VEGA: Learning Navigation VLAs from In-the-Wild Egocentric Video with Geometric Trajectory Supervision
Pith reviewed 2026-06-27 00:13 UTC · model grok-4.3
The pith
VEGA distills obstacle-aware navigation into vision-only VLAs using trajectories generated from reconstructed monocular video geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
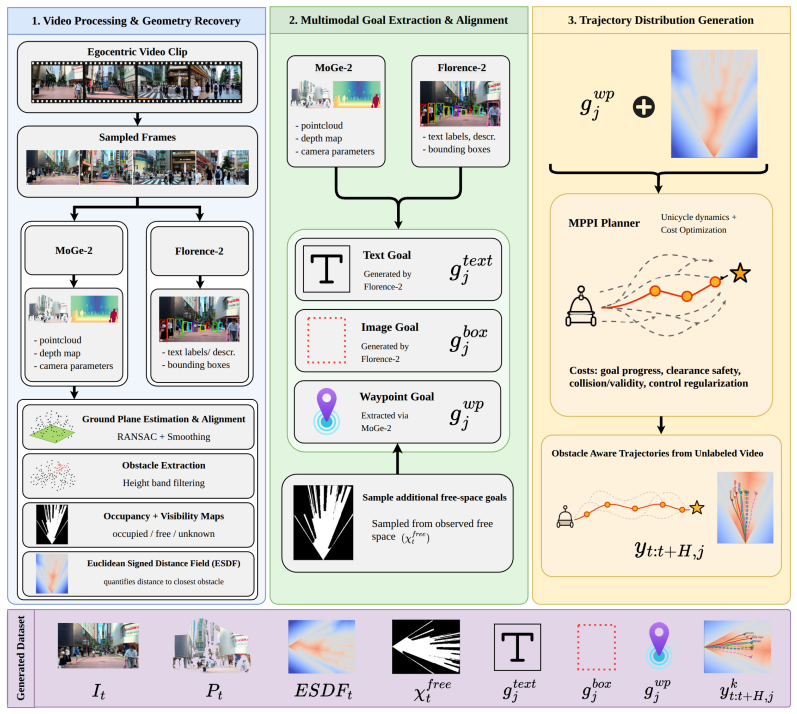
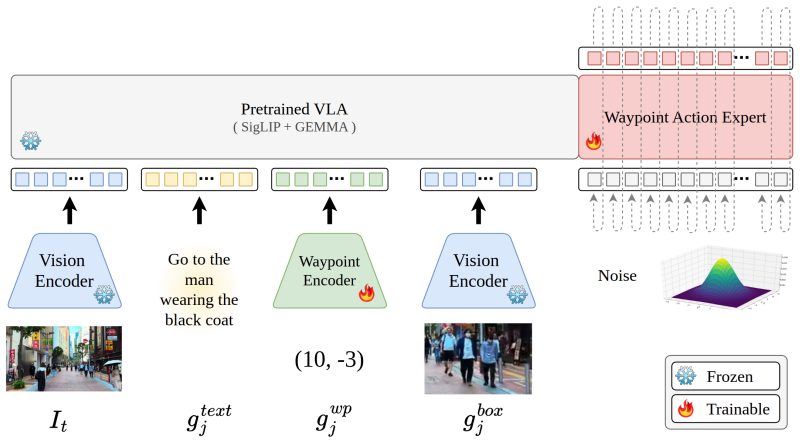
VEGA reconstructs local scene geometry from monocular egocentric videos, samples navigation goals represented as text image or spatial waypoints, generates obstacle-aware trajectories using the constructed geometry, and trains a flow-matching VLA policy on the resulting trajectory distribution. Geometry is used exclusively during training so that the final policy operates from vision and language alone.
What carries the argument
Geometric trajectory supervision: monocular video reconstruction produces obstacle-aware paths that supervise a flow-matching vision-language-action policy.
If this is right
- On VEGABench the method matches goal progress while reducing collisions by 33 percent and raising obstacle clearance by 17.9 percent over the strongest baseline.
- In real-world trials success rises by at least 150 percent, collisions fall by at least 66.7 percent, and clearance improves by at least 60 percent.
- Geometry is required only at training time, allowing the final policy to run from camera images and language goals.
- Internet-scale unlabeled egocentric video becomes a direct source of scalable supervision for obstacle-aware navigation VLAs.
Where Pith is reading between the lines
- The same video-to-geometry pipeline could supply supervision for manipulation or mobile manipulation tasks where explicit 3D planning is available offline but not at test time.
- Larger unlabeled video corpora could be processed in the same way to test whether performance scales without additional human labeling.
- The approach implies that explicit planning signals can be compressed into reactive policies via imitation, opening a route to test whether other forms of offline planning (for example from simulators) produce similar distillation effects.
Load-bearing premise
Reconstructed local scene geometry from monocular video is accurate enough to produce obstacle-aware trajectories that train a vision-only policy which generalizes without geometry at inference time.
What would settle it
Real-robot trials in which the trained policy collides at rates comparable to vision-only baselines would falsify the claim that video-derived geometric supervision produces effective obstacle-aware behavior.
Figures


read the original abstract
We introduce VEGA, an approach for training navigation VisionLanguage-Action (VLA) models from unlabeled egocentric navigation videos. Internet-scale egocentric videos provide a scalable source of navigation-relevant visual observations, capturing cluttered scenes, close-range obstacles, and natural human motion through real-world spaces. However, these videos are not directly usable for policy learning because they do not provide obstacle-aware trajectories conditioned on explicit navigation goals in the robot's coordinate frame. VEGA addresses this gap by reconstructing local scene geometry from monocular video, sampling navigation goals (represented as text, image, or spatial waypoints) and generating obstacle-aware trajectories using the constructed geometry. The resulting trajectory distribution is then used to train a flow-matching VLA navigation policy. By using geometry exclusively during training, VEGA distills obstacle-aware planning directly into a vision-based policy. Furthermore, we introduce VEGA-Bench, a benchmark containing 250k scenes and approximately 5 million navigation goals paired with scene geometry, designed to evaluate goal progress, collision avoidance, and obstacle clearance of VLAs. Our evaluation shows that VEGA achieves competitive goal progress while reducing collisions by 33.0% and improving obstacle clearance by 17.9% over the strongest baseline on VEGABench, while improving success by at least 150.0%, reducing collisions by at least 66.7%, and improving obstacle clearance by at least 60.0% in real-world trials. Ultimately, we demonstrate that video-derived geometric supervision provides a scalable and effective signal for training obstacle-aware navigation VLAs. The code and benchmark will be released at the time of publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VEGA, which reconstructs local scene geometry from monocular egocentric navigation videos to sample goals and generate obstacle-aware trajectories; these trajectories supervise a flow-matching VLA policy that operates vision-only at inference. It also releases VEGABench (250k scenes, ~5M goals) and reports that VEGA matches baselines on goal progress while cutting collisions 33% and improving clearance 17.9% on the benchmark, with larger gains (≥150% success, ≥66.7% fewer collisions, ≥60% better clearance) in real-world trials.
Significance. If the monocular reconstruction produces sufficiently accurate local geometry, the method supplies a scalable training signal for obstacle-aware navigation VLAs from unlabeled internet video, distilling geometric reasoning into a purely visual policy without requiring depth or maps at test time.
major comments (1)
- [Abstract] Abstract, paragraph on trajectory generation: the central claim that video-derived geometric supervision yields the reported collision reductions (33% on VEGABench, ≥66.7% real-world) requires that monocular reconstruction errors remain small enough not to inject false obstacles or unsafe paths into the supervision trajectories; no quantitative validation of reconstruction accuracy (e.g., against LiDAR, stereo, or known ground-truth geometry) or error-propagation analysis is referenced, which is load-bearing for attributing performance gains to the geometric signal rather than reconstruction artifacts.
Simulated Author's Rebuttal
We thank the referee for the detailed comment on the need for quantitative validation of monocular reconstruction accuracy. This is a substantive point regarding attribution of the reported gains. We respond below and commit to revisions that directly address the concern.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph on trajectory generation: the central claim that video-derived geometric supervision yields the reported collision reductions (33% on VEGABench, ≥66.7% real-world) requires that monocular reconstruction errors remain small enough not to inject false obstacles or unsafe paths into the supervision trajectories; no quantitative validation of reconstruction accuracy (e.g., against LiDAR, stereo, or known ground-truth geometry) or error-propagation analysis is referenced, which is load-bearing for attributing performance gains to the geometric signal rather than reconstruction artifacts.
Authors: We agree that the absence of direct quantitative validation of reconstruction accuracy against ground-truth geometry (LiDAR, stereo, etc.) and error-propagation analysis is a limitation in the current manuscript. The paper currently supports its claims via downstream policy metrics on VEGABench and real-world trials, where the vision-only policy trained on the generated trajectories shows clear collision and clearance improvements. However, this does not fully isolate reconstruction quality from other factors. In the revision we will add a dedicated subsection (likely in Section 4 or a new Appendix) that reports reconstruction accuracy metrics on a held-out subset of egocentric videos for which stereo depth or other reference geometry is available. This will include standard depth metrics (Abs Rel, RMSE, δ<1.25) and a targeted error-propagation study showing how depth noise affects sampled goals and generated trajectories. We will also discuss the operating regime (local, short-horizon navigation) in which the observed errors remain tolerable. These additions will strengthen the attribution argument without altering the core method or results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical pipeline that reconstructs local geometry from monocular egocentric video, samples goals, generates trajectories, and uses the resulting distribution to train a flow-matching VLA policy, with geometry used only at training time. Reported metrics (goal progress, collision reduction, obstacle clearance) are obtained from external evaluation on VEGABench (250k scenes) and real-world trials rather than from any internal fit, self-definition, or self-citation chain. No equations, parameter-fitting steps, or load-bearing claims reduce the central result to quantities defined by the method's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Monocular video can be used to reconstruct local scene geometry accurately enough for obstacle-aware trajectory planning.
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
Pith/arXiv arXiv 2023
-
[2]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[4]
NVIDIA, :, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z...
Pith/arXiv arXiv 2025
-
[5]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[6]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[7]
Kawaharazuka, J
K. Kawaharazuka, J. Oh, J. Yamada, I. Posner, and Y . Zhu. Vision-language-action models for robotics: A review towards real-world applications.IEEE Access, 2025
2025
-
[8]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
- [9]
- [10]
-
[11]
D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine. Gnm: A general navigation model to drive any robot. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 7226–7233. IEEE, 2023
2023
-
[12]
Caesar, V
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 9
2020
-
[13]
Chang, J
M.-F. Chang, J. Lambert, P. Sangkloy, J. Singh, S. Bak, A. Hartnett, D. Wang, P. Carr, S. Lucey, D. Ramanan, et al. Argoverse: 3d tracking and forecasting with rich maps. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8748–8757, 2019
2019
-
[14]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
2020
-
[15]
C. Glossop, W. Chen, A. Bhorkar, D. Shah, and S. Levine. Cast: Counterfactual labels improve instruction following in vision-language-action models, 2025. URLhttps://arxiv.org/ abs/2508.13446
Pith/arXiv arXiv 2025
-
[16]
G. Seneviratne, J. An, V . Shende, S. Ellahy, Y . Amin, K. Manasanjani, S. Chopra, J. D. Kannan, and D. Manocha. Chop: Counterfactual human preference labels improve obstacle avoidance in visuomotor navigation policies.arXiv preprint arXiv:2603.02004, 2026
arXiv 2026
- [17]
- [18]
-
[19]
Seneviratne, J
G. Seneviratne, J. An, S. Ellahy, K. Weerakoon, M. B. Elnoor, J. D. Kannan, A. T. Sunil, and D. Manocha. Halo: Human preference aligned offline reward learning for robot navigation,
-
[20]
URLhttps://arxiv.org/abs/2508.01539
-
[21]
Werby, C
A. Werby, C. Huang, M. B¨uchner, A. Valada, and W. Burgard. Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation. InFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024, 2024
2024
- [22]
- [23]
-
[24]
M. G. Castro, S. Rajagopal, D. Gorbatov, M. Schmittle, R. Baijal, O. Zhang, R. Scalise, S. Talia, E. Romig, C. de Melo, B. Boots, and A. Gupta. Vamos: A hierar- chical vision-language-action model for capability-modulated and steerable navigation. ArXiv, abs/2510.20818, 2025. URLhttps://api.semanticscholar.org/CorpusID: 282304520
arXiv 2025
-
[25]
Kumar, S
A. Kumar, S. Gupta, and J. Malik. Learning navigation subroutines from egocentric videos. In Conference on Robot Learning, pages 617–626. PMLR, 2020
2020
-
[26]
X. Liu, J. Li, Y . Jiang, N. Sujay, Z. Yang, J. Zhang, J. Abanes, J. Zhang, and C. Feng. City- walker: Learning embodied urban navigation from web-scale videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6875–6885, 2025
2025
-
[27]
Z. Chen, Y . Guo, Z. Chu, M. Luo, Y . Shen, M. Sun, J. Hu, S. Xie, K. Yang, P. Shi, Z. Gu, L. Liu, H. Han, X. Wu, M. Xu, and Y . Zhang. Socialnav: Training human-inspired foundation model for socially-aware embodied navigation.ArXiv, abs/2511.21135, 2025. URLhttps: //api.semanticscholar.org/CorpusID:283262361
arXiv 2025
- [28]
-
[29]
Sridhar, D
A. Sridhar, D. Shah, C. Glossop, and S. Levine. Nomad: Goal masked diffusion policies for navigation and exploration. In2024 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 63–70. IEEE, 2024
2024
- [30]
-
[31]
M. N. Finean, W. Merkt, and I. Havoutis. Predicted composite signed-distance fields for real- time motion planning in dynamic environments. InProceedings of the International Confer- ence on Automated Planning and Scheduling, volume 31, pages 616–624, 2021
2021
-
[32]
S. T. Bukhari, D. Lawson, and A. H. Qureshi. Differentiable composite neural signed distance fields for robot navigation in dynamic indoor environments. In2025 International Conference on Robotics and Automation (ICRA). IEEE, 2025
2025
-
[33]
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[34]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
Pith/arXiv arXiv 2022
-
[35]
Z. Ren, Z. Zhang, W. Li, Q. Liu, and H. Tang. Anydepth: Depth estimation made easy, 2026. URLhttps://arxiv.org/abs/2601.02760
arXiv 2026
-
[36]
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao. Depth anything: Unleashing the power of large-scale unlabeled data, 2024. URLhttps://arxiv.org/abs/2401.10891
arXiv 2024
-
[37]
R. Wang, S. Xu, C. Dai, J. Xiang, Y . Deng, X. Tong, and J. Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision,
-
[38]
URLhttps://arxiv.org/abs/2410.19115
-
[39]
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang. Moge- 2: Accurate monocular geometry with metric scale and sharp details, 2025. URLhttps: //arxiv.org/abs/2507.02546
Pith/arXiv arXiv 2025
-
[40]
M. A. Fischler and R. C. Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Commun. ACM, 24(6):381–395, June 1981. ISSN 0001-0782. doi:10.1145/358669.358692. URLhttps://doi.org/10. 1145/358669.358692
-
[41]
the person wearing the orange jacket
B. Xiao, H. Wu, W. Xu, X. Dai, H. Hu, Y . Lu, M. Zeng, C. Liu, and L. Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks, 2023. URLhttps://arxiv. org/abs/2311.06242. 11 8 Appendix 8.1 Evaluation Metrics We define the evaluation metrics used in VEGA-Bench mathematically here. Let a predicted trajec- tory beY={p t}T t=0, wher...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.