Sparse Sensor Placement in Multi-Agent Reinforcement Learning Control of Rayleigh-B\'enard Convection
Pith reviewed 2026-06-30 03:54 UTC · model grok-4.3
The pith
Sparse apprentice policies distilled from dense multi-agent RL experts achieve comparable control of Rayleigh-Bénard convection at maximal or near-maximal sparsity levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
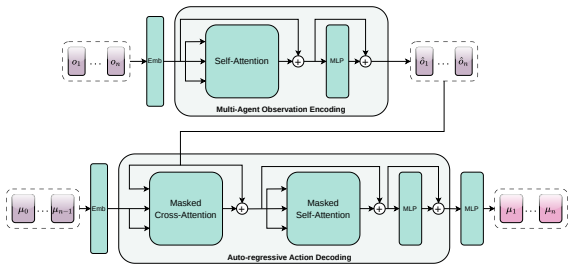
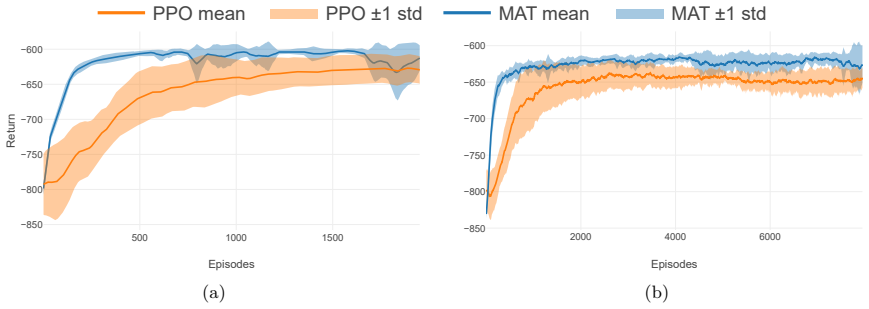
Dense expert policies are trained with windowed observations in a multi-agent RL setting for Rayleigh-Bénard convection control; these are then distilled into sparse apprentice policies via supervised learning that applies grouped regularization to the encoder input weights. The distillation uses a grouping construction to enforce consistent pruning across overlapping windows together with ordered non-convex grouped regularization and iterative reweighted grouped regularization. Multi-agent transformer policies prove more stable to train than PPO baselines, and the resulting sparse apprentices retain control behavior comparable to the dense experts across both fixed and varying initial-condi
What carries the argument
Grouped regularization applied to encoder input weights, with a construction that enforces consistent pruning decisions across overlapping observation windows, combined with ordered non-convex and iterative reweighted grouped regularization.
If this is right
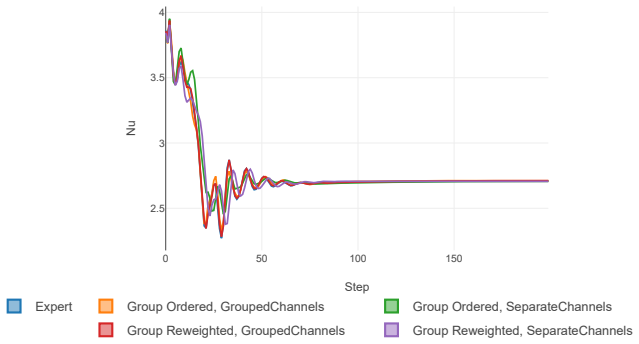
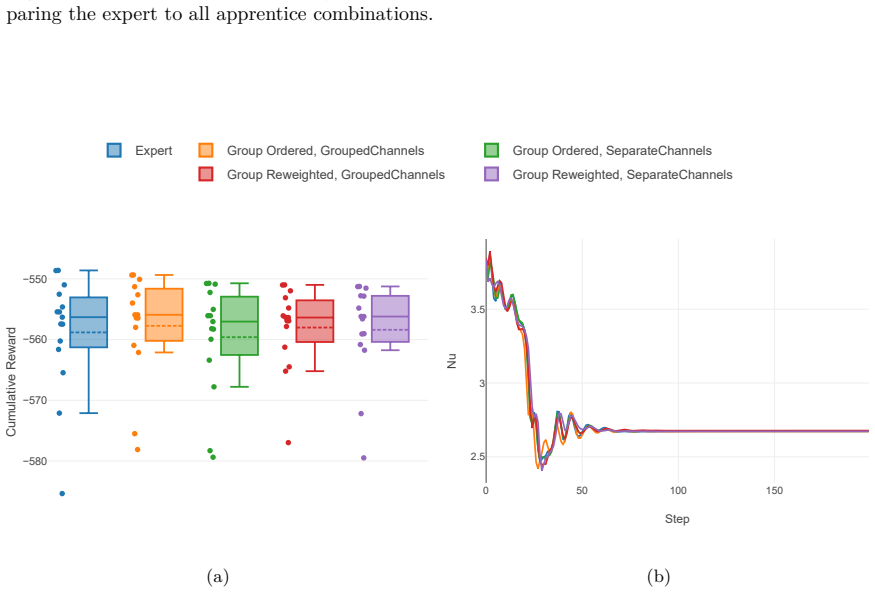
- Sparse apprentices retain control behavior comparable to dense experts across the tested settings.
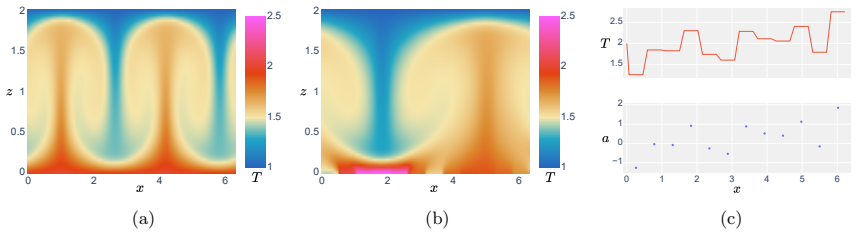
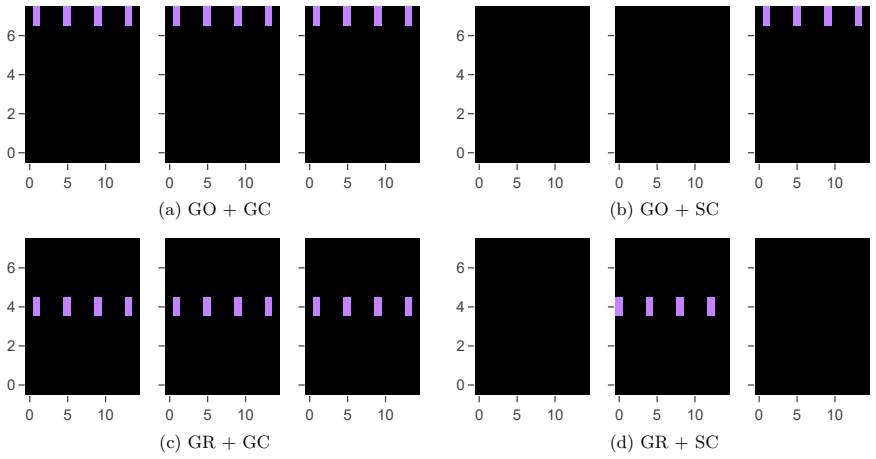
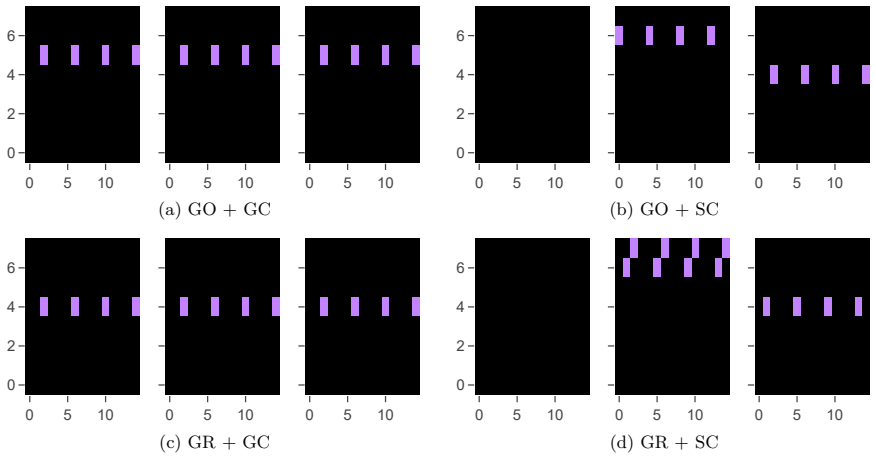
- Maximal sparsity is reached in all fixed-initial-condition variants and maximal or near-maximal sparsity in varying-initial-condition variants.
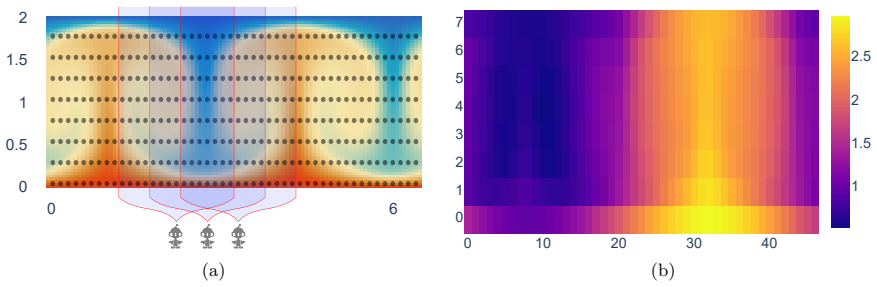
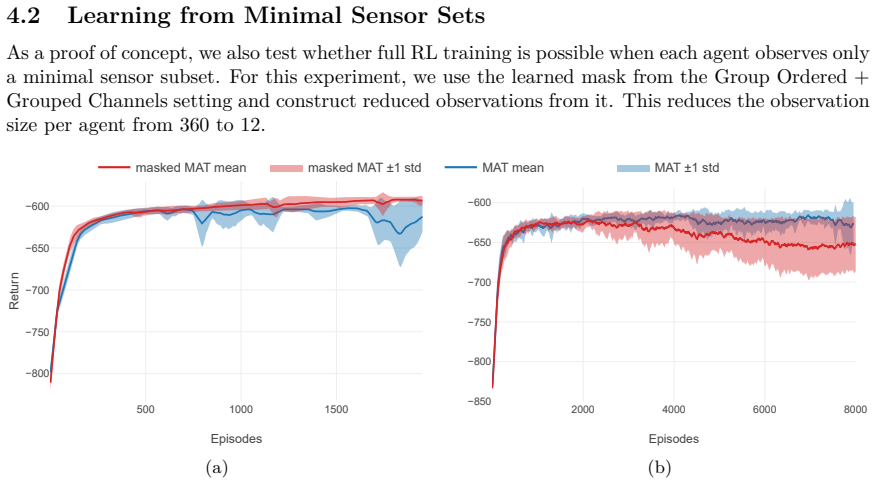
- Training from the learned minimal sensor sets reduces per-agent observation size from 360 to 12 while preserving the overall training trend and lowering data throughput.
- Multi-agent transformer policies train more stably than proximal policy optimization baselines.
Where Pith is reading between the lines
- The identified control-relevant spatial regions and state components could guide sensor placement decisions in other spatially distributed fluid or chaotic systems.
- The large reduction in required observations suggests the method may scale to higher-resolution simulations or physical hardware with strict bandwidth limits.
- The consistent pruning across sliding windows may extend to other reinforcement learning tasks that use overlapping temporal or spatial observation buffers.
Load-bearing premise
The grouping construction that enforces consistent pruning across overlapping observation windows, combined with ordered non-convex and iterative reweighted grouped regularization, preserves sufficient control-relevant information during distillation from dense to sparse policies.
What would settle it
A direct side-by-side simulation run in which a sparse apprentice policy produces measurably larger deviations in the controlled temperature or velocity fields than its dense expert counterpart under identical initial conditions and actuation limits would falsify the claim of retained control behavior.
Figures

read the original abstract
This paper studies sparse sensor placement for control of Rayleigh-B\'enard convection with multi-agent reinforcement learning. We train dense expert policies with windowed observations and distill sparse apprentice policies by supervised learning with grouped regularization on encoder input weights. The framework combines ordered non-convex grouped regularization and iterative reweighted grouped regularization, and uses a grouping construction that enforces consistent pruning across overlapping observation windows. Experiments with fixed and varying initial conditions show that Multi-Agent Transformer policies train more stably than proximal policy optimization baselines, while sparse apprentices retain control behavior comparable to dense experts. Sparsity results are strong for the proposed grouped methods across settings, including maximal sparsity in all fixed-initial-condition setting variants and maximal or near-maximal sparsity in varying-initial-condition setting variants. As an additional proof of concept, training from learned minimal sensor sets reduces per-agent observation size from 360 to 12 and preserves the overall training trend in simulation while reducing data throughput. The results provide both an interpretable basis for identifying control-relevant spatial regions and state components, and a practical pathway toward sensor-efficient control under realistic hardware constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a sparse sensor placement framework for multi-agent RL control of Rayleigh-Bénard convection. Dense expert policies are trained on windowed observations and distilled into sparse apprentice policies via supervised learning that applies ordered non-convex grouped regularization combined with iterative reweighted grouped regularization; a grouping construction enforces consistent pruning across overlapping windows. Experiments in fixed- and varying-initial-condition regimes show that Multi-Agent Transformer policies train more stably than PPO baselines, that sparse apprentices retain comparable closed-loop control behavior, and that the grouped methods achieve maximal or near-maximal sparsity; a proof-of-concept further reduces per-agent observation size from 360 to 12 while preserving training trends.
Significance. If the quantitative results hold, the work supplies both an interpretable method for identifying control-relevant spatial regions and state components and a practical route to sensor-efficient MARL policies under hardware constraints. The grouped-regularization construction that maintains consistency across time windows, together with explicit ablations of the non-convex and reweighted penalties, constitutes a clear technical contribution; the stability advantage of MAT over PPO in this fluid-control setting is also of interest to the community.
minor comments (2)
- [Abstract] Abstract: the claims of 'comparable performance' and 'maximal sparsity' are stated without any numerical values, error metrics, or baseline comparisons; including at least one quantitative summary statistic per setting would make the abstract self-contained.
- The manuscript would benefit from an explicit statement of the precise performance metric (e.g., Nusselt-number deviation or integrated control cost) used to declare 'comparable behavior' in the results tables.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The feedback affirms the technical contributions of the grouped regularization approach and the stability observations for Multi-Agent Transformer policies. Since no specific major comments or requested changes were provided in the report, we have no point-by-point revisions to address at this stage.
Circularity Check
No significant circularity
full rationale
The manuscript describes an empirical pipeline: dense expert policies are trained on windowed observations, then sparse apprentices are obtained via supervised distillation with grouped regularization on encoder weights. Sparsity and closed-loop performance are reported as experimental outcomes across fixed- and varying-initial-condition regimes, supported by ablations of the regularization scheme. No load-bearing step reduces by the paper's own equations or self-citation to a fitted quantity or definitional identity; the grouping construction and regularization are methodological choices whose effectiveness is evaluated externally against control metrics. The derivation chain is therefore self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A review on sparse solutions in optimal control of partial differential equations
Eduardo Casas. A review on sparse solutions in optimal control of partial differential equations. SeMA Journal, 74, 04 2017. doi: 10.1007/s40324-017-0121-5
-
[2]
B. W. Brunton, S. L. Brunton, J. L. Proctor, and J. N. Kutz. Sparse sensor placement opti- mization for classification.SIAM Journal on Applied Mathematics, 76(5):2099–2122, 2016. doi: 10.1137/15M1036713. URLhttps://doi.org/10.1137/15M1036713
-
[3]
Krithika Manohar, Bingni W. Brunton, J. Nathan Kutz, and Steven L. Brunton. Data-Driven Sparse Sensor Placement for Reconstruction: Demonstrating the Benefits of Exploiting Known Patterns.IEEE Control Systems, 38(3):63–86, January 2018. doi: 10.1109/MCS.2018.2810460
-
[4]
Thomas Duriez, Steven L. Brunton, and Bernd R. Noack.Taming Nonlinear Dynamics with MLC, pages 93–120. Springer International Publishing, Cham, 2017. ISBN 978-3-319-40624-4. doi: 10.1007/978-3-319-40624-4_5. URLhttps://doi.org/10.1007/978-3-319-40624-4_5
-
[5]
M. A. Bucci, O. Semeraro, A. Allauzen, G. Wisniewski, L. Cordier, and L. Mathelin. Control of chaotic systems by deep reinforcement learning.Proceedings of the Royal Society A: Mathe- matical, Physical and Engineering Sciences, 475(2231):20190351, 11 2019. ISSN 1364-5021. doi: 10.1098/rspa.2019.0351. URLhttps://doi.org/10.1098/rspa.2019.0351
-
[6]
Jean Rabault, Miroslav Kuchta, Atle Jensen, Ulysse Réglade, and Nicolas Cerardi. Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control.Journal of Fluid Mechanics, 865:281–302, February 2019. ISSN 1469-7645. doi: 10.1017/jfm.2019.62. URLhttp://dx.doi.org/10.1017/jfm.2019.62
-
[7]
Max Weissenbacher, Anastasia Borovykh, and Georgios Rigas. Reinforcement learning of chaoticsystemscontrolinpartiallyobservableenvironments.Flow, Turbulence and Combustion, 115:1357–1378, 01 2025. doi: 10.1007/s10494-024-00632-5
-
[8]
Brunton, and Kunihiko Taira
Sebastian Peitz, Jan Stenner, Vikas Chidananda, Oliver Wallscheid, Steven L. Brunton, and Kunihiko Taira. Distributed control of partial differential equations using convolutional rein- forcement learning, 2024. ISSN 0167-2789. URLhttps://www.sciencedirect.com/science/ article/pii/S0167278924000472
2024
-
[9]
Colin Vignon, Jean Rabault, Joel Vasanth, Francisco Alcántara-Ávila, Mikael Mortensen, and Ricardo Vinuesa. Effective control of two-dimensional rayleigh–bénard convection: Invariant multi-agent reinforcement learning is all you need.Physics of Fluids, 35(6):065146, 06 2023. ISSN 1070-6631. doi: 10.1063/5.0153181. URLhttps://doi.org/10.1063/5.0153181
-
[10]
JoongooJeon, JeanRabault, JoelVasanth, FranciscoAlcántara-Ávila, ShilajBaral, andRicardo Vinuesa. Advanced deep-reinforcement-learning methods for flow control: group-invariant and positional-encoding networks improve learning speed and quality, 2024. URLhttps://arxiv. org/abs/2407.17822
-
[11]
ThorbenMarkmann, MichielStraat, SebastianPeitz, andBarbaraHammer. Controlofrayleigh- bénard convection: Effectiveness of reinforcement learning in the turbulent regime, 2025. URL https://arxiv.org/abs/2504.12000
-
[12]
Song Han, Huizi Mao, and William J. Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding, 2016. URLhttps://arxiv. org/abs/1510.00149. 17
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[13]
In value-based deep reinforcement learning, a pruned network is a good network, 21–27 Jul 2024
Johan Samir Obando Ceron, Aaron Courville, and Pablo Samuel Castro. In value-based deep reinforcement learning, a pruned network is a good network, 21–27 Jul 2024. URLhttps: //proceedings.mlr.press/v235/obando-ceron24a.html
2024
-
[14]
Christos Louizos, Max Welling, and Diederik P. Kingma. Learning sparse neural networks throughL 0 regularization. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=H1Y8hhg0b
2018
-
[15]
Nicolò Botteghi and Urban Fasel. Parametric pde control with deep reinforcement learning and differentiableL 0-sparse polynomial policies, 2024. URLhttps://arxiv.org/abs/2403.15267
-
[16]
Representational similarity learning with application to brain networks
Urvashi Oswal, Christopher Cox, Matthew Lambon-Ralph, Timothy Rogers, and Robert Nowak. Representational similarity learning with application to brain networks. In Maria Flo- rina Balcan and Kilian Q. Weinberger, editors,Proceedings of The 33rd International Con- ference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1041...
2016
-
[17]
Learning to share: Simul- taneous parameter tying and sparsification in deep learning
Dejiao Zhang, Haozhu Wang, Mario Figueiredo, and Laura Balzano. Learning to share: Simul- taneous parameter tying and sparsification in deep learning. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=rypT3fb0b
2018
- [18]
-
[19]
A reduction of imitation learning and structured prediction to no-regret online learning
Stephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. In Geoffrey Gordon, David Dunson, and Miroslav Dudík, editors,Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pag...
2011
-
[20]
Andrei A. Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, Volodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy distillation, 2016. URLhttps://arxiv.org/abs/1511.06295
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
Progressive reinforce- ment learning with distillation for multi-skilled motion control
Glen Berseth, Cheng Xie, Paul Cernek, and Michiel Van de Panne. Progressive reinforce- ment learning with distillation for multi-skilled motion control. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=B13njo1R-
2018
-
[22]
Dor Livne and Kobi Cohen. Pops: Policy pruning and shrinking for deep reinforcement learn- ing.IEEE Journal of Selected Topics in Signal Processing, 14(4):789–801, May 2020. ISSN 1941-0484. doi: 10.1109/jstsp.2020.2967566. URLhttp://dx.doi.org/10.1109/JSTSP.2020. 2967566
-
[23]
Multi-agent reinforcement learning is a sequence modeling problem
Muning Wen, Jakub Grudzien Kuba, Runji Lin, Weinan Zhang, Ying Wen, Jun Wang, and Yaodong Yang. Multi-agent reinforcement learning is a sequence modeling problem. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural In- formation Processing Systems, 2022. URLhttps://openreview.net/forum?id=1W8UwXAQubL
2022
-
[24]
Candès, Michael B
Emmanuel J. Candès, Michael B. Wakin, and Stephen P. Boyd. Enhancing sparsity by reweightedℓ1 minimization, October 2008. ISSN 1531-5851. URLhttp://dx.doi.org/10. 1007/s00041-008-9045-x. 18
2008
-
[25]
Plug-and-Play Benchmarking of Reinforcement Learning Algorithms for Large-Scale Flow Control
Jannis Becktepe, Aleksandra Franz, Nils Thuerey, and Sebastian Peitz. Plug-and-play bench- marking of reinforcement learning algorithms for large-scale flow control, 2026. URLhttps: //arxiv.org/abs/2601.15015
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. The MIT Press, second edition, 2018. URLhttp://incompleteideas.net/book/the-book-2nd.html
2018
-
[27]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.CoRR, abs/1707.06347, 2017. URLhttp://arxiv.org/abs/ 1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Matthijs T. J. Spaan.Partially Observable Markov Decision Processes, pages 387–414. Springer Berlin Heidelberg, Berlin, Heidelberg, 2012. ISBN 978-3-642-27645-3. doi: 10.1007/ 978-3-642-27645-3_12. URLhttps://doi.org/10.1007/978-3-642-27645-3_12
-
[29]
Springer Berlin Heidelberg, Berlin, Heidelberg, 2010
Lucian Buşoniu, Robert Babuška, and Bart De Schutter.Multi-agent Reinforcement Learning: An Overview, pages 183–221. Springer Berlin Heidelberg, Berlin, Heidelberg, 2010. ISBN 978-3-642-14435-6. doi: 10.1007/978-3-642-14435-6_7. URLhttps://doi.org/10.1007/ 978-3-642-14435-6_7
-
[30]
Ordered weighted l1 regularized regression with strongly correlated covariates: Theoretical aspects
Mario Figueiredo and Robert Nowak. Ordered weighted l1 regularized regression with strongly correlated covariates: Theoretical aspects. In Arthur Gretton and Christian C. Robert, editors, Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, vol- ume 51 ofProceedings of Machine Learning Research, pages 930–938, Cadiz,...
-
[31]
URLhttps://proceedings.mlr.press/v51/figueiredo16.html
PMLR. URLhttps://proceedings.mlr.press/v51/figueiredo16.html
-
[32]
Xiangrong Zeng and Mário A. T. Figueiredo. The ordered weightedℓ1 norm: Atomic formula- tion, projections, and algorithms, 2015. URLhttps://arxiv.org/abs/1409.4271
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
Nonconvex sortedℓ1 minimization for sparse ap- proximation.Journal of the Operations Research Society of China, 3(2):207–229, February
Xiao-Lin Huang, Lei Shi, and Ming Yan. Nonconvex sortedℓ1 minimization for sparse ap- proximation.Journal of the Operations Research Society of China, 3(2):207–229, February
-
[34]
doi: 10.1007/s40305-014-0069-4
ISSN 2194-6698. doi: 10.1007/s40305-014-0069-4. URLhttp://dx.doi.org/10.1007/ s40305-014-0069-4
-
[35]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URLhttps://arxiv. org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Simone Silvestri, Gregory L. Wagner, Christopher Hill, Matin Raayai Ardakani, Johannes Blaschke, Jean-Michel Campin, Valentin Churavy, Navid C. Constantinou, Alan Edelman, John Marshall, Ali Ramadhan, Andre Souza, and Raffaele Ferrari. Oceananigans.jl: A julia library that achieves breakthrough resolution, memory and energy efficiency in global ocean simu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.