A Finite Mixture Failure-rate based Heterogeneous Step-stress Accelerated Life Testing (h-SSALT) Model
Pith reviewed 2026-05-21 08:33 UTC · model grok-4.3
The pith
Ignoring population heterogeneity leads to systematic bias in lifetime predictions across all quantiles, worst at early failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
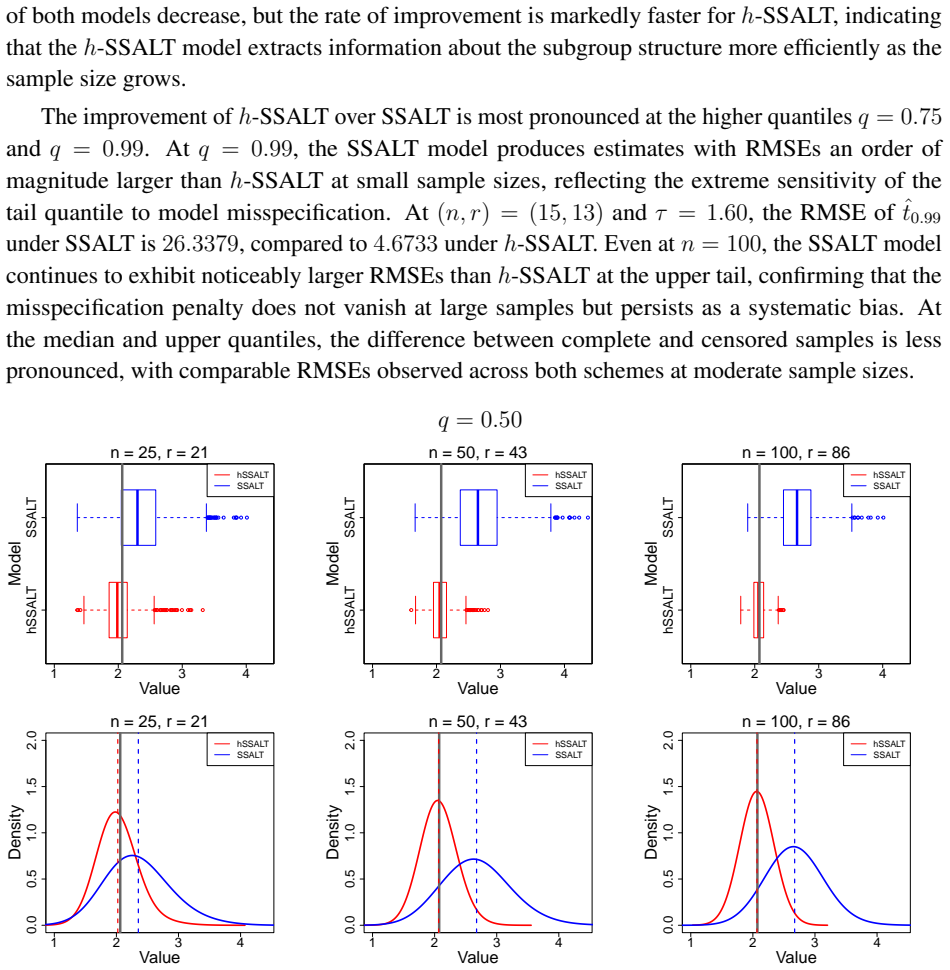
The paper establishes a heterogeneous simple SSALT model where failure times follow a mixture of Weibull distributions under a failure-rate based cumulative exposure framework, with the mixture components corresponding to latent subgroups that differ in their stress response starting at the second level. Maximum likelihood estimation proceeds via the EM algorithm, and the analysis shows that disregarding the mixture structure introduces bias in predicted lifetimes at all quantiles, with the largest errors at small quantiles.
What carries the argument
Finite mixture of m latent Weibull subgroups in the failure-rate formulation of the h-SSALT model, enabling distinct failure behaviors per subgroup while accommodating Type-II censoring.
If this is right
- Systematic bias is avoided in lifetime predictions at all quantiles when the mixture is used.
- Early failure quantiles receive more accurate estimates, improving warranty period design.
- Finite-sample performance of the estimators is reliable based on the simulation results.
- The Weibull model encompasses the prior heterogeneous model as a special case when the shape equals one.
Where Pith is reading between the lines
- Applying the model to additional real datasets could help determine typical numbers of subgroups in production batches.
- Future test designs might incorporate features to identify heterogeneity before the second stress level.
- Similar mixture approaches could address heterogeneity in other accelerated testing protocols.
Load-bearing premise
The load-bearing premise is that any heterogeneity in the population only becomes apparent at the second stress level and can be captured by a finite number of subgroups each with Weibull distributed lifetimes.
What would settle it
A comparison on real failure data where the heterogeneous model's quantile estimates align closely with observed early failures while the homogeneous model does not.
Figures



read the original abstract
Traditional step-stress accelerated life testing models assume that test units originate from a homogeneous population. Recently, Lu and Kateri (2025) proposed a heterogeneous cumulative exposure based SSALT model to account for the inhomogeneous aging patterns among test units belonging to the same production batch. This paper introduces an alternative yet flexible failure-rate based heterogeneous simple SSALT (h-SSALT) model with Weibull-distributed Type-II censored failure times, allowing heterogeneity to emerge at the second stress level through a finite mixture of m latent subgroups, each characterized by its own failure behavior. The expectation-maximization algorithm is developed for maximum likelihood estimation of the model parameters, exploiting the incomplete data structure arising from both unknown group membership and Type-II censoring. Interval estimation is performed using the missing information identity of Louis (1982) with transformation-based confidence intervals respecting parameter constraints. An extensive simulation study evaluates the finite-sample performance of the proposed estimators and demonstrates, through a quantile-based comparison, that ignoring population heterogeneity leads to systematic bias in lifetime predictions across the entire quantile range, with the most severe consequences at early failure quantiles of direct relevance to warranty period design. A special case comparison confirms that the proposed Weibull failure-rate based formulation reduces to the existing model of Lu and Kateri (2025) when the shape parameter equals unity, validating the proposed framework as a proper generalization. The practical application of the model is further illustrated through simulated and real data analysis examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a finite mixture failure-rate based heterogeneous simple step-stress accelerated life testing (h-SSALT) model assuming Weibull failure times under Type-II censoring. Heterogeneity is modeled as emerging only at the second stress level via m latent subgroups with distinct parameters; an EM algorithm is derived for MLE exploiting the incomplete-data structure from latent group membership and censoring. Interval estimation uses Louis' missing-information principle with transformed confidence intervals. Simulations demonstrate that fitting a homogeneous model to data generated from the h-SSALT process produces systematic bias in lifetime quantiles (most pronounced at lower quantiles), and the model reduces exactly to the Lu-Kateri (2025) cumulative-exposure formulation when the Weibull shape equals 1.
Significance. If the modeling assumptions hold, the work supplies a flexible failure-rate-based alternative to existing heterogeneous SSALT models and supplies concrete evidence, via simulation, that population heterogeneity can induce non-negligible bias in quantile lifetime predictions relevant to warranty analysis. The explicit reduction to the Lu-Kateri model when the shape parameter is unity, together with the finite-sample simulation study, provides supporting evidence for both generalization and estimator performance.
major comments (2)
- [Section 2] Section 2: The central modeling choice—that heterogeneity arises only after the first stress change through a finite mixture—is stated without derivation, empirical motivation, or sensitivity analysis. Because the simulation design in Section 4 generates data under precisely this timing restriction, the reported bias pattern (systematic across quantiles and most severe at early failures) is conditional on this untested assumption. If batch heterogeneity is instead present from time zero, the homogeneous-model bias could shift or attenuate, weakening the claim that early quantiles are the most affected for warranty applications.
- [Section 4] Section 4: The quantile-based bias comparison is performed only against the homogeneous Weibull model. No additional runs are reported that vary the mixture onset time, compare against a fully heterogeneous cumulative-exposure baseline, or examine robustness under different censoring schemes. These omissions leave the load-bearing claim about the severity of bias at early quantiles dependent on a single data-generating process.
minor comments (2)
- [Section 2] The notation for the stress-change time and the mixture weights could be introduced more explicitly in the model equations to improve readability for readers unfamiliar with SSALT literature.
- [Section 4] Table captions and axis labels in the simulation figures should state the exact values of m, the stress levels, and the censoring proportion used in each scenario.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important aspects of model motivation and simulation robustness that we will address in the revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Section 2] Section 2: The central modeling choice—that heterogeneity arises only after the first stress change through a finite mixture—is stated without derivation, empirical motivation, or sensitivity analysis. Because the simulation design in Section 4 generates data under precisely this timing restriction, the reported bias pattern (systematic across quantiles and most severe at early failures) is conditional on this untested assumption. If batch heterogeneity is instead present from time zero, the homogeneous-model bias could shift or attenuate, weakening the claim that early quantiles are the most affected for warranty applications.
Authors: We agree that the timing of heterogeneity emergence is a key modeling assumption that warrants explicit justification. In the failure-rate based framework, the first stress level represents the baseline condition under which units are typically assumed to exhibit more uniform behavior before acceleration; heterogeneity is introduced at the second level to reflect the point at which stress-induced differences in failure mechanisms become observable. This choice aligns with the cumulative exposure reduction shown when the shape parameter equals 1. To strengthen the manuscript, we will expand Section 2 with a dedicated paragraph providing practical motivation from accelerated testing literature and include a brief sensitivity analysis examining the effect of earlier heterogeneity onset on the reported quantile bias patterns. revision: yes
-
Referee: [Section 4] Section 4: The quantile-based bias comparison is performed only against the homogeneous Weibull model. No additional runs are reported that vary the mixture onset time, compare against a fully heterogeneous cumulative-exposure baseline, or examine robustness under different censoring schemes. These omissions leave the load-bearing claim about the severity of bias at early quantiles dependent on a single data-generating process.
Authors: The referee correctly notes that the current simulation design focuses on the proposed data-generating process. While the existing results already demonstrate systematic bias under the stated assumptions and include the special-case reduction to the Lu-Kateri model, we acknowledge that broader robustness checks would enhance the claims. In the revised manuscript we will add simulation scenarios that (i) vary the mixture onset time, (ii) compare quantile bias against a fully heterogeneous cumulative-exposure baseline, and (iii) repeat the study under Type-I censoring to assess sensitivity of the early-quantile bias finding. revision: yes
Circularity Check
No significant circularity: model formulation, EM estimation, and simulation-based bias demonstration are self-contained.
full rationale
The paper defines a new failure-rate based h-SSALT model with finite mixture heterogeneity emerging at the second stress level, develops the EM algorithm for MLE under Type-II censoring, and performs quantile comparisons via data simulated directly from the proposed process. This is standard model evaluation and does not reduce any claimed prediction to a fitted input or self-citation by construction. The special-case reduction to Lu and Kateri (2025) when the Weibull shape equals 1 is presented as a consistency check rather than a load-bearing derivation. No self-definitional equations, fitted-input predictions, or uniqueness theorems imported from the authors' prior work appear in the abstract or described structure. The central bias claim is evaluated against an external benchmark (homogeneous model) using generated data, keeping the derivation independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- m (number of latent subgroups)
- Weibull shape and scale parameters per subgroup
axioms (2)
- domain assumption Finite mixture adequately represents population heterogeneity emerging at second stress level
- standard math Type-II censoring and incomplete group membership structure
Reference graph
Works this paper leans on
-
[1]
Abdel-Hamid, A. H. and E. K. Al-Hussaini (2007). Progressive stress accelerated life tests under finite mixture models. Metrika\/ 66\/ (2), 213--231
work page 2007
-
[2]
Abdel-Hamid, A. H. and E. K. Al-Hussaini (2008). Step partially accelerated life tests under finite mixture models. Journal of Statistical Computation and Simulation\/ 78\/ (10), 911--924
work page 2008
-
[3]
Al-Hussaini, E. K. and A. H. Abdel-Hamid (2006). Accelerated life tests under finite mixture models. Journal of Statistical Computation and Simulation\/ 76\/ (8), 673--690
work page 2006
-
[4]
Bagdonavicius, V. and M. Nikulin (2001). Accelerated life models: modeling and statistical analysis . Chapman and Hall/CRC
work page 2001
-
[5]
Bai, D. S., M. Kim, and S. Lee (1989). Optimum simple step-stress accelerated life tests with censoring. IEEE transactions on reliability\/ 38\/ (5), 528--532
work page 1989
-
[6]
Bai, D. S. and M. S. Kim (1993). Optimum simple step-stress accelerated life tests for weibull distribution and type I censoring. Naval Research Logistics (NRL)\/ 40\/ (2), 193--210
work page 1993
- [7]
-
[8]
Basak, I. and N. Balakrishnan (2018). A note on the prediction of censored exponential lifetimes in a simple step-stress model with type- II censoring. Calcutta Statistical Association Bulletin\/ 70\/ (1), 57--73
work page 2018
-
[9]
Bhattacharyya, G. K. and Z. Soejoeti (1989). A tampered failure rate model for step-stress accelerated life test. Communications in Statistics -- Theory and Methods\/ 18\/ (5), 1627--1643
work page 1989
-
[10]
Cramer, E., A. Pal, and D. Samanta (2025). On order restricted inference in multi-step stage life testing for a general family of distributions. Naval Research Logistics (NRL)\/ , 1--20
work page 2025
-
[11]
Dempster, A. P., N. M. Laird, and D. B. Rubin (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, Series B\/ 39\/ (1), 1--38
work page 1977
-
[12]
Everitt, B. S. and D. J. Hand (1981). Finite Mixture Distributions . London: Chapman & Hall
work page 1981
-
[13]
Harris, S. J., D. J. Harris, and C. Li (2017). Failure statistics for commercial lithium ion batteries: A study of 24 pouch cells. Journal of Power Sources\/ 342 , 589--597
work page 2017
-
[14]
Kateri, M. and N. Balakrishnan (2008). Inference for a simple step-stress model with type- II censoring, and W eibull distributed lifetimes. IEEE Transactions on Reliability\/ 57\/ (4), 616--626
work page 2008
-
[15]
Kateri, M. and U. Kamps (2015). Inference in step-stress models based on failure rates. Statistical Papers\/ 56\/ (3), 639--660
work page 2015
-
[16]
Kundu, D. and A. Ganguly (2017). Analysis of Step-Stress Models: Existing Methods and Recent Developments . Amsterdam: Elsevier
work page 2017
-
[17]
Leon, R. V., R. Ramachandran, A. J. Ashby, and J. Thyagarajan (2007). B ayesian modeling of accelerated life tests with random effects. Journal of Quality Technology\/ 39\/ (1), 3--16
work page 2007
-
[18]
Lin, C. T., Y. Y. Hsu, S. Y. Lee, and N. Balakrishnan (2017). Inference on step-stress accelerated life tests for weibull lifetimes under progressive type- I interval censoring. Communications in Statistics -- Theory and Methods\/ 46\/ (7), 3164--3180
work page 2017
- [19]
-
[20]
Lu, Y. and M. Kateri (2025). Simple heterogeneous step-stress accelerated life testing model under type II censoring. Quality and Reliability Engineering International\/ 41\/ (5), 1936--1952
work page 2025
-
[21]
Lv, S., Z. Niu, and K. Song (2015). Reliability analysis using a mixed effects model. Quality and Reliability Engineering International\/ 31\/ (5), 803--812
work page 2015
-
[22]
McLachlan, G. J. and K. E. Basford (1988). Mixture Models: Inference and Applications to Clustering . New York: Marcel Dekker
work page 1988
-
[23]
McLachlan, G. J. and D. Peel (2000). Finite Mixture Models . New York: Wiley
work page 2000
-
[24]
Meeker, W. Q. and L. A. Escobar (1998). Statistical Methods for Reliability Data . New York: Wiley
work page 1998
-
[25]
Meeker, W. Q. and M. J. LuValle (1995). An accelerated life test model based on reliability kinetics. Technometrics\/ 37\/ (2), 133--146
work page 1995
-
[26]
Miller, R. and W. Nelson (1983). Optimum simple step-stress plans for accelerated life testing. IEEE Transactions on Reliability\/ 32\/ (1), 59--65
work page 1983
-
[27]
Nelson, W. (1990). Accelerated Testing: Statistical Models, Test Plans, and Data Analysis . New York: Wiley
work page 1990
-
[28]
Nelson, W. and W. Q. Meeker (1978). Theory for optimum accelerated censored life tests for W eibull and extreme value distributions. Technometrics\/ 20\/ (2), 171--177
work page 1978
-
[29]
Nelson, W. B. (1980). Accelerated life testing - step-stress models and data analyses. IEEE Transactions on Reliability\/ 29\/ (2), 103--108
work page 1980
-
[30]
Pal, A., S. Mitra, and D. Kundu (2021). Order restricted classical inference of a weibull multiple step-stress model. Journal of Applied Statistics\/ 48\/ (4), 623--645
work page 2021
-
[31]
Pal, A. and D. Prajapati (2023). Mixture model for dependent competing risks data and application for diabetic retinopathy treatment. Applied Mathematical Modelling\/ 113 , 514--527
work page 2023
-
[32]
Prajapat, K. (2026). Exact B ayesian planning for simple step-stress accelerated life testing with competing risks. arXiv preprint arXiv:2604.09259\/
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Prajapat, K., S. Mitra, and D. Kundu (2026). On constrained multicriteria-based planning for a two-parameter exponential distribution. Quality and Reliability Engineering International\/ 42\/ (1), 11--23
work page 2026
-
[34]
Prajapati, D., A. Pal, and D. Kundu (2024). A finite mixture model for multiple dependent competing risks with applications of automotive warranty claims data. Statistics and Computing\/ 34\/ (1), 19
work page 2024
-
[35]
Samanta, D. and D. Kundu (2021). Analysis of W eibull step-stress model in presence of competing risk. IEEE Transactions on Reliability\/ 70\/ (2), 687--699
work page 2021
-
[36]
Sedyakin, N. M. (1966). On one physical principle in reliability theory. Technical Cybernetics\/ 3 , 80--87
work page 1966
-
[37]
Seo, J. H. and R. Pan (2016). Accelerated destructive degradation test planning. Technometrics\/ 58\/ (1), 13--24
work page 2016
-
[38]
Seo, J. H. and R. Pan (2017). Mixed effects models for step-stress accelerated life test data. IEEE Transactions on Reliability\/ 66\/ (3), 785--794
work page 2017
-
[39]
Titterington, D. M., A. F. M. Smith, and U. E. Makov (1985). Statistical Analysis of Finite Mixture Distributions . New York: Wiley
work page 1985
-
[40]
Wang, L. (2020). Inference for W eibull competing risks data under W einman multivariate exponential assumption with progressive censoring. IEEE Transactions on Reliability\/ 69\/ (3), 1107--1120
work page 2020
-
[41]
Watkins, A. J. (2001). Commentary: Inference in simple step-stress accelerated life tests. IEEE Transactions on Reliability\/ 50\/ (1), 36--38
work page 2001
- [42]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.