Mind Companion: An Embodied Conversational Agent for Process-Based Psychotherapy
Pith reviewed 2026-06-26 23:05 UTC · model grok-4.3
The pith
An LLM-based embodied agent for process-based psychotherapy generates responses rated higher than human therapists on understanding, effectiveness, collaboration, and alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
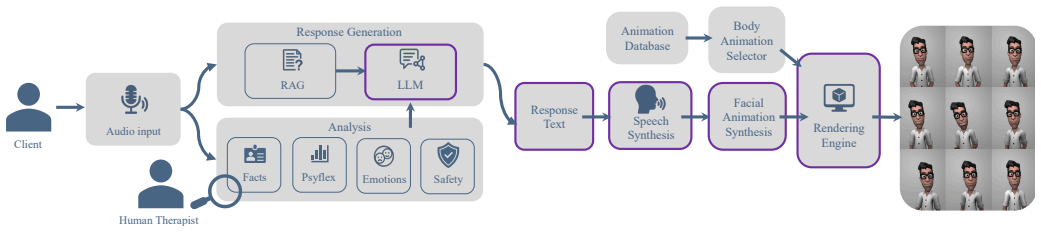
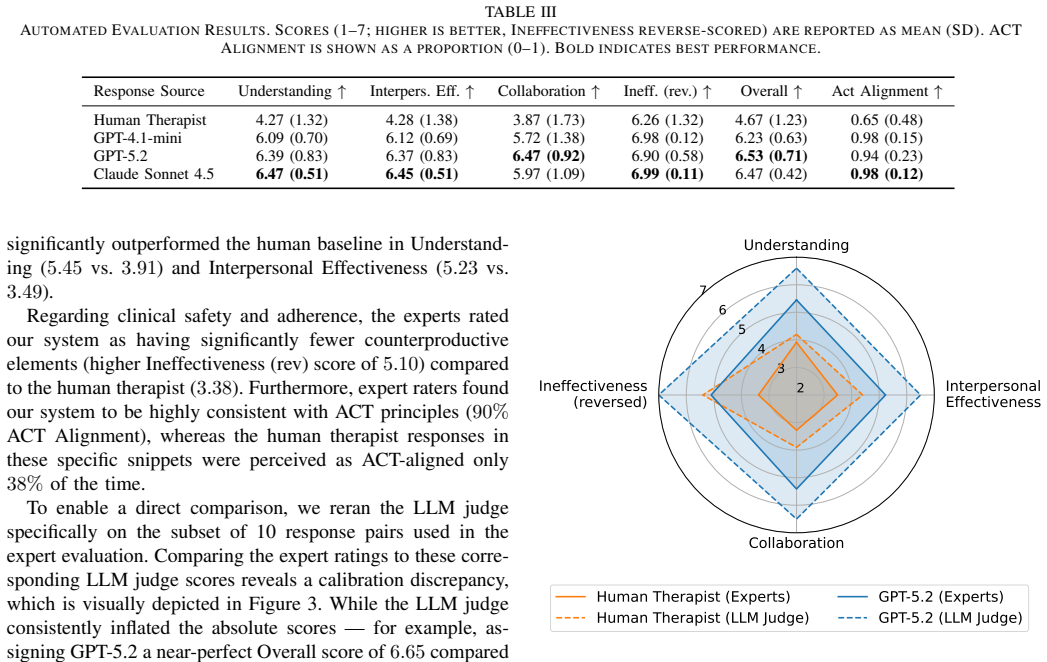
Mind Companion performs layered real-time analysis of client input and uses retrieval-augmented generation to produce responses that, in the case of the GPT-5.2 configuration, were rated higher than human therapist responses on understanding, interpersonal effectiveness, collaboration, and therapeutic alignment by both an automated LLM judge and 11 expert psychotherapists.
What carries the argument
The multi-layered analysis pipeline that extracts facts, detects psychological flexibility processes, recognizes emotions, and monitors safety to inform context-aware response generation and storage for clinicians.
If this is right
- Analysis outputs from client statements can be stored and reviewed by supervising clinicians to support treatment planning.
- Response generation can draw on retrieval from evidence-based therapeutic literature to maintain alignment with process-based principles.
- Embodied delivery through an avatar with synchronized speech synthesis can be used to present the generated responses.
- Multiple LLM back-ends can be swapped and compared on the same therapeutic evaluation criteria.
Where Pith is reading between the lines
- The approach could be extended to allow the stored analysis data to trigger automated alerts for clinicians when safety concerns are detected.
- Over time the same analysis pipeline might support longitudinal tracking of a client's psychological flexibility across multiple sessions.
- The system architecture could be adapted to other therapy orientations by swapping the underlying therapeutic literature used for retrieval.
Load-bearing premise
Ratings produced by an automated LLM judge together with scores from only 11 professional psychotherapists on existing session transcripts are enough to show that the generated responses would be therapeutically appropriate, effective, and safe with real clients.
What would settle it
A randomized trial that tracks symptom change and engagement metrics for clients assigned to sessions with the Mind Companion agent versus sessions with human therapists.
Figures

read the original abstract
Access to evidence-based psychotherapy remains limited worldwide, with long waitlists even in high-income regions. Recent advances in large language models (LLMs) offer potential for scalable mental health support when designed with clinical oversight and safety mechanisms. We present Mind Companion, an LLM-based embodied conversational agent integrating multi-layered psychological analysis with process-based therapy principles. The system performs real-time analysis of client statements across fact extraction, psychological flexibility process detection, emotion recognition, and safety monitoring. Analysis results are stored for supervising clinicians to inform therapeutic planning. Response generation incorporates retrieval-augmented generation from evidence-based therapeutic literature and context-aware prompting. Responses are delivered through an embodied avatar with synchronized speech synthesis and animation. We evaluated three LLM configurations (GPT-4.1-mini, GPT-5.2, Claude Sonnet 4.5) against therapist responses from real therapy sessions using automated LLM-judge assessment and expert evaluation with 11 professional psychotherapists. GPT-5.2 achieved higher ratings than human therapist responses across understanding, interpersonal effectiveness, collaboration, and therapeutic alignment in both evaluations, demonstrating the feasibility of LLM-based conversational agents as tools to complement clinical care.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Mind Companion, an LLM-based embodied conversational agent for process-based psychotherapy that performs real-time multi-layered analysis (fact extraction, psychological flexibility process detection, emotion recognition, safety monitoring) and generates responses via retrieval-augmented generation from therapeutic literature, delivered through an avatar. Three LLM configurations are evaluated against human therapist responses from real sessions using an automated LLM-judge and ratings from 11 professional psychotherapists; GPT-5.2 is reported to receive higher scores than humans on understanding, interpersonal effectiveness, collaboration, and therapeutic alignment, supporting feasibility as a clinical complement.
Significance. If the evaluation methodology and results withstand scrutiny, the work could advance HCI and AI applications in mental health by demonstrating a concrete architecture that combines process-based therapy principles with LLM capabilities and safety layers. The multi-layered analysis pipeline and use of evidence-based retrieval represent a thoughtful design choice that goes beyond generic chatbots. However, the absence of rigorous validation details limits the immediate clinical significance to a preliminary feasibility demonstration rather than established utility.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: The claim that GPT-5.2 achieved higher ratings than human therapist responses is presented without any description of the evaluation protocol, including response sampling method, blinding procedures for the 11 raters, exact rating instruments, or how LLM-judge prompts were constructed and validated.
- [Results] Results section: No statistical tests, confidence intervals, effect sizes, or inter-rater reliability metrics (e.g., Cohen's kappa or ICC) are reported for the differences between LLM and human responses or among the 11 expert raters, preventing assessment of whether the superiority is reliable or meaningful.
- [Discussion] Discussion / Conclusion: The assertion that the system demonstrates feasibility as a tool to complement clinical care, including therapeutic appropriateness and safety, rests solely on offline ratings; no live client interactions, symptom outcome measures, alliance assessments, or adverse-event monitoring data are described to support this extrapolation.
minor comments (2)
- [Abstract] The model identifiers (GPT-4.1-mini, GPT-5.2, Claude Sonnet 4.5) are used without citation or version clarification, which may confuse readers unfamiliar with the exact checkpoints.
- [Results] Figure captions and table descriptions for the evaluation results could be expanded to include the number of responses rated per condition and the precise scale anchors.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We agree that additional details on the evaluation methodology and statistical analyses are needed to strengthen the paper. We will revise the manuscript to address these points and provide greater transparency. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The claim that GPT-5.2 achieved higher ratings than human therapist responses is presented without any description of the evaluation protocol, including response sampling method, blinding procedures for the 11 raters, exact rating instruments, or how LLM-judge prompts were constructed and validated.
Authors: We concur that the evaluation protocol requires more detailed exposition to enable readers to fully assess the validity of the results. In the revised version, we will augment the Evaluation section with comprehensive descriptions of the response sampling method from the real therapy sessions, any blinding procedures employed with the 11 professional psychotherapists, the precise rating instruments and scales utilized, and the methodology for constructing and validating the prompts used by the LLM-judge. These additions will ensure full reproducibility and address the concerns raised. revision: yes
-
Referee: [Results] Results section: No statistical tests, confidence intervals, effect sizes, or inter-rater reliability metrics (e.g., Cohen's kappa or ICC) are reported for the differences between LLM and human responses or among the 11 expert raters, preventing assessment of whether the superiority is reliable or meaningful.
Authors: The absence of statistical reporting is an oversight in the current manuscript. We will incorporate the necessary analyses in the revised Results section, including appropriate statistical tests for comparing LLM and human responses, confidence intervals around the ratings, effect sizes to quantify the magnitude of differences, and inter-rater reliability metrics such as intraclass correlation coefficients (ICC) for the expert ratings. This will allow for a more rigorous evaluation of the reliability and meaningfulness of the observed differences. revision: yes
-
Referee: [Discussion] Discussion / Conclusion: The assertion that the system demonstrates feasibility as a tool to complement clinical care, including therapeutic appropriateness and safety, rests solely on offline ratings; no live client interactions, symptom outcome measures, alliance assessments, or adverse-event monitoring data are described to support this extrapolation.
Authors: We recognize that our evaluation is confined to offline expert ratings and does not encompass live client interactions or clinical outcome data. The manuscript is intended as a demonstration of the technical feasibility and initial expert assessment of the Mind Companion system. In the revised Discussion and Conclusion sections, we will explicitly delineate the limitations of the offline evaluation approach, moderate the language regarding clinical complementarity to reflect the preliminary nature of the findings, and recommend future research involving live deployments, symptom measures, therapeutic alliance assessments, and adverse event monitoring to establish clinical utility. revision: yes
Circularity Check
No circularity: evaluation compares outputs to external human baselines and independent raters
full rationale
The paper describes system construction and then performs direct empirical comparison of LLM-generated responses against real therapist responses from sessions, using both automated LLM judges and ratings from 11 external professional psychotherapists. No equations, parameter fitting, self-definitional loops, or load-bearing self-citations are present in the reported derivation or evaluation chain. The central claim rests on external data (human session transcripts and expert ratings) rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Global, regional, and national burden of 12 mental disorders in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019,
GBD 2019 Mental Disorders Collaborators, “Global, regional, and national burden of 12 mental disorders in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019,” 2022, iSSN: 2215-0366 Number: 2 Pages: 137-150 V olume: 9. [Online]. Available: https://www.sciencedirect.com/science/ article/pii/S2215036621003953
2019
-
[2]
World Health Organization, “Mental health atlas 2020,” Geneva, 2021, tex.howpublished: Electronic version. [Online]. Available: https://www.who.int/publications-detail-redirect/9789240036703
arXiv 2020
-
[3]
Access to mental health care in europe – consensus paper,
A. Barbato, M. Vallarino, F. Rapisarda, A. Lora, and J. M. C. de Almeida, “Access to mental health care in europe – consensus paper,” 2016. [Online]. Available: https://health.ec.europa.eu/system/ files/2016-12/ev 20161006 co04 en 0.pdf
2016
-
[4]
Toward expert-level medical question answering with large language models,
K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, M. Amin, L. Hou, K. Clark, S. R. Pfohl, H. Cole-Lewis, and others, “Toward expert-level medical question answering with large language models,” Nature Medicine, vol. 31, no. 3, pp. 943–950, 2025. [Online]. Available: https://www.nature.com/articles/s41591-024-03423-7
2025
-
[5]
J. W. Ayers, A. Poliak, M. Dredze, E. C. Leas, Z. Zhu, J. B. Kelley, D. J. Faix, A. M. Goodman, C. A. Longhurst, M. Hogarth, and others, “Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum,”JAMA Internal Medicine, vol. 183, no. 6, pp. 589–596, 2023. [Online]. Available: https: //jam...
arXiv 2023
-
[6]
N. Naor, A. Frenkel, and M. Winsberg, “Improving well-being with a mobile artificial intelligence–powered acceptance commitment therapy Tool: Pragmatic retrospective study,”JMIR Formative Research, vol. 6, no. 7, p. e36018, 2022. [Online]. Available: https://pubmed.ncbi.nlm. nih.gov/35598216/
arXiv 2022
-
[7]
Adolescents’ well-being while using a mobile artificial intelligence–Powered Acceptance Commitment therapy tool: Evidence from a longitudinal study,
D. Vertsberger, N. Naor, M. Winsberg, and others, “Adolescents’ well-being while using a mobile artificial intelligence–Powered Acceptance Commitment therapy tool: Evidence from a longitudinal study,”Jmir Ai, vol. 1, no. 1, p. e38171, 2022. [Online]. Available: https://ai.jmir.org/2022/1/e38171
2022
-
[8]
J. Moore, D. Grabb, W. Agnew, K. Klyman, S. Chancellor, D. C. Ong, and N. Haber, “Expressing stigma and inappropriate responses prevents LLMs from safely replacing mental health providers,” in Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, Jun. 2025, pp. 599–627, arXiv:2504.18412 [cs]. [Online]. Available: http://arx...
arXiv 2025
-
[9]
The future of intervention science: Process-based therapy,
S. G. Hofmann and S. C. Hayes, “The future of intervention science: Process-based therapy,”Clinical Psychological Science, vol. 7, no. 1, pp. 37–50, 2019, publisher: Sage Publications Sage CA: Los Angeles, CA. [Online]. Available: https://pmc.ncbi.nlm.nih.gov/articles/PMC6350520/
2019
-
[10]
Acceptance and commitment therapy: Model, processes and outcomes,
S. C. Hayes, J. B. Luoma, F. W. Bond, A. Masuda, and J. Lillis, “Acceptance and commitment therapy: Model, processes and outcomes,” Behaviour Research and Therapy, vol. 44, no. 1, pp. 1–25, 2006. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0005796705002147
2006
-
[11]
S. C. Hayes, K. D. Strosahl, and K. G. Wilson,Acceptance and commitment therapy: The process and practice of mindful change. Guilford press, 2011
2011
-
[12]
The empirical status of acceptance and commitment therapy: A review of meta-analyses,
A. T. Gloster, N. Walder, M. E. Levin, M. P. Twohig, and M. Karekla, “The empirical status of acceptance and commitment therapy: A review of meta-analyses,”Journal of contextual behavioral science, vol. 18, pp. 181–192, 2020
2020
-
[13]
K. K. Fitzpatrick, A. Darcy, and M. Vierhile, “Delivering cognitive be- havior therapy to young adults with symptoms of depression and anxiety using a fully automated conversational agent (woebot): a randomized controlled trial,”JMIR mental health, vol. 4, no. 2, p. e7785, 2017
2017
-
[14]
Evaluating the therapeutic alliance with a free-text cbt conversational agent (wysa): a mixed- methods study,
C. Beatty, T. Malik, S. Meheli, and C. Sinha, “Evaluating the therapeutic alliance with a free-text cbt conversational agent (wysa): a mixed- methods study,”Frontiers in Digital Health, vol. 4, p. 847991, 2022
2022
-
[15]
iCare - An AI - Powered Virtual Assistant for Mental Health,
R. Mavila, S. Jaiswal, R. Naswa, W. Yuwen, B. Erdly, and D. Si, “iCare - An AI - Powered Virtual Assistant for Mental Health,” in2024 IEEE 12th International Conference on Healthcare Informatics (ICHI), Jun. 2024, pp. 466–471. [Online]. Available: https://ieeexplore.ieee.org/document/10628911
arXiv 2024
-
[16]
Benchmarking retrieval- augmented generation for medicine,
G. Xiong, Q. Jin, Z. Lu, and A. Zhang, “Benchmarking retrieval- augmented generation for medicine,” inFindings of the Association for Computational Linguistics ACL 2024, 2024, pp. 6233–6251
2024
-
[17]
Improving retrieval-augmented generation in medicine with iterative follow-up questions,
G. Xiong, Q. Jin, X. Wang, M. Zhang, Z. Lu, and A. Zhang, “Improving retrieval-augmented generation in medicine with iterative follow-up questions,” inBiocomputing 2025: Proceedings of the Pacific Sympo- sium. World Scientific, 2024, pp. 199–214
2025
-
[18]
Retrieval-augmented gen- eration for generative artificial intelligence in medicine,
R. Yang, Y . Ning, E. Keppo, M. Liu, C. Hong, D. S. Bitterman, J. C. L. Ong, D. S. W. Ting, and N. Liu, “Retrieval-augmented gen- eration for generative artificial intelligence in medicine,”arXiv preprint arXiv:2406.12449, 2024
arXiv 2024
-
[19]
Using Large Language Models to Create Personalized Networks From Therapy Sessions,
C. W. Ong, H. Arnaout, K. Sheehan, E. Fox, E. Owtscharow, and I. Gurevych, “Using Large Language Models to Create Personalized Networks From Therapy Sessions,” Dec. 2025, arXiv:2512.05836 [cs]. [Online]. Available: http://arxiv.org/abs/2512.05836
arXiv 2025
-
[20]
Embodied con- versational agents in clinical psychology: a scoping review,
S. Provoost, H. M. Lau, J. Ruwaard, and H. Riper, “Embodied con- versational agents in clinical psychology: a scoping review,”Journal of medical Internet research, vol. 19, no. 5, p. e151, 2017
2017
-
[21]
The thera- peutic alliance in digital mental health interventions for serious mental illnesses: narrative review,
H. Tremain, C. McEnery, K. Fletcher, G. Murrayet al., “The thera- peutic alliance in digital mental health interventions for serious mental illnesses: narrative review,”JMIR mental health, vol. 7, no. 8, p. e17204, 2020
2020
-
[22]
Use of automated conversa- tional agents in improving young population mental health: a scoping review,
R. Balan, A. Dobrean, and C. R. Poetar, “Use of automated conversa- tional agents in improving young population mental health: a scoping review,”NPJ Digital Medicine, vol. 7, no. 1, p. 75, 2024
2024
-
[23]
The distress analysis interview corpus of human and computer interviews,
J. Gratch, R. Artstein, G. Lucas, G. Stratou, S. Scherer, A. Nazarian, R. Wood, J. Boberg, D. DeVault, S. Marsella, D. Traum, S. Rizzo, and L.-P. Morency, “The distress analysis interview corpus of human and computer interviews,” inProceedings of the ninth international conference on language resources and evaluation (LREC’14), N. Calzolari, K. Choukri, T...
2014
-
[24]
A demonstration of dialogue processing in SimSensei kiosk,
F. Morbini, D. DeVault, K. Georgila, R. Artstein, D. Traum, and L.-P. Morency, “A demonstration of dialogue processing in SimSensei kiosk,” inProceedings of the 15th annual meeting of the special interest group on discourse and dialogue (SIGDIAL), 2014, pp. 254–256. [Online]. Available: https://aclanthology.org/W14-4334.pdf
2014
-
[25]
An embodied conversational agent for unguided internet-based cognitive behavior therapy in preventative mental health: feasibility and acceptability pilot trial,
S. Suganuma, D. Sakamoto, and H. Shimoyama, “An embodied conversational agent for unguided internet-based cognitive behavior therapy in preventative mental health: feasibility and acceptability pilot trial,”JMIR mental health, vol. 5, no. 3, p. e10454, 2018. [Online]. Available: https://mental.jmir.org/2018/3/e10454/
2018
-
[26]
Towards streaming speech-to-avatar synthesis,
T. S. Prabhune, P. Wu, B. Yu, and G. K. Anumanchipalli, “Towards streaming speech-to-avatar synthesis,”arXiv preprint arXiv:2310.16287, 2023
arXiv 2023
-
[27]
How LLM Counselors Violate Ethical Standards in Mental Health Practice: A Practitioner-Informed Framework,
Z. Iftikhar, A. Xiao, S. Ransom, J. Huang, and H. Suresh, “How LLM Counselors Violate Ethical Standards in Mental Health Practice: A Practitioner-Informed Framework,”Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, vol. 8, no. 2, pp. 1311–1323, Oct. 2025. [Online]. Available: https://ojs.aaai.org/index.php/AIES/ article/view/36632
2025
-
[28]
Through the extended evolutionary meta-model, and what ACT found there: ACT as a process-based therapy,
C. W. Ong, J. Ciarrochi, S. G. Hofmann, M. Karekla, and S. C. Hayes, “Through the extended evolutionary meta-model, and what ACT found there: ACT as a process-based therapy,”Journal of Contextual Behavioral Science, vol. 32, p. 100734, Apr. 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S2212144724000140
2024
-
[29]
Are there basic emotions?
P. Ekman, “Are there basic emotions?”Psychological review, vol. 99, pp. 550–3, Jul. 1992
1992
-
[30]
An argument for basic emotions,
——, “An argument for basic emotions,”Cognition & emotion, vol. 6, no. 3-4, pp. 169–200, 1992
1992
-
[31]
Harris,ACT made simple: An easy-to-read primer on acceptance and commitment therapy
R. Harris,ACT made simple: An easy-to-read primer on acceptance and commitment therapy. New Harbinger Publications, 2019
2019
-
[32]
Karekla and M
M. Karekla and M. M. Kelly,Cravings and addictions: Free yourself from the struggle of addictive behavior with acceptance and commitment therapy. New Harbinger Publications, 2022
2022
-
[33]
Harris,The happiness trap: How to stop struggling and start living
R. Harris,The happiness trap: How to stop struggling and start living. Shambhala Publications, 2022
2022
-
[34]
Salsa lipsync suite: Real-time lip sync for unity3d,
C. M. Studio, “Salsa lipsync suite: Real-time lip sync for unity3d,” https://crazyminnowstudio.com/unity-3d/lip-sync-salsa/, 2016, reference for the fallback lip-sync system used when A2F is unavailable, ensuring system robustness and continuous operation
2016
-
[35]
Audio2face-3d: Audio-driven realistic facial animation for digital avatars,
C. Chung, I. Fedorov, M. Huang, A. Karmanov, D. Korobchenko, R. Ribera, Y . Seolet al., “Audio2face-3d: Audio-driven realistic facial animation for digital avatars,”arXiv preprint arXiv:2508.16401, 2025
arXiv 2025
-
[36]
Psychotherapy for Chronic In- and Outpatients with Common Mental Disorders: The “Choose Change
A. T. Gloster, E. Haller, J. Villanueva, V . Block, C. Benoy, A. H. Meyer, S. Brogli, V . Kuhweide, M. Karekla, K. Bader, M. Walter, and U. Lang, “Psychotherapy for Chronic In- and Outpatients with Common Mental Disorders: The “Choose Change” Effectiveness Trial.” [Online]. Available: https://dx.doi.org/10.1159/000529411
-
[37]
JudgeBench: A Benchmark for Evaluating LLM-based Judges,
S. Tan, S. Zhuang, K. Montgomery, W. Y . Tang, A. Cuadron, C. Wang, R. A. Popa, and I. Stoica, “JudgeBench: A Benchmark for Evaluating LLM-based Judges,” Apr. 2025, arXiv:2410.12784 [cs]. [Online]. Available: http://arxiv.org/abs/2410.12784
Pith/arXiv arXiv 2025
-
[38]
Therapy Transcript Coding Manual - Interactive Guide
J. Ciarrochi, “Therapy Transcript Coding Manual - Interactive Guide.” [Online]. Available: https://therapy-code-guide-josephciarrochi.replit. app/
-
[39]
Applied knowledge of Acceptance and Commitment Therapy (ACT): Developing and assessing the utility of a Situational Judgement Test (SJT),
K. Jamison, D. Curran, R. White, and V . Samuel, “Applied knowledge of Acceptance and Commitment Therapy (ACT): Developing and assessing the utility of a Situational Judgement Test (SJT),”Journal of Contextual Behavioral Science, vol. 38, p. 100949, Oct. 2025. [Online]. Available: https://linkinghub.elsevier.com/retrieve/pii/S221214472500081X
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.