See What I See, Know What I Think: Dense Latent Communication Across Heterogeneous Agents
Pith reviewed 2026-06-27 04:55 UTC · model grok-4.3
The pith
Heterogeneous language models can transfer both observations and reasoning by aligning their KV caches with a lightweight transformation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A lightweight cross-model cache transformation trained in two phases enables dense KV-cache communication between heterogeneous agents, allowing them to share both what one agent sees and how it thinks.
What carries the argument
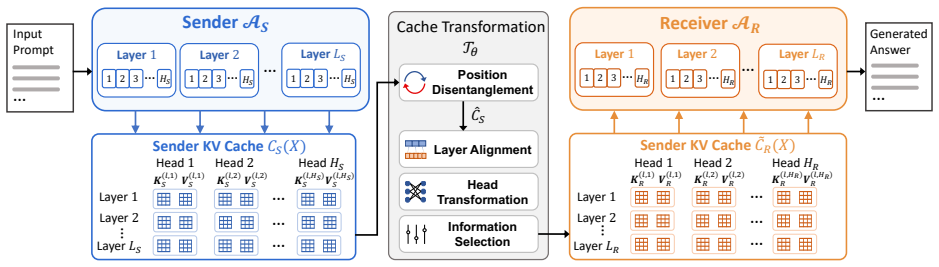
lightweight cross-model cache transformation with two-phase training (reconstruction followed by generation) that aligns KV caches across different model sizes.
If this is right
- Multi-agent systems can exchange perceptions and internal states at roughly two-to-three times lower compute than text messaging in context-aware settings.
- Context-unaware transfer becomes viable, allowing a receiver with no local input to still benefit from another agent's cache.
- The same alignment works across model sizes from 4B to 14B on both in-domain and out-of-domain benchmarks.
- Prior heterogeneous methods that rely on shared inputs or steering alone are outperformed by the dense alignment approach.
Where Pith is reading between the lines
- The same lightweight transformation could be tested on model families with larger architectural differences to check how far the duality generalizes.
- Deployed agent teams might reduce bandwidth and latency by substituting cache transfers for text in time-critical coordination tasks.
- If the reconstruction phase can be made even cheaper, the method might extend to real-time streaming communication among many agents.
Load-bearing premise
That KV-cache states from models of different sizes contain alignable information about both reasoning signals and contextual knowledge.
What would settle it
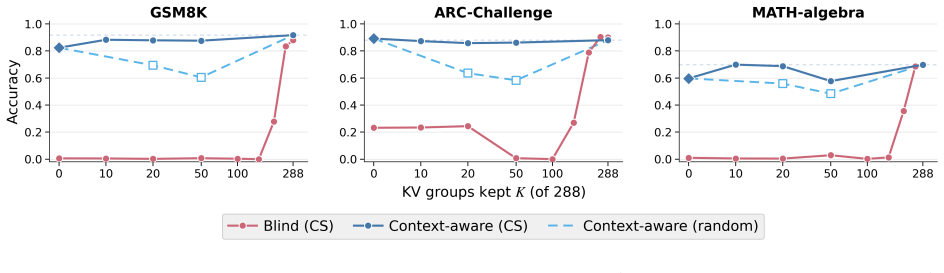
Failure of the transformed caches to improve downstream task performance when the receiver model is given only the cache and no input tokens.
Figures

read the original abstract
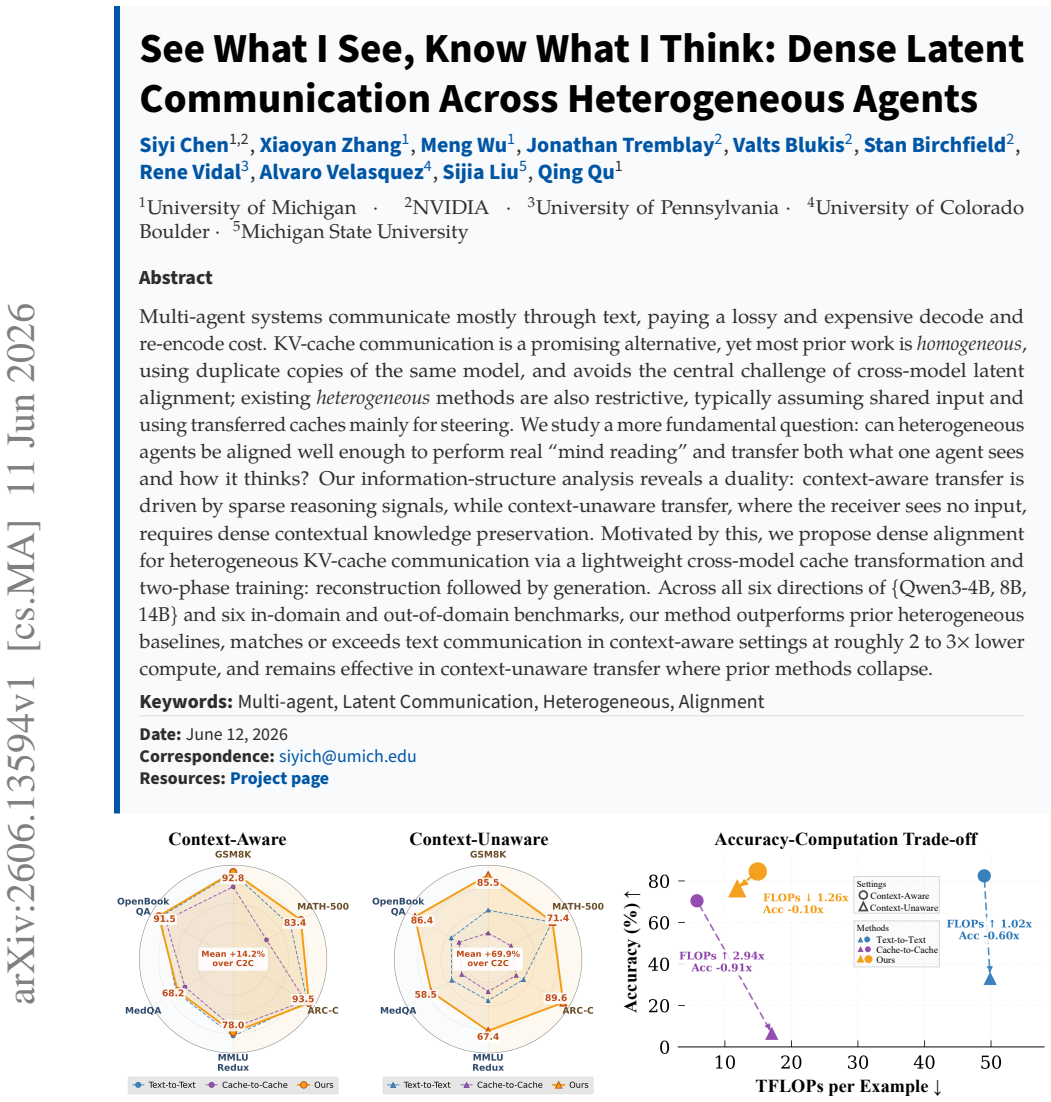
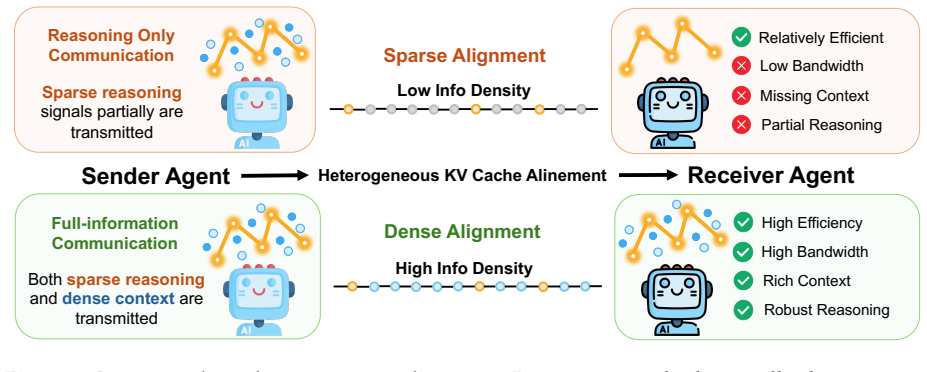
Multi-agent systems communicate mostly through text, paying a lossy and expensive decode and re-encode cost. KV-cache communication is a promising alternative, yet most prior work is homogeneous, using duplicate copies of the same model, and avoids the central challenge of cross-model latent alignment; existing heterogeneous methods are also restrictive, typically assuming shared input and using transferred caches mainly for steering. We study a more fundamental question: can heterogeneous agents be aligned well enough to perform real "mind reading" and transfer both what one agent sees and how it thinks? Our information-structure analysis reveals a duality: context-aware transfer is driven by sparse reasoning signals, while context-unaware transfer, where the receiver sees no input, requires dense contextual knowledge preservation. Motivated by this, we propose dense alignment for heterogeneous KV-cache communication via a lightweight cross-model cache transformation and two-phase training: reconstruction followed by generation. Across all six directions of {Qwen3-4B, 8B, 14B} and six in-domain and out-of-domain benchmarks, our method outperforms prior heterogeneous baselines, matches or exceeds text communication in context-aware settings at roughly 2 to 3 times lower compute, and remains effective in context-unaware transfer where prior methods collapse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that heterogeneous agents can achieve effective 'mind reading' via dense KV-cache communication using a lightweight cross-model cache transformation trained in two phases (reconstruction then generation). Motivated by an information-structure duality (sparse reasoning signals for context-aware transfer vs. dense knowledge preservation for context-unaware), the method is evaluated across all six transfer directions among Qwen3-4B/8B/14B models on six in- and out-of-domain benchmarks. It reportedly outperforms prior heterogeneous baselines, matches or exceeds text communication in context-aware settings at 2-3x lower compute, and succeeds in context-unaware transfer where baselines collapse.
Significance. If the empirical results hold, the work is significant for multi-agent systems: it moves beyond homogeneous KV-cache methods and restrictive heterogeneous approaches (shared input, steering-only) to enable practical cross-model latent alignment. The two-phase training and duality analysis offer a concrete, scalable path to lower-cost communication that preserves both observations and reasoning, with potential impact on efficient agent coordination.
minor comments (3)
- The abstract states results 'across all six directions' and 'six benchmarks' but does not name the specific transfer pairs or benchmarks; adding these in §4 or a table would improve reproducibility without altering the central claim.
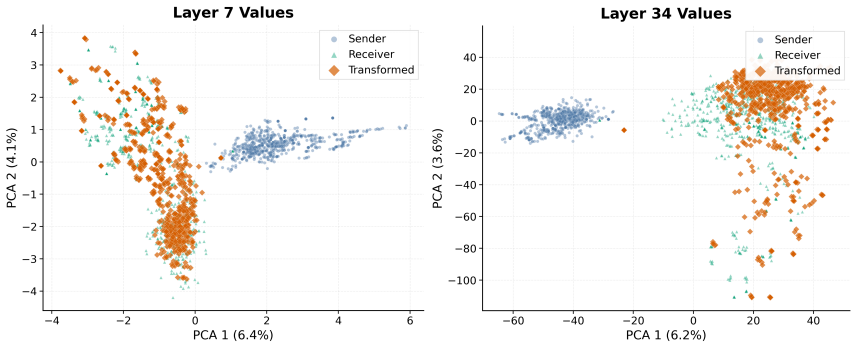
- The information-structure duality is described as revealed by analysis yet presented only motivationally; a brief quantitative illustration (e.g., sparsity metrics or activation statistics) in the methods section would strengthen the motivation without requiring new theorems.
- Compute claims ('roughly 2 to 3 times lower') are given relative to text communication; specifying the exact metric (tokens, FLOPs, or wall-clock) and the baseline implementation details would clarify the comparison.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its significance for multi-agent systems, and the recommendation for minor revision. We are pleased that the empirical results and the proposed two-phase training approach were viewed favorably.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method for heterogeneous KV-cache communication using a lightweight cross-model transformation trained in two phases, motivated by an information-structure duality analysis. All central claims rest on reported outperformance across six transfer directions, three model sizes, and six benchmarks, with direct comparisons to baselines and text communication. No equations, fitted parameters renamed as predictions, self-citation load-bearing theorems, or self-definitional reductions appear in the derivation chain; the work is self-contained against external benchmarks and does not reduce its results to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
First conference on language modeling , year=
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author=. First conference on language modeling , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Rema: Learning to meta-think for llms with multi-agent reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
International Conference on Learning Representations , volume=
MetaGPT: Meta programming for a multi-agent collaborative framework , author=. International Conference on Learning Representations , volume=
-
[4]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Optima: Optimizing effectiveness and efficiency for llm-based multi-agent system , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[5]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Agentdropout: Dynamic agent elimination for token-efficient and high-performance llm-based multi-agent collaboration , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
International Conference on Learning Representations , volume=
Cut the crap: An economical communication pipeline for llm-based multi-agent systems , author=. International Conference on Learning Representations , volume=
-
[7]
Advances in Neural Information Processing Systems , volume=
Thought communication in multiagent collaboration , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
International Conference on Learning Representations , volume=
Let models speak ciphers: Multiagent debate through embeddings , author=. International Conference on Learning Representations , volume=
-
[9]
arXiv preprint arXiv:2412.06769 , year=
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
-
[10]
arXiv preprint arXiv:2511.09149 , year=
Enabling agents to communicate entirely in latent space , author=. arXiv preprint arXiv:2511.09149 , year=
-
[11]
arXiv preprint arXiv:2501.14082 , year=
Communicating activations between language model agents , author=. arXiv preprint arXiv:2501.14082 , year=
-
[12]
arXiv preprint arXiv:2510.03346 , year=
KVComm: Enabling Efficient LLM Communication through Selective KV Sharing , author=. arXiv preprint arXiv:2510.03346 , year=
-
[13]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Augmenting Multi-Agent Communication with State Delta Trajectory , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[14]
arXiv preprint arXiv:2510.03215 , year=
Cache-to-cache: Direct semantic communication between large language models , author=. arXiv preprint arXiv:2510.03215 , year=
-
[15]
arXiv preprint arXiv:2604.13349 , year=
When Less Latent Leads to Better Relay: Information-Preserving Compression for Latent Multi-Agent LLM Collaboration , author=. arXiv preprint arXiv:2604.13349 , year=
-
[16]
arXiv preprint arXiv:2604.25917 , year=
Recursive multi-agent systems , author=. arXiv preprint arXiv:2604.25917 , year=
-
[17]
arXiv preprint arXiv:2509.21164 , year=
Mixture of thoughts: Learning to aggregate what experts think, not just what they say , author=. arXiv preprint arXiv:2509.21164 , year=
-
[18]
arXiv preprint arXiv:2602.03695 , year=
Agent Primitives: Reusable Latent Building Blocks for Multi-Agent Systems , author=. arXiv preprint arXiv:2602.03695 , year=
-
[19]
arXiv preprint arXiv:2602.15382 , year=
The vision wormhole: Latent-space communication in heterogeneous multi-agent systems , author=. arXiv preprint arXiv:2602.15382 , year=
-
[20]
arXiv preprint arXiv:2411.02820 , year=
DroidSpeak: KV Cache Sharing for Cross-LLM Communication and Multi-LLM Serving , author=. arXiv preprint arXiv:2411.02820 , year=
-
[21]
arXiv preprint arXiv:2511.20639 , year=
Latent collaboration in multi-agent systems , author=. arXiv preprint arXiv:2511.20639 , year=
-
[22]
arXiv preprint arXiv:2603.03335 , year=
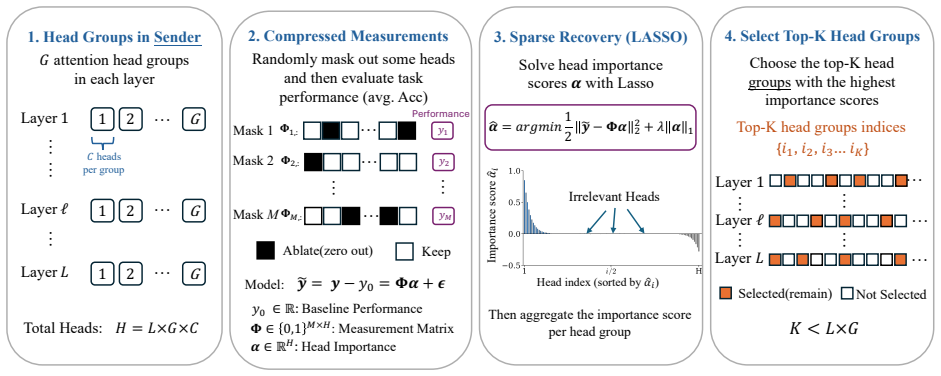
Identifying Functional Heads of Large Language Models with Compressed Sensing , author=. arXiv preprint arXiv:2603.03335 , year=
-
[23]
International Conference on Learning Representations , volume=
Aflow: Automating agentic workflow generation , author=. International Conference on Learning Representations , volume=
-
[24]
arXiv preprint arXiv:2501.06322 , year=
Multi-agent collaboration mechanisms: A survey of llms , author=. arXiv preprint arXiv:2501.06322 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Sirius: Self-improving multi-agent systems via bootstrapped reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2604.21794 , year=
Learning to Communicate: Toward End-to-End Optimization of Multi-Agent Language Systems , author=. arXiv preprint arXiv:2604.21794 , year=
-
[27]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[28]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[29]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[30]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[31]
2025 International Joint Conference on Neural Networks (IJCNN) , pages=
Llm-medqa: Enhancing medical question answering through case studies in large language models , author=. 2025 International Joint Conference on Neural Networks (IJCNN) , pages=. 2025 , organization=
2025
-
[32]
Are we done with mmlu? , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[33]
EMNLP , year=
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author=. EMNLP , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.