KEMO: Event-Driven Keyframe Memory for Long-Horizon Robot Manipulation with VLA Policies
Pith reviewed 2026-06-26 08:19 UTC · model grok-4.3
The pith
KEMO equips vision-language-action policies with selective keyframe memory based on detected events to resolve stage ambiguity in long robot tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
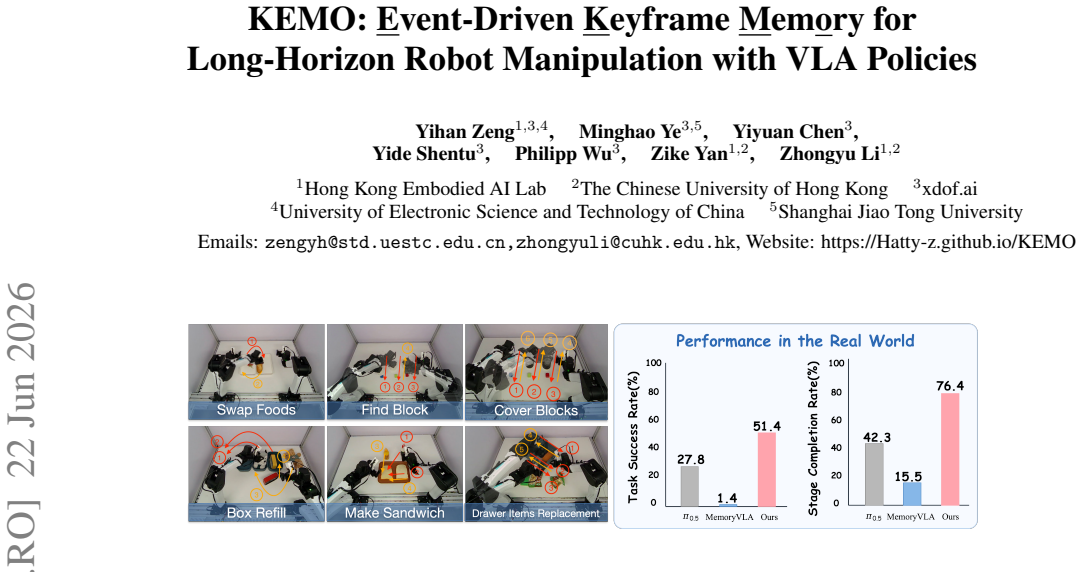
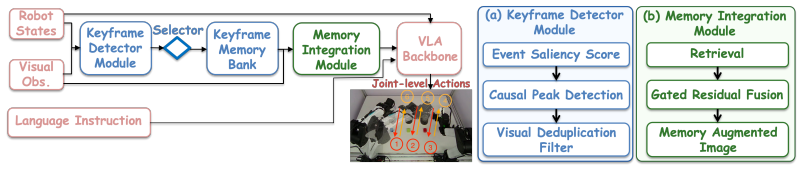
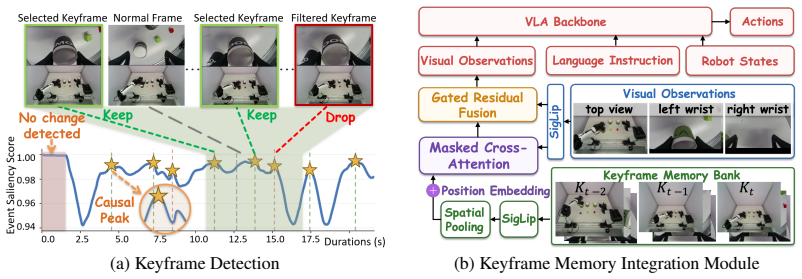
KEMO detects events by combining robot kinematics with visual filtering to identify state changes, selects and encodes the associated keyframes into compact temporally ordered memory tokens, integrates these tokens with current visual features through cross-attention and gated residual fusion during VLA training, and assigns higher loss weights to samples near critical transitions; this selective memory approach raises aggregate task success rate by 23.6% and stage completion rate by 34.1% compared to memory-free baselines on dual-arm tasks with 2 to 6 subtasks and trajectories of 830 to 2846 steps.
What carries the argument
Event-driven keyframe selection that combines kinematics and visual filtering to preserve only task-relevant past states as ordered memory tokens for cross-attention fusion.
If this is right
- Task success improves because the policy can distinguish repeated observations by recalling specific prior events.
- Memory remains lightweight since only keyframes are kept instead of full histories or recent windows.
- Training focuses on critical moments through event-aligned loss weighting, sharpening policy responses at transitions.
- Event detection outperforms uniform or recent-frame sampling as shown in ablations.
Where Pith is reading between the lines
- Similar event-based selection could apply to other sequential policies facing observation aliasing.
- Extending the visual filtering to more modalities might reduce reliance on kinematics for event detection.
- Testing on single-arm or non-manipulation tasks would check if the dual-arm setup is necessary for the gains.
Load-bearing premise
Event detection from kinematics and vision reliably marks the important state changes without missing key transitions or adding noise from false events.
What would settle it
A set of manipulation tasks where visual changes and kinematic signals fail to align with actual task progress, causing KEMO to either drop important keyframes or retain irrelevant ones and show no performance gain.
Figures







read the original abstract
Long-horizon robot manipulation remains challenging because similar observations may occur at different execution stages, while the appropriate action depends on previously completed operations. Memory can address this ambiguity by enabling policies to infer task progress from execution history. However, existing memory-augmented approaches often either retain dense histories that require compression or rely primarily on recent context that may discard earlier task-relevant events. In this work, we propose propose KEMO, a lightweight plug-in memory framework that automatically selectively preserves keyframes associated with task-relevant state changes for VLA policies. KEMO combines robot kinematics with visual filtering to detect events, encodes the selected keyframes as compact temporally ordered memory tokens, and integrates them with current visual features through cross-attention and gated residual fusion for VLA training. The detected events also define higher-weight training samples near critical transitions. We evaluate KEMO on various real-world dual-arm manipulation tasks spanning 2 to 6 scored subtasks, and trajectory length ranging from 830 steps to 2846 execution steps (durations from 28 to 95 seconds). Compared with the memory-free baseline (e.g., $\pi_{0.5}$), KEMO improves aggregate Task Success Rate by 23.6\% and Stage Completion Rate by 34.1\%. Ablations show that event-driven keyframe selection outperforms uniform sampling and recent-frame retention, while the proposed gated fusion and keyframe-aligned loss weighting provide complementary gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KEMO, a lightweight plug-in memory framework for VLA policies in long-horizon robot manipulation. It detects events via robot kinematics combined with visual filtering to select and encode keyframes as compact temporally ordered memory tokens, fuses them with current visual features using cross-attention and gated residual connections, and applies higher loss weights to samples near critical transitions. On real-world dual-arm tasks (2-6 subtasks, 830-2846 steps), KEMO reports 23.6% higher aggregate Task Success Rate and 34.1% higher Stage Completion Rate versus memory-free baselines such as π0.5, with ablations indicating benefits from event-driven selection over uniform or recent-frame sampling.
Significance. If the results hold, KEMO addresses a practical limitation in VLA policies for long-horizon tasks by providing selective, event-based memory without dense history compression or recency bias. The real-world dual-arm evaluation across varied task lengths and the ablations on keyframe selection, gated fusion, and transition-weighted loss constitute clear strengths that could inform memory-augmented robot learning. The plug-in design and internal consistency of the pipeline are also positive features.
major comments (2)
- [Evaluation] Evaluation section: the central performance claims (23.6% TSR and 34.1% SCR gains) are presented without reported trial counts, variance, statistical significance tests, or precise baseline implementation details (e.g., how π0.5 is configured or adapted), which are load-bearing for assessing whether the data support the stated improvements.
- [Method] Method and Experiments: the assumption that kinematics-plus-visual-filtering event detection reliably identifies task-relevant state changes (without excessive false positives, misses, or sensitivity to noise) underpins keyframe selection and the weighted loss, yet no quantitative metrics on event detection accuracy or failure modes are supplied.
minor comments (2)
- [Abstract] Abstract: repeated word 'propose propose KEMO' is a typographical error.
- The manuscript would benefit from explicit pseudocode or a diagram for the gated residual fusion and cross-attention integration to improve clarity of the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of evaluation reporting and method validation that we will address in revision.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central performance claims (23.6% TSR and 34.1% SCR gains) are presented without reported trial counts, variance, statistical significance tests, or precise baseline implementation details (e.g., how π0.5 is configured or adapted), which are load-bearing for assessing whether the data support the stated improvements.
Authors: We agree these details are necessary for assessing result reliability. In the revised manuscript we will explicitly report that each task was evaluated over 10 independent real-world trials, include standard deviations for TSR and SCR metrics, provide the exact π0.5 baseline configuration (identical VLA backbone, observation/action spaces, training dataset, and hyperparameters to KEMO but with memory module disabled), and add a limitations paragraph noting that formal statistical significance tests were omitted due to the small per-task sample sizes inherent to costly dual-arm experiments. These changes will strengthen the evaluation section without altering the reported aggregate gains. revision: yes
-
Referee: [Method] Method and Experiments: the assumption that kinematics-plus-visual-filtering event detection reliably identifies task-relevant state changes (without excessive false positives, misses, or sensitivity to noise) underpins keyframe selection and the weighted loss, yet no quantitative metrics on event detection accuracy or failure modes are supplied.
Authors: Obtaining ground-truth labels for task-relevant state changes is inherently subjective and would require prohibitive manual annotation effort for long-horizon trajectories. We therefore validate the detector indirectly via ablations (event-driven selection outperforming uniform and recent-frame baselines) and end-to-end performance gains. In revision we will add a qualitative analysis subsection with example event detections, discussion of potential noise sensitivity, and explicit failure-mode examples. We maintain that the current evidence from downstream metrics is sufficient to support the design choice, but the added analysis will make the validation more transparent. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method (event detection via kinematics+visual filtering, keyframe memory tokens, cross-attention fusion, and transition-weighted loss) evaluated on real dual-arm tasks against external baselines such as π0.5. No equations, derivations, or fitted quantities are defined and then re-presented as predictions. No self-citation chains or uniqueness theorems are invoked to justify core claims. Results are direct experimental comparisons with ablations, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv.org/abs/2406.09246
Pith/arXiv arXiv 2024
-
[3]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
Pith/arXiv arXiv 2023
-
[4]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion, 2024. URLhttps://arxiv.org/ abs/2303.04137
Pith/arXiv arXiv 2024
-
[5]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success, 2025. URLhttps://arxiv.org/abs/2502.19645
Pith/arXiv arXiv 2025
-
[6]
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wang, E. Zhou, H. Fan, X. Zhang, and G. Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic ma- nipulation.arXiv preprint arXiv:2508.19236, 2025
Pith/arXiv arXiv 2025
-
[7]
Y . Dai, H. Fu, J. Lee, Y . Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies, 2026. URLhttps: //arxiv.org/abs/2603.04639
Pith/arXiv arXiv 2026
-
[8]
H. Li, S. Yang, Y . Chen, X. Chen, X. Yang, Y . Tian, H. Wang, T. Wang, D. Lin, F. Zhao, and J. Pang. Cronusvla: Towards efficient and robust manipulation via multi-frame vision- language-action modeling, 2025. URLhttps://arxiv.org/abs/2506.19816
arXiv 2025
-
[9]
A. Sridhar, J. Pan, S. Sharma, and C. Finn. Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328, 2025
arXiv 2025
-
[10]
T. Chen, Y . Wang, M. Li, Y . Qin, H. Shi, Z. Li, Y . Hu, Y . Zhang, K. Wang, Y . Chen, H. Wang, R. Xu, R. Wu, Y . Mu, Y . Yang, H. Dong, and P. Luo. Rmbench: Memory-dependent robotic manipulation benchmark with insights into policy design, 2026. URLhttps://arxiv.org/ abs/2603.01229. 12
arXiv 2026
-
[11]
M. S. Mark, J. Liang, M. Attarian, C. Fu, D. Dwibedi, D. Shah, and A. Kumar. Bpp: Long-context robot imitation learning by focusing on key history frames.arXiv preprint arXiv:2602.15010, 2026
arXiv 2026
-
[12]
S. James and P. Abbeel. Coarse-to-fine q-attention with learned path ranking.arXiv preprint arXiv:2204.01571, 2022
arXiv 2022
-
[13]
Shridhar, L
M. Shridhar, L. Manuelli, and D. Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
2023
-
[14]
H. Fang, M. Grotz, W. Pumacay, Y . R. Wang, D. Fox, R. Krishna, and J. Duan. Sam2act: In- tegrating visual foundation model with a memory architecture for robotic manipulation.arXiv preprint arXiv:2501.18564, 2025
arXiv 2025
-
[15]
F. Pu, L. Jiang, and W. Yang. Tgm-vla: Task-guided mixup for sampling-efficient and robust robotic manipulation.arXiv preprint arXiv:2603.00615, 2026
arXiv 2026
-
[16]
B. Yu, S. Lian, X. Lin, Z. Shen, Y . Wei, C. Wu, H. Yuan, H. Liu, B. Wang, C. Huang, et al. Frameskip: Learning from fewer but more informative frames in vla training.arXiv preprint arXiv:2605.13757, 2026
Pith/arXiv arXiv 2026
-
[17]
H. Jang, S. Yu, H. Kwon, H. Jeon, Y . Seo, and J. Shin. Contextvla: Vision-language-action model with amortized multi-frame context.arXiv preprint arXiv:2510.04246, 2025
arXiv 2025
-
[18]
M. Koo, D. Choi, T. Kim, K. Lee, C. Kim, Y . Seo, and J. Shin. Hamlet: Switch your vision- language-action model into a history-aware policy.arXiv preprint arXiv:2510.00695, 2025
Pith/arXiv arXiv 2025
-
[19]
H. Li, F. Shen, D. Chen, L. Yang, X. Wang, J. Shi, Z. Bing, Z. Liu, and A. Knoll. Remem- vla: Empowering vision-language-action model with memory via dual-level recurrent queries. arXiv preprint arXiv:2603.12942, 2026
arXiv 2026
-
[20]
X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wu, C. Cheang, Y . Jing, W. Zhang, H. Liu, H. Li, and T. Kong. Vision-language foundation models as effective robot imitators.arXiv preprint arXiv:2311.01378, 2023
Pith/arXiv arXiv 2023
-
[21]
Y . Gui, Y . Zhou, S. Cheng, X. Yuan, H. Fan, P. Cheng, and S. Liu. Seedpolicy: Horizon scaling via self-evolving diffusion policy for robot manipulation.arXiv preprint arXiv:2603.05117, 2026
Pith/arXiv arXiv 2026
-
[22]
M. Torne, K. Pertsch, H. Walke, K. Vedder, S. Nair, B. Ichter, A. Z. Ren, H. Wang, J. Tang, K. Stachowicz, K. Dhabalia, M. Equi, Q. Vuong, J. T. Springenberg, S. Levine, C. Finn, and D. Driess. Mem: Multi-scale embodied memory for vision language action models, 2026. URLhttps://arxiv.org/abs/2603.03596
arXiv 2026
-
[23]
Y . Chen, W. Tan, L. Zhu, F. Li, J. Li, G. Yang, and H. T. Shen. Non-markovian long-horizon robot manipulation via keyframe chaining.arXiv preprint arXiv:2603.01465, 2026
arXiv 2026
-
[24]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without sup...
Pith/arXiv arXiv 2024
-
[25]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training, 2023. URLhttps://arxiv.org/abs/2303.15343. 13 Figure 10:Real-World Experimental Setup.Demonstrations are collected through leader–follower teleoperation, where two 6-DoF leader arms control the corresponding two 6-DoF follower arms. During policy inference and...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.