CoPersona: Collaborative Persona Graphs for Robust LLM Personalization
Pith reviewed 2026-07-03 18:18 UTC · model grok-4.3
The pith
CoPersona builds multiplex persona graphs to model facet-level user alignments and borrow signals from peers for robust LLM personalization with sparse histories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
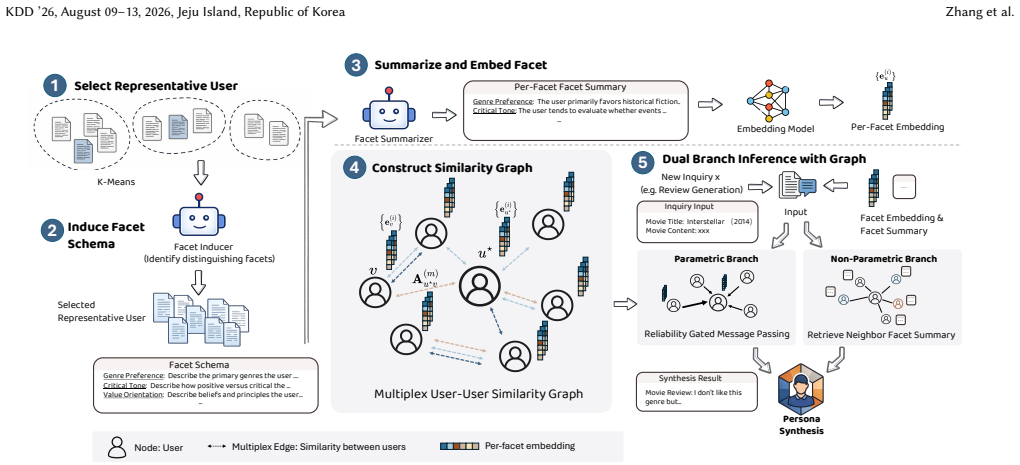
CoPersona decomposes interaction histories into multiple facet-level representations and explicitly models peer-to-peer, facet-level alignment through a multiplex persona graph to complete sparse user profiles by borrowing signals from behaviorally similar peers, using a dual-branch architecture of non-parametric peer retrieval and parametric graph reasoning at inference time.
What carries the argument
The multiplex persona graph that decomposes user histories into facets and connects peers at the facet level to enable aligned signal transfer.
If this is right
- Consistent performance improvements over strong baselines in multiple domains and model scales.
- Greater robustness when test-time requests involve under-supported facets.
- Effective use of peer information without direct transfer of biased global signals.
- Scalable collaborative personalization that handles uneven facet coverage.
Where Pith is reading between the lines
- The facet-level alignment could help in other sparse data settings like recommendation systems beyond LLMs.
- Interpreting the graph edges might provide insights into why certain users are similar on specific preferences.
- Extending the graph to include temporal facets could capture evolving user interests.
Load-bearing premise
That decomposing histories into facet-level representations and modeling explicit peer-to-peer alignment in a multiplex graph can overcome bias from uneven facet coverage that obscures similarity in the global space.
What would settle it
A controlled test on datasets with deliberately skewed facet distributions where CoPersona shows no improvement or worse performance than global similarity baselines would indicate the assumption does not hold.
Figures



read the original abstract
Real-world LLM personalization is often constrained by sparse and skewed user histories: most users provide only a handful of interactions, while even frequent users' logs capture an incomplete and biased view of their preferences. As a result, weakly observed user attributes are difficult to infer, leading to brittle personalization when test-time requests shift toward under-supported facets. Motivated by this limitation, we present CoPersona, a graph-based collaborative personalization framework that completes sparse user profiles by borrowing signals from behaviorally similar peers. However, directly transferring signals is difficult because uneven facet coverage introduces bias into interaction histories, obscuring user similarity in the unstructured global space. To address this issue, CoPersona decomposes interaction histories into multiple facet-level representations and explicitly models peer-to-peer, facet-level alignment through a multiplex persona graph. To effectively leverage peer information at inference time, we employ a dual-branch architecture that combines non-parametric peer retrieval with parametric graph reasoning. Experiments across multiple domains and model scales demonstrate consistent improvements over strong baselines, validating CoPersona as an effective approach for robust LLM personalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CoPersona, a graph-based collaborative framework for LLM personalization. It decomposes sparse and skewed user interaction histories into multiple facet-level representations, constructs a multiplex persona graph to explicitly model peer-to-peer facet alignments, and employs a dual-branch inference architecture combining non-parametric peer retrieval with parametric graph reasoning. Experiments across domains and model scales report consistent gains over strong baselines.
Significance. If the central claims hold, the work addresses a practically important limitation in real-world LLM personalization—brittle performance on under-supported facets due to uneven history coverage—by leveraging collaborative signals at the facet level rather than globally. The explicit multiplex-graph modeling and dual-branch design are concrete technical contributions that could influence subsequent graph-augmented personalization systems.
major comments (2)
- [Motivation and §3] Motivation and §3 (Method): The claim that facet-level decomposition yields cleaner similarity signals than the global space rests on the assumption that facet extraction itself is not biased by the same sparse coverage. The manuscript does not describe an independent facet-discovery procedure (e.g., external corpus, pre-trained topic model, or bootstrap step) that would avoid inheriting coverage bias from the original histories; without this, the multiplex-graph edges on under-supported facets remain unreliable, directly undermining the central motivation.
- [§4 and Table X] §4 (Experiments) and Table X (main results): While consistent improvements are reported, the absence of an ablation that isolates the contribution of the multiplex alignment (versus simple global retrieval or single-facet graphs) makes it difficult to attribute gains specifically to the facet-level peer modeling. This is load-bearing because the paper’s novelty claim centers on the multiplex structure.
minor comments (2)
- [§3] Notation for the multiplex graph (e.g., edge types per facet) should be formalized with a clear mathematical definition early in §3 to improve readability.
- [Figure 2] The dual-branch architecture diagram would benefit from explicit labeling of which branch is non-parametric and which is parametric.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting important aspects of our motivation and experimental design. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Motivation and §3] Motivation and §3 (Method): The claim that facet-level decomposition yields cleaner similarity signals than the global space rests on the assumption that facet extraction itself is not biased by the same sparse coverage. The manuscript does not describe an independent facet-discovery procedure (e.g., external corpus, pre-trained topic model, or bootstrap step) that would avoid inheriting coverage bias from the original histories; without this, the multiplex-graph edges on under-supported facets remain unreliable, directly undermining the central motivation.
Authors: We agree that the reliability of facet extraction is central to the motivation and that the current manuscript does not provide sufficient detail on an independent discovery procedure. In the revised version we will expand §3 to explicitly describe the facet extraction process, incorporate a bootstrap initialization step drawing on a small external seed corpus, and add a discussion of how this mitigates inheritance of coverage bias into the multiplex edges. This revision directly addresses the concern while preserving the core collaborative-alignment contribution. revision: yes
-
Referee: [§4 and Table X] §4 (Experiments) and Table X (main results): While consistent improvements are reported, the absence of an ablation that isolates the contribution of the multiplex alignment (versus simple global retrieval or single-facet graphs) makes it difficult to attribute gains specifically to the facet-level peer modeling. This is load-bearing because the paper’s novelty claim centers on the multiplex structure.
Authors: We acknowledge that the lack of a targeted ablation for the multiplex component limits the ability to isolate its contribution. The existing experiments compare against strong baselines but do not include the requested controls. In the revision we will add an ablation study to §4 and update Table X to compare the full multiplex model against (i) global retrieval without facet decomposition and (ii) single-facet graphs, thereby providing clearer evidence for the value of the multiplex structure. revision: yes
Circularity Check
No circularity: method described at conceptual level with no equations or self-referential fits
full rationale
The provided abstract and description contain no mathematical derivations, equations, fitted parameters, or self-citations that could reduce claims to inputs by construction. The framework is presented as a high-level graph-based approach without visible prediction steps that loop back to fitted values. Per rules, absence of load-bearing equations or self-citation chains means no circularity can be exhibited via direct quote and reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nor Aniza Abdullah, Rasheed Abubakar Rasheed, Mohd Hairul Nizam Md Nasir, and Md Mujibur Rahman. 2021. Eliciting auxiliary information for cold start user recommendation: A survey.Applied Sciences11, 20 (2021), 9608
2021
-
[2]
Gati V Aher, Rosa I Arriaga, and Adam Tauman Kalai. 2023. Using large language models to simulate multiple humans and replicate human subject studies. In International conference on machine learning. PMLR, 337–371
2023
- [3]
-
[4]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. InProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. 65–72
2005
-
[5]
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long- document transformer.arXiv preprint arXiv:2004.05150(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
JesúS Bobadilla, Fernando Ortega, Antonio Hernando, and Jesús Bernal. 2012. A collaborative filtering approach to mitigate the new user cold start problem. Knowledge-based systems26 (2012), 225–238
2012
- [7]
-
[8]
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He
-
[9]
arXiv:2010.03240 [cs.IR] https://arxiv.org/abs/2010.03240
Bias and Debias in Recommender System: A Survey and Future Directions. arXiv:2010.03240 [cs.IR] https://arxiv.org/abs/2010.03240
-
[10]
Jin Chen, Zheng Liu, Xu Huang, Chenwang Wu, Qi Liu, Gangwei Jiang, Yuanhao Pu, Yuxuan Lei, Xiaolong Chen, Xingmei Wang, et al. 2024. When large language models meet personalization: Perspectives of challenges and opportunities.World Wide Web27, 4 (2024), 42
2024
- [11]
-
[12]
J. A. Hartigan and M. A. Wong. 1979. Algorithm AS 136: A K-Means Clustering Algorithm.Applied Statistics28, 1 (1979), 100–108. doi:10.2307/2346830
- [13]
-
[14]
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley
-
[15]
Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[17]
Qiushi Huang, Shuai Fu, Xubo Liu, Wenwu Wang, Tom Ko, Yu Zhang, and Lilian Tang. 2023. Learning retrieval augmentation for personalized dialogue generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2523–2540
2023
-
[18]
EunJeong Hwang, Bodhisattwa Majumder, and Niket Tandon. 2023. Aligning language models to user opinions. InFindings of the Association for Computational Linguistics: EMNLP 2023. 5906–5919
2023
-
[19]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bo- janowski, Armand Joulin, and Edouard Grave. 2021. Unsupervised dense in- formation retrieval with contrastive learning.arXiv preprint arXiv:2112.09118 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Joel Jang, Seungone Kim, Bill Yuchen Lin, Yizhong Wang, Jack Hessel, Luke Zettlemoyer, Hannaneh Hajishirzi, Yejin Choi, and Prithviraj Ammanabrolu
- [21]
-
[22]
Daniel Jurafsky and James H. Martin. 2026.Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, with Language Models(3rd ed.). Online manuscript released January 6, 2026. https://web.stanford.edu/~jurafsky/slp3/
2026
- [23]
-
[24]
Ishita Kumar, Snigdha Viswanathan, Sushrita Yerra, Alireza Salemi, Ryan A Rossi, Franck Dernoncourt, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, et al. 2024. Longlamp: A benchmark for personalized long-form text generation.arXiv preprint arXiv:2407.11016(2024)
-
[25]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles. 611–626
2023
-
[26]
Cheng Li, Mingyang Zhang, Qiaozhu Mei, Weize Kong, and Michael Bendersky
-
[27]
InProceedings of the ACM Web Conference 2024
Learning to rewrite prompts for personalized text generation. InProceedings of the ACM Web Conference 2024. 3367–3378
2024
- [28]
- [29]
- [30]
-
[31]
Blerina Lika, Kostas Kolomvatsos, and Stathes Hadjiefthymiades. 2014. Facing the cold start problem in recommender systems.Expert systems with applications 41, 4 (2014), 2065–2073
2014
-
[32]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[33]
Jiongnan Liu, Yutao Zhu, Shuting Wang, Xiaochi Wei, Erxue Min, Yu Lu, Shuaiqiang Wang, Dawei Yin, and Zhicheng Dou. 2025. Llms+ persona-plug= personalized llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9373–9385
2025
-
[34]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
Zhenyi Lu, Wei Wei, Xiaoye Qu, Xian-Ling Mao, Dangyang Chen, and Jixiong Chen. 2023. Miracle: Towards Personalized Dialogue Generation with Latent- Space Multiple Personal Attribute Control. InFindings of the Association for KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Zhang et al. Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan ...
-
[36]
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Chris Leung, Jiajie Tang, and Jiebo Luo. 2024. Llm-rec: Personalized recom- mendation via prompting large language models. InFindings of the Association for Computational Linguistics: NAACL 2024. 583–612
2024
-
[37]
Wenyu Mao, Jiancan Wu, Weijian Chen, Chongming Gao, Xiang Wang, and Xiangnan He. 2025. Reinforced prompt personalization for recommendation with large language models.ACM Transactions on Information Systems43, 3 (2025), 1–27
2025
-
[38]
Sheshera Mysore, Zhuoran Lu, Mengting Wan, Longqi Yang, Bahareh Sarrafzadeh, Steve Menezes, Tina Baghaee, Emmanuel Barajas Gonzalez, Jennifer Neville, and Tara Safavi. 2024. Pearl: Personalizing large language model writing assis- tants with generation-calibrated retrievers. InProceedings of the 1st Workshop on Customizable NLP: Progress and Challenges in...
2024
-
[39]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). 188–197
2019
-
[40]
OpenAI. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL] https://arxiv. org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
2002
- [42]
- [43]
-
[44]
Sriyash Poddar, Yanming Wan, Hamish Ivison, Abhishek Gupta, and Natasha Jaques. 2024. Personalizing reinforcement learning from human feedback with variational preference learning.Advances in Neural Information Processing Sys- tems37 (2024), 52516–52544
2024
-
[45]
Matt Post. 2018. A Call for Clarity in Reporting BLEU Scores. InProceedings of the Third Conference on Machine Translation: Research Papers. 186–191
2018
- [46]
-
[47]
Yilun Qiu, Xiaoyan Zhao, Yang Zhang, Yimeng Bai, Wenjie Wang, Hong Cheng, Fuli Feng, and Tat-Seng Chua. 2025. Measuring What Makes You Unique: Difference-Aware User Modeling for Enhancing LLM Personalization. InFind- ings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics, 21258–21277
2025
-
[48]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084 [cs.CL] https://arxiv.org/abs/ 1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [49]
-
[50]
Stephen Robertson, Hugo Zaragoza, et al . 2009. The probabilistic relevance framework: BM25 and beyond.Foundations and trends®in information retrieval 3, 4 (2009), 333–389
2009
-
[51]
Yuta Saito, Suguru Yaginuma, Yuta Nishino, Hayato Sakata, and Kazuhide Nakata
-
[52]
Unbiased Recommender Learning from Missing-Not-At-Random Implicit Feedback. InProceedings of the 13th International Conference on Web Search and Data Mining(Houston, TX, USA)(WSDM ’20). Association for Computing Machinery, New York, NY, USA, 501–509. doi:10.1145/3336191.3371783
-
[53]
Alireza Salemi, Surya Kallumadi, and Hamed Zamani. 2024. Optimization meth- ods for personalizing large language models through retrieval augmentation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 752–762
2024
-
[54]
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2024. LaMP: When Large Language Models Meet Personalization. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7370–7392
2024
-
[55]
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. 2023. Whose opinions do language models reflect?. In International Conference on Machine Learning. PMLR, 29971–30004
2023
-
[56]
Andrew I Schein, Alexandrin Popescul, Lyle H Ungar, and David M Pennock
-
[57]
InProceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval
Methods and metrics for cold-start recommendations. InProceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval. 253–260
-
[58]
Teng Shi, Jun Xu, Xiao Zhang, Xiaoxue Zang, Kai Zheng, Yang Song, and Han Li
-
[59]
InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval
Retrieval augmented generation with collaborative filtering for personalized text generation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1294–1304
- [60]
-
[61]
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. Learning to summarize with human feedback.Advances in neural information processing systems33 (2020), 3008–3021
2020
-
[62]
Chenkai Sun, Ke Yang, Revanth Gangi Reddy, Yi Fung, Hou Pong Chan, Kevin Small, ChengXiang Zhai, and Heng Ji. 2025. Persona-db: Efficient large language model personalization for response prediction with collaborative data refinement. InProceedings of the 31st International Conference on Computational Linguistics. 281–296
2025
- [63]
-
[64]
Zhaoxuan Tan, Qingkai Zeng, Yijun Tian, Zheyuan Liu, Bing Yin, and Meng Jiang
- [65]
-
[66]
Qwen Team. 2024. Qwen2.5: A Party of Foundation Models. https://qwenlm. github.io/blog/qwen2.5/
2024
-
[67]
Yu-Min Tseng, Yu-Chao Huang, Teng-Yun Hsiao, Wei-Lin Chen, Chao-Wei Huang, Yu Meng, and Yun-Nung Chen. 2024. Two Tales of Persona in LLMs: A Survey of Role-Playing and Personalization. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics...
- [68]
-
[69]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Cheng- peng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [70]
-
[71]
Mert Yazan, Suzan Verberne, and Frederik Situmeang. 2025. Improving RAG for Personalization with Author Features and Contrastive Examples. InEuropean Conference on Information Retrieval. Springer, 408–416
2025
- [72]
-
[73]
Jinghao Zhang, Yuting Liu, Wenjie Wang, Qiang Liu, Shu Wu, Liang Wang, and Tat-Seng Chua. 2025. Personalized Text Generation with Contrastive Activation Steering. InProceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 7128–7141
2025
- [74]
-
[75]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi
-
[76]
In8th International Conference on Learning Representations, ICLR 2020, 2020
BERTScore: Evaluating Text Generation with BERT. In8th International Conference on Learning Representations, ICLR 2020, 2020
2020
- [77]
-
[78]
Yuchen Zhuang, Haotian Sun, Yue Yu, Rushi Qiang, Qifan Wang, Chao Zhang, and Bo Dai. 2024. Hydra: Model factorization framework for black-box llm personalization.Advances in Neural Information Processing Systems37 (2024), 100783–100815. CoPersona: Collaborative Persona Graphs for Robust LLM Personalization KDD ’26, August 09–13, 2026, Jeju Island, Republi...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.