Hessian-informed, Coordinate Friendly Hamiltonian Monte Carlo in Linear Time
Pith reviewed 2026-06-27 22:42 UTC · model grok-4.3
The pith
RHMC fixed-point iterations with diagonal preconditioners reduce from O(d^2) to O(d) time for targets with coordinate-friendly structure via compute-graph manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
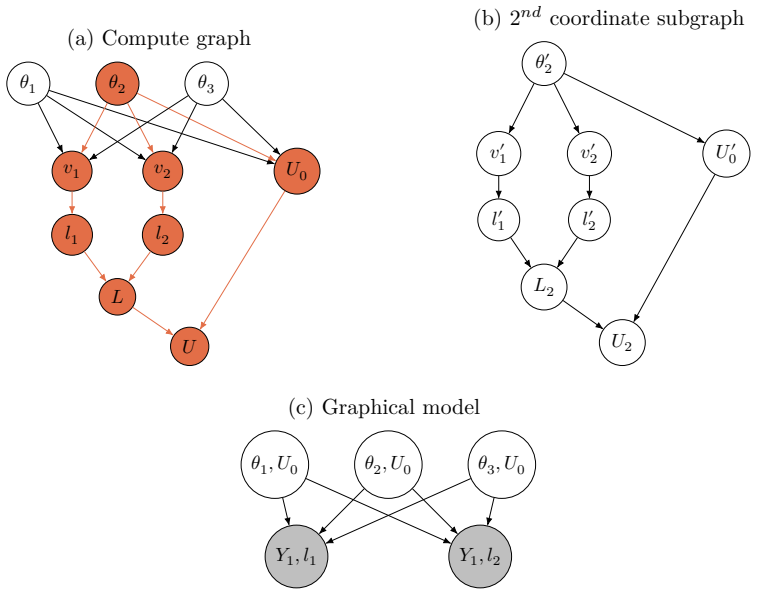
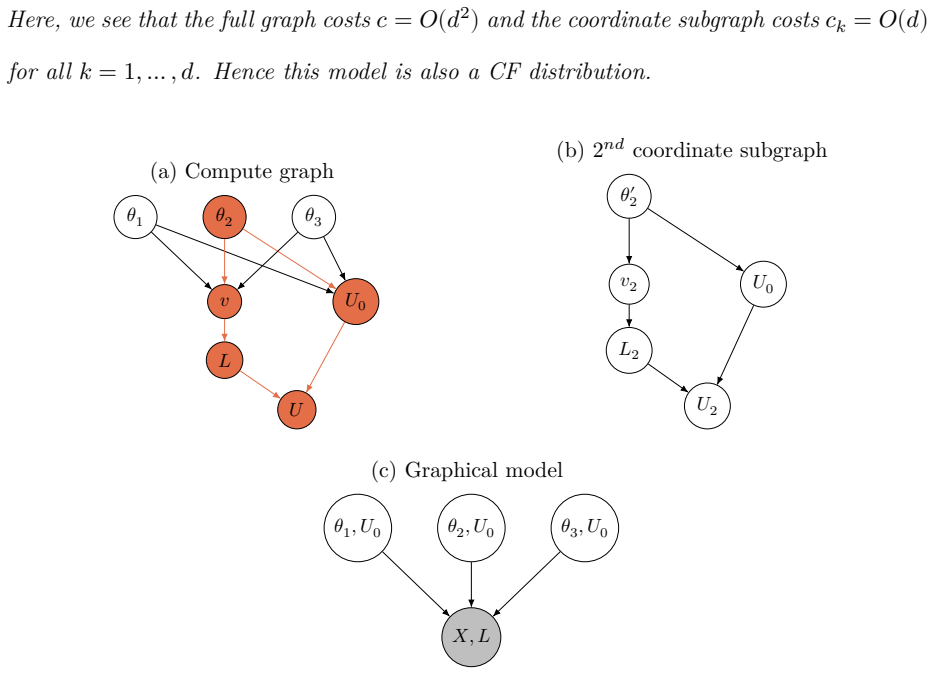
For targets possessing coordinate-friendly structure, the fixed-point iterations of diagonal-preconditioned RHMC can be executed in O(d) rather than O(d^2) time by manipulating the compute graph so that only linear-cost operations are performed while the mathematical correctness of each iteration is preserved. The class includes generalized linear models together with certain dense and sparse graphical models, and the same graph manipulation can be automated for black-box targets.
What carries the argument
Compute-graph manipulation of the fixed-point iterations required by diagonal-preconditioned RHMC, which isolates coordinate-wise contributions to achieve linear scaling.
If this is right
- RHMC becomes practical for high-dimensional generalized linear models without incurring quadratic cost per iteration.
- The same linear-time property holds for both dense and sparse graphical models that satisfy the coordinate-friendly condition.
- Automation through graph manipulation extends the method to black-box targets that internally possess the required structure.
- Empirical sample quality per unit compute time exceeds that of position-independent and position-dependent HMC baselines.
Where Pith is reading between the lines
- The graph-rewrite technique could be adapted to lower the cost of other Hessian-informed MCMC algorithms that currently scale quadratically.
- In regimes with thousands of dimensions the linear scaling may make previously intractable models accessible to position-dependent preconditioning.
- The breadth of coordinate-friendly structures could be mapped by applying the method to additional families of graphical models beyond those tested.
Load-bearing premise
The target must possess a coordinate-friendly structure that permits the graph manipulation to deliver true linear cost while leaving the fixed-point iteration mathematically unchanged.
What would settle it
A wall-clock timing experiment on a logistic-regression target that shows iteration cost growing faster than linearly with dimension, or that yields samples whose distribution deviates from the known posterior.
Figures
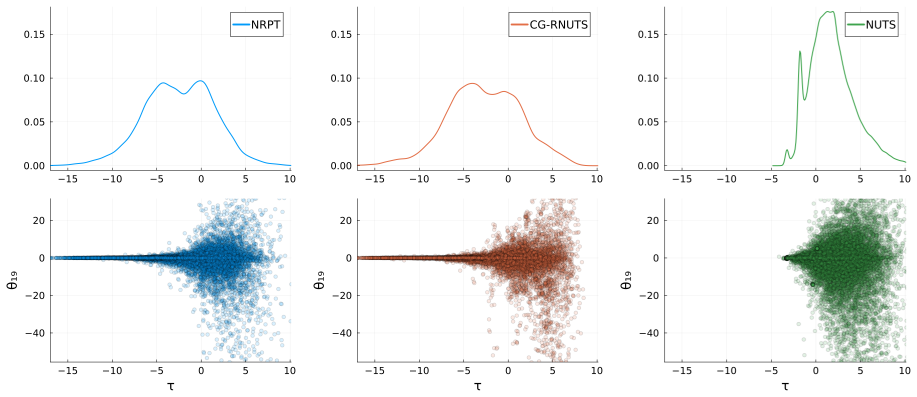
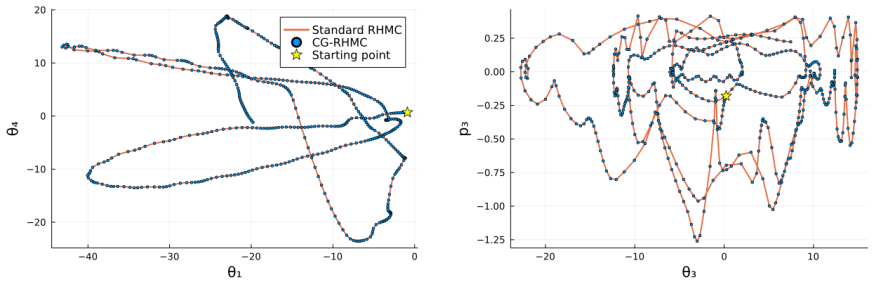
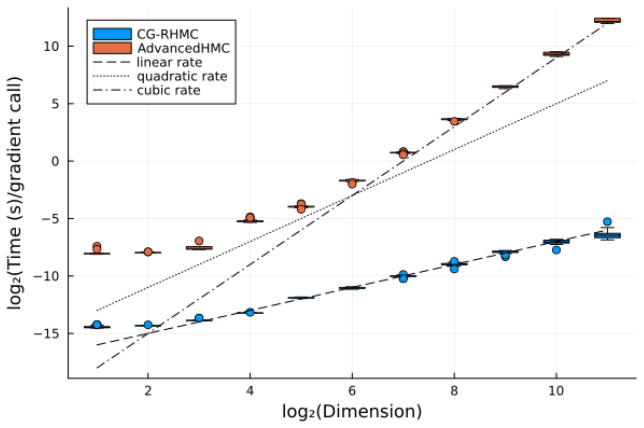
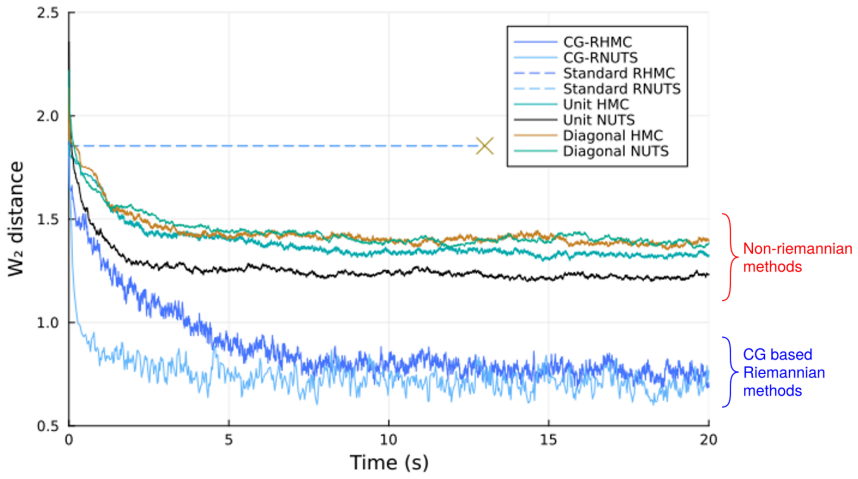
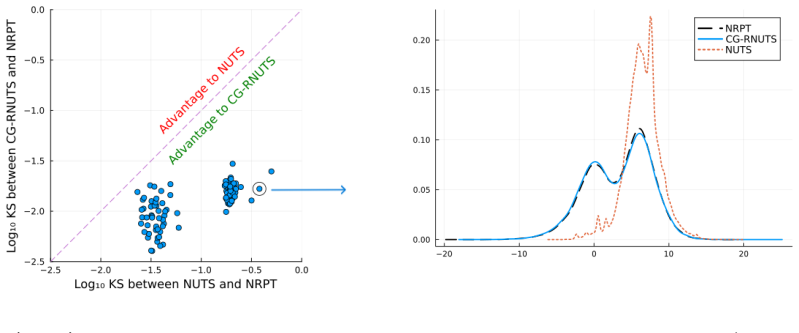
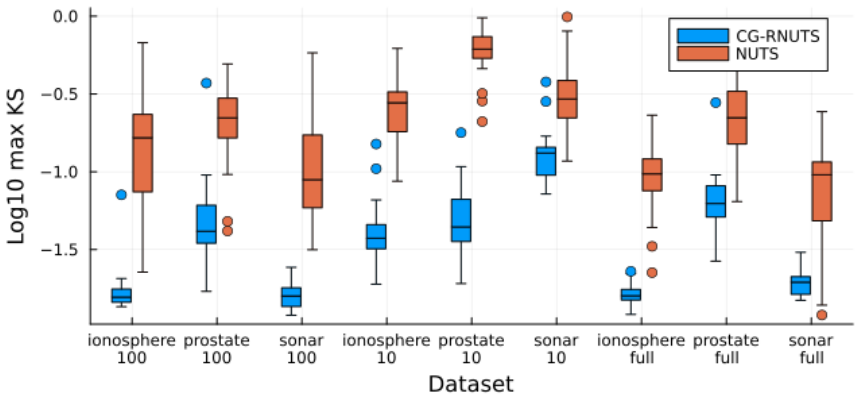
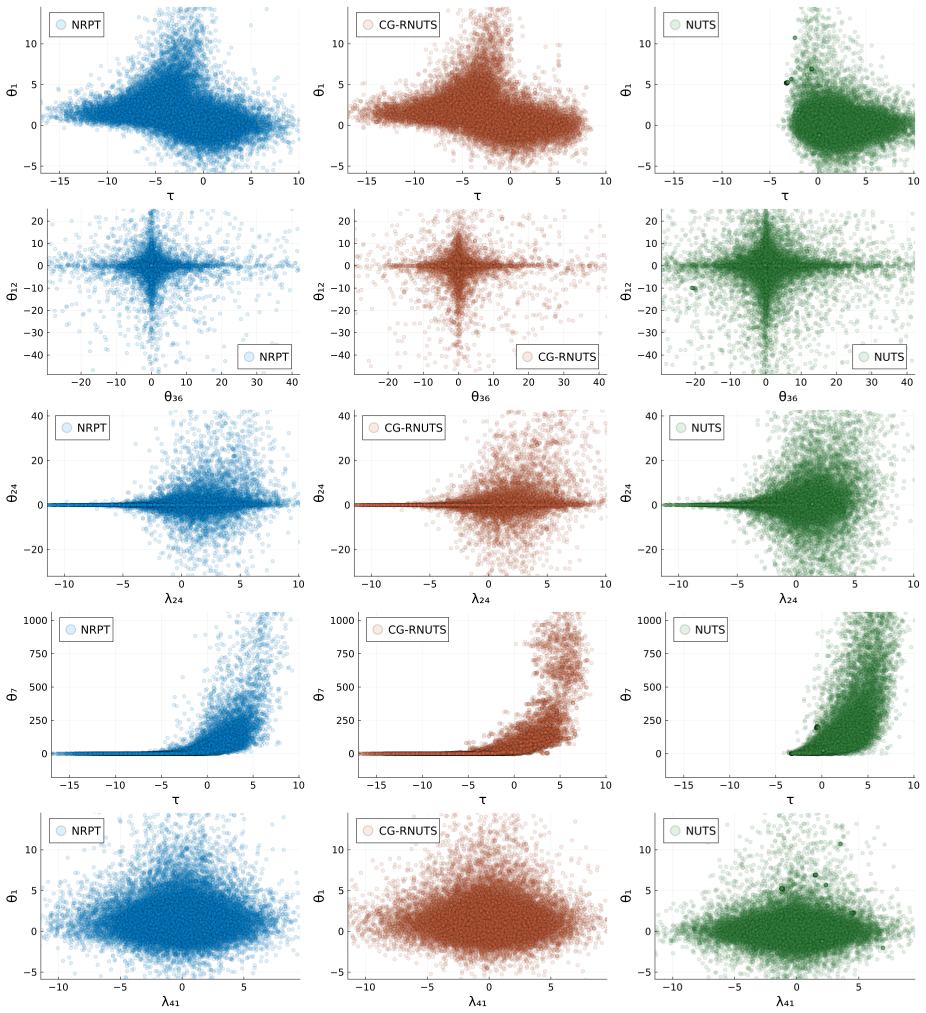
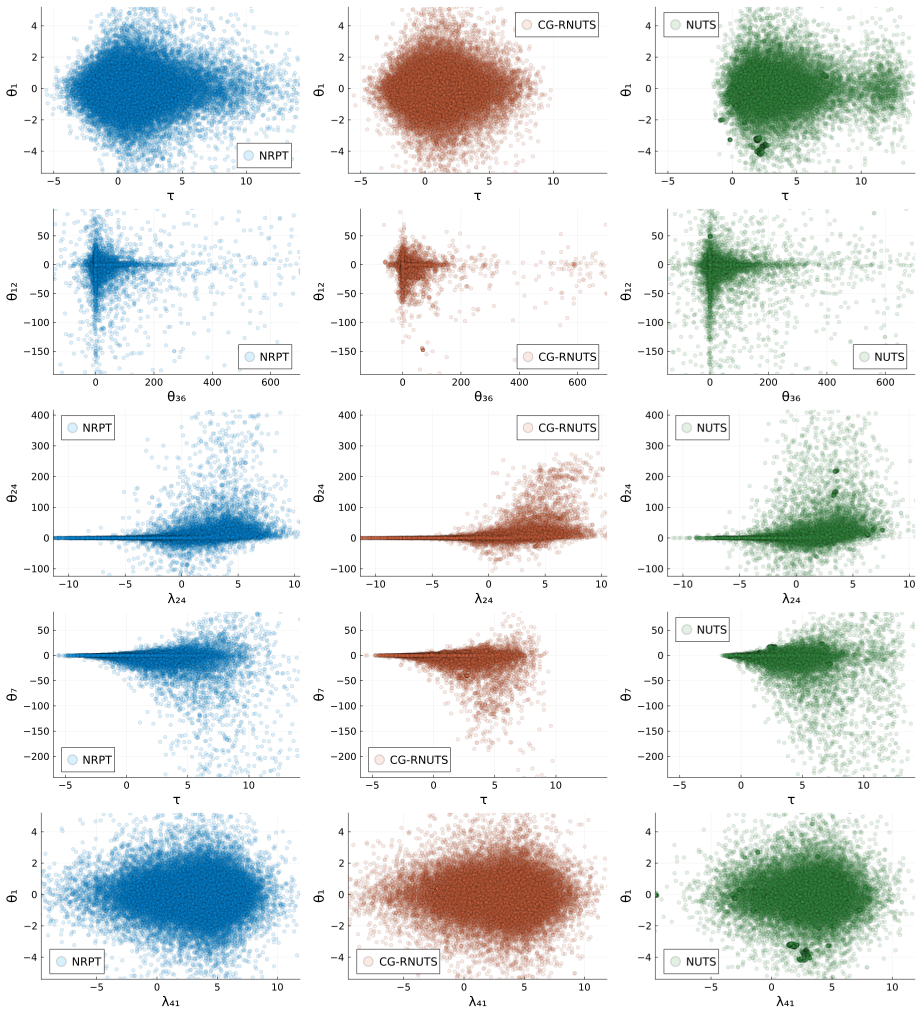
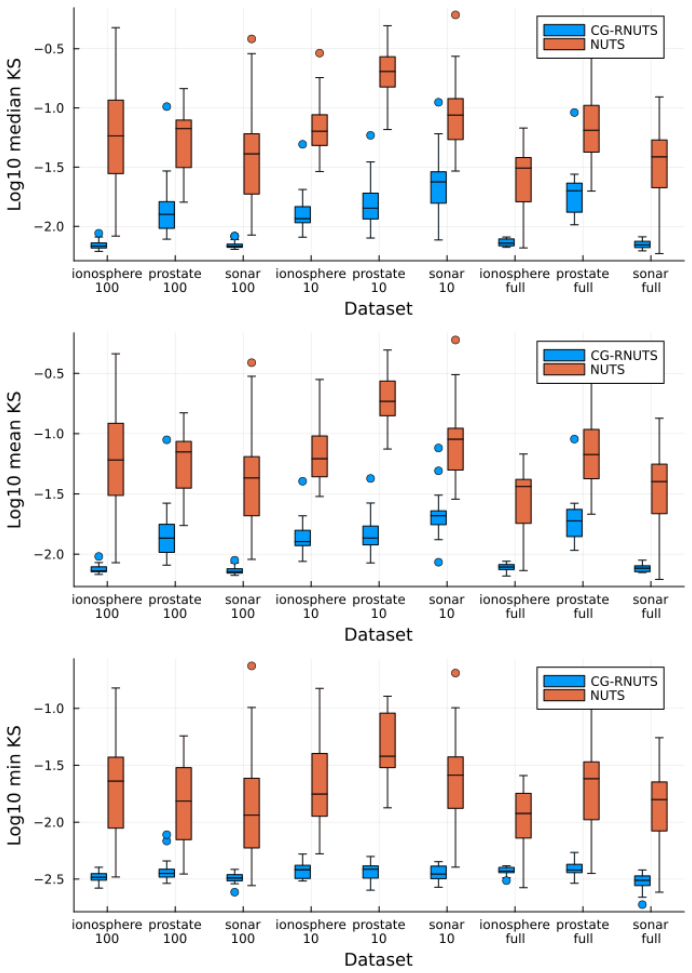
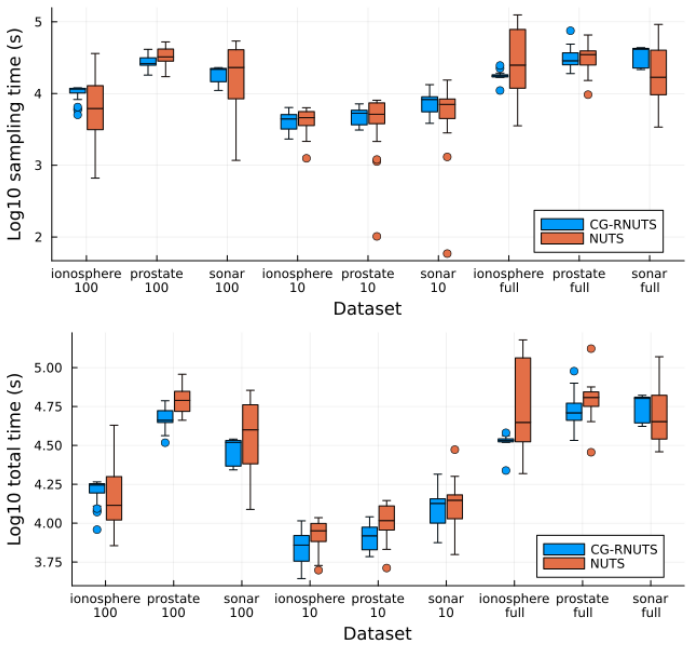
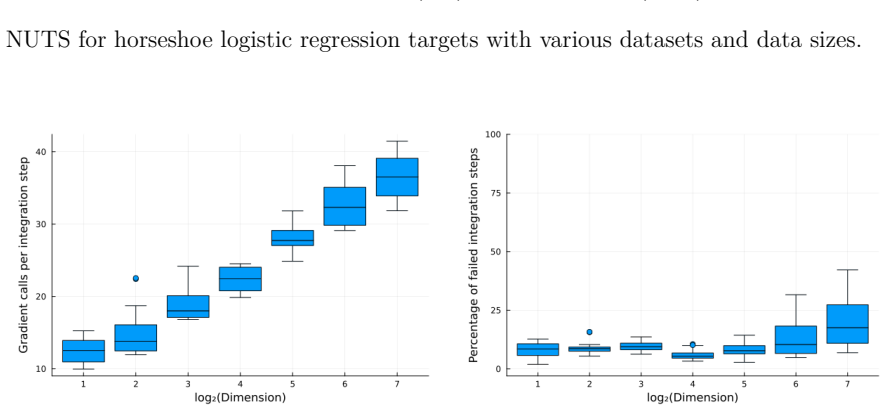
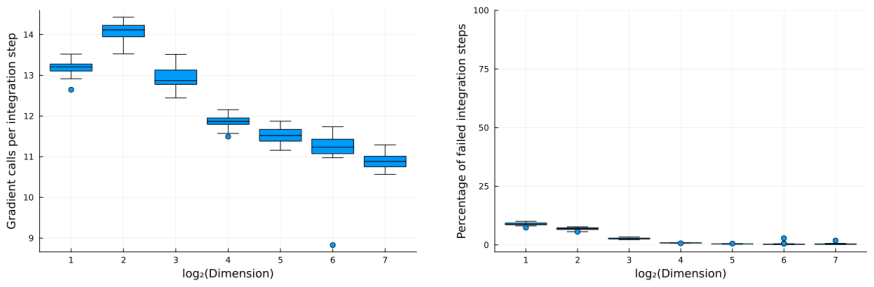
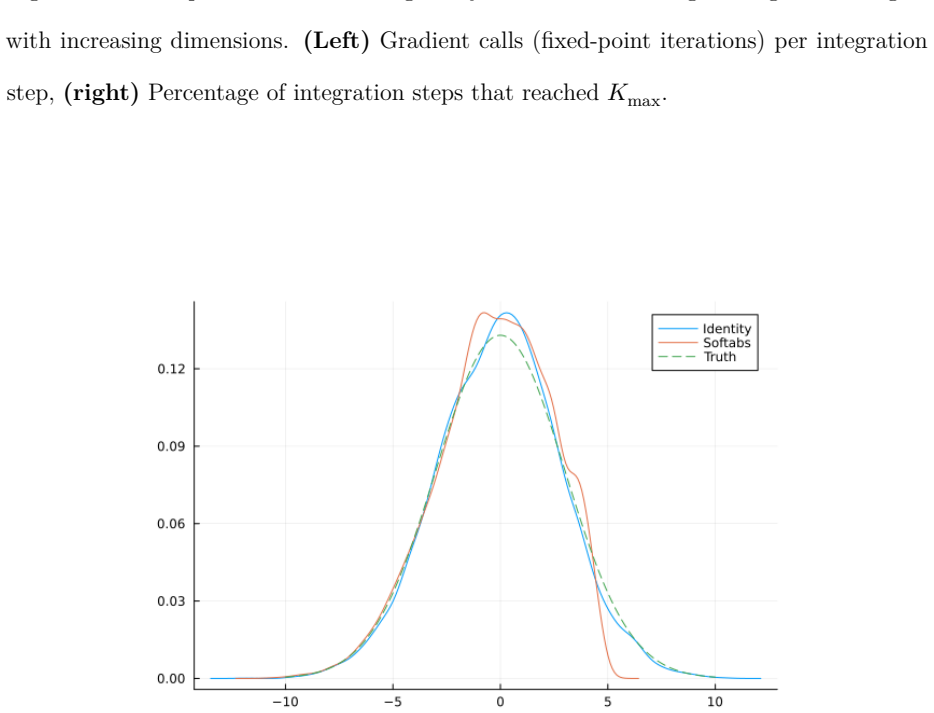
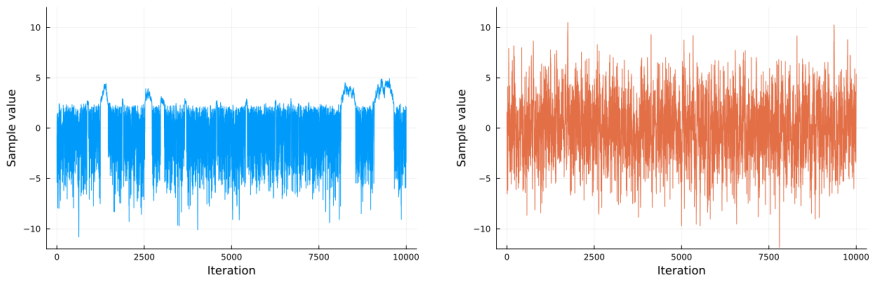
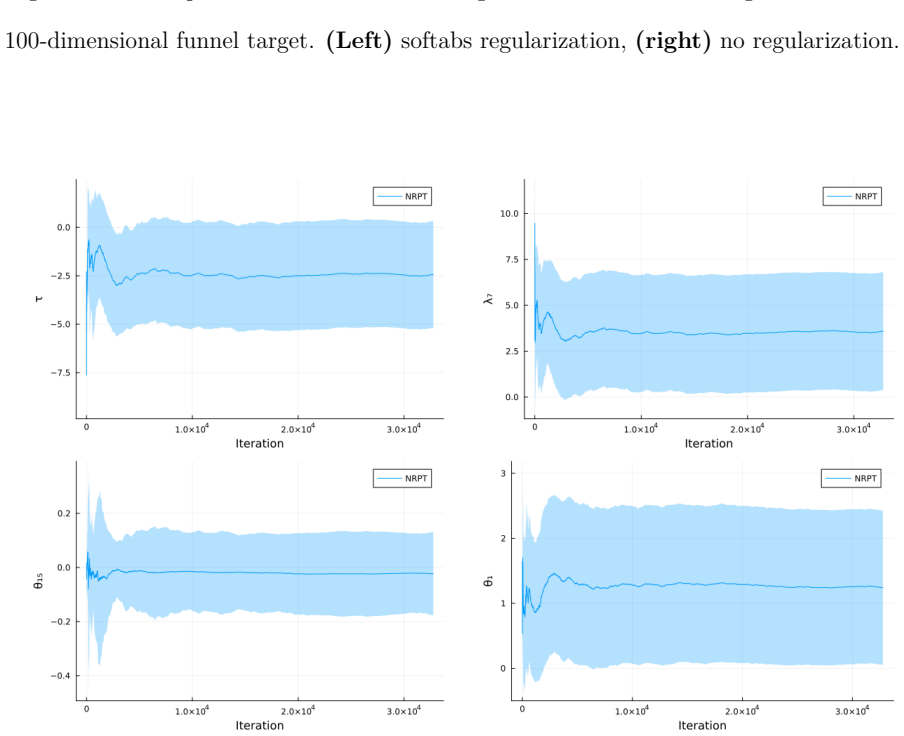
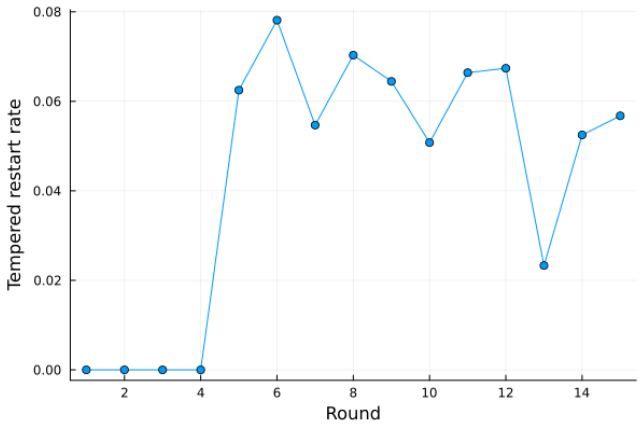
read the original abstract
Riemannian Hamiltonian Monte Carlo (RHMC) is a promising MCMC methodology thanks to its ability to accommodate position-dependent preconditioning and multi-step proposals. While RHMC performs well in low dimensions, it becomes infeasible in high dimensions due to its $O(d^3)$ cost per fixed-point iteration, where $d$ is the dimension of the target density. Even when the position-dependent preconditioner is based on the diagonal of the Hessian, the cost is still $O(d^2)$ per fixed-point iteration. In this paper, we propose a computational method to reduce the computational complexity of RHMC fixed-point iterations with diagonal preconditioners from $O(d^2)$ to $O(d)$ for targets with ``coordinate friendly'' structures. This distribution class includes generalized linear models as well as other dense and sparse graphical models. The method is expressed as manipulating the compute graph and can therefore be automated to work on black box targets. Finally, we show empirically that our implementation of RHMC results in better sample quality per unit of compute time for various target distributions compared to state-of-the-art HMC NUTS algorithms with both position-independent and position-dependent preconditioners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for targets with coordinate-friendly structure (including GLMs and certain graphical models), the fixed-point iteration inside diagonal-preconditioned RHMC can be rewritten via compute-graph manipulation to achieve O(d) cost per iteration while remaining numerically identical to the original O(d²) version; the resulting method is automatable for black-box targets and empirically yields higher effective samples per unit compute time than NUTS with both static and position-dependent preconditioners.
Significance. If the rewritten iteration is provably equivalent, the work would supply a practical route to position-dependent HMC at linear cost for an important model class, with the automation angle offering a path toward integration in probabilistic programming frameworks. The empirical comparisons provide concrete evidence of wall-clock gains on the tested targets.
major comments (2)
- [§3 (compute-graph manipulation)] The central claim that the compute-graph rewrite leaves the fixed-point equation unchanged (and therefore preserves symplecticity and reversibility) is load-bearing yet unsupported by an explicit algebraic identity or inductive argument. No section derives that the reordered operations return exactly the same numerical solution for arbitrary coordinate-friendly targets; the abstract and §3 treat equivalence as automatic once the structure is present.
- [§3, Algorithm 1] The O(d) complexity claim rests on the assumption that cross-coordinate dependencies introduced by the diagonal metric in the momentum update are fully captured by the reordered graph; if any dependency is inadvertently dropped, the integrator ceases to be measure-preserving. The manuscript supplies no general proof that this does not occur for the stated class of models.
minor comments (2)
- [§2] Notation for the fixed-point map and the diagonal preconditioner is introduced without a compact reference equation; adding a single displayed equation early in §2 would improve readability.
- [§5] The experimental section reports effective sample size per second but does not tabulate the raw iteration counts or the observed per-iteration flop counts; including these would allow direct verification of the claimed linear scaling.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the importance of rigorously establishing equivalence and measure preservation. We address the two major comments below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3 (compute-graph manipulation)] The central claim that the compute-graph rewrite leaves the fixed-point equation unchanged (and therefore preserves symplecticity and reversibility) is load-bearing yet unsupported by an explicit algebraic identity or inductive argument. No section derives that the reordered operations return exactly the same numerical solution for arbitrary coordinate-friendly targets; the abstract and §3 treat equivalence as automatic once the structure is present.
Authors: We agree that an explicit derivation is needed. The reordering operates only on independent sub-expressions permitted by the coordinate-friendly structure (i.e., the Hessian diagonal and gradient factorizations that admit per-coordinate updates). In the revision we will insert a short inductive argument in §3 showing that, for any target whose log-density and Hessian diagonal admit the stated factorization, the fixed-point map computed on the reordered graph is algebraically identical to the original map. This identity immediately implies that symplecticity and reversibility are unchanged. revision: yes
-
Referee: [§3, Algorithm 1] The O(d) complexity claim rests on the assumption that cross-coordinate dependencies introduced by the diagonal metric in the momentum update are fully captured by the reordered graph; if any dependency is inadvertently dropped, the integrator ceases to be measure-preserving. The manuscript supplies no general proof that this does not occur for the stated class of models.
Authors: The coordinate-friendly class is defined precisely so that the only cross-coordinate dependencies arise through the shared diagonal metric; the graph rewrite is constructed to retain every such dependency. We will augment the revision with a general argument (again inductive) that every momentum-update term present in the original O(d²) iteration appears unchanged in the reordered O(d) version, thereby preserving the measure. The same argument covers the models listed in the paper (GLMs and the indicated graphical models). revision: yes
Circularity Check
No circularity; algorithmic graph rewrite is an independent computational technique.
full rationale
The paper's core contribution is a compute-graph manipulation that rewrites fixed-point iterations for diagonal-preconditioned RHMC to achieve O(d) cost on coordinate-friendly targets. The abstract and claims present this as an explicit algorithmic transformation that preserves the original iteration's output for the stated distribution class, without any self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the claimed equivalence to prior author work. No derivation chain collapses by construction; the method is offered as a verifiable rewrite applicable to black-box targets, making the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard properties of Hamiltonian dynamics and fixed-point iterations hold for the RHMC proposal.
- domain assumption Targets belong to the coordinate-friendly class (GLMs, dense/sparse graphical models) for which the linear-time reduction applies.
Reference graph
Works this paper leans on
-
[1]
and Hazan, E
Agarwal, N., Bullins, B. and Hazan, E. [2017], ‘Second-order stochastic optimization for machine learning in linear time’, Journal of Machine Learning Research 18(116), 1– 40
2017
-
[2]
[2013a], A general metric for Riemannian manifold Hamiltonian Monte 29 Carlo, in ‘International Conference on Geometric Science of Information’, Springer, pp
Betancourt, M. [2013a], A general metric for Riemannian manifold Hamiltonian Monte 29 Carlo, in ‘International Conference on Geometric Science of Information’, Springer, pp. 327–334
-
[3]
[2017], ‘A conceptual introduction to Hamiltonian Monte Carlo’, arXiv:1701.02434
Betancourt, M. [2017], ‘A conceptual introduction to Hamiltonian Monte Carlo’, arXiv:1701.02434
Pith/arXiv arXiv 2017
-
[4]
Betancourt, M. J. [2013 b], ‘Generalizing the No-U-Turn sampler to Riemannian man- ifolds’, arXiv:1304.1920
Pith/arXiv arXiv 2013
-
[5]
and Roberts, G
Bierkens, J., Fearnhead, P. and Roberts, G. [2019], ‘The Zig-zag process and super-efficient sampling for Bayesian analysis of big data’, The Annals of Statistics 47(3), 1288–1320
2019
-
[6]
and Bouchard-Côté, A
Biron-Lattes, M., Surjanovic, N., Syed, S., Campbell, T. and Bouchard-Côté, A. [2024], AutoMALA: Locally adaptive Metropolis-adjusted Langevin algorithm, in ‘Proceed- ings of The 27th International Conference on Artificial Intelligence and Statistics’, PMLR, pp. 4600–4608
2024
-
[7]
Bou-Rabee, N., Carpenter, B., Kleppe, T. S. and Liu, S. [2025], ‘The within-orbit adaptive leapfrog no-u-turn sampler’, arXiv preprint arXiv:2506.18746
arXiv 2025
-
[8]
Bouchard-Côté, A., Vollmer, S. J. and Doucet, A. [2018], ‘The Bouncy Particle sam- pler: A nonreversible rejection-free Markov chain Monte Carlo method’, Journal of the American Statistical Association 113(522), 855–867
2018
-
[9]
Brofos, J. A. and Lederman, R. R. [2021 a], ‘On numerical considerations for Rieman- nian manifold Hamiltonian Monte Carlo’, arXiv:2111.09995
arXiv 2021
-
[10]
and Lederman, R
Brofos, J. and Lederman, R. R. [2021 b], Evaluating the implicit midpoint integrator for Riemannian Hamiltonian Monte Carlo, in ‘Proceedings of The 38th International Conference on Machine Learning’, PMLR, pp. 1072–1081. 30
2021
-
[11]
M., Polson, N
Carvalho, C. M., Polson, N. G. and Scott, J. G. [2009], Handling sparsity via the horse- shoe, in ‘Proceedings of The 12th International Conference on Artificial Intelligence and Statistics’, PMLR, pp. 73–80
2009
-
[12]
and Vempala, S
Chen, Z. and Vempala, S. S. [2022], ‘Optimal convergence rate of Hamiltonian Monte Carlo for strongly logconcave distributions’, Theory of Computing 18, 1–18
2022
-
[13]
Chevallier, A., Power, S. and Sutton, M. [2025], ‘Towards practical pdmp sampling: Metropolis adjustments, locally adaptive step-sizes, and nuts-based time lengths’, arXiv preprint arXiv:2503.11479
Pith/arXiv arXiv 2025
-
[14]
[1988], ‘Global Monte Carlo algorithms for many-fermion systems’, Physi- cal Review D 38(4), 1228–1238
Creutz, M. [1988], ‘Global Monte Carlo algorithms for many-fermion systems’, Physi- cal Review D 38(4), 1228–1238
1988
-
[15]
Dalalyan, A. S. [2017], ‘Theoretical Guarantees for Approximate Sampling from Smooth and Log-Concave Densities’, Journal of the Royal Statistical Society Series B: Statistical Methodology 79(3), 651–676
2017
-
[16]
D., Pendleton, B
Duane, S., Kennedy, A. D., Pendleton, B. J. and Roweth, D. [1987], ‘Hybrid Monte Carlo’, Physics letters B 195(2), 216–222
1987
-
[17]
and Vempala, S
Gatmiry, K., Kelner, J. and Vempala, S. S. [2024], Sampling polytopes with Rieman- nian HMC: Faster mixing via the Lewis weights barrier, in ‘Proceedings of The 37th Annual Conference on Learning Theory’, PMLR, pp. 1796–1881
2024
-
[18]
and Calderhead, B
Girolami, M. and Calderhead, B. [2011], ‘Riemann manifold Langevin and Hamilto- nian Monte Carlo methods’, Journal of the Royal Statistical Society Series B: Statis- tical Methodology 73(2), 123–214
2011
-
[19]
and Walther, A
Griewank, A. and Walther, A. [2008], Evaluating derivatives: Principles and techniques of algorithmic differentiation , SIAM. 31
2008
-
[20]
and Lubich, C
Hairer, E., Hochbruck, M., Iserles, A. and Lubich, C. [2006], ‘Geometric numerical integration’, Oberwolfach Reports 3(1), 805–882
2006
-
[21]
and Klami, A
Hartmann, M., Girolami, M. and Klami, A. [2022], Lagrangian manifold Monte Carlo on Monge patches, in ‘Proceedings of The 25th International Conference on Artificial Intelligence and Statistics’, PMLR, pp. 4764–4781
2022
-
[22]
Hird, M. and Livingstone, S. [2023], ‘Quantifying the effectiveness of linear precondi- tioning in Markov chain Monte Carlo’, arXiv:2312.04898
arXiv 2023
-
[23]
Hird, M. and Livingstone, S. [2026], ‘High-dimensional Adaptive MCMC with Reduced Computational Complexity’, arXiv:2604.09286
Pith/arXiv arXiv 2026
-
[24]
Hoffman, M. D. and Gelman, A. [2014], ‘The No-U-Turn Sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo’, Journal of Machine Learning Research 15(47), 1593–1623
2014
-
[25]
and Shahbaba, B
Holbrook, A., Lan, S., Vandenberg-Rodes, A. and Shahbaba, B. [2018], ‘Geodesic Lagrangian Monte Carlo over the space of positive definite matrices: with applica- tion to Bayesian spectral density estimation’, Journal of Statistical Computation and Simulation 88(5), 982–1002
2018
-
[26]
[2018], ‘Don’t unroll adjoint: Differentiating SSA-form programs’, arXiv:1810.07951
Innes, M. [2018], ‘Don’t unroll adjoint: Differentiating SSA-form programs’, arXiv:1810.07951
Pith/arXiv arXiv 2018
-
[27]
Jordan, M. I. [2004], ‘Graphical Models’, Statistical Science 19(1), 140–155
2004
-
[28]
Kailas, M., Vihola, M. and Wallin, J. [2026], ‘Hierarchical Riemannian manifold Hamil- tonian Monte Carlo algorithms’, arXiv:2604.09832
Pith/arXiv arXiv 2026
-
[29]
Kleppe, T. S. [2018], ‘Modified Cholesky Riemann manifold Hamiltonian Monte Carlo: 32 exploiting sparsity for fast sampling of high-dimensional targets’, Statistics and Com- puting 28(4), 795–817
2018
-
[30]
Kleppe, T. S. [2022], ‘Connecting the Dots: Numerical Randomized Hamiltonian Monte Carlo with State-dependent Event Rates’, Journal of Computational and Graph- ical Statistics 31(4), 1238–1253
2022
-
[31]
Kleppe, T. S. [2024], ‘Log-density gradient covariance and automatic metric ten- sors for Riemann manifold Monte Carlo methods’, Scandinavian Journal of Statistics 51(3), 1206–1229
2024
-
[32]
and Vempala, S
Kook, Y., Lee, Y.-T., Shen, R. and Vempala, S. [2022], Sampling with Riemannian Hamiltonian Monte Carlo in a constrained space, in ‘Advances in Neural Information Processing Systems’, Vol. 35, Curran Associates, Inc., pp. 31684–31696
2022
-
[33]
T., Shen, R
Kook, Y., Lee, Y. T., Shen, R. and Vempala, S. [2023], Condition-number-independent Convergence Rate of Riemannian Hamiltonian Monte Carlo with Numerical Integra- tors, in ‘Proceedings of The 36th Conference on Learning Theory’, PMLR, pp. 4504– 4569
2023
-
[34]
Langmore, I., Dikovsky, M., Geraedts, S., Norgaard, P. and Von Behren, R. [2019], ‘A condition number for Hamiltonian Monte Carlo’, arXiv:1905.09813
arXiv 2019
-
[35]
and Reich, S
Leimkuhler, B. and Reich, S. [2005], Simulating Hamiltonian dynamics , Cambridge Monographs on Applied and Computational Mathematics, Cambridge University Press
2005
-
[36]
[2021], ‘Geometric ergodicity of the random walk Metropolis with position-dependent proposal covariance’, Mathematics 9(4), 341
Livingstone, S. [2021], ‘Geometric ergodicity of the random walk Metropolis with position-dependent proposal covariance’, Mathematics 9(4), 341. 33
2021
-
[37]
and Wang, L
Lu, J. and Wang, L. [2022], ‘On explicit 𝐿2-convergence rate estimate for piecewise de- terministic Markov processes in MCMC algorithms’, The Annals of Applied Probability 32(2), 1333–1361
2022
-
[38]
and Bouchard-Cote, A
Luu, S., Xu, Z., Surjanovic, N., Biron-Lattes, M., Campbell, T. and Bouchard-Cote, A. [2025], Is Gibbs sampling faster than Hamiltonian Monte Carlo on GLMs?, in ‘Pro- ceedings of The 28th International Conference on Artificial Intelligence and Statistics’, PMLR, pp. 2881–2889
2025
-
[39]
Mackenze, P. B. [1989], ‘An improved hybrid Monte Carlo method’, Physics Letters B 226(3), 369–371
1989
-
[40]
and Swersky, K
Martens, J., Sutskever, I. and Swersky, K. [2012], Estimating the Hessian by Back- propagating Curvature, in ‘Proceedings of The 29th International Conference on Ma- chine Learning’, PMLR, pp. 963–970
2012
-
[41]
and Churavy, V
Moses, W. and Churavy, V. [2020], Instead of Rewriting Foreign Code for Machine Learning, Automatically Synthesize Fast Gradients, in ‘Advances in Neural Informa- tion Processing Systems’, Vol. 33, Curran Associates, Inc., pp. 12472–12485
2020
-
[42]
Neal, R. M. [2003], ‘Slice sampling’, The Annals of Statistics 31(3), 705–767
2003
-
[43]
Neal, R. M. [2011], MCMC using Hamiltonian dynamics, in ‘Handbook of Markov Chain Monte Carlo’, Chapman and Hall/CRC, pp. 113–162
2011
-
[44]
[2012], ‘Efficiency of coordinate descent methods on huge-scale optimiza- tion problems’, SIAM Journal on Optimization 22(2), 341–362
Nesterov, Y. [2012], ‘Efficiency of coordinate descent methods on huge-scale optimiza- tion problems’, SIAM Journal on Optimization 22(2), 341–362
2012
-
[45]
Paquet, U. and Fraccaro, M. [2018], ‘An efficient implementation of Riemannian man- ifold Hamiltonian Monte Carlo for Gaussian process models’, arXiv:1810.11893 . 34
Pith/arXiv arXiv 2018
-
[46]
Peng, Z., Wu, T., Xu, Y., Yan, M. and Yin, W. [2016], ‘Coordinate friendly structures, algorithms and applications’, arXiv:1601.00863
Pith/arXiv arXiv 2016
-
[47]
Sejnowski, T. and Gorman, R. [1988], ‘Connectionist bench (sonar, mines vs. rocks)’, UCI Machine Learning Repository. URL: https://doi.org/10.24432/C5T01Q
-
[48]
Sigillito, V., Wing, S., Hutton, L. and Baker, K. [1989], ‘Ionosphere’, UCI Machine Learning Repository. URL: https://doi.org/10.24432/C5W01B
-
[49]
G., Ross, K., Jackson, D
Singh, D., Febbo, P. G., Ross, K., Jackson, D. G., Manola, J., Ladd, C., Tamayo, P., Renshaw, A. A., D’Amico, A. V., Richie, J. P. et al. [2002], ‘Gene expression correlates of clinical prostate cancer behavior’, Cancer Cell 1(2), 203–209
2002
-
[50]
and Bouchard- Cote, A
Surjanovic, N., Biron-Lattes, M., Tiede, P., Syed, S., Campbell, T. and Bouchard- Cote, A. [2025], ‘Pigeons.jl: Distributed sampling from intractable distributions’, Pro- ceedings of The JuliaCon Conferences 7(69), 139
2025
-
[51]
and Doucet, A
Syed, S., Bouchard-Côté, A., Deligiannidis, G. and Doucet, A. [2022], ‘Non-reversible parallel tempering: A scalable highly parallel MCMC scheme’, Journal of the Royal Statistical Society Series B: Statistical Methodology 84(2), 321–350
2022
-
[52]
[2016], ‘Explicit symplectic approximation of nonseparable Hamiltonians: Al- gorithm and long time performance’, Physical Review E 94(4), 043303
Tao, M. [2016], ‘Explicit symplectic approximation of nonseparable Hamiltonians: Al- gorithm and long time performance’, Physical Review E 94(4), 043303
2016
-
[53]
[1998], ‘A note on Metropolis-Hastings kernels for general state spaces’, The Annals of Applied Probability 8(1), 1–9
Tierney, L. [1998], ‘A note on Metropolis-Hastings kernels for general state spaces’, The Annals of Applied Probability 8(1), 1–9
1998
-
[54]
Vanetti, P., Bouchard-Côté, A., Deligiannidis, G. and Doucet, A. [2017], ‘Piecewise- deterministic Markov chain Monte Carlo’, arXiv:1707.05296 . 35
Pith/arXiv arXiv 2017
-
[55]
and Klami, A
Williams, B., Yu, H., Hartmann, M. and Klami, A. [2024], Geometric No-U-Turn sam- plers: Concepts and evaluation, in ‘Proceedings of The 12th International Conference on Probabilistic Graphical Models (PGM)’, PMLR, pp. 327–347
2024
-
[56]
Wright, S. J. [2015], ‘Coordinate descent algorithms’, Mathematical programming 151(1), 3–34
2015
-
[57]
and Ge, H
Xu, K. and Ge, H. [2024], Practical Hamiltonian Monte Carlo on Riemannian man- ifolds via relativity theory, in ‘Proceedings of The 41st International Conference on Machine Learning’, PMLR
2024
-
[58]
and Ghahramani, Z
Xu, K., Ge, H., Tebbutt, W., Tarek, M., Trapp, M. and Ghahramani, Z. [2020], Ad- vancedHMC. jl: A robust, modular and efficient implementation of advanced HMC algorithms, in ‘Proceedings of The 2nd Symposium on Advances in Approximate Bayesian Inference’, PMLR, pp. 1–10
2020
-
[59]
and Mahoney, M
Yao, Z., Gholami, A., Shen, S., Mustafa, M., Keutzer, K. and Mahoney, M. [2021], Adahessian: An adaptive second order optimizer for machine learning, in ‘Proceedings of The AAAI Conference on Artificial Intelligence’, Vol. 35, pp. 10665–10673. 36 SUPPLEMENTARY MATERIAL A Implementation of coordinate friendly methods via compute graphs A.1 Compute graph Th...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.