SIGMA: Saliency-Guided Sparse Mask Attacks for Speech Emotion Recognition
Pith reviewed 2026-06-30 04:41 UTC · model grok-4.3
The pith
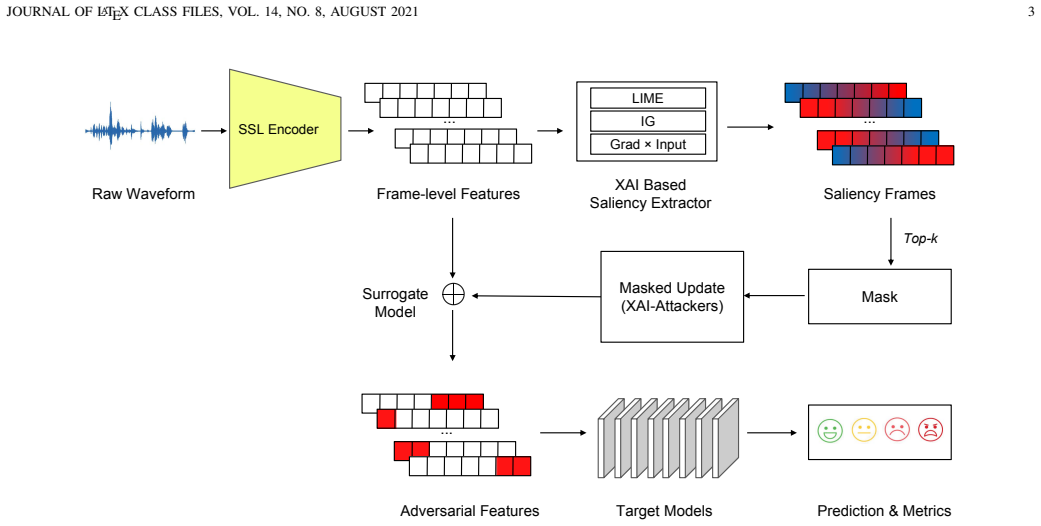
SIGMA computes a single saliency-guided mask from post-hoc XAI on self-supervised speech features to restrict sparse adversarial perturbations on emotion recognition models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On self-supervised speech features, post-hoc XAI techniques produce saliency maps that identify the scope of the mask, to which magnitude-bounded updates are then restricted. The mask is computed once and can be reused across models and different sparsity attacks to amortise cost. Under matched budgets and across multiple sparse-attack settings on IEMOCAP and TESS, SIGMA maintains competitive attack success rates while navigating a trade-off between attack efficacy and explanation consistency.
What carries the argument
The saliency-guided sparse mask produced by post-hoc XAI techniques applied to self-supervised speech features, which scopes all subsequent magnitude-bounded perturbations.
If this is right
- Attack success rates remain competitive with baseline sparse methods under the same budgets on IEMOCAP and TESS.
- Explanation consistency improves because perturbations are confined to regions highlighted by saliency maps.
- Computational cost is amortised since one mask can be reused across multiple target models and attack families.
- The framework applies uniformly to multiple sparse-attack settings and supports analysis of transferability across models.
Where Pith is reading between the lines
- The reusable mask property suggests efficiency advantages when analysing vulnerability across large ensembles of SER models.
- Incorporating saliency guidance upfront may help identify input regions whose protection could increase overall model robustness.
- The explicit trade-off documented here provides a concrete axis for comparing future sparse attack methods that also claim interpretability.
Load-bearing premise
Post-hoc XAI techniques on self-supervised speech features produce saliency maps that reliably identify the scope of the mask for effective and consistent sparse perturbations.
What would settle it
An experiment in which explanation consistency metrics show no improvement or decline when the saliency-guided mask is used versus random or non-XAI masks at equivalent attack success rates and sparsity levels.
Figures
read the original abstract
Speech conveys rich emotional information. As Speech Emotion Recognition (SER) is usually deployed in privacy-sensitive and reliability-critical environments, adversarial attacks on SER have attracted increasing attention. Existing sparse attacks control the number of perturbed elements, yet, they often lack explainability guidance and explicit measures of explanation consistency. A unified treatment of sparsity and magnitude constraints is also uncommon. In addition, transferability across attack families and target models remains limited. Hence, we propose a SalIency-Guided sparse Mask Attack (SIGMA). On self-supervised speech features, we use post-hoc explainable artificial intelligence (XAI) techniques to produce saliency maps and identify the scope of the mask, and then restrict magnitude-bounded updates to this mask. The mask is computed once and can be reused across models and different sparsity attacks to amortise cost. We evaluate on the IEMOCAP and TESS datasets. Under matched budgets and across multiple sparse-attack settings, SIGMA maintains competitive attack success rates, navigating a conscious trade-off between attack efficacy and explanation consistency. SIGMA therefore provides an efficient and interpretable framework for analysing the vulnerability and explanation behaviour of SER models under structured perturbations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SIGMA, a saliency-guided sparse mask attack for Speech Emotion Recognition. It applies post-hoc XAI techniques to self-supervised speech features to generate saliency maps that define the scope of a sparse mask, then applies magnitude-bounded perturbations only within this mask. The mask is computed once and reused across models and attack variants. On IEMOCAP and TESS, the method is claimed to maintain competitive attack success rates while navigating a trade-off between efficacy and explanation consistency, providing an efficient, interpretable framework for SER vulnerability analysis.
Significance. If the empirical results hold with proper validation, the approach offers a reusable mask mechanism that amortizes XAI computation and explicitly links sparse attack design to model explanations, which is a constructive contribution to both adversarial robustness in audio and XAI applications in privacy-sensitive SER. The unified handling of sparsity and magnitude budgets is a methodological strength.
major comments (4)
- [Abstract] Abstract: the claim that SIGMA 'maintains competitive attack success rates' and navigates a 'conscious trade-off' between efficacy and explanation consistency is unsupported by any quantitative values, baselines, error bars, or metrics for consistency; without these, the central empirical claim cannot be evaluated.
- [Method] Method section (description of saliency map usage): the assumption that post-hoc XAI saliency maps on self-supervised features (e.g., wav2vec) reliably identify causally relevant regions for emotion classification is load-bearing for the consistency gain, yet no faithfulness metrics, insertion/deletion scores, or ablation against random masks are reported; if the maps are unfaithful, the method reduces to a standard sparse attack with added overhead.
- [Experiments] Experiments section: no sensitivity analysis to XAI technique choice or target model is provided, despite known method-dependence of saliency maps for audio; this directly affects the claim of improved explanation consistency across settings and reuse of the mask.
- [Experiments] Experiments section: the manuscript reports no direct comparison of SIGMA-guided masks versus non-XAI sparse attacks under identical sparsity/magnitude budgets, leaving the incremental benefit of saliency guidance on success rates versus consistency unquantified.
minor comments (2)
- [Abstract] Abstract: the expansion of SIGMA contains inconsistent capitalization ('SalIency-Guided'); standardize to 'Saliency-Guided'.
- [Abstract] Abstract: specify the concrete post-hoc XAI methods employed (e.g., Grad-CAM variant or integrated gradients) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the empirical support and validation of the method.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that SIGMA 'maintains competitive attack success rates' and navigates a 'conscious trade-off' between efficacy and explanation consistency is unsupported by any quantitative values, baselines, error bars, or metrics for consistency; without these, the central empirical claim cannot be evaluated.
Authors: We agree that the abstract should contain explicit quantitative support. The experiments section reports attack success rates, baseline comparisons, and consistency metrics under matched sparsity/magnitude budgets on IEMOCAP and TESS. We will revise the abstract to include these specific values, error bars, and a brief definition of the consistency metric. revision: yes
-
Referee: [Method] Method section (description of saliency map usage): the assumption that post-hoc XAI saliency maps on self-supervised features (e.g., wav2vec) reliably identify causally relevant regions for emotion classification is load-bearing for the consistency gain, yet no faithfulness metrics, insertion/deletion scores, or ablation against random masks are reported; if the maps are unfaithful, the method reduces to a standard sparse attack with added overhead.
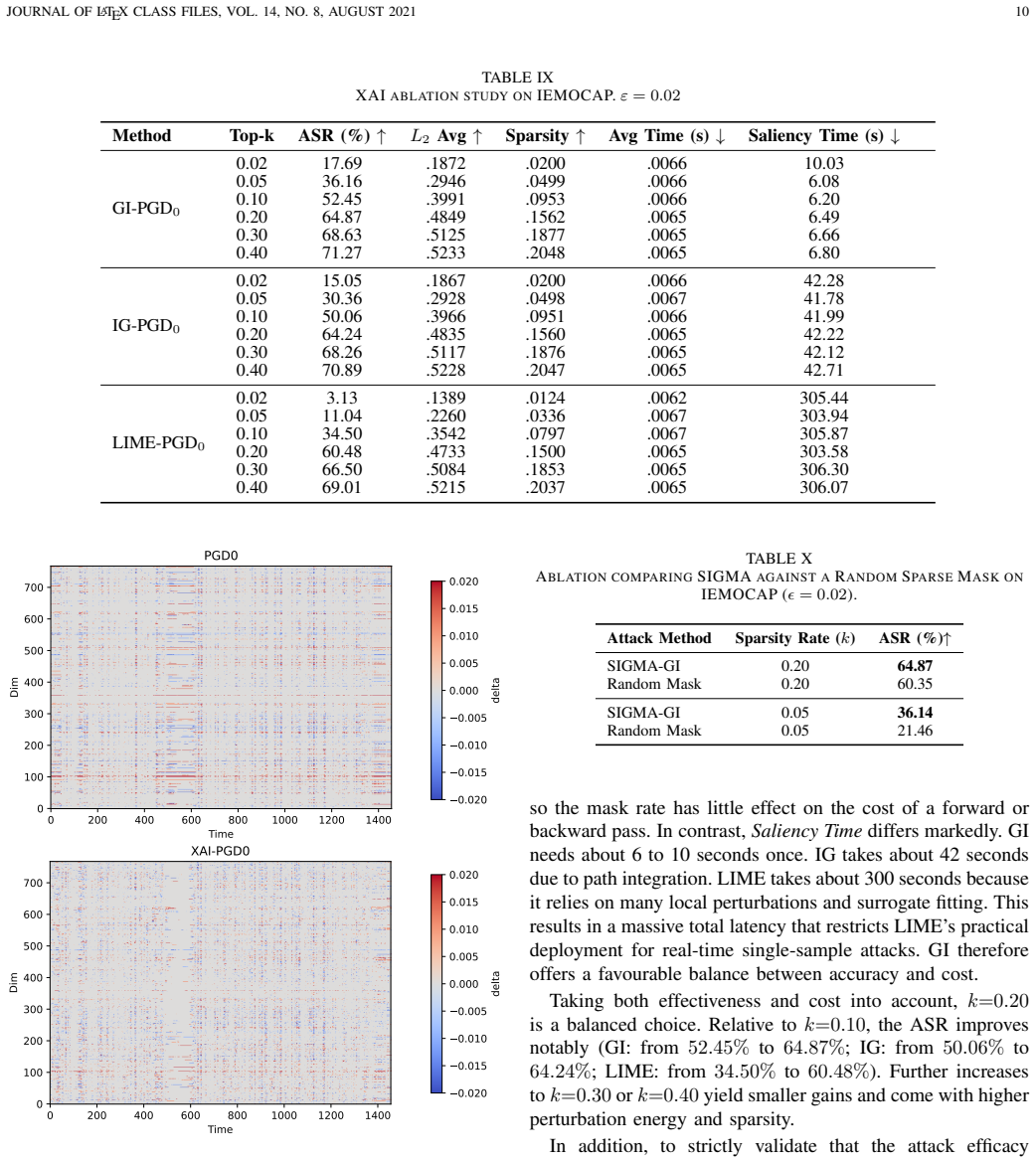
Authors: This concern is valid. The manuscript does not report insertion/deletion scores or random-mask ablations. We will add an ablation comparing SIGMA-guided masks against random masks of identical sparsity and magnitude budgets, and include any post-hoc faithfulness indicators that can be computed on the existing saliency maps to quantify the benefit of the guidance. revision: yes
-
Referee: [Experiments] Experiments section: no sensitivity analysis to XAI technique choice or target model is provided, despite known method-dependence of saliency maps for audio; this directly affects the claim of improved explanation consistency across settings and reuse of the mask.
Authors: We acknowledge the known variability of saliency methods. While the current evaluation reuses masks across target models, it does not vary the underlying XAI technique. In revision we will add results using at least one additional XAI method to demonstrate that the mask reuse and consistency benefits are not tied to a single saliency extractor. revision: yes
-
Referee: [Experiments] Experiments section: the manuscript reports no direct comparison of SIGMA-guided masks versus non-XAI sparse attacks under identical sparsity/magnitude budgets, leaving the incremental benefit of saliency guidance on success rates versus consistency unquantified.
Authors: We agree that a direct comparison is required to isolate the contribution of saliency guidance. The paper compares SIGMA across attack families but does not benchmark against equivalent non-guided sparse attacks. We will add this head-to-head evaluation under identical budgets, reporting differences in both attack success rate and explanation consistency. revision: yes
Circularity Check
No circularity: empirical method proposal with no derivation chain
full rationale
The paper proposes SIGMA, a saliency-guided sparse mask attack for SER using post-hoc XAI on self-supervised features. No equations, predictions, fitted parameters, or self-citations are presented that reduce any claim to its inputs by construction. The work consists of a method description followed by empirical evaluation on IEMOCAP and TESS under sparsity/magnitude budgets; the central assumption about XAI map reliability is a methodological choice, not a derived result. This matches the default expectation for non-circular papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GatedxLSTM: A multimodal affective computing approach for emotion recognition in conversations,
Y . Li, Q. Sun, S. M. K. Murthy, E. Alturki, and B. W. Schuller, “GatedxLSTM: A multimodal affective computing approach for emotion recognition in conversations,”arXiv preprint:2503.20919, pp. 1–9, 2025
-
[2]
Make patient consultation warmer: A clinical application for speech emotion recognition,
H.-C. Li, T. Pan, M.-H. Lee, and H.-W. Chiu, “Make patient consultation warmer: A clinical application for speech emotion recognition,”Applied Sciences, vol. 11, no. 11, 2021
2021
-
[3]
Speech emotion recognition and serious games: An entertaining approach for crowdsourcing annotated samples,
L. Matsouliadis, E. Siamtanidou, N. Vryzas, and C. Dimoulas, “Speech emotion recognition and serious games: An entertaining approach for crowdsourcing annotated samples,”Information, vol. 16, no. 3, p. 238, 2025
2025
-
[4]
The acoustically emotion-aware conversational agent with speech emotion recognition and empathetic responses,
J. Hu, Y . Huang, X. Hu, and Y . Xu, “The acoustically emotion-aware conversational agent with speech emotion recognition and empathetic responses,”IEEE Transactions on Affective Computing, vol. 14, no. 1, pp. 17–30, 2022
2022
-
[5]
Towards friendly AI: A comprehensive review and new perspectives on human-AI alignment,
Q. Sun, Y . Li, E. Alturki, S. M. K. Murthy, and B. W. Schuller, “Towards friendly AI: A comprehensive review and new perspectives on human-AI alignment,”arXiv preprint:2412.15114, pp. 1–15, 2024
-
[6]
Adversarial attacks and defenses in deep learning,
K. Ren, T. Zheng, Z. Qin, and X. Liu, “Adversarial attacks and defenses in deep learning,”Engineering, vol. 6, no. 3, pp. 346–360, 2020
2020
-
[7]
Threat of adversarial attacks on deep learning in computer vision: A survey,
N. Akhtar and A. Mian, “Threat of adversarial attacks on deep learning in computer vision: A survey,”IEEE Access, vol. 6, pp. 14 410–14 430, 2018. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
2018
-
[8]
Adversarial attacks on ASR systems: An overview,
X. Zhang, H. Tan, X. Huang, D. Zhang, K. Tang, and Z. Gu, “Adversarial attacks on ASR systems: An overview,”arXiv preprint:2208.02250, pp. 1–8, 2022
-
[9]
Adversarial attacks and defenses in speaker recognition systems: A survey,
J. Lan, R. Zhang, Z. Yan, J. Wang, Y . Chen, and R. Hou, “Adversarial attacks and defenses in speaker recognition systems: A survey,”Journal of Systems Architecture, vol. 127, p. 102526, 2022
2022
-
[10]
Generating and protecting against adversarial attacks for deep speech-based emotion recognition models,
Z. Ren, A. Baird, J. Han, Z. Zhang, and B. W. Schuller, “Generating and protecting against adversarial attacks for deep speech-based emotion recognition models,” inProc. ICASSP, 2020, pp. 7184–7188
2020
-
[11]
A black-box adversarial attack strategy with adjustable sparsity and generalizability for deep image classifiers,
A. Ghosh, S. S. Mullick, S. Datta, S. Das, A. K. Das, and R. Mallipeddi, “A black-box adversarial attack strategy with adjustable sparsity and generalizability for deep image classifiers,”Pattern Recognition, vol. 122, p. 108279, 2022
2022
-
[12]
Weighted-sampling audio adversarial example attack,
X. Liu, K. Wan, Y . Ding, X. Zhang, and Q. Zhu, “Weighted-sampling audio adversarial example attack,” inProc. AAAI, 2020, pp. 4908–4915
2020
-
[13]
Audio injection adversarial example attack,
X. Liu, X. Chen, M. Yin, Y . Wang, T. Hu, and K. Ding, “Audio injection adversarial example attack,” inProc. ICML Workshop on Adversarial Machine Learning, 2021
2021
-
[14]
STAA-net: A sparse and transferable adversarial attack for speech emotion recognition,
Y . Chang, Z. Ren, Z. Zhang, X. Jing, K. Qian, X. Shao, B. Hu, T. Schultz, and B. W. Schuller, “STAA-net: A sparse and transferable adversarial attack for speech emotion recognition,”IEEE Transactions on Affective Computing, 2024
2024
-
[15]
Boosting adversarial attacks with momentum,
Y . Dong, F. Liao, T. Pang, H. Su, J. Zhu, X. Hu, and J. Li, “Boosting adversarial attacks with momentum,” inProc. CVPR, 2018, pp. 9185– 9193
2018
-
[16]
Muting Whisper: A universal acoustic adversarial attack on speech foundation models,
V . Raina, R. Ma, C. McGhee, K. Knill, and M. Gales, “Muting Whisper: A universal acoustic adversarial attack on speech foundation models,” arXiv preprint:2405.06134, pp. 1–18, 2024
-
[17]
W. Jin, J. Su, H. Wang, Y . Ye, and J. Hao, “Boosting the transferability of audio adversarial examples with acoustic representation optimization,” arXiv preprint:2503.19591, pp. 1–16, 2025
-
[18]
Focus-shifting attack: An adversarial attack that retains saliency map information and manipulates model explanations,
Q.-X. Huang, L.-K. Chiang, M.-Y . Chiu, and H.-M. Sun, “Focus-shifting attack: An adversarial attack that retains saliency map information and manipulates model explanations,”IEEE Transactions on Reliability, vol. 73, no. 2, pp. 808–819, 2023
2023
-
[19]
Maximal Jacobian-based Saliency Map Attack
R. Wiyatno and A. Xu, “Maximal Jacobian-based saliency map attack,” arXiv preprint:1808.07945, pp. 1–5, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Saliency attack: Towards imper- ceptible black-box adversarial attack,
Z. Dai, S. Liu, Q. Li, and K. Tang, “Saliency attack: Towards imper- ceptible black-box adversarial attack,”ACM Transactions on Intelligent Systems and Technology., vol. 14, no. 3, pp. 1–20, 2023
2023
-
[21]
Hidden Markov model-based speech emotion recognition,
B. Schuller, G. Rigoll, and M. Lang, “Hidden Markov model-based speech emotion recognition,” inProc. ICASSP, vol. 2, 2003, pp. II–1
2003
-
[22]
Audio explanation synthesis with generative foundation models,
A. Akman, Q. Sun, and B. W. Schuller, “Audio explanation synthesis with generative foundation models,” inProc. ICASSP, 2025, pp. 1–5
2025
-
[23]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Proc. KDDNeurIPS, vol. 33, 2020, pp. 12 449–12 460
2020
-
[24]
Speech emotion diarization: Which emotion appears when?
Y . Wang, M. Ravanelli, A. Nfissi, and A. Yacoubi, “Speech emotion diarization: Which emotion appears when?”arXiv preprint:2306.12991, pp. 1–7, 2023
-
[25]
SUPERB: Speech process- ing Universal PERformance benchmark,
S. w. Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y .-T. Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Linet al., “SUPERB: Speech process- ing Universal PERformance benchmark,”arXiv preprint:2105.01051, pp. 1–6, 2021
-
[26]
emotion2vec: Self-supervised pre-training for speech emotion repre- sentation,
Z. Ma, Z. Zheng, J. Ye, J. Li, Z. Gao, S. Zhang, and X. Chen, “emotion2vec: Self-supervised pre-training for speech emotion repre- sentation,” inProc. ACL, 2024, pp. 15 747–15 760
2024
-
[27]
Ex- HuBERT: Enhancing HuBERT through block extension and fine-tuning on 37 emotion datasets,
S. Amiriparian, F. Packa ´n, M. Gerczuk, and B. W. Schuller, “Ex- HuBERT: Enhancing HuBERT through block extension and fine-tuning on 37 emotion datasets,”arXiv preprint:2406.10275, pp. 1–5, 2024
-
[28]
Y . Wang, A. Boumadane, and A. Heba, “A fine-tuned wav2vec 2.0/Hu- BERT benchmark for speech emotion recognition, speaker verification and spoken language understanding,”arXiv preprint:2111.02735, pp. 1– 7, 2021
-
[29]
Emotion recognition from speech using wav2vec 2.0 embeddings,
L. Pepino, P. Riera, and L. Ferrer, “Emotion recognition from speech using wav2vec 2.0 embeddings,”arXiv preprint:2104.03502, pp. 1–5, 2021
-
[30]
Explaining and harnessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” inProc. ICLR, 2015
2015
-
[31]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” inProc. ICLR, 2018
2018
-
[32]
Simple black-box adversarial attacks,
C. Guo, J. Gardner, Y . You, A. G. Wilson, and K. Weinberger, “Simple black-box adversarial attacks,” inProc. ICML, vol. 97, 2019, pp. 2484– 2493
2019
-
[33]
One pixel attack for fooling deep neural networks,
J. Su, D. V . Vargas, and K. Sakurai, “One pixel attack for fooling deep neural networks,”IEEE Transactions on Evolutionary Computation, vol. 23, no. 5, pp. 828–841, 2019
2019
-
[34]
Universal adversarial perturbations for speech recogni- tion systems,
P. Neekhara, S. Hussain, P. Pandey, S. Dubnov, J. J. McAuley, and F. Koushanfar, “Universal adversarial perturbations for speech recogni- tion systems,” inProc. Interspeech, 2019, pp. 481–485
2019
-
[35]
Generating transferable adversarial examples for speech classification,
H. Kim, J. Park, and J. Lee, “Generating transferable adversarial examples for speech classification,”Pattern Recognition, vol. 137, p. 109286, 2023
2023
-
[36]
Attack on practical speaker verification system using universal adversarial perturbations,
W. Zhang, S. Zhao, L. Liu, J. Li, X. Cheng, T. F. Zheng, and X. Hu, “Attack on practical speaker verification system using universal adversarial perturbations,” inProc. ICASSP, 2021, pp. 2575–2579
2021
-
[37]
Generative adversarial networks,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial networks,” Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020
2020
-
[38]
DiffAttack: Imperceptible and transfer- able audio adversarial attack via diffusion model,
J. Chen, Y . Dai, and F. Huang, “DiffAttack: Imperceptible and transfer- able audio adversarial attack via diffusion model,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2025, pp. 1–5
2025
-
[39]
Enabling fast and universal audio adversarial attack using generative model,
Y . Xie, Z. Li, C. Shi, J. Liu, Y . Chen, and B. Yuan, “Enabling fast and universal audio adversarial attack using generative model,” inProc. AAAI, 2021, pp. 14 129–14 137
2021
-
[40]
EvilHarmony: Stealthy adversarial attacks against black-box speech recognition systems,
X. Yuan, J. Zhang, F. Guo, K. Chen, X. Wang, S. Zhang, Y . Chen, D. Liu, P. Li, Z. Wang, and R. Zhu, “EvilHarmony: Stealthy adversarial attacks against black-box speech recognition systems,” inProc. IEEE Symp. Secur. Privacy (SP), 2025, pp. 4569–4587
2025
-
[41]
Explainable artificial in- telligence for medical applications: A review,
Q. Sun, A. Akman, and B. W. Schuller, “Explainable artificial in- telligence for medical applications: A review,”ACM Transactions on Computing for Healthcare, vol. 6, no. 2, pp. 1–31, 2025
2025
-
[42]
Learning important features through propagating activation differences,
A. Shrikumar, P. Greenside, and A. Kundaje, “Learning important features through propagating activation differences,” inProc. ICML, 2017, pp. 3145–3153
2017
-
[43]
Explainable ai for healthcare,
Y . Li, Q. Sun, A. Akman, and B. W. Schuller, “Explainable ai for healthcare,” inHandbook on Smart Health. SAGE Publications 1 Oliver’s Yard, 55 City Road, London, EC1Y 1SP, 2025, pp. 632–652
2025
-
[44]
Axiomatic attribution for deep networks,
M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” inProc. ICML, 2017, pp. 3319–3328
2017
-
[45]
Layer-wise relevance propagation: An overview,
G. Montavon, A. Binder, S. Lapuschkin, W. Samek, and K.-R. M ¨uller, “Layer-wise relevance propagation: An overview,” inExplainable AI: Interpreting, Explaining and Visualizing Deep Learning, ser. Lecture Notes in Computer Science. Springer, 2019, vol. 11700, pp. 193–209
2019
-
[46]
Grad-CAM: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-CAM: Visual explanations from deep networks via gradient-based localization,” inProc. ICCV, 2017, pp. 618–626
2017
-
[47]
“Why should I trust you?
M. T. Ribeiro, S. Singh, and C. Guestrin, ““Why should I trust you?” explaining the predictions of any classifier,” inProc. KDD, 2016, pp. 1135–1144
2016
-
[48]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” inProc. NeurIPS, vol. 30, 2017
2017
-
[49]
Audio explainable artificial intelligence: A review,
A. Akman and B. W. Schuller, “Audio explainable artificial intelligence: A review,”Intelligent Computing, vol. 2, p. 0074, 2024
2024
-
[50]
audiolime: Listenable explanations using source separation,
V . Haunschmid, E. Manilow, and G. Widmer, “audiolime: Listenable explanations using source separation,”arXiv preprint:2008.00582, pp. 1–5, 2020
-
[51]
Unveiling hidden factors: Explainable AI for feature boosting in speech emotion recognition,
A. Nfissi, W. Bouachir, N. Bouguila, and B. Mishara, “Unveiling hidden factors: Explainable AI for feature boosting in speech emotion recognition,”arXiv preprint:2406.01624, pp. 1–36, 2024
-
[52]
Reliable evaluation of at- tribution maps in CNNs: A perturbation-based approach,
L. Nieradzik, H. Stephani, and J. Keuper, “Reliable evaluation of at- tribution maps in CNNs: A perturbation-based approach,”International Journal of Computer Vision, vol. 133, no. 5, pp. 2392–2409, 2025
2025
-
[53]
IEMOCAP: Interactive emotional dyadic motion capture database,
C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “IEMOCAP: Interactive emotional dyadic motion capture database,”Language resources and evaluation, vol. 42, no. 4, pp. 335–359, 2008
2008
-
[54]
Self-attention transfer networks for speech emotion recognition,
Z. Zhao, K. Wang, Z. Bao, Z. Zhang, N. Cummins, S. Sun, H. Wang, J. Tao, and B. W. Schuller, “Self-attention transfer networks for speech emotion recognition,”Virtual Reality & Intelligent Hardware, vol. 3, no. 1, pp. 43–54, 2021
2021
-
[55]
Toronto emotional speech set (TESS),
M. K. Pichora-Fuller and K. Dupuis, “Toronto emotional speech set (TESS),” Scholars Portal Dataverse, 2020. [Online]. Available: https://doi.org/10.5683/SP2/E8H2MF
-
[56]
Speech emotion recognition using deep 1D & 2D CNN LSTM networks,
J. Zhao, X. Mao, and L. Chen, “Speech emotion recognition using deep 1D & 2D CNN LSTM networks,”Biomedical Signal Processing and Control, vol. 47, pp. 312–323, 2019
2019
-
[57]
End-to-end speech emotion recognition using deep neural networks,
P. Tzirakis, J. Zhang, and B. W. Schuller, “End-to-end speech emotion recognition using deep neural networks,” inProc. ICASSP, 2018, pp. 5089–5093
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.