Mapping Mathematical Hardness: Machine-Assisted Conjecture Discovery and the Quantification of Non-Triviality
Pith reviewed 2026-06-27 04:33 UTC · model grok-4.3
The pith
Mahalanobis distance in an embedding of known conjectures quantifies the non-triviality of machine-generated mathematical statements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that non-triviality of a new mathematical conjecture can be quantified by its Mahalanobis distance from a cluster of selected known conjectures inside an embedding space; this distance supplies both a benchmark for automated discovery and an error-localization signal for statements that current formalizers cannot verify.
What carries the argument
Mahalanobis distance within an embedding cluster of selected known mathematical conjectures
If this is right
- Automated conjecture generators receive a numeric score for the non-triviality of each new statement they produce.
- Statements that lie far from the known cluster can be flagged as possible errors even when proof assistants cannot reach a decision.
- The Birch test conditions for machine discovery can be checked in part by comparing generated conjectures against the distance benchmark.
- Conjectures on twin-prime distributions can be placed on a continuous scale of non-triviality relative to existing results.
Where Pith is reading between the lines
- The geometric treatment suggests that non-triviality may correspond to a measurable position in a space of mathematical ideas.
- Once embeddings are available in other branches, the same distance could rank conjectures in algebra or geometry.
- A working version would allow closed-loop systems that generate, score, and refine conjectures without constant human oversight.
Load-bearing premise
The embedding space built from known conjectures together with Mahalanobis distance will rank new statements in a way that matches human mathematical judgment of non-triviality.
What would settle it
A set of machine-generated conjectures whose order by Mahalanobis distance disagrees with the order in which mathematicians independently rank their non-triviality.
Figures
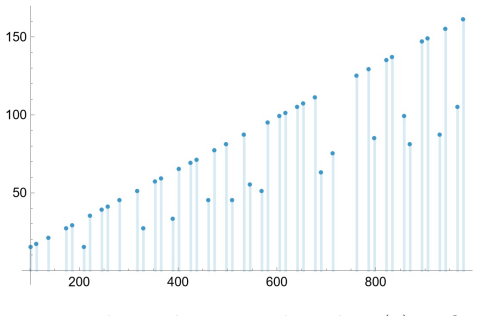

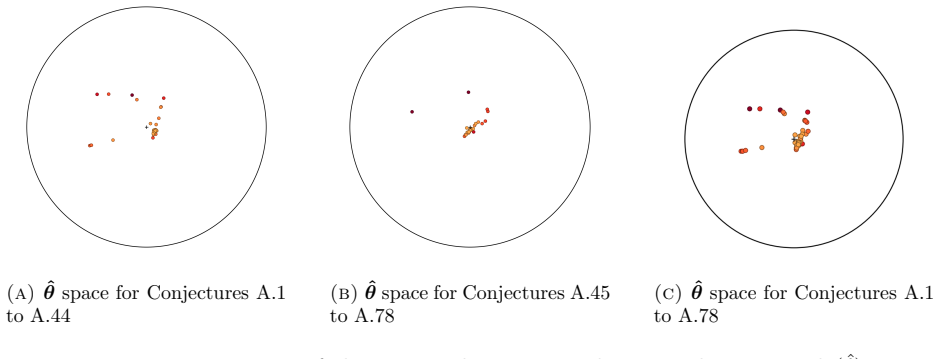
read the original abstract
Machine-assisted mathematical discovery has been a long-standing challenge in machine learning and artificial intelligence. In recent years, we have seen tremendous progress with generative AI, yet its contribution to automated discovery in advanced mathematical research has been limited. One of the most difficult benchmarks in this context is the Birch test, which asks whether a machine can discover truly novel and non-trivial mathematical structures without human intervention. In this work, we particularly focus on the branch of automated conjecture discovery. We use HypothesiX, an automated conjecture mining agent and analyse its generated conjectures related to the distribution of twin primes to verify the conditions of the Birch test. Furthermore, note that automated discovery is now operating at scale, but verifying its non-triviality still depends on human evaluation. We propose a benchmark to quantify the non-triviality of machine-generated conjectures using the Mahalanobis distance within an embedding cluster of selected known mathematical conjectures. We also note that this quantified benchmark can be used as an error indication signal to localise the incorrectness of a new mathematical statement, which autoformalisers fail to verify due to their limitations in proof discovery capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes HypothesiX, an automated conjecture-mining agent applied to twin-prime distributions, and proposes a benchmark for non-triviality of machine-generated conjectures that uses Mahalanobis distance inside an embedding cluster formed from selected known mathematical conjectures; the same distance is suggested as an error-localization signal for autoformalizers that cannot complete proofs.
Significance. A validated, non-circular quantitative proxy for non-triviality would be a useful addition to the toolkit for automated conjecture discovery and could help operationalize the Birch test. The manuscript, however, supplies neither the embedding construction details nor any empirical check that the proposed distance ranks statements in agreement with expert judgment, so the claimed utility remains unestablished.
major comments (2)
- [Abstract] Abstract: the central claim that Mahalanobis distance within the chosen embedding cluster supplies a benchmark for non-triviality rests on an untested assumption; no human-rated test set, correlation coefficient, or comparison against alternative notions of non-triviality is reported.
- [Abstract] Abstract: the benchmark is constructed from a cluster of already-known conjectures, yet the manuscript provides no account of how the embedding is built or whether the selection of those conjectures was independent of the very notions of non-triviality the distance is meant to quantify, leaving the method open to circularity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments on the proposed non-triviality benchmark below, acknowledging the gaps in empirical validation and methodological detail while clarifying the intent and scope of the current manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Mahalanobis distance within the chosen embedding cluster supplies a benchmark for non-triviality rests on an untested assumption; no human-rated test set, correlation coefficient, or comparison against alternative notions of non-triviality is reported.
Authors: We agree that the manuscript presents the Mahalanobis-distance benchmark primarily as a proposed quantitative proxy motivated by anomaly detection principles, without a dedicated human-rated validation study or reported correlation coefficients. The twin-prime conjectures generated by HypothesiX serve as an illustrative case study rather than a formal test set. We will add a new subsection containing a small expert-rated test set of mathematical statements together with Spearman correlation results against the proposed distance in the revised version. revision: yes
-
Referee: [Abstract] Abstract: the benchmark is constructed from a cluster of already-known conjectures, yet the manuscript provides no account of how the embedding is built or whether the selection of those conjectures was independent of the very notions of non-triviality the distance is meant to quantify, leaving the method open to circularity.
Authors: The full manuscript (Section 3) specifies that the cluster comprises 15 historically prominent open conjectures embedded via a fixed sentence-transformer model pretrained on mathematical corpora; the selection criterion was their status as long-standing open problems across subfields, not any pre-existing non-triviality score. Nevertheless, we accept that the current description is insufficiently detailed to fully dispel circularity concerns. We will expand the embedding-construction subsection with explicit model hyperparameters, the precise list of seed conjectures, and an explicit statement that no non-triviality metric was used in their selection. revision: yes
Circularity Check
Proposed benchmark is a definitional measure with no reduction to inputs by construction
full rationale
The manuscript proposes a benchmark for non-triviality based on Mahalanobis distance in an embedding cluster of selected known conjectures. This is presented as a new quantitative tool rather than a derivation claiming that some quantity X produces a result Y. No equations, fitted parameters renamed as predictions, or self-citation chains are exhibited that would make the benchmark output equivalent to its inputs by construction. The embedding is described as constructed from known conjectures, but the proposal itself does not reduce the claimed quantification to a self-referential fit or imported uniqueness result. Concerns about alignment with human judgment concern empirical validation and are distinct from circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mathematical conjectures admit a vector embedding in which Mahalanobis distance from a reference cluster measures non-triviality.
Reference graph
Works this paper leans on
-
[1]
Lemmanaid: Neuro-Symbolic Lemma Conjecturing
Y. Alhessi et al. “Lemmanaid: Neuro-Symbolic Lemma Conjecturing”. In:Pre-prints:arXiv (2025).url:https://arxiv.org/abs/2504.04942
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
On the representation of a larger even integer as the sum of a prime and the product of at most two primes
J. R. Chen. “On the representation of a larger even integer as the sum of a prime and the product of at most two primes”. In:Sci. Sinica26 (1973), pp. 157–176. 22
1973
-
[3]
Mining Math Conjectures from LLMs: A Pruning Approach
J. Chuharski, R. Collins, and M. Meringolo. “Mining Math Conjectures from LLMs: A Pruning Approach”. In:Pre-prints:arXiv(2024).url:https://arxiv.org/abs/2412.16177
-
[4]
Advancing mathematics by guiding human intuition with AI
A. Davies, P. Veliˇ ckovi´ c, and L. Buesing et al. “Advancing mathematics by guiding human intuition with AI”. In:Nature600 (2021), pp. 70–74
2021
-
[5]
Fel’s Conjecture on Syzygies of Numerical Semigroups
E. Chen and C. Cummins and D. Grubisic et al. “Fel’s Conjecture on Syzygies of Numerical Semigroups”. In:Pre-print:https: // arxiv. org/ pdf/ 2602. 03716v1(2026)
2026
-
[6]
Primes in Tuples I
D. A. Goldston, J. Pintz, and Cem Y. C. Y. Yıldırım. “Primes in Tuples I”. In:Annals of Mathematics170.2 (2009), pp. 819–862
2009
-
[7]
Primes in Tuples II
D. A. Goldston, J. Pintz, and C. Y. Yıldırım. “Primes in Tuples II”. In:Acta Mathematica 204.1 (2010), pp. 1–47
2010
-
[8]
Primes in Tuples III: On the Difference pn+ν −p n
D. A. Goldston, J. Pintz, and C. Y. Yıldırım. “Primes in Tuples III: On the Difference pn+ν −p n”. In:Functiones et Approximatio Commentarii Mathematici35 (2006), pp. 79–89
2006
-
[9]
Primes in Tuples IV: Density of Small Gaps Between Consecutive Primes
D. A. Goldston, J. Pintz, and C. Y. Yıldırım. “Primes in Tuples IV: Density of Small Gaps Between Consecutive Primes”. In:Acta Arithmetica160.1 (2013), pp. 37–53
2013
-
[10]
Halberstam and H
H. Halberstam and H. E. Richert.Sieve Methods. London Mathematical Society Monographs
-
[11]
London: Academic Press, 1974
1974
-
[12]
Some problems of ‘Partitio numerorum’; III: On the expression of a number as a sum of primes
G. H. Hardy and J. E. Littlewood. “Some problems of ‘Partitio numerorum’; III: On the expression of a number as a sum of primes”. In:Acta Mathematica44.1 (1923), pp. 1–70
1923
-
[13]
Harman.Prime-Detecting Sieves
G. Harman.Prime-Detecting Sieves. Prime-Detecting Sieves 33. Princeton, NJ: Princeton University Press, 2012
2012
-
[14]
Can AI make genuine theoretical discoveries?
Y. He and M. Burtsev. “Can AI make genuine theoretical discoveries?” In:Nature625.241 (2024)
2024
-
[15]
Iwaniec and E
H. Iwaniec and E. Kowalski.Analytic Number Theory. Vol. 53. Colloquium Publications, 2004. isbn: 978-1-4704-6770-8
2004
-
[16]
Sur la distribution des nombres premiers
H. von Koch. “Sur la distribution des nombres premiers”. In:Acta Mathematica24.1 (1901), pp. 159–182
1901
-
[17]
Small Gaps between primes
J. Maynard. “Small Gaps between primes”. In:Annals of Mathematics181.1 (2015), pp. 383– 413
2015
-
[18]
The Twin Prime Conjecture
J. Maynard. “The Twin Prime Conjecture”. In:Japanese Journal of Mathematics14.2 (2019), pp. 175–206
2019
-
[19]
Twin primes and the parity problem
M. Murty and A. Vatwani. “Twin primes and the parity problem”. In:Journal of Number Theory180 (2017), pp. 643–659
2017
-
[20]
Nipkow, C
T. Nipkow, C. P. Lawrence, and M. Wenzel.Isabelle/HOL: A Proof Assistant for Higher-Order Logic. Vol. 2283. Lecture Notes in Computer Science. Springer, 2002
2002
-
[21]
arXiv preprint arXiv:2506.22005 , year =
N. Onda et al. “LeanConjecturer: Automatic Generation of Mathematical Conjectures for Theorem Proving”. In:Pre-prints:arXiv(2025).url:https://arxiv.org/abs/2506.22005
-
[22]
Ueber die Anzahl der Primzahlen unter einer gegebenen Gr¨ osse
B. Riemann. “Ueber die Anzahl der Primzahlen unter einer gegebenen Gr¨ osse”. In:Monats- berichte der Berliner Akademie(1859), pp. 671–680
-
[23]
Annual Report
Peter Sarnak.Problems of the Millennium: The Riemann Hypothesis. Annual Report. Clay Mathematics Institute, 2004
2004
-
[24]
Aristotle: IMO-level Automated Theorem Prov- ing
T. Achim and A. Best and A. Bietti et al. “Aristotle: IMO-level Automated Theorem Prov- ing”. In:Pre-print:https: // arxiv. org/ abs/ 2510. 01346(2026)
2026
-
[25]
Olympiad-level formal mathematical reasoning with reinforcement learning
T. Hubert and R. Mehta and L. Sartran et al. “Olympiad-level formal mathematical reasoning with reinforcement learning”. In:Nature(2025)
2025
-
[26]
Tao.Open question: The parity problem in sieve theory.url:https : / / terrytao
T. Tao.Open question: The parity problem in sieve theory.url:https : / / terrytao . wordpress.com/2007/06/05/open-question-the-parity-problem-in-sieve-theory/
2007
-
[27]
A Lean 4 library of formalized mathematics
The Lean Community Project.mathlib4. A Lean 4 library of formalized mathematics. 2024. url:https://github.com/leanprover-community/mathlib4. 23 cnew Name ˆθ= [ ˆθ1, ˆθ2, ˆθ3, ˆθ4, ˆθ5, ˆθ6] d2(ˆθ) ˆΥ(ˆθ) Closest known conjecture A.1 [8.01,8.16,7.00,5.10,6.07,5.98] 3.7061 0.1667 Elliott–Halberstam A.2 [7.93,8.31,7.05,5.20,6.09,5.88] 2.8243 0.0556 Elliott–H...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.