RACORN-1: Adaptive Recall-Preserving Speedup for Low-Selectivity Filtered Vector Search
Pith reviewed 2026-07-02 03:08 UTC · model grok-4.3
The pith
RACORN-1 restores high recall in filtered vector search below 1% selectivity by turning filter-failing nodes into temporary bridges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
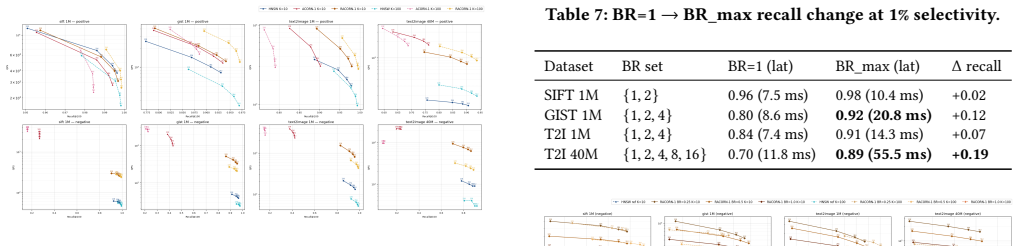
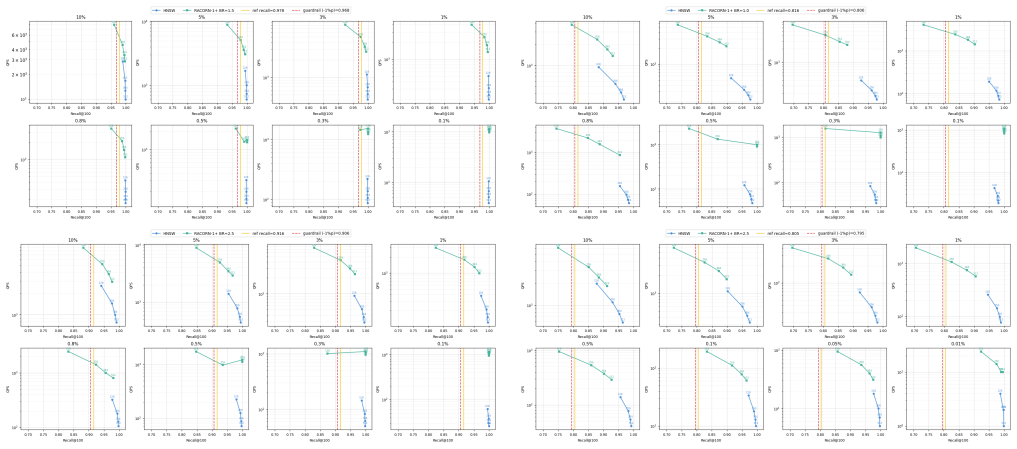
RACORN-1 fixes ACORN-1's connectivity instability below 5 percent selectivity and recall collapse below 1 percent by introducing Adaptive Search Fallback that repurposes filter-failing nodes as transient bridges, with stride sampling used to select bridges and two-hop candidates for spatial diversity. This improves the recall-latency trade-off relative to distance-first HNSW. On three 1M-scale and one 40M-scale datasets it delivers 9-26x latency reduction over HNSW in the 1-0.3 percent selectivity range while lifting recall from 0.45-0.72 to 0.70-0.96 at 1 percent and from 0.03-0.10 to 0.77-0.98 at 0.3 percent. The RACORN-1+ variant adds Adaptive Exact Fallback to reach recall 1.00 with 20-7
What carries the argument
Adaptive Search Fallback (ASF), which repurposes filter-failing nodes as transient bridges selected via stride sampling to restore connectivity and spatial diversity in the filtered graph search.
If this is right
- Delivers 9-26x latency reduction over HNSW in the 1-0.3 percent selectivity range across 1M-40M datasets.
- Recovers recall to 0.70-0.96 at 1 percent and 0.77-0.98 at 0.3 percent selectivity.
- Maintains recall 0.80-0.98 under negative correlation queries where prior methods drop sharply.
- RACORN-1+ variant reaches recall 1.00 with 20-75x speedup at selectivities at or below 0.1 percent on 1M data and 13x at 40M and 0.01 percent.
Where Pith is reading between the lines
- The bridge-repurposing idea could extend to other graph indexes that currently separate filtered and unfiltered search paths.
- It may reduce the need for multiple specialized indexes when queries vary widely in selectivity.
- Testing stride sampling parameters on additional correlation patterns could expose hidden limits not covered in the reported experiments.
Load-bearing premise
That repurposing filter-failing nodes as transient bridges via stride sampling will reliably restore connectivity across all query-filter correlation patterns without new failure modes or excessive overhead.
What would settle it
A dataset and query set with strong negative correlation where stride-sampled bridges miss critical paths and recall falls below 0.7 at 0.3 percent selectivity.
Figures



read the original abstract
Filtered Vector Search (FVS), which combines vector embedding similarity with structured metadata predicates, has emerged as a core requirement in RAG and production retrieval systems. ACORN-1, the representative In-filtering algorithm that reuses an existing HNSW index, substantially reduces latency at low selectivity but suffers connectivity instability below 5% selectivity and recall collapse below 1%. We propose RACORN-1, an in-place extension of ACORN-1 that resolves this collapse via (i) Adaptive Search Fallback (ASF) -- repurposing filter-failing nodes as transient bridges to detour around severed paths; bridge and two-hop candidate selection uses stride sampling for spatial diversity. While filter-first ACORN-family methods have a structural recall trade-off relative to distance-first HNSW, RACORN-1 improves the trade-off curve via ASF, minimizing recall loss while substantially reducing latency. Across three 1M-scale and one 40M-scale dataset, RACORN-1 delivers approximately 9-26x latency reduction over HNSW in the sweet spot (1%-0.3%), and recovers ACORN-1's recall collapse from 0.45-0.72 (1%) and 0.03-0.10 (0.3%) to 0.70-0.96 and 0.77-0.98 respectively. For the extreme-low-selectivity regime where linear scan can outperform graph search, we combine RACORN-1 with (ii) Adaptive Exact Fallback (AEF) in a variant RACORN-1+, achieving recall 1.00 with 20-75x speedup at 1M <=0.1% and 13x speedup at 40M 0.01%. Under a Negative Correlation evaluation (K-means clusters), where ACORN-1 collapses (recall 0.08-0.41), RACORN-1 maintains recall 0.80-0.98 with a 5-9x latency advantage over HNSW. Together, RACORN-1 and RACORN-1+ form an ACORN-1-compatible mechanism robust to both extreme-low-selectivity and adversarial query-filter correlation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RACORN-1, an in-place extension of ACORN-1 for in-filtering vector search on HNSW indexes. It adds Adaptive Search Fallback (ASF) that repurposes filter-failing nodes as transient bridges selected via stride sampling to restore connectivity at low selectivity, plus Adaptive Exact Fallback (AEF) in the RACORN-1+ variant. Experiments across 1M-40M datasets report that RACORN-1 recovers recall from ACORN-1's collapse (0.45-0.72 at 1%, 0.03-0.10 at 0.3%) to 0.70-0.96 and 0.77-0.98 respectively, while achieving 9-26x latency reduction versus HNSW in the 0.3-1% selectivity range; under K-means negative correlation, recall is maintained at 0.80-0.98 with 5-9x speedup. RACORN-1+ reaches recall 1.0 with 20-75x speedup at extreme low selectivity.
Significance. If the reported empirical results hold under the stated experimental conditions, the work provides a practical, index-compatible mechanism that meaningfully improves the recall-latency trade-off for low-selectivity filtered vector search in RAG and production systems. The explicit inclusion of a negative-correlation (K-means) evaluation directly addresses a key robustness concern for the ASF bridge mechanism, strengthening the claim that the approach is not limited to positive-correlation cases. No parameter-free derivations or machine-checked proofs are present, but the reproducible experimental protocol on multiple dataset scales is a positive attribute.
minor comments (2)
- [ASF mechanism] The description of stride sampling within ASF would benefit from an explicit pseudocode listing or parameter table (e.g., stride length, candidate pool size) to support exact reproduction of the bridge-selection logic.
- [Experimental results] Table or figure captions for the 1M-scale and 40M-scale results should explicitly state the number of queries, query distribution, and whether error bars or standard deviations are shown.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The recognition of RACORN-1's practical improvements to the recall-latency trade-off, the inclusion of negative-correlation evaluation, and the reproducible experimental protocol is appreciated. No major comments were listed in the report.
Circularity Check
No circularity: empirical algorithmic extension with no self-referential derivations.
full rationale
The paper describes RACORN-1 as an in-place algorithmic extension of ACORN-1 using Adaptive Search Fallback (ASF) with stride sampling for bridge selection and Adaptive Exact Fallback (AEF). No equations, fitted parameters, or first-principles derivations are present that reduce to inputs by construction. Claims rest on empirical latency/recall measurements across datasets (including negative-correlation cases), not on self-citations, uniqueness theorems, or renamed known results. The method is presented as a heuristic fix for observed connectivity issues, with performance validated externally rather than forced by definition or prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2020. ANN- Benchmarks: A Benchmarking Tool for Approximate Nearest Neighbor Algo- rithms.Information Systems87 (2020), 101374. https://arxiv.org/abs/1807.05614
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. 2021. SPANN: Highly-Efficient Billion-Scale Approximate Nearest Neighborhood Search. InAdvances in Neural Information Processing Systems (NeurIPS). https://arxiv.org/abs/2111.08566
-
[3]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss Library.arXiv preprint arXiv:2401.08281(2024). https://arxiv.org/abs/ 2401.08281
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Elastic. [n.d.]. Filtered HNSW kNN Search. https://elastic.co/search-labs/blog/ filtered-hnsw-knn-search Elastic Search Labs
- [5]
-
[6]
Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premku- mar Srinivasan, Amit Singh, and Harsha Vardhan Simhadri. 2023. Filtered- DiskANN: Graph Algorithms for Approximate Nearest Neighbor Search with Filters. InProceedings of the ACM Web Conference (WWW). ht...
2023
-
[7]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. InProceedings of the 37th International Conference on Machine Learning (ICML). https://arxiv.org/abs/1908.10396 12
-
[8]
Hervé Jégou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Transactions on Pattern Analysis and Machine Intelligence(2011). SIFT 1M / GIST 1M datasets: http://corpus-texmex.irisa.fr/
2011
-
[9]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Informa- tion Processing Systems (NeurIPS). https://arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[10]
MacQueen
J. MacQueen. 1967. Some Methods for Classification and Analysis of Multivariate Observations. InProceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Vol. 1. 281–297
1967
-
[11]
Yu. A. Malkov et al. [n.d.]. hnswlib: Header-only C++/Python Library for Fast Approximate Nearest Neighbors. https://github.com/nmslib/hnswlib
-
[12]
Yu. A. Malkov and D. A. Yashunin. 2018. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence(2018). https: //arxiv.org/abs/1603.09320
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [13]
- [14]
-
[15]
Qdrant. [n.d.]. ACORN Algorithm in Qdrant 1.16. https://qdrant.tech/blog/ qdrant-1.16.x/ Qdrant Engineering Blog
-
[16]
P. Griffiths Selinger, M. M. Astrahan, D. D. Chamberlin, R. A. Lorie, and T. G. Price. 1979. Access Path Selection in a Relational Database Management System. InProceedings of the ACM SIGMOD International Conference on Management of Data. https://doi.org/10.1145/582095.582099
-
[17]
Harsha Vardhan Simhadri, George Williams, Martin Aumüller, et al. 2022. Results of the NeurIPS 2021 Challenge on Billion-Scale Approximate Nearest Neighbor Search.Proceedings of Machine Learning Research(2022). https://arxiv.org/ abs/2205.03763 Yandex Text-to-Image datasets: https://research.yandex.com/ datasets/biganns
-
[18]
Suhas Jayaram Subramanya, Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnaswamy, and Rohan Kadekodi. 2019. DiskANN: Fast Accurate Billion-Point Nearest Neighbor Search on a Single Node. InAdvances in Neural Information Processing Systems (NeurIPS)
2019
- [19]
-
[20]
Unum Cloud. [n.d.]. USearch: Smaller and Faster Single-File Vector Search Engine. https://github.com/unum-cloud/USearch
-
[21]
Vespa. [n.d.]. Additions to HNSW. https://blog.vespa.ai/additions-to-hnsw Vespa Engineering Blog
-
[22]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, Kun Yu, Yuxing Yuan, Yinghao Zou, Jiquan Long, Yudong Cai, Zhenxiang Li, Zhifeng Zhang, Yihua Mo, Jun Gu, Ruiyi Jiang, Yi Wei, and Charles Xie. 2021. Milvus: A Purpose-Built Vec- tor Data Management System. InProceedings of the A...
- [23]
- [24]
-
[25]
Weaviate. 2024. Speed-up Filtered Vector Search. https://weaviate.io/blog/speed- up-filtered-vector-search Weaviate Engineering Blog
2024
-
[26]
Chuangxian Wei, Bin Wu, Sheng Wang, Renjie Lou, Chaoqun Zhan, Feifei Li, and Yuxing Cai. 2020. AnalyticDB-V: A Hybrid Analytical Engine Towards Query Fusion for Structured and Unstructured Data.Proceedings of the VLDB Endowment(2020). https://doi.org/10.14778/3415478.3415541
-
[27]
Chaoji Zuo, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2024. SeRF: Segment Graph for Range-Filtering Approximate Nearest Neighbor Search.Pro- ceedings of the ACM on Management of Data2, 1 (2024), Article 69. https: //doi.org/10.1145/3639324 SIGMOD. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.