AI Conversational Interviewing: Scaling Up Semi-Structured and In-depth Interviews
Pith reviewed 2026-06-26 15:50 UTC · model grok-4.3
The pith
AI systems can scale semi-structured interviews to reveal reasoning and mental models that standardized surveys miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
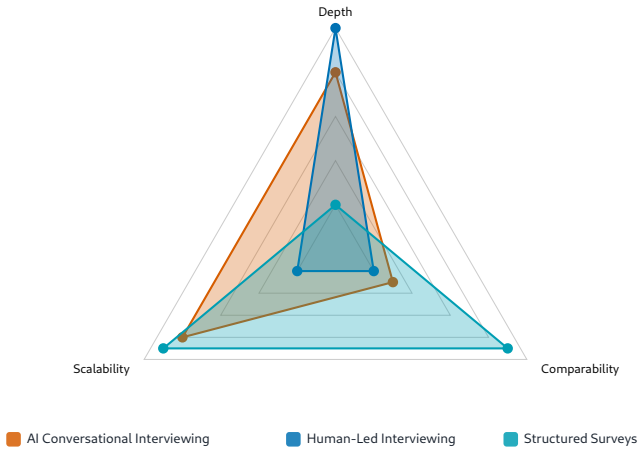
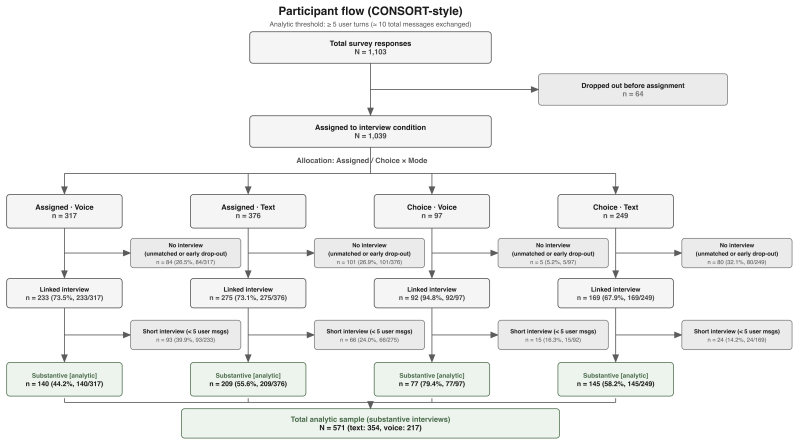
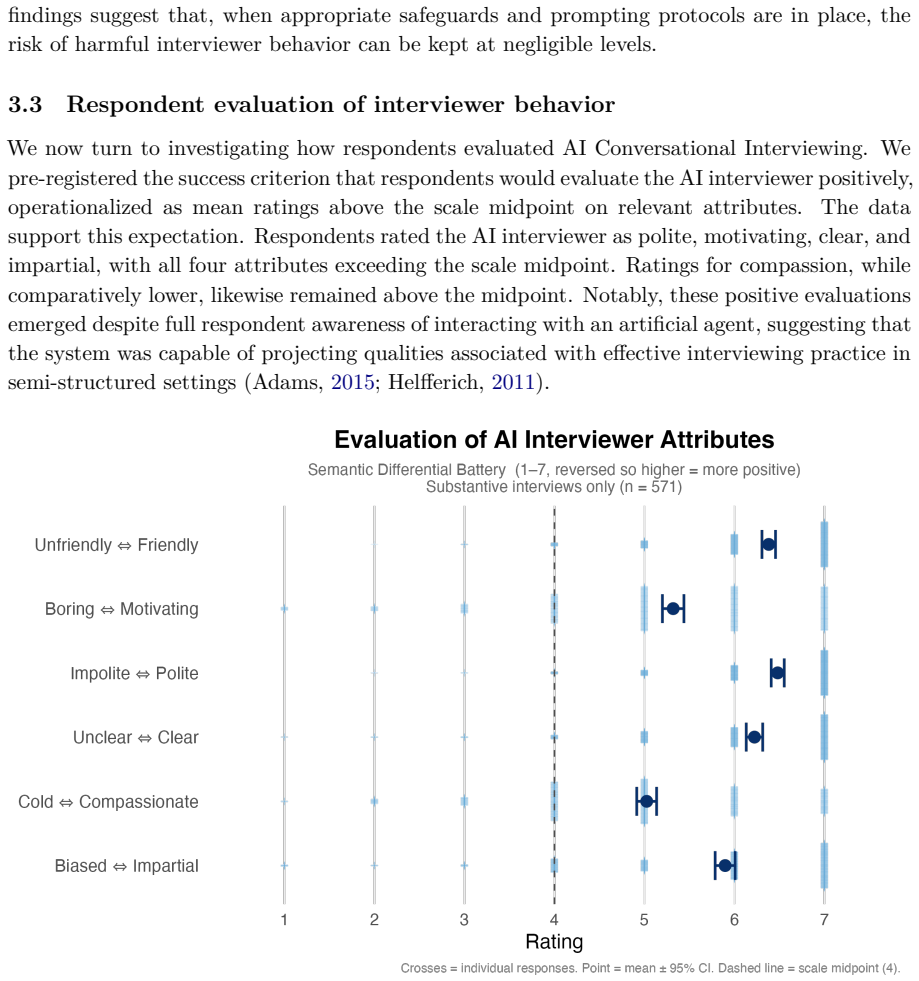
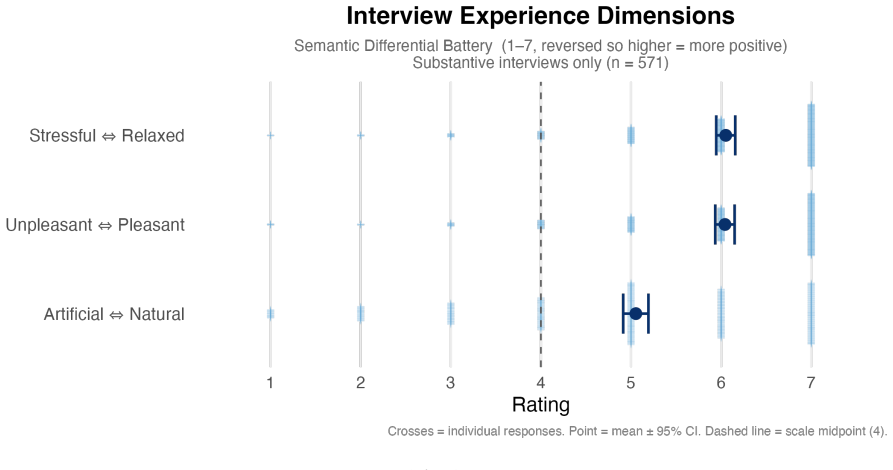
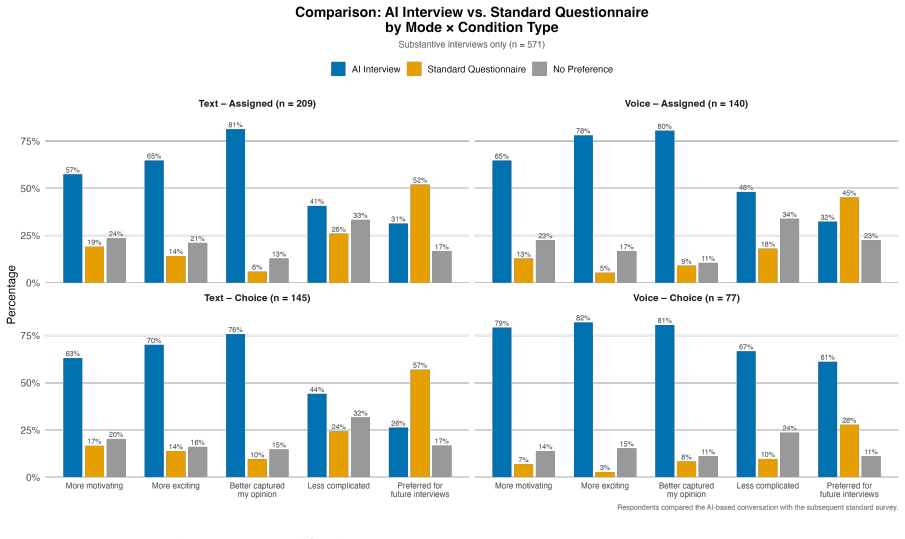
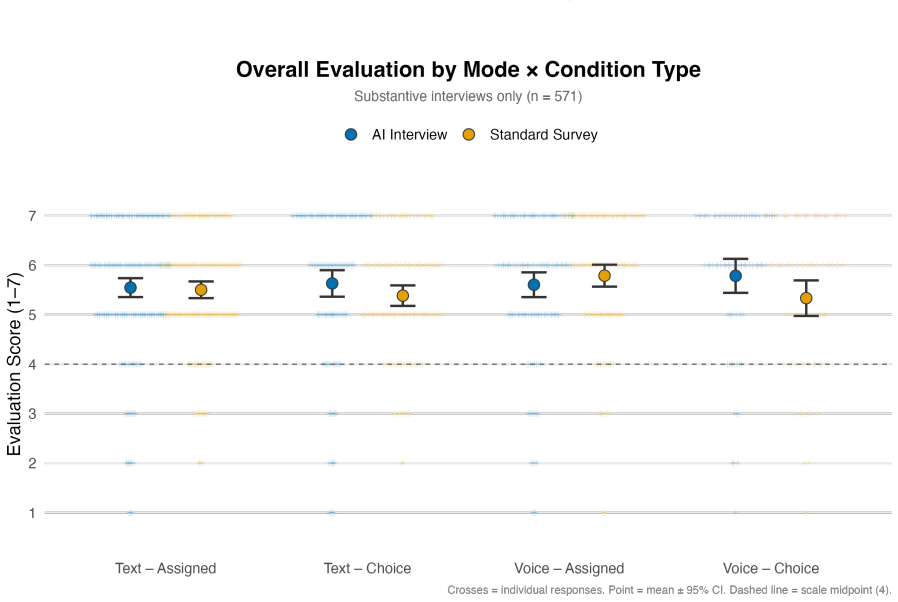
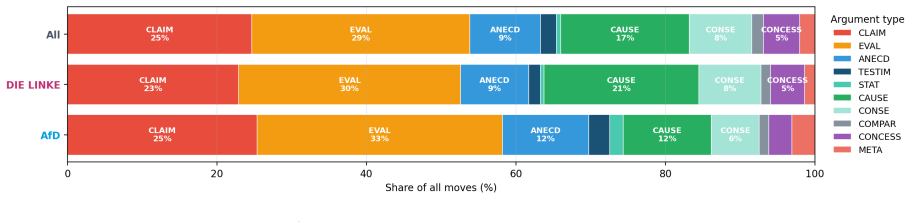
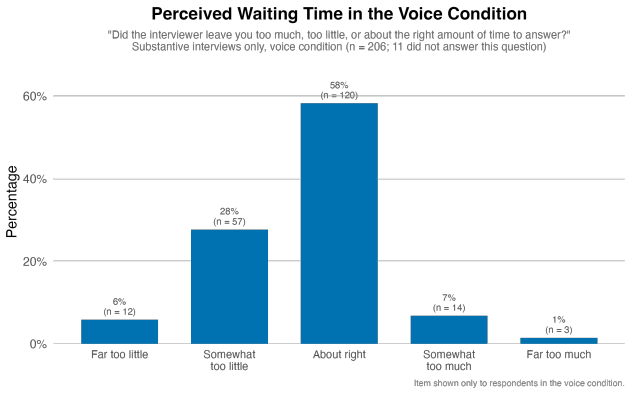
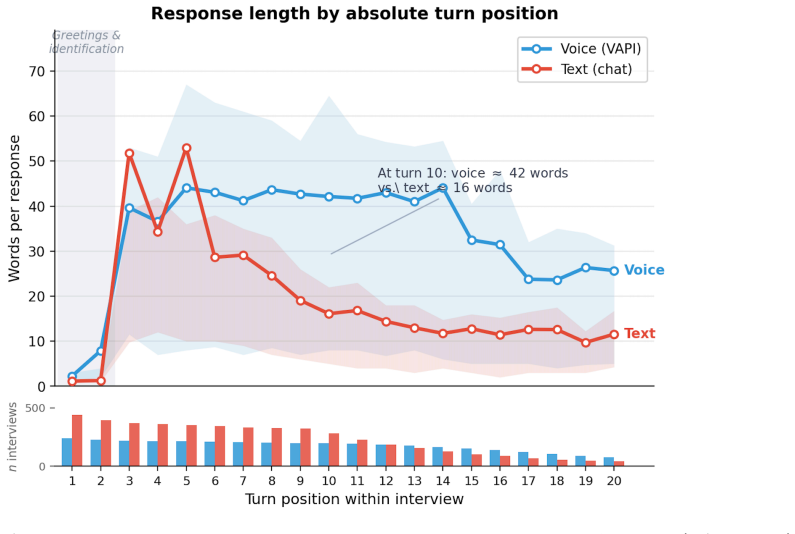
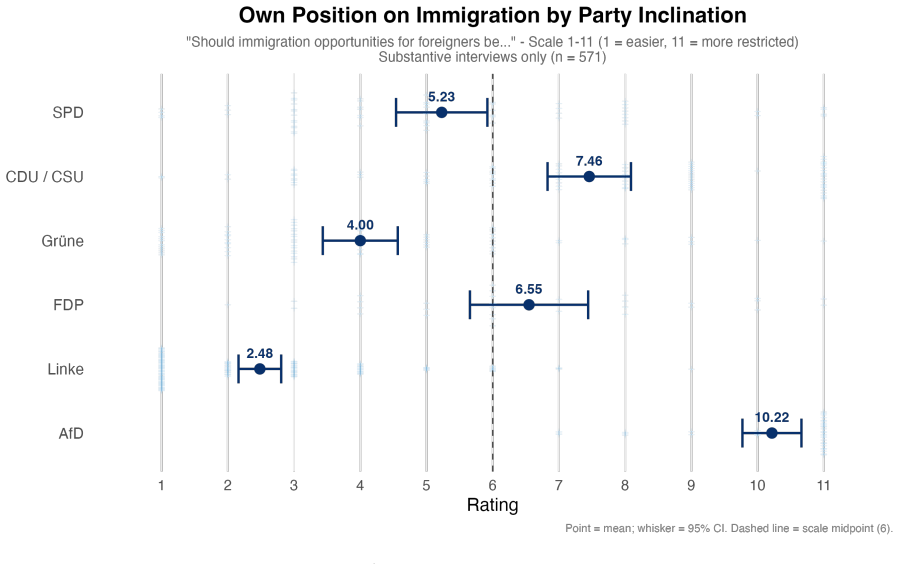
The authors claim that AI Conversational Interviewing supplies scalable open-ended data whose transcripts surface considerations and reasoning beyond the reach of standardized survey items, including markedly different mental models of migration among subgroups that hold similar attitude levels. Participant evaluations of the AI interviews reached or exceeded those of the standardized survey in voice, chat, and free-choice modes, although completion itself varied by condition.
What carries the argument
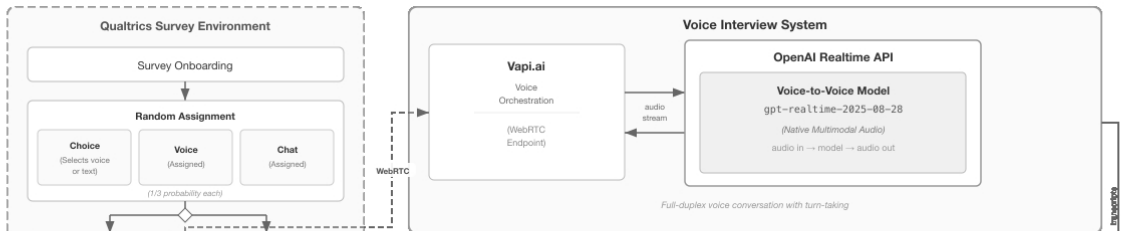
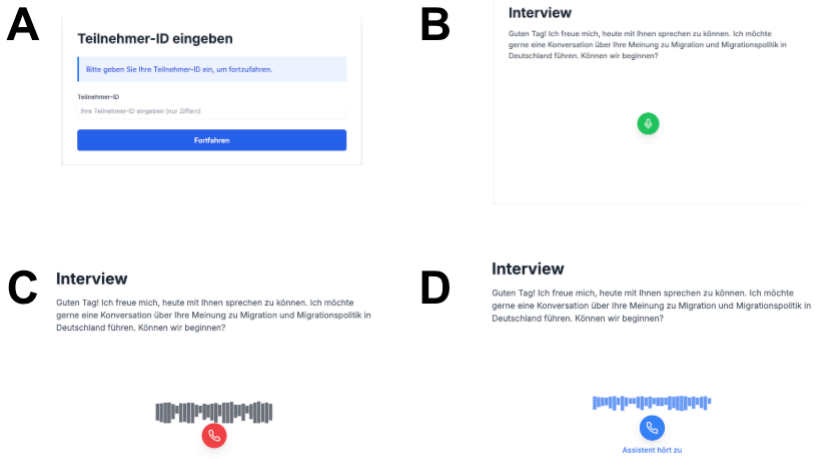
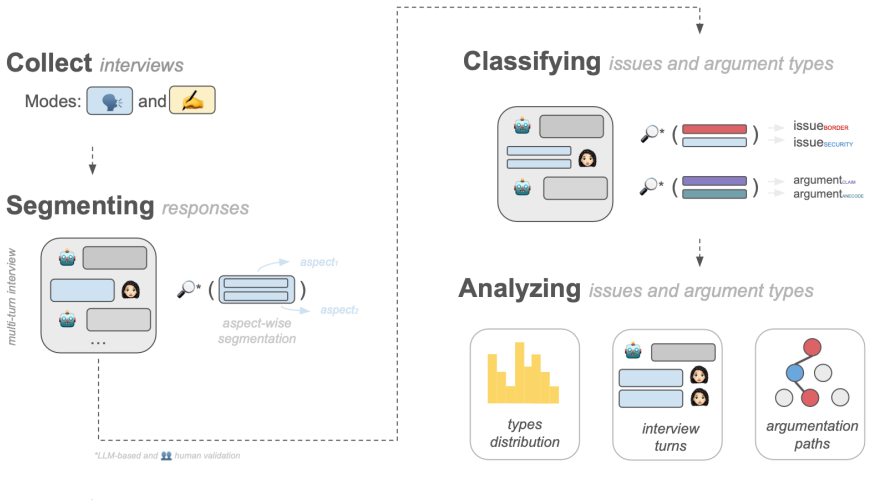
AI Conversational Interviewing, an AI-led system that conducts adaptive open-ended probing in voice, chat, or free-choice modes to gather detailed respondent reasoning on a policy topic.
If this is right
- Researchers can gather open-ended public opinion data from hundreds of respondents without relying on trained human interviewers.
- Analyses can distinguish reasoning patterns among subgroups that register similar scores on attitude scales.
- The method produces respondent evaluations at or above those of standardized surveys in multiple delivery modes.
- Open release of transcripts and pipeline materials allows direct testing on new topics and populations.
Where Pith is reading between the lines
- The approach could be applied to other domains where attitude measures conceal varied underlying beliefs, such as economic policy or technology adoption.
- Automated analysis of the resulting transcripts might identify reasoning clusters more efficiently than manual coding.
- Longer-term studies could track whether the mental models surfaced by AI interviews predict behavior better than attitude batteries alone.
Load-bearing premise
An AI system can conduct effective semi-structured probing and maintain conversational quality comparable to trained human interviewers without introducing systematic bias or limiting response depth.
What would settle it
A direct side-by-side comparison in which human interviewers elicit significantly greater response depth or less patterned bias than the AI system on the same migration questions.
Figures

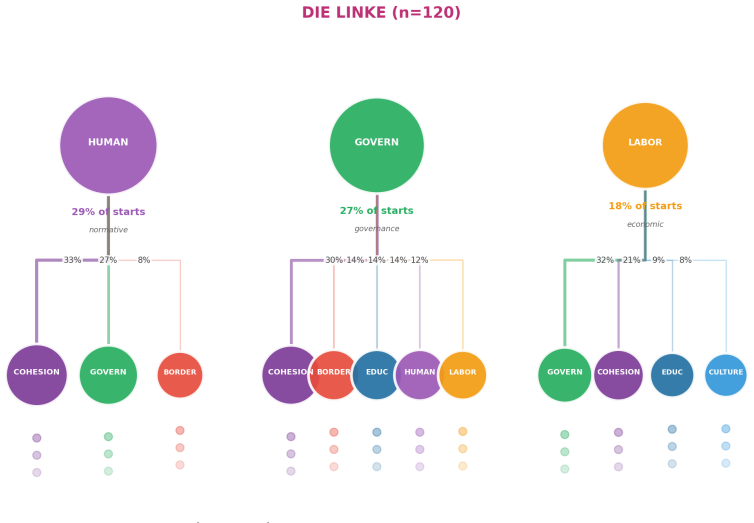
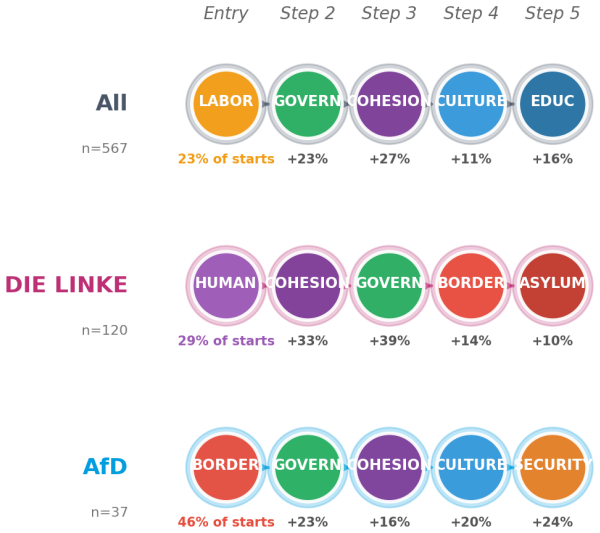
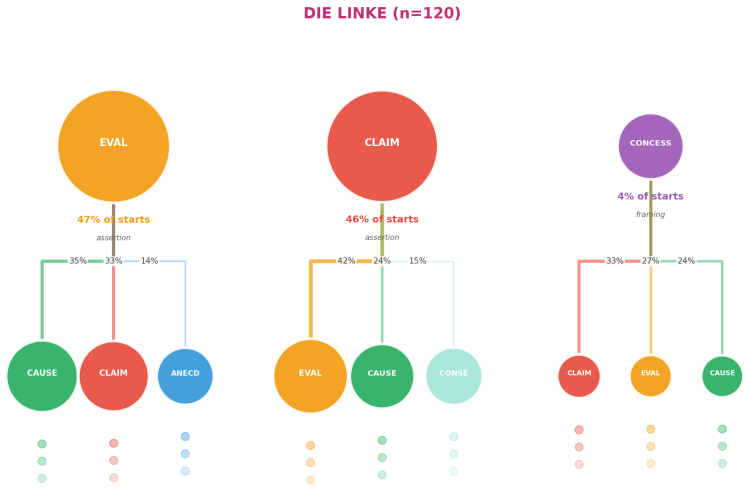

read the original abstract
Public opinion research has long faced a trade-off between depth and scale: standardized surveys enable large-scale measurement but restrict respondents to researcher-defined categories, obscuring the diversity of unexpected considerations that underlie public sentiment. More conversational interviews provide richer insights through open-ended probing, but their reliance on trained human interviewers has kept them difficult to scale. This study introduces AI Conversational Interviewing as a method for collecting open-ended public opinion data at scale, pursuing three objectives: to demonstrate the analytical value of conversational text data for questions beyond the reach of closed-ended items; to assess the method's practical viability through participants' own evaluations; and to inform implementation by experimentally comparing voice-based, chat-based, and free-choice interview modes. We conducted a study combining an AI-led interview with a standardized survey on migration policy among 571 respondents recruited via Prolific and Payback Panel. The findings establish AI Conversational Interviewing as a viable and valuable addition to the social-science toolkit. The conversational transcripts surface considerations and reasoning that a comprehensive standardized battery does not capture such as markedly different mental models of migration among subgroups with similar attitudes levels. Among respondents who completed the interview, evaluations of the AI interview were at or above those of the standardized survey across modes, although completion itself varied by condition. By releasing open data and open-source pipeline materials, the study contributes to a growing literature on harnessing artificial intelligence to expand the methods of public opinion measurement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AI Conversational Interviewing as a scalable method for semi-structured public-opinion interviews. It reports results from a 571-participant experiment on migration policy that pairs an AI-led interview (voice, chat, or free-choice modes) with a standardized survey battery; the central findings are that the conversational transcripts reveal considerations and mental models not captured by closed items, that completers rate the AI interview at or above the survey on participant evaluations, and that completion rates vary by mode. The study releases open data and pipeline code.
Significance. If the method can be shown to produce human-comparable probing depth and thematic coverage without systematic bias, it would meaningfully expand the toolkit for combining scale with open-ended insight in opinion research. The planned open release of data and code is a concrete strength that supports reproducibility and further testing.
major comments (3)
- [Abstract, objectives and findings sections] Abstract, objectives and findings sections: the claim that AI Conversational Interviewing is a 'viable and valuable addition to the social-science toolkit' and scales semi-structured interviews rests on an implicit assumption of comparability to trained human interviewers, yet the experiment contains no human-interviewer arm; the only comparison is to a standardized survey, leaving open whether observed differences in surfaced considerations arise from conversational format, AI artifacts, or both.
- [Findings section] Findings section (as described in abstract): no quantitative metrics of probe frequency, response elaboration, or inter-rater coded thematic diversity are reported to ground the assertion that transcripts 'surface considerations and reasoning that a comprehensive standardized battery does not capture'; without these, the analytical-value claim cannot be evaluated against the survey baseline.
- [Methods] Methods (implied by soundness note): the manuscript provides no details on the AI interview protocol, transcript coding scheme, statistical tests for mode differences, or handling of non-completers; these omissions directly affect assessment of the viability and mode-comparison objectives.
minor comments (1)
- [Abstract] Clarify in the abstract whether the AI system uses a fixed prompt template or dynamic probing logic, as this bears on replicability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the positioning and presentation of our work. We respond to each major comment below.
read point-by-point responses
-
Referee: Abstract, objectives and findings sections: the claim that AI Conversational Interviewing is a 'viable and valuable addition to the social-science toolkit' and scales semi-structured interviews rests on an implicit assumption of comparability to trained human interviewers, yet the experiment contains no human-interviewer arm; the only comparison is to a standardized survey, leaving open whether observed differences in surfaced considerations arise from conversational format, AI artifacts, or both.
Authors: We agree that the absence of a human-interviewer comparison arm means we cannot claim direct comparability to trained human interviewers. The study demonstrates value relative to standardized surveys by showing additional considerations in the conversational data and comparable or better participant evaluations. We will revise the relevant sections to remove any implication of human comparability and explicitly frame the contribution as scaling open-ended interviewing beyond surveys, while noting the lack of human benchmark as a limitation for future research. revision: yes
-
Referee: Findings section (as described in abstract): no quantitative metrics of probe frequency, response elaboration, or inter-rater coded thematic diversity are reported to ground the assertion that transcripts 'surface considerations and reasoning that a comprehensive standardized battery does not capture'; without these, the analytical-value claim cannot be evaluated against the survey baseline.
Authors: The manuscript currently supports the claim with qualitative illustrations of distinct mental models. To address this, we will add quantitative metrics in the revision, including the count of unique considerations identified through thematic coding of transcripts compared to survey responses, and report inter-rater agreement for the coding process. This will provide a more robust evaluation of the analytical value. revision: yes
-
Referee: Methods (implied by soundness note): the manuscript provides no details on the AI interview protocol, transcript coding scheme, statistical tests for mode differences, or handling of non-completers; these omissions directly affect assessment of the viability and mode-comparison objectives.
Authors: We will revise the Methods section to include fuller details on the AI interview protocol, the coding scheme for transcripts, the statistical tests applied to mode differences, and the approach to non-completers. The open release of data and code will also aid in assessing these aspects. revision: yes
Circularity Check
No circularity: purely empirical study with no derivations or self-referential predictions
full rationale
The paper reports an empirical experiment (n=571) contrasting AI-led interviews against a standardized survey on migration policy, evaluating participant satisfaction, completion rates, and qualitative transcript content. No equations, fitted parameters, model predictions, or derivation chains exist. Claims rest on direct data collection and open-ended analysis rather than any reduction of outputs to inputs by construction. No self-citations are invoked to justify load-bearing methodological uniqueness or uniqueness theorems. The absence of a human-interviewer arm is a methodological limitation but does not constitute circularity under the defined criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AI systems can conduct effective semi-structured interviews that elicit open-ended responses comparable in quality to those from trained human interviewers
Reference graph
Works this paper leans on
-
[1]
Can Generative AI Improve Social Science?
issn: 1047-1987, 1476-4989. doi: 10.1093/pan/mpt049. url: https://www.cambridge. org/core/product/identifier/S1047198700013942/type/journal_article (visited on 07/30/2024). Bail, Christopher A. (2022). “Can Generative AI Improve Social Science?” In: Big Data & Society 9.1, pp. 1–7. doi: 10.1177/20539517221080146. url: https://journals.sagepub. com/doi/ful...
-
[2]
Does prompt formatting have any impact on llm performance?
doi: 10.48550/ARXIV.2411.10541. url: https://arxiv.org/abs/2411.10541 (visited on 02/27/2026). Helfferich, Cornelia (2011). Die Qualität qualitativer Daten: Manual für die Durchführung quali- tativer Interviews. ger. 4. Auflage. SpringerLink Bücher. Wiesbaden: VS Verlag für Sozialwis- senschaften. isbn: 978-3-531-17382-5 978-3-531-92076-4. doi: 10.1007/97...
-
[3]
Why open-source generative AI models are an ethical way forward for science
doi: 10.18653/v1/2023.argmining-1.15 . url: https://aclanthology.org/2023. argmining-1.15/. Spirling, Arthur (2023). “Why open-source generative AI models are an ethical way forward for science” . In: Nature 616.7957, pp. 413–413. Spradley, James P. (2016). The ethnographic interview . eng. Long Grove, Illinois: Waveland Press, Inc. isbn: 978-1-4786-3207-...
-
[4]
Ich bestätige, dass ich die Studieninformationen gelesen habe und Gelegenheit hatte, die Informationen zu prüfen
-
[5]
Ich stimme der Erhebung und Speicherung meiner Daten in anonymisierter Form zu, die zu Replikationszwecken der Forschungsgemeinschaft zur Verfügung gestellt werden können
-
[6]
Ich stimme der Teilnahme an der Studie zu
-
[7]
Ich bestätige, dass ich mindestens 18 Jahre alt bin
-
[8]
Ich stimme zu, dass Daten auch außerhalb der EU verarbeitet und gespeichert werden können
Ich erkläre mich einverstanden, dass im Rahmen dieser Studie Daten von V API, Literal.AI, Qualtrics und OpenAI verarbeitet und gespeichert werden. Ich stimme zu, dass Daten auch außerhalb der EU verarbeitet und gespeichert werden können. Q1: Datenschutzinformationen. Die Survey-Seite enthielt ausführliche Datenschutzinfor- mationen gemäß Art. 13 DSGVO. In...
-
[9]
Gespräch via Text-Chat,
-
[10]
Beim Text-Chat werden Sie Ihre Antworten über die Tastatur eingeben
Gespräch via Sprachein- und Sprachausgabe. Beim Text-Chat werden Sie Ihre Antworten über die Tastatur eingeben. Das Gespräch via Sprachein- und Sprachausgabe nutzt Mikrofon sowie Lautsprecher/Kopfhörer. Je nach Auswahl wurde anschließend die entsprechende Text- oder Voice-Oberfläche mit demselben Instruktionstext wie in den direkt zugewiesenen Bedingungen...
-
[11]
dem Gesprächspartner Antworten geben,
-
[12]
problems_txt
vom Gesprächspartner Fragen erhalten. problems_txt. Nur für Befragte mit kleinen oder großen Problemen: Welche Probleme sind während Ihres KI-gestützten Gesprächs aufgetreten? Nennen Sie bitte alle Probleme. Q91. Hat sich der KI-Interviewer während des Gesprächs in irgendeiner Weise anstößig, ver- letzend oder in anderer Weise grob unangemessen geäußert?
-
[13]
Falls “Ja” bei Q91: Hinweis auf die Möglichkeit der Kontaktaufnahme mit Prof
Ja, und zwar folgende Äußerung: Q94. Falls “Ja” bei Q91: Hinweis auf die Möglichkeit der Kontaktaufnahme mit Prof. Dr. Alexander Wuttke. ai-accuracy . Manchmal traut man sich in einem Interview nicht frei zu sagen, was man eigentlich denkt. Inwiefern reflektieren Ihre Äußerungen gegenüber dem KI-Gesprächspartner Ihre ehrlichen Gedanken, Gefühle und Erfahr...
-
[14]
Sollte häufiger eingesetzt werden
-
[15]
Im Folgenden möchten wir noch einmal mehr über Ihre politischen Ansichten erfahren
Sollte nicht häufiger eingesetzt werden B.8 Block: GLES Q45. Im Folgenden möchten wir noch einmal mehr über Ihre politischen Ansichten erfahren. q42. Parteipositionen zum Zuzug von Ausländern. Matrix für CDU/CSU, SPD, Bündnis 90/Die Grünen, Die Linke und AfD auf einer 11-Punkte-Skala von Zuzug von Ausländern erleichtern bis Zuzug von Ausländern einschränk...
-
[16]
Minderheiten sollten sich den deutschen Gepflogenheiten anpassen
-
[17]
Der Wille der Mehrheit sollte immer Vorrang haben, auch wenn Minderheitenrechte betrof- fen sind
-
[18]
Einwanderinnen/Einwanderer sind im Allgemeinen gut für die deutsche Wirtschaft
-
[19]
Die deutsche Kultur ist durch Einwanderinnen/Einwanderer bedroht
-
[20]
wirklich deutsch
Einwanderinnen/Einwanderer erhöhen die Kriminalitätsrate in Deutschland. q75. Parteiidentifikation: SPD, CDU/CSU, CDU, CSU, Grüne, FDP, AfD, Die Linke, BSW, andere Partei (offene Nennung) oder keiner Partei . 38 q126. Wichtigkeit verschiedener Kriterien, um “wirklich deutsch” zu sein:
-
[21]
in Deutschland geboren sein,
-
[22]
deutsche Vorfahren haben,
-
[23]
deutsch sprechen können,
-
[24]
Vierstufige Skala von überhaupt nicht wichtig bis sehr wichtig
sich an deutsche Traditionen und Gepflogenheiten halten. Vierstufige Skala von überhaupt nicht wichtig bis sehr wichtig . q27a. Einwanderinnen/Einwanderer sollten verpflichtet werden, sich der deutschen Kultur anzupassen. Fünfstufige Zustimmungsskala. q166. Matrix zu autoritären, nationalistischen und fremdenfeindlichen Aussagen mit fünfstu- figer Zustimm...
-
[25]
Was Deutschland jetzt braucht, ist eine einzige starke Partei, die die Volksgemeinschaft insgesamt verkörpert
-
[26]
Wir sollten endlich wieder Mut zu einem starken Nationalgefühl haben
-
[27]
Die Bundesrepublik ist durch die vielen Ausländer in einem gefährlichen Maß überfremdet
-
[28]
Auch heute noch ist der Einfluss von Jüdinnen/Juden zu groß
-
[29]
Wie in der Natur sollte sich in der Gesellschaft immer der Stärkere durchsetzen
-
[30]
B.9 Block: End comparison
Die Verbrechen des Nationalsozialismus sind in der Geschichtsschreibung weit übertrieben worden. B.9 Block: End comparison. Vergleich zwischen KI-Gespräch und standardisiertem Fragebogen auf fünf Di- mensionen mit den Antwortoptionen KI-gestütztes Gespräch , Standardisierter Fragebogen, Kei- ne Präferenz :
-
[31]
ich habe mehr meine individuelle Meinung ausdrücken können,
-
[32]
Wir führen ein Gespräch über Politik und Gesellschaft, mit besonderem Fokus auf Migrationsthemen
bevorzuge ich für zukünftige Interviews. survey_evaluation. Gesamtbewertung des klassischen Fragebogens auf einer 7-Punkte-Skala von sehr schlecht bis sehr gut . survey-accuracy . Inwiefern reflektieren die Äußerungen im klassischen Fragebogen die ehrli- chen Gedanken, Gefühle und Erfahrungen? Skala von 1 = völlig bis 8 = überhaupt nicht . device. Gerätet...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.