Predictively-Oriented Kalman Filtering
Pith reviewed 2026-06-28 09:03 UTC · model grok-4.3
The pith
EKF-PrO performs online filtering in nonlinear state-space models without becoming overconfident under misspecification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
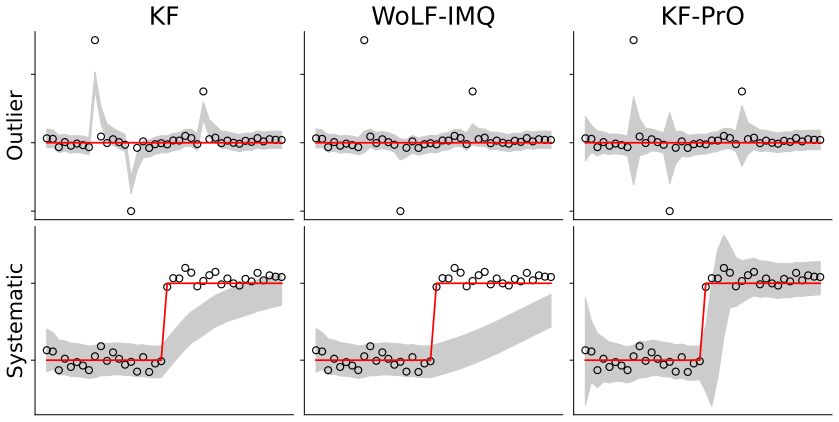
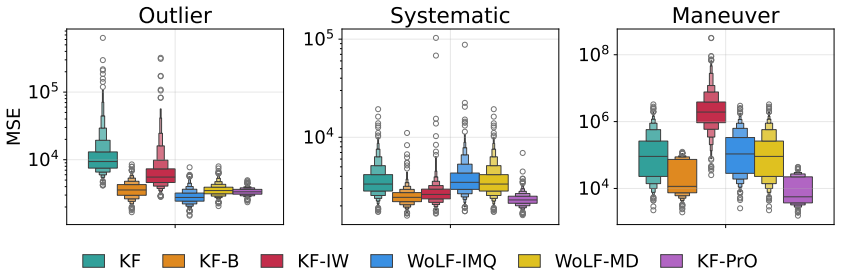
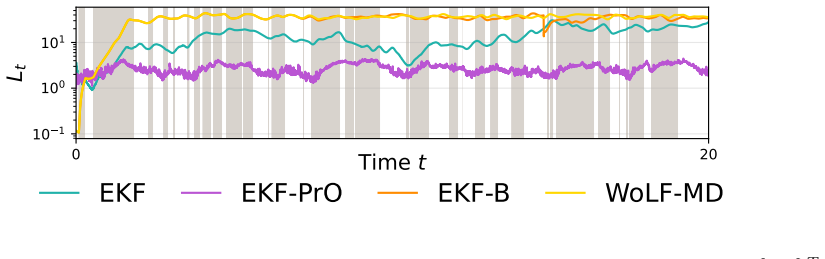
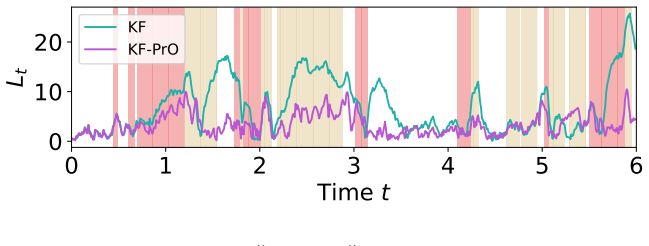
The paper introduces EKF-PrO, a fast approximate linear-Gaussian update procedure for predictively-oriented posteriors in nonlinear state-space models. This procedure is analogous to an iterated extended Kalman filter and ensures posterior concentration occurs if and only if the overall model is well-specified, without strict adherence to Bayes' theorem and without any tunable hyperparameters.
What carries the argument
The predictively-oriented (PrO) posterior updated by an approximate linear-Gaussian rule analogous to the iterated extended Kalman filter.
If this is right
- Posterior concentration occurs only when the state-space model is correctly specified.
- The filter requires no hyperparameter tuning.
- Computational cost remains comparable to that of standard extended Kalman filters.
- The method applies directly to both linear and nonlinear models under misspecification.
Where Pith is reading between the lines
- The same predictively-oriented update idea could be adapted to particle filters or other sequential Monte Carlo methods.
- This framework may improve calibration in real-time tracking applications where models are known to be imperfect approximations.
- Connections to other post-Bayesian online methods could yield a broader class of hyperparameter-free robust filters.
Load-bearing premise
A fast approximate linear-Gaussian update can be derived for predictively-oriented posteriors that preserves concentration only under correct specification without introducing bias or requiring tunable hyperparameters.
What would settle it
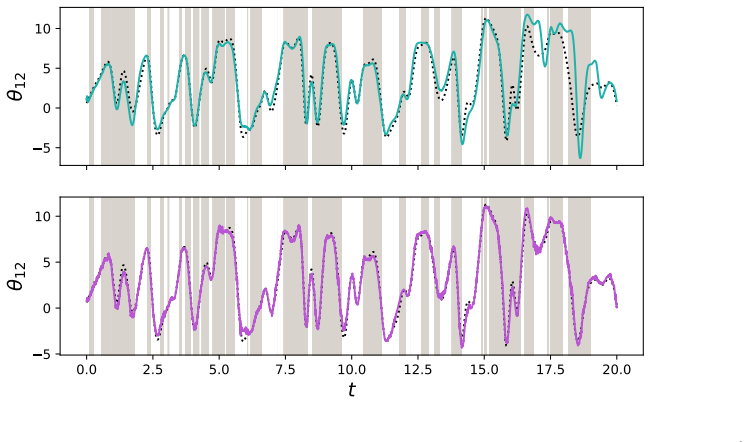
Apply EKF-PrO to data generated from a misspecified nonlinear state-space model and check whether the resulting posterior intervals achieve nominal coverage probabilities on held-out predictions.
Figures
read the original abstract
This paper presents a post-Bayesian approach to online filtering in nonlinear state-space models, capable of avoiding over-confident inferences in settings where either the dynamical model, the measurement model, or both, could be misspecified. This is addressed using predictively oriented (PrO) posteriors, an emerging paradigm in which learning (i.e., posterior concentration) occurs if and only if the overall model is well-specified, without strict adherence to Bayes' theorem. As the characterisation of PrO posteriors is challenging, our main technical contribution is a fast approximate linear-Gaussian update procedure, analogous to an (iterated) extended Kalman filter. The methodology, which we call EKF-PrO, has no tunable hyper-parameters and has a computational cost comparable to that of existing filtering methods. Performance is empirically assessed on a range of linear and non-linear applications, in which the state-space model is systematically misspecified.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EKF-PrO, a hyperparameter-free approximate linear-Gaussian update for predictively-oriented (PrO) posteriors in nonlinear state-space models. It enables online filtering that avoids over-confident inferences under misspecification of the dynamical or measurement model (or both), with the property that posterior concentration occurs if and only if the overall model is correctly specified. The method is constructed via moment-matching analogous to an iterated extended Kalman filter, has computational cost comparable to existing filters, and is assessed empirically on systematically misspecified linear and nonlinear examples.
Significance. If the derivation and experiments hold, the work is significant for providing a practical, tuning-free post-Bayesian filtering procedure that inherits the predictive-orientation property by construction. The absence of free parameters, the explicit moment-matching construction, and the validation on misspecified models are notable strengths that address a common practical limitation of standard Kalman-type filters.
minor comments (2)
- [Abstract] Abstract: the phrase 'post-Bayesian approach' is used without a one-sentence reminder of how PrO posteriors differ from standard Bayesian updating; a brief parenthetical would improve accessibility.
- [Experiments] The empirical section would benefit from an explicit statement of the misspecification levels (e.g., parameter deviation magnitudes) used in the linear and nonlinear test cases to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, the recognition of its practical contributions, and the recommendation to accept. No major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper defines EKF-PrO as a new approximate linear-Gaussian update for predictively-oriented (PrO) posteriors in nonlinear state-space models, with the concentration property (only under correct specification) inherited from the PrO paradigm described as emerging and external. The derivation is framed as analogous to iterated EKF without tunable hyperparameters, and no equations or steps reduce by construction to fitted inputs, self-definitions, or self-citation chains. The approximation preserves the target property without redefining inputs as outputs or smuggling ansatzes. This is a standard non-circular technical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PrO posteriors concentrate if and only if the overall model is well-specified
Reference graph
Works this paper leans on
-
[1]
Agamennoni, J
G. Agamennoni, J. I. Nieto, and E. M. Nebot. Approximate inference in state-space models with heavy-tailed noise. IEEE Transactions on Signal Processing, 60 0 (10): 0 5024--5037, 2012
2012
-
[2]
P. G. Bissiri, C. C. Holmes, and S. G. Walker. A general framework for updating belief distributions. Journal of the Royal Statistical Society Series B: Statistical Methodology, 78 0 (5): 0 1103--1130, 2016
2016
-
[3]
C. G. Boncelet and B. W. Dickinson. An approach to robust K alman filtering. In IEEE Conference on Decision and Control, pages 304--305, 1983
1983
-
[4]
Boustati, O
A. Boustati, O. D. Akyildiz, T. Damoulas, and A. Johansen. Generalised B ayesian filtering via sequential M onte C arlo. Advances in Neural Information Processing Systems, 34: 0 418--429, 2020
2020
-
[5]
P. G. Chang, G. Dur \'a n-Mart \' n, A. Shestopaloff, M. Jones, and K. P. Murphy. Low-rank extended K alman filtering for online learning of neural networks from streaming data. In Conference on Lifelong Learning Agents, pages 1025--1071. PMLR, 2023
2023
- [6]
-
[7]
S.-Y. Chen. Kalman filter for robot vision: A survey. IEEE Transactions on Industrial Electronics, 59 0 (11): 0 4409--4420, 2011
2011
-
[8]
Dahan, G
Y. Dahan, G. Revach, J. Dunik, and N. Shlezinger. Bayesian KalmanNet : Q uantifying uncertainty in deep learning augmented K alman filter. IEEE Transactions on Signal Processing, 73: 0 2558--2573, 2025
2025
-
[9]
S. Das. Robust State Estimation Methods for Robotics Applications. PhD thesis, West Virginia University, 2023
2023
-
[10]
Duran-Martin, M
G. Duran-Martin, M. Altamirano, A. Y. Shestopaloff, L. S \'a nchez-Betancourt, J. Knoblauch, M. Jones, F.-X. Briol, and K. Murphy. Outlier-robust K alman filtering through generalised B ayes. In Proceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[11]
Duran-Martin, L
G. Duran-Martin, L. S \'a nchez-Betancourt, A. Shestopaloff, and K. Murphy. A unifying framework for generalised B ayesian online learning in non-stationary environments. Transactions on Machine Learning Research, 2025
2025
-
[12]
Durbin and S
J. Durbin and S. J. Koopman. Time Series Analysis by State Space Methods. Oxford University Press, 2012
2012
-
[13]
G. Evensen. The ensemble K alman filter: T heoretical formulation and practical implementation. Ocean Dynamics, 53 0 (4): 0 343--367, 2003
2003
-
[14]
Fitzgerald
R. Fitzgerald. Divergence of the K alman filter. IEEE Transactions on Automatic Control, 16 0 (6): 0 736--747, 2003
2003
-
[15]
A. Gelb. Applied Optimal Estimation. MIT Press, 1974
1974
-
[16]
Gneiting and A
T. Gneiting and A. E. Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102 0 (477): 0 359--378, 2007
2007
-
[17]
Huang, Y
Y. Huang, Y. Zhang, N. Li, and J. Chambers. A robust G aussian approximate filter for nonlinear systems with heavy tailed measurement noises. In IEEE International Conference on Acoustics, Speech and Signal Processing, pages 4209--4213, 2016
2016
-
[18]
Huang, Y
Y. Huang, Y. Zhang, N. Li, Z. Wu, and J. A. Chambers. A novel robust student's t-based K alman filter. IEEE Transactions on Aerospace and Electronic Systems, 53 0 (3): 0 1545--1554, 2017
2017
-
[19]
Huang, F
Y. Huang, F. Zhu, G. Jia, and Y. Zhang. A slide window variational adaptive K alman filter. IEEE Transactions on Circuits and Systems II: Express Briefs, 67 0 (12): 0 3552--3556, 2020
2020
-
[20]
Ito and K
K. Ito and K. Xiong. Gaussian filters for nonlinear filtering problems. IEEE Transactions on Automatic Control, 45 0 (5): 0 910--927, 2002
2002
-
[21]
Jankowiak, G
M. Jankowiak, G. Pleiss, and J. Gardner. Parametric G aussian process regressors. In International Conference on Machine Learning, pages 4702--4712. PMLR, 2020
2020
-
[22]
Jazwinski
A. Jazwinski. Stochastic Processes and Filtering Theory. Academic Press, 1970
1970
-
[23]
Jones, P
M. Jones, P. Chang, and K. Murphy. Bayesian online natural gradient (BONG) . Advances in Neural Information Processing Systems, 37: 0 131104--131153, 2024
2024
-
[24]
S. J. Julier. A general method for approximating non-linear transformations of probability distributions. 1996. URL http://www.robots.ox.ac.uk/\ siju/work/work.html
1996
-
[25]
R. E. Kalman. A new approach to linear filtering and prediction problems. Journal of Basic Engineering, 82 0 (Series D): 0 35--45, 1960
1960
-
[26]
C. D. Karlgaard. Nonlinear regression H uber-- K alman filtering and fixed-interval smoothing. Journal of Guidance, Control, and Dynamics, 38 0 (2): 0 322--330, 2015
2015
-
[27]
R. Kelly. Reducing geometric dilution of precision using ridge regression. IEEE Transactions on Aerospace and Electronic Systems, 26 0 (1): 0 154--168, 2002
2002
-
[28]
Knoblauch, J
J. Knoblauch, J. Jewson, and T. Damoulas. An optimization-centric view on B ayes' rule: Reviewing and generalizing variational inference. Journal of Machine Learning Research, 23 0 (132): 0 1--109, 2022
2022
-
[29]
Kuleshov, N
V. Kuleshov, N. Fenner, and S. Ermon. Accurate uncertainties for deep learning using calibrated regression. In International Conference on Machine Learning, 2018
2018
-
[30]
J. Lai and Y. Yao. Predictive variational inference: Learn the predictively optimal posterior distribution. arXiv preprint arXiv:2410.14843, 2024
Pith/arXiv arXiv 2024
-
[31]
N. Laird. Nonparametric maximum likelihood estimation of a mixing distribution. Journal of the American Statistical Association, 73 0 (364): 0 805--811, 1978
1978
-
[32]
Lambert, S
M. Lambert, S. Bonnabel, and F. Bach. The recursive variational Gaussian approximation (R-VGA) . Statistics and Computing, 32 0 (1): 0 10, 2022
2022
-
[33]
D. C. Liu and J. Nocedal. On the limited memory BFGS method for large scale optimization. Mathematical Programming, 45 0 (1): 0 503--528, 1989
1989
-
[34]
G. Liu. Data quality problems troubling business and financial researchers: A literature review and synthetic analysis. Journal of Business & Finance Librarianship, 25 0 (3-4): 0 315--371, 2020
2020
-
[35]
Q. Liu, M. A. Fisher, Z. Shen, K. Tant, X. Zhao, A. Curtis, and C. J. Oates. Detecting model misspecification in B ayesian inverse problems via variational gradient descent. arXiv preprint arXiv:2512.01667, 2025
Pith/arXiv arXiv 2025
-
[36]
E. N. Lorenz. Predictability of Weather and Climate, chapter Predictability: A problem partly solved. Cambridge University Press, 1996
1996
-
[37]
Masegosa
A. Masegosa. Learning under model misspecification: A pplications to variational and ensemble methods. Advances in Neural Information Processing Systems, 34, 2020
2020
-
[38]
P. S. Maybeck. Stochastic Models, Estimation, and Control. Academic Press, 1982
1982
-
[39]
Y. McLatchie, B.-E. Cherief-Abdellatif, D. T. Frazier, and J. Knoblauch. Predictively oriented posteriors. arXiv preprint arXiv:2510.01915, 2025
arXiv 2025
-
[40]
R. Mehra. Approaches to adaptive filtering. IEEE Transactions on Automatic Control, 17 0 (5): 0 693--698, 2003
2003
-
[41]
J. W. Miller. Asymptotic normality, concentration, and coverage of generalized posteriors. Journal of Machine Learning Research, 22 0 (168): 0 1--53, 2021
2021
-
[42]
W. R. Morningstar, A. Alemi, and J. V. Dillon. PACm-Bayes : N arrowing the empirical risk gap in the misspecified B ayesian regime. In International Conference on Artificial Intelligence and Statistics, 2022
2022
-
[43]
K. P. Murphy. Probabilistic Machine Learning: Advanced Topics. MIT Press, 2023
2023
-
[44]
Nogueira
F. Nogueira. Bayesian Optimization : Open source constrained global optimization tool for Python , 2014. URL https://github.com/bayesian-optimization/BayesianOptimization
2014
-
[45]
Nurminen, T
H. Nurminen, T. Ardeshiri, R. Piché, and F. Gustafsson. Robust inference for state-space models with skewed measurement noise. IEEE Signal Processing Letters, 22 0 (11): 0 1898--1902, 2015
1902
-
[46]
Piché, S
R. Piché, S. Särkkä, and J. Hartikainen. Recursive outlier-robust filtering and smoothing for nonlinear systems using the multivariate student-t distribution. In IEEE International Workshop on Machine Learning for Signal Processing, 2012
2012
-
[47]
M. Roth, E. \"O zkan, and F. Gustafsson. A student's t filter for heavy tailed process and measurement noise. In 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 5770--5774. IEEE, 2013
2013
-
[48]
M. Roth, T. Ardeshiri, E. \"O zkan, and F. Gustafsson. Robust B ayesian filtering and smoothing using S tudent's-t distribution. arXiv preprint arXiv:1703.02428, 2017 a
Pith/arXiv arXiv 2017
-
[49]
M. Roth, G. Hendeby, C. Fritsche, and F. Gustafsson. The ensemble K alman filter: A signal processing perspective. Journal on Advances in Signal Processing, 2017: 0 1--16, 2017 b
2017
-
[50]
Schlee, C
F. Schlee, C. Standish, and N. Toda. Divergence in the K alman filter. AIAA Journal, 5 0 (6): 0 1114--1120, 1967
1967
-
[51]
Z. Shen, J. Knoblauch, S. Power, and C. J. Oates. Prediction-centric uncertainty quantification via MMD . In International Conference on Artificial Intelligence and Statistics, 2025
2025
-
[52]
Sheth and R
R. Sheth and R. Khardon. Pseudo- B ayesian learning via direct loss minimization with applications to sparse G aussian process models. In Symposium on Advances in Approximate Bayesian Inference, 2020
2020
-
[53]
Särkkä and L
S. Särkkä and L. Svensson. B ayesian Filtering and Smoothing (2nd edition) . Cambridge University Press, 2023
2023
-
[54]
P. D. Tao and L. H. An. Convex analysis approach to DC programming: T heory, algorithms and applications. Acta Mathematica Vietnamica, 22 0 (1): 0 289--355, 1997
1997
-
[55]
S. Thrun. Probabilistic robotics. Communications of the ACM, 45 0 (3): 0 52--57, 2002
2002
-
[56]
J.-A. Ting, E. Theodorou, and S. Schaal. Learning an outlier-robust K alman filter. In European Conference on Machine Learning, 2007
2007
-
[57]
J. d. Vilmarest and O. Wintenberger. Viking: V ariational B ayesian variance tracking. Statistical Inference for Stochastic Processes, 27 0 (3): 0 839--860, 2024
2024
-
[58]
H. Wang, H. Li, J. Fang, and H. Wang. Robust G aussian K alman filter with outlier detection. IEEE Signal Processing Letters, 25 0 (8): 0 1236--1240, 2018
2018
-
[59]
Wenzel, K
F. Wenzel, K. Roth, B. Veeling, J. Swiatkowski, L. Tran, S. Mandt, J. Snoek, T. Salimans, R. Jenatton, and S. Nowozin. How good is the B ayes posterior in deep neural networks really? In International Conference on Machine Learning, 2020
2020
-
[60]
A. L. Yuille and A. Rangarajan. The concave-convex procedure. Neural Computation, 15 0 (4): 0 915--936, 2003
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.