Valuing Winners: When and How to Correct for Selection Bias in Randomized Experiments
Pith reviewed 2026-05-20 14:19 UTC · model grok-4.3
The pith
Different methods for correcting winner's curse bias in randomized experiments perform best under different conditions, with no approach dominating all evaluation targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
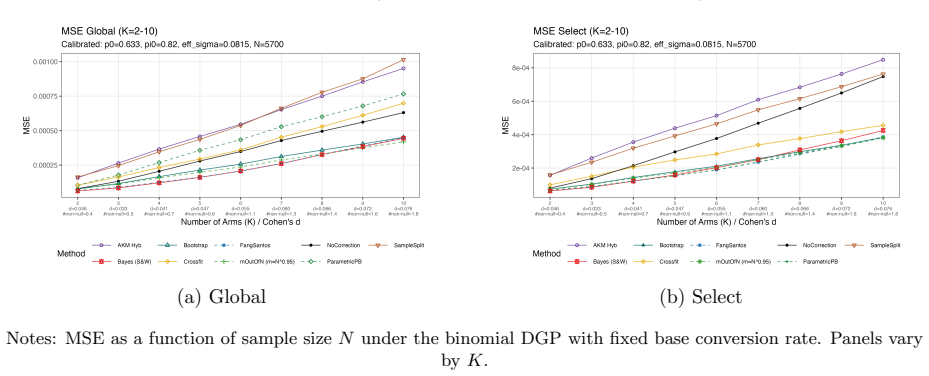
The paper establishes that bias-correction methods for the winner's curse must be chosen to match the manager's objective, because performance rankings shift with effect sizes and across the seven decision-relevant metrics of mean bias, mean squared error, and confidence-interval coverage for global and selective bias plus mean regret. Simulations demonstrate that the plug-in estimator yields the lowest errors when treatment differences are large, cross-fitting performs best when treatments are similar, resampling methods achieve low mean squared error for moderate differences, and the introduced adaptive empirical likelihood procedure supplies asymptotically valid confidence intervals in a
What carries the argument
The distinction between global winner's curse (bias relative to the true best treatment) and selective winner's curse (bias relative to the selected treatment's true mean), which connects selection to regret from choosing a suboptimal arm and defines the seven evaluation targets used to compare correction methods.
If this is right
- Decision-makers facing large treatment differences can use simple plug-in estimators without substantial loss in accuracy for valuing the winner.
- When treatment arms produce similar outcomes, cross-fitting corrections reduce both global and selective bias more reliably than alternatives.
- Resampling-based corrections minimize mean squared error when effect sizes are moderate, supporting more precise regret calculations.
- The adaptive empirical likelihood procedure allows construction of valid intervals without choosing tuning parameters that resampling methods require.
Where Pith is reading between the lines
- Platforms running repeated A/B tests could monitor observed effect sizes in real time and switch correction methods automatically to reduce cumulative regret.
- The global-versus-selective distinction may extend to non-randomized selection problems such as ranking products from noisy sales data.
- Sequential experiments that add arms over time would likely introduce additional forms of selection bias not covered by the current static framework.
Load-bearing premise
The performance rankings and the asymptotic validity of the adaptive empirical likelihood procedure depend on the specific simulation designs and data-generating processes calibrated to an online A/B testing platform.
What would settle it
A field experiment with known true treatment means in which the adaptive empirical likelihood confidence intervals fail to achieve the nominal coverage rate would refute the claim of asymptotic validity across settings.
Figures





read the original abstract
Decision-makers often deploy the best-performing treatment from a randomized experiment, creating a winner's curse: selection favors treatments whose observed outcomes are high partly because of statistical noise, so the na\"ive estimate of the winner is upward biased. We distinguish two forms of winner's curse, bias relative to the true best treatment (global) and bias relative to the selected treatment's true mean (selective), and link them to regret from deploying a suboptimal treatment. This framework defines seven decision-relevant evaluation targets: mean bias, mean squared error, and confidence interval coverage for the global and selective winner's curse, and mean regret. We then show that methods that perform well on one target can perform poorly on others, so corrections should be matched to the manager's objective. Across simulations with varying effect sizes, multiple-arm settings, and data calibrated to an online A/B testing platform, no method dominates uniformly: the plug-in estimator performs best when treatment differences are large, cross-fitting performs best when treatments are similar, and resampling methods often achieve low mean squared error for moderate differences. We also introduce an adaptive empirical likelihood procedure that delivers asymptotically valid confidence intervals across settings without the tuning sensitivity of resampling-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines selection bias (winner's curse) when deploying the best-performing arm from a randomized experiment. It distinguishes global bias (relative to the true best treatment) from selective bias (relative to the selected arm's true mean), links both to regret, and defines seven decision-relevant targets: mean bias, MSE, and CI coverage for each bias type plus mean regret. Simulations across effect-size regimes, arm counts, and A/B-platform-calibrated data show that no correction method dominates uniformly; the plug-in estimator excels for large treatment differences, cross-fitting for similar arms, and resampling for moderate differences. The authors introduce an adaptive empirical likelihood procedure claimed to deliver asymptotically valid confidence intervals without the tuning sensitivity of resampling methods.
Significance. If the simulation-based performance rankings and the asymptotic validity of the adaptive EL procedure hold beyond the specific DGPs, the paper supplies actionable guidance for experimenters on matching bias-correction tools to managerial objectives (bias vs. regret vs. coverage) and offers a tuning-robust inference method. The explicit mapping from bias measures to regret and the multi-target evaluation framework are useful contributions to the econometrics of selection in experiments.
major comments (2)
- [Simulation section (and abstract)] The central performance-ordering claim (plug-in best for large differences, cross-fitting for similar arms, resampling for moderate) and the asymptotic-validity claim for adaptive EL both rest on simulation designs calibrated to one online A/B platform with particular effect-size distributions and arm-independence assumptions (see abstract and the simulation section). These are not generic; if the true effect-size law or dependence structure differs, both the 'match method to objective' recommendation and the 'valid across settings without tuning' claim can fail while the formal definitions of the seven targets remain intact. Full details of the DGP, including the distribution from which arm effects are drawn and any cross-arm correlation structure, are required to assess external validity.
- [Asymptotic procedure / adaptive EL section] The manuscript reports simulation results showing method performance varies by setting and introduces an asymptotic procedure for the adaptive EL, but without full derivations, explicit verification of coverage properties, or sensitivity checks to the independence and effect-size assumptions, the soundness of the asymptotic-validity claim receives only moderate support. A formal proof sketch or at least the key steps establishing asymptotic coverage under the paper's maintained conditions would strengthen the contribution.
minor comments (2)
- [Section 2 or 3] Clarify the exact definition of the seven targets in a single table or numbered list early in the paper so that later simulation results can be directly mapped to each target.
- [Simulation design subsection] Provide more detail on how the A/B-platform data are calibrated (sample sizes, variance estimates, number of arms) so readers can judge how representative the simulation designs are.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and robustness of our paper. We address each of the major comments in turn below.
read point-by-point responses
-
Referee: [Simulation section (and abstract)] The central performance-ordering claim (plug-in best for large differences, cross-fitting for similar arms, resampling for moderate) and the asymptotic-validity claim for adaptive EL both rest on simulation designs calibrated to one online A/B platform with particular effect-size distributions and arm-independence assumptions (see abstract and the simulation section). These are not generic; if the true effect-size law or dependence structure differs, both the 'match method to objective' recommendation and the 'valid across settings without tuning' claim can fail while the formal definitions of the seven targets remain intact. Full details of the DGP, including the distribution from which arm effects are drawn and any cross-arm correlation structure, are required to assess external validity.
Authors: We agree that providing full details of the data-generating process (DGP) is essential for evaluating the external validity of our simulation results. In the revised manuscript, we will include a complete description of the DGP, specifying the distribution from which arm effects are drawn and the cross-arm correlation structure (which is assumed to be zero under independence). While our simulations are calibrated to realistic A/B testing scenarios, we acknowledge that the performance rankings may vary under different effect-size distributions or dependence structures. We will add a discussion of these limitations and emphasize that the recommendations are conditional on the settings considered. The multi-target framework itself remains general and independent of specific DGPs. revision: yes
-
Referee: [Asymptotic procedure / adaptive EL section] The manuscript reports simulation results showing method performance varies by setting and introduces an asymptotic procedure for the adaptive EL, but without full derivations, explicit verification of coverage properties, or sensitivity checks to the independence and effect-size assumptions, the soundness of the asymptotic-validity claim receives only moderate support. A formal proof sketch or at least the key steps establishing asymptotic coverage under the paper's maintained conditions would strengthen the contribution.
Authors: We appreciate this suggestion. The current version relies primarily on simulation evidence for the adaptive empirical likelihood (EL) procedure. In the revision, we will provide a formal proof sketch outlining the key steps for establishing asymptotic coverage under the maintained assumptions of arm independence and the specified effect-size distributions. Additionally, we will include sensitivity analyses to assess robustness to violations of these assumptions. This will strengthen the support for the asymptotic validity claim. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper links bias measures to regret and defines seven evaluation targets using standard statistical definitions rather than by construction from fitted quantities. Performance rankings across methods are obtained from explicit simulations under varying effect sizes and A/B-platform-calibrated DGPs, while the adaptive empirical likelihood procedure is introduced as an independent statistical contribution with asymptotic validity claims. No load-bearing step reduces to a self-citation chain, a renamed known result, or an input parameter presented as a prediction; the framework remains self-contained against external simulation benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard regularity conditions for asymptotic validity of empirical likelihood estimators
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We distinguish two forms of winner’s curse, bias relative to the true best treatment (global) and bias relative to the selected treatment’s true mean (selective), and link them to regret... We also introduce an adaptive empirical likelihood procedure that delivers asymptotically valid confidence intervals
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the maximum function is convex... standard approaches that rely on the Delta method will fail at the kink
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Review of Economic Studies , volume =
Inference on Directionally Differentiable Functions , author =. The Review of Economic Studies , volume =. 2019 , publisher =
work page 2019
- [2]
-
[3]
Journal of Econometrics , volume =
The Numerical Delta Method , author =. Journal of Econometrics , volume =. 2018 , publisher =
work page 2018
-
[4]
When Does Bootstrap Work?: Asymptotic Results and Simulations , author=. 1992 , publisher=
work page 1992
- [5]
-
[6]
Smith, James E. and Winkler, Robert L. , title =. Management Science , volume =. 2006 , doi =. https://doi.org/10.1287/mnsc.1050.0451 , abstract =
-
[7]
SSRN Electronic Journal , year =
The Winner's Curse in Data-Driven Decision Making: Evidence and Solutions , author =. SSRN Electronic Journal , year =. doi:10.2139/ssrn.5930537 , url =
-
[8]
arXiv preprint arXiv:2510.18161 , year=
Beating the Winner's Curse via Inference-Aware Policy Optimization , author=. arXiv preprint arXiv:2510.18161 , year=
-
[9]
The Quarterly Journal of Economics , volume=
Inference on winners , author=. The Quarterly Journal of Economics , volume=. 2024 , publisher=
work page 2024
-
[10]
challenger experiments , author=
Efficiently evaluating targeting policies: Improving on champion vs. challenger experiments , author=. Management Science , volume=. 2020 , publisher=
work page 2020
-
[11]
Inconsistency of the Bootstrap When a Parameter is on the Boundary of the Parameter Space , author=. Econometrica , volume=. 2000 , publisher=
work page 2000
-
[12]
Journal of Multivariate Analysis , volume=
Local asymptotic minimax estimation of nonregular parameters with translation-scale equivariant maps , author=. Journal of Multivariate Analysis , volume=. 2014 , publisher=
work page 2014
-
[13]
Annual Review of Statistics and Its Application , author =
Kuchibhotla, Arun K. and Kolassa, John E. and Kuffner, Todd A. Post-Selection Inference. Annual Review of Statistics and Its Application. 2022. doi:https://doi.org/10.1146/annurev-statistics-100421-044639
-
[14]
The Annals of Statistics , volume =
Large Sample Confidence Regions Based on Subsamples under Minimal Assumptions , author =. The Annals of Statistics , volume =. 1994 , month =
work page 1994
-
[15]
Asymptotic Normality for Chi-Bar-Square Distributions , volume =
Richard Dykstra , journal =. Asymptotic Normality for Chi-Bar-Square Distributions , volume =
-
[16]
Feit, Elea McDonnell and Berman, Ron , title =. Marketing Science , volume =. 2019 , doi =. https://doi.org/10.1287/mksc.2019.1194 , abstract =
-
[17]
Journal of the American Statistical Association , volume=
Steven G. Self and Kung-Yee Liang , title =. Journal of the American Statistical Association , volume =. 1987 , publisher =. doi:10.1080/01621459.1987.10478472 , URL =
-
[18]
The Winner's Curse: Behavioral Economics Anomalies, Then and Now , author=. 2025 , publisher=
work page 2025
-
[19]
Selecting the Best Arm in One-Shot Multi-Arm RCTs: The Asymptotic Minimax-Regret Decision Framework for the Best-Population Selection Problem , author =. 2025 , eprint =
work page 2025
-
[20]
Joo, Joonhwi and Chiong, Khai X. , title =. Management Science , volume =. 2025 , doi =. https://doi.org/10.1287/mnsc.2024.06590 , abstract =
-
[21]
Megastudies improve the impact of applied behavioural science , author=. Nature , volume=. 2021 , publisher=
work page 2021
-
[22]
Advances in Neural Information Processing Systems , volume=
Non-stationary experimental design under linear trends , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Regret in decision making under uncertainty , author=. Operations research , volume=. 1982 , publisher=
work page 1982
-
[24]
Berman, Ron and Van den Bulte, Christophe , title =. Management Science , volume =. 2022 , doi =. https://doi.org/10.1287/mnsc.2021.4207 , abstract =
- [25]
-
[26]
Mogstad, Magne and Romano, Joseph P. and Shaikh, Azeem M. and Wilhelm, Daniel , title =. The Review of Economic Studies , year =
-
[27]
Gu, Jiaying and Koenker, Roger , title =. Econometrica , volume =. doi:https://doi.org/10.3982/ECTA19304 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.3982/ECTA19304 , abstract =
-
[28]
Milkman, Katherine L and Ellis, Sean F and Gromet, Dena M and DeMay, Isabella M and Graci, Heather N and Jung, Youngwoo and Mobarak, Rayyan S and Silvera Zumaran, Ramon A and Simmons, Mia N and Van den Bulte, Christophe and Benartzi, Shlomo and Hilchey, Matthew and Goodyear, Laura and Karlan, Dean and Mazar, Nina and Mochon, Daniel and Shah, Avni M and So...
-
[29]
Milkman, Katherine L. and Ellis, Sean F. and Gromet, Dena M. and Jung, Youngwoo and Luscher, Alex S. and Mobarak, Rayyan S. and Paxson, Madeline K. and Silvera Zumaran, Ramon A. and Kuan, Robert and Berman, Ron and Lewis, Neil A. and List, John A. and Patel, Mitesh S. and Van den Bulte, Christophe and Volpp, Kevin G. and Beauvais, Maryann V. and Bellows, ...
-
[30]
James, W. and Stein, C. , title =. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability , volume =. 1961 , publisher =
work page 1961
-
[31]
Efron, B. and Morris, C. , title =. Journal of the American Statistical Association , volume =. 1973 , doi =
work page 1973
-
[32]
Impossibility Results for Nondifferentiable Functionals , author=. Econometrica , volume=. 2012 , publisher=
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.