather than of the architecture. The principle generalises: integrating inputs against the basis used for the output is what allows a neural operator to serve as a Galerkin-type coarse-space correction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper systematically compares four DeepONet-style neural operator architectures for use as coarse-space corrections inside two-level preconditioners for discretized linear PDEs. Varying input discretization (sampling vs. integration against a basis) and source-term linearity, it identifies the Neural Green's Operator (NGO) as the sole architecture that matches the iteration counts of an exact coarse solve on both diffusion and advection-diffusion problems. Other corners of the 2x2 design produce predictable failures: non-symmetric preconditioned spectra, breakdown of PCG on self-adjoint problems, and stagnation on non-self-adjoint ones. The work also isolates the breakdown of fixed-size learned coarse spaces at high Helmholtz wave numbers as a basis-size limitation rather than an architectural one, and concludes that integrating inputs against the output basis is the key principle enabling a Galerkin-type coarse correction.
Significance. If the empirical results hold under the reported conditions, the paper supplies concrete architectural guidance for embedding neural operators into classical iterative solvers. The systematic ablation of design axes and the explicit linkage to Galerkin consistency are strengths; the demonstration that NGO can reproduce exact-coarse-solve iteration counts on both self-adjoint and non-self-adjoint model problems would be a useful data point for the growing literature on learned preconditioners.
major comments (2)
- [§4.3, Table 3] §4.3 and Table 3 (advection-diffusion experiments): the claim that NGO matches exact-coarse-solve iteration counts is load-bearing for the central thesis, yet the manuscript provides no quantitative bound on the approximation error ||NGO - true coarse correction|| or on the perturbation of the preconditioned spectrum. For non-self-adjoint operators this is especially critical, as even small symmetry-breaking errors can destroy the effectiveness of the outer Krylov method; a residual-norm or eigenvalue-distribution comparison between NGO and exact coarse solve would directly address the skeptic's concern.
- [§5.2] §5.2 (Helmholtz high-wave-number study): the isolation of failure to basis size rather than architecture is plausible, but the experiments fix the coarse-space dimension while varying wave number; it remains unclear whether the NGO architecture itself would continue to match an exact coarse solve if the basis were enlarged to the point where the exact coarse solve remains effective. A controlled comparison with an exact coarse solve on the same enlarged basis would strengthen the architectural-principle claim.
minor comments (3)
- [Eq. (7)] Equation (7) defining the NGO output projection uses the same symbol for the learned map and the exact Green's operator; a distinct notation would reduce confusion when comparing the two.
- [Figure 4] Figure 4 caption states 'iteration counts are averaged over 5 random right-hand sides' but does not report the standard deviation; adding error bars or a table of per-instance counts would make the robustness claim easier to assess.
- [Introduction] The manuscript cites several prior neural-operator preconditioner papers but does not discuss how the present 2x2 ablation differs from the architectural choices in those works; a short related-work paragraph would clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation for minor revision, and the constructive comments that help strengthen the evidence for the Neural Green's Operator. We address each major comment below and will incorporate the suggested additions into the revised manuscript.
read point-by-point responses
-
Referee: [§4.3, Table 3] §4.3 and Table 3 (advection-diffusion experiments): the claim that NGO matches exact-coarse-solve iteration counts is load-bearing for the central thesis, yet the manuscript provides no quantitative bound on the approximation error ||NGO - true coarse correction|| or on the perturbation of the preconditioned spectrum. For non-self-adjoint operators this is especially critical, as even small symmetry-breaking errors can destroy the effectiveness of the outer Krylov method; a residual-norm or eigenvalue-distribution comparison between NGO and exact coarse solve would directly address the skeptic's concern.
Authors: We agree that a direct quantitative comparison would strengthen the central claim. Although matching iteration counts already provides strong practical evidence of effectiveness, we will add in the revision a comparison of residual norms between the NGO approximation and the exact coarse correction for the advection-diffusion experiments. Where computationally feasible, we will also include a brief analysis or visualization of the preconditioned spectra to quantify perturbations, with particular attention to symmetry preservation in the non-self-adjoint case. These additions will appear as supplementary figures or tables in §4.3. revision: yes
-
Referee: [§5.2] §5.2 (Helmholtz high-wave-number study): the isolation of failure to basis size rather than architecture is plausible, but the experiments fix the coarse-space dimension while varying wave number; it remains unclear whether the NGO architecture itself would continue to match an exact coarse solve if the basis were enlarged to the point where the exact coarse solve remains effective. A controlled comparison with an exact coarse solve on the same enlarged basis would strengthen the architectural-principle claim.
Authors: We acknowledge that the current experiments hold the coarse-space dimension fixed. To more rigorously isolate the failure mode as a basis-size limitation, we will add controlled experiments in the revision that enlarge the basis at high wave numbers and directly compare NGO iteration counts against those of an exact coarse solve on the identical enlarged basis. This will provide the requested side-by-side evidence that the architecture can reproduce exact-coarse-solve behavior once the basis is adequate. revision: yes
Circularity Check
No circularity: empirical architectural comparison is self-contained against numerical benchmarks
full rationale
The paper conducts a systematic empirical study by varying four DeepONet-like architectures along input discretisation and source-term linearity axes, then evaluates their performance as coarse-space corrections inside two-level preconditioners on diffusion and advection-diffusion problems. The central observation that the Neural Green's Operator matches exact-coarse-solve iteration counts is reported directly from these experiments rather than derived from any fitted parameter or self-referential definition. No equations are presented that would reduce the reported iteration counts or spectral properties to the training data by construction, and the generalisation principle (integrating inputs against the output basis) is stated as an observed outcome of the design-space exploration. The study therefore remains self-contained against external numerical benchmarks with no load-bearing self-citation chains or ansatz smuggling detectable from the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of two-level preconditioning and Galerkin coarse-space corrections for discretised linear PDEs hold.
invented entities (1)
-
Neural Green's Operator (NGO)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NGO preconditioner has the form Z C Z^T W … row and column space coinciding with span(Z)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Multigrid-Augmented Deep Learning Preconditioners for the Helmholtz Equation
Y. Azulay and E. Treister. “Multigrid-Augmented Deep Learning Preconditioners for the Helmholtz Equation”. en. In:SIAM Journal on Scientific Computing45.3 (2023), S127– S151.issn: 1064-8275, 1095-7197.doi:10.1137/21M1433514
-
[2]
A resolution independent neural operator
B. Bahmani et al. “A resolution independent neural operator”. In:Computer Methods in Applied Mechanics and Engineering444 (2025).issn: 0045-7825.doi:10 . 1016 / j . cma . 2025.118113
-
[3]
Weak imposition of Dirichlet boundary conditions in fluid mechanics
Y. Bazilevs and T.J.R. Hughes. “Weak imposition of Dirichlet boundary conditions in fluid mechanics”. In:Computers & fluids36.1 (2005), pp. 12–26. 25
work page 2005
-
[4]
Two-Level Preconditioners for the Helmholtz Equation
M. Bonazzoli et al. “Two-Level Preconditioners for the Helmholtz Equation”. In:Domain De- composition Methods in Science and Engineering XXIV. Ed. by P.E. Bjørstad et al. Vol. 125. Lecture Notes in Computational Science and Engineering. Cham: Springer International Pub- lishing, 2018, pp. 139–147.isbn: 978-3-319-93872-1.doi:10.1007/978-3-319-93873-8_11. u...
-
[5]
Spherical fourier neural operators: Learning stable dynamics on the sphere
B. Bonev et al. “Spherical fourier neural operators: Learning stable dynamics on the sphere”. In:International conference on machine learning. PMLR. 2023, pp. 2806–2823
work page 2023
-
[6]
A comparison of coarse spaces for Helmholtz problems in the high fre- quency regime
N. Bootland et al. “A comparison of coarse spaces for Helmholtz problems in the high fre- quency regime”. In:Computers & Mathematics with Applications98 (2021), pp. 239–253. doi:10.1016/j.camwa.2021.07.011
-
[7]
Overlapping Schwarz methods with GenEO coarse spaces for indefi- nite and non-self-adjoint problems
N. Bootland et al. “Overlapping Schwarz methods with GenEO coarse spaces for indefi- nite and non-self-adjoint problems”. In:IMA Journal of Numerical Analysis43.4 (2023), pp. 1899–1936.doi:10.1093/imanum/drac036
-
[8]
Choose a transformer: Fourier or Galerkin
S. Cao. “Choose a transformer: Fourier or Galerkin”. In:Advances in neural information processing systems34 (2021), pp. 24924–24940
work page 2021
-
[9]
Graph Neural Preconditioners for Iterative Solutions of Sparse Linear Systems
J. Chen. “Graph Neural Preconditioners for Iterative Solutions of Sparse Linear Systems”. In:International Conference on Learning Representations. Vol. 2025. 2025, pp. 23942–23967
work page 2025
-
[10]
T. Chen and H. Chen. “Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems”. In:IEEE Transactions on Neural Networks6.4 (1995), pp. 911–917
work page 1995
-
[11]
A coarse space for heterogeneous Helmholtz problems based on the Dirichlet- to-Neumann operator
L. Conen et al. “A coarse space for heterogeneous Helmholtz problems based on the Dirichlet- to-Neumann operator”. In:Journal of Computational and Applied Mathematics271 (2014), pp. 83–99
work page 2014
-
[12]
Can symmetric positive definite (SPD) coarse spaces perform well for indefinite Helmholtz problems?
V. Dolean, M Fry, and M. Langer. “Can symmetric positive definite (SPD) coarse spaces perform well for indefinite Helmholtz problems?” In:Journal of Computational and Applied Mathematics484 (2026), p. 117403.issn: 0377-0427.doi:https : / / doi . org / 10 . 1016 / j.cam.2026.117403.url:https://www.sciencedirect.com/science/article/pii/ S0377042726000683
-
[13]
V. Dolean, P. Jolivet, and F. Nataf.An Introduction to Domain Decomposition Methods. Philadelphia, PA: Society for Industrial and Applied Mathematics, 2015.doi:10.1137/1. 9781611974065. eprint:https://epubs.siam.org/doi/pdf/10.1137/1.9781611974065. url:https://epubs.siam.org/doi/abs/10.1137/1.9781611974065
work page doi:10.1137/1 2015
-
[14]
How Descriptive are GMRES Convergence Bounds?
M. Embree. “How Descriptive are GMRES Convergence Bounds?” In: arXiv:2209.01231 (2022). arXiv:2209.01231 [math].doi:10.48550/arXiv.2209.01231.url:http://arxiv. org/abs/2209.01231
work page doi:10.48550/arxiv.2209.01231.url:http://arxiv 2022
-
[15]
Domain decomposition preconditioning for high- frequency Helmholtz problems with absorption
I. Graham, E. Spence, and E. Vainikko. “Domain decomposition preconditioning for high- frequency Helmholtz problems with absorption”. In:Mathematics of Computation86.307 (2017), pp. 2089–2127
work page 2017
-
[16]
Any nonincreasing convergence curve is possible form GMRES
A. Greenbaum, V. Pt´ ak, and S. Zdenˇ ek. “Any nonincreasing convergence curve is possible form GMRES”. In:SIAM Journal on Matrix Analysis and Applications17 (1996), pp. 465– 469
work page 1996
-
[17]
GNOT: A general neural operator transformer for operator learning
Z. Hao et al. “GNOT: A general neural operator transformer for operator learning”. In: International conference on machine learning. PMLR. 2023, pp. 12556–12569
work page 2023
-
[18]
Generating synthetic data for neural operators
E. Hasani and R.A. Ward. “Generating synthetic data for neural operators”. In:The SMAI Journal of Computational Mathematics11 (2025), pp. 497–516
work page 2025
-
[19]
Learning incomplete factorization precon- ditioners for GMRES
P. H¨ ausner, A. Nieto Juscafresa, and J. Sj¨ olund. “Learning incomplete factorization precon- ditioners for GMRES”. In:Proceedings of the 6th Northern Lights Deep Learning Conference (NLDL). PMLR. 2025
work page 2025
-
[20]
P. H¨ ausner, O. ¨Oktem, and J. Sj¨ olund. “Neural incomplete factorization: learning precondi- tioners for the conjugate gradient method”. en. In:arXiv preprint arXiv:2305.16368 [math] (2024).doi:10.48550/arXiv.2305.16368.url:http://arxiv.org/abs/2305.16368. 26
work page doi:10.48550/arxiv.2305.16368.url:http://arxiv.org/abs/2305.16368 2024
-
[21]
MgNO: Efficient parameterization of linear operators via multi- grid
J. He, X. Liu, and J. Xu. “MgNO: Efficient parameterization of linear operators via multi- grid”. In:International Conference on Learning Representations. Vol. 2024. 2024, pp. 53409– 53428
work page 2024
-
[22]
Hsieh et al.Learning Neural PDE Solvers with Convergence Guarantees
J. Hsieh et al.Learning Neural PDE Solvers with Convergence Guarantees. en. 2019.url: https://arxiv.org/abs/1906.01200v1
-
[23]
A hybrid iterative method based on MIONet for PDEs: Theory and numerical examples
J. Hu and P. Jin. “A hybrid iterative method based on MIONet for PDEs: Theory and numerical examples”. In:Mathematics of Computation(2025). Published electronically. DOI https://doi.org/10.1090/mcom/4086.doi:https://doi.org/10.1090/mcom/4086.url: https://www.ams.org/mcom/0000-000-00/S0025-5718-2025-04086-9/
work page doi:10.1090/mcom/4086.doi:https://doi.org/10.1090/mcom/4086.url: 2025
-
[24]
Resolution invariant deep operator network for PDEs with complex geometries
J. Huang and Y. Qiu. “Resolution invariant deep operator network for PDEs with complex geometries”. In:Journal of Computational Physics522 (2025)
work page 2025
-
[25]
A fast scalable iterative implicit solver with Green’s function-based neural networks
T. Ichimura et al. “A fast scalable iterative implicit solver with Green’s function-based neural networks”. In:2020 IEEE/ACM 11th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems (ScalA). IEEE, 2020, pp. 61–68.url:https://ieeexplore.ieee. org/abstract/document/9308819/
-
[26]
MIONet: Learning Multiple-Input Operators via Tensor Prod- uct
P. Jin, S. Meng, and L. Lu. “MIONet: Learning Multiple-Input Operators via Tensor Prod- uct”. en. In:SIAM Journal on Scientific Computing44.6 (2022), A3490–A3514.issn: 1064- 8275, 1095-7197.doi:10.1137/22M1477751
-
[27]
DeepONet Based Preconditioning Strategies for Solving Parametric Linear Systems of Equations
A. Kopaniˇ c´ akov´ a and G.E. Karniadakis. “DeepONet Based Preconditioning Strategies for Solving Parametric Linear Systems of Equations”. In:SIAM Journal on Scientific Computing 47.1 (2025), pp. C151–C181.issn: 1064-8275, 1095-7197.doi:10.1137/24M162861X
-
[28]
A. Kopaniˇ c´ akov´ a, Y. Lee, and G.E. Karniadakis. “Leveraging Operator Learning to Acceler- ate Convergence of the Preconditioned Conjugate Gradient Method”. In: arXiv:2508.00101 (2025). arXiv:2508.00101 [math].doi:10.48550/arXiv.2508.00101.url:http://arxiv. org/abs/2508.00101
work page doi:10.48550/arxiv.2508.00101.url:http://arxiv 2025
-
[29]
Neural operator: Learning maps between function spaces with applica- tions to PDEs
N. Kovachki et al. “Neural operator: Learning maps between function spaces with applica- tions to PDEs”. In:Journal of Machine Learning Research24.89 (2023), pp. 1–97
work page 2023
-
[30]
B. Lerer, I. Ben-Yair, and E. Treister. “Multigrid-Augmented Deep Learning Precondition- ers for the Helmholtz Equation Using Compact Implicit Layers”. en. In:SIAM Journal on Scientific Computing46.5 (2024), S123–S144.issn: 1064-8275, 1095-7197.doi:10 . 1137 / 23M1583302
work page 2024
-
[31]
R. Li, S. Wang, and C. Wang. “Deep Learning-Enhanced Preconditioning for Efficient Con- jugate Gradient Solvers in Large-Scale PDE Systems”. In:arXiv preprint arXiv:2412.07127 [cs](2024).doi:10.48550/arXiv.2412.07127.url:http://arxiv.org/abs/2412.07127
work page doi:10.48550/arxiv.2412.07127.url:http://arxiv.org/abs/2412.07127 2024
-
[32]
Learning preconditioners for conjugate gradient PDE solvers
Y. Li et al. “Learning preconditioners for conjugate gradient PDE solvers”. In:Interna- tional Conference on Machine Learning. PMLR, 2023, pp. 19425–19439.url:https : / / proceedings.mlr.press/v202/li23e.html
work page 2023
-
[33]
Physics-Informed Neural Operator for Learning Partial Differential Equations
Z. Li and H. Zheng. “Physics-Informed Neural Operator for Learning Partial Differential Equations”. en. In: 1.3 (2024)
work page 2024
-
[34]
Fourier Neural Operator for Parametric Partial Differential Equations
Z. Li et al. “Fourier Neural Operator for parametric partial differential equations”. In:arXiv preprint arXiv:2010.08895 [cs](2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[35]
Multipole graph neural operator for parametric partial differential equations
Z. Li et al. “Multipole graph neural operator for parametric partial differential equations”. In:Advances in Neural Information Processing Systems33 (2020), pp. 6755–6766
work page 2020
-
[36]
Li et al.Neural Preconditioning Operator for Efficient PDE Solves
Z. Li et al.Neural Preconditioning Operator for Efficient PDE Solves. 2025. arXiv:2502. 01337 [cs.CE].url:https://arxiv.org/abs/2502.01337
-
[37]
Green’s functions for preconditioning
D. Loghin. “Green’s functions for preconditioning”. PhD thesis. University of Oxford, 1999. url:https://api.semanticscholar.org/CorpusID:11238315
work page 1999
-
[38]
L. Lu et al. “Learning nonlinear operators via DeepONet based on the universal approxima- tion theorem of operators”. In:Nature Machine Intelligence3.3 (2021), pp. 218–229
work page 2021
-
[39]
Balancing domain decomposition
J. Mandel. “Balancing domain decomposition”. In:Communications in Numerical Methods in Engineering9.3 (1993), pp. 233–241. 27
work page 1993
-
[40]
Neural Green’s operators for parametric partial differential equations
H. A. Melchers, J. H. M. Prins, and M. R. A. Abdelmalik. “Neural Green’s operators for parametric partial differential equations”. In:Computer Methods in Applied Mechanics and Engineering455 (2026).issn: 0045-7825.doi:10.1016/j.cma.2026.118893
-
[41]
Deflation of conjugate gradients with applications to boundary value problems
R. A. Nicolaides. “Deflation of conjugate gradients with applications to boundary value problems”. In:SIAM Journal on Numerical Analysis24.2 (1987), pp. 355–365
work page 1987
-
[42]
A.G. ¨Ozbay et al. “Poisson CNN: Convolutional neural networks for the solution of the Poisson equation on a Cartesian mesh”. In:Data-Centric Engineering2 (2021)
work page 2021
-
[43]
Variationally mimetic operator networks
D. Patel et al. “Variationally mimetic operator networks”. In:Computer Methods in Applied Mechanics and Engineering419 (2024)
work page 2024
-
[44]
Convolutional Neural Operators for robust and accurate learning of PDEs
B. Raonic et al. “Convolutional Neural Operators for robust and accurate learning of PDEs”. In:Advances in Neural Information Processing Systems36 (2024)
work page 2024
-
[45]
Neural operators meet conjugate gradients: the FCG-NO method for efficient PDE solving
A. Rudikov et al. “Neural operators meet conjugate gradients: the FCG-NO method for efficient PDE solving”. In:Proceedings of the 41st International Conference on Machine Learning. Vol. 235. PMLR. arXiv:2402.05598. 2024, pp. 42766–42782
-
[46]
H. Ruelmann, M. Geveler, and S. Turek. “On the prospects of using machine learning for the numerical simulation of PDEs: training neural networks to assemble approximate inverses”. In: (2018).url:https://www.mathematik.tu-dortmund.de/papers/RuelmannGevelerTurek2018. pdf
work page 2018
-
[47]
A Flexible Inner-Outer Preconditioned GMRES Algorithm
Y. Saad. “A Flexible Inner-Outer Preconditioned GMRES Algorithm”. In:SIAM Journal on Scientific Computing14.2 (1993), pp. 461–469.issn: 1064-8275, 1095-7197.doi:10.1137/ 0914028
work page 1993
-
[48]
J. M. Tang et al. “Theoretical and numerical comparison of various projection methods de- rived from deflation, domain decomposition and multigrid methods”. In: (2007).url:https: //repository.tudelft.nl/file/File_95dd52de-1a07-4d78-9b1b-968b25d7fd93
work page 2007
-
[49]
J.M. Tang et al. “Comparison of Two-Level Preconditioners Derived from Deflation, Domain Decomposition and Multigrid Methods”. In:Journal of Scientific Computing39.3 (2009), pp. 340–370.issn: 0885-7474, 1573-7691.doi:10.1007/s10915-009-9272-6
-
[50]
The Finite Volume-Complete Flux Scheme for Advection-Diffusion-Reaction Equations
J.H.M. ten Thije-Boonkkamp and M.J.H. Anthonissen. “The Finite Volume-Complete Flux Scheme for Advection-Diffusion-Reaction Equations”. In:Journal of Scientific Computing 46.1 (2011), pp. 47–70.issn: 1573-7691.doi:10.1007/s10915-010-9388-8
-
[51]
A. Toselli and O. Widlund.Domain decomposition methods-algorithms and theory. Vol. 34. Springer Science & Business Media, 2004
work page 2004
-
[52]
V. Trifonov et al. “Learning from linear algebra: A graph neural network approach to precon- ditioner design for conjugate gradient solvers”. In:Computational Methods in Applied Math- ematics0 (2026).url:https://www.degruyterbrill.com/document/doi/10.1515/cmam- 2025-0170/html
-
[53]
U. Trottenberg, C. W. Oosterlee, and A. Sch¨ uller.Multigrid. Academic Press, 2001
work page 2001
-
[54]
Wesseling.An introduction to multigrid methods
P. Wesseling.An introduction to multigrid methods. English. Corr. reprint. Philadelphia: R.T. Edwards, 2004.isbn: 978-1-930217-08-9
work page 2004
-
[55]
Y. Wu et al. “Are Deep Learning Based Hybrid PDE Solvers Reliable? Why Training Paradigms and Update Strategies Matter”. In: arXiv:2602.06842 (2026). arXiv:2602.06842 [math].doi:10.48550/arXiv.2602.06842.url:http://arxiv.org/abs/2602.06842
work page doi:10.48550/arxiv.2602.06842.url:http://arxiv.org/abs/2602.06842 2026
-
[56]
Blending neural operators and relaxation methods in PDE numerical solvers
E. Zhang et al. “Blending neural operators and relaxation methods in PDE numerical solvers”. In:Nature Machine Intelligence6.11 (2024), pp. 1303–1313.issn: 2522-5839.doi: 10.1038/s42256-024-00910-x. 28 A PDE details A.1 Diffusion The exact equation is as follows: −∇ ·(θ∇u) =fon Ω = (0,1) 2,(10a) θ∇u·n=ηon Γ N ={top,bottom},(10b) θu=gon Γ D ={left,right}.(...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.