RespiraMFM: A Multimodal Foundation Model with Contrastive Audio-Language Alignment for Respiratory Disease Identification
Pith reviewed 2026-06-27 15:03 UTC · model grok-4.3
The pith
RespiraMFM aligns respiratory audio with clinical text via contrastive learning to raise disease detection accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
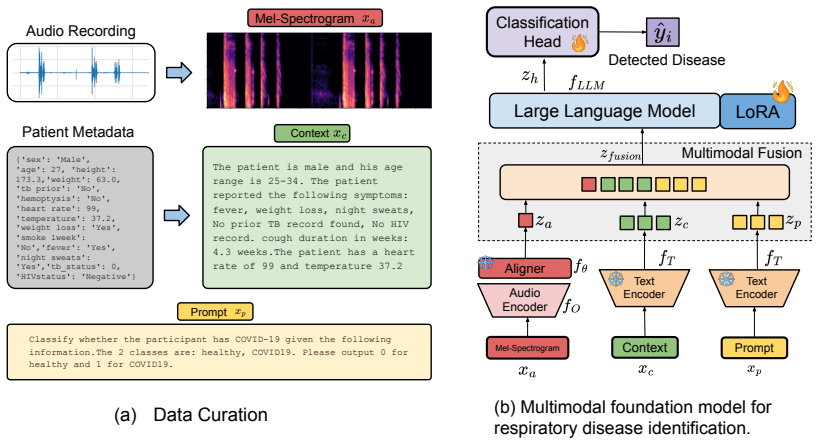
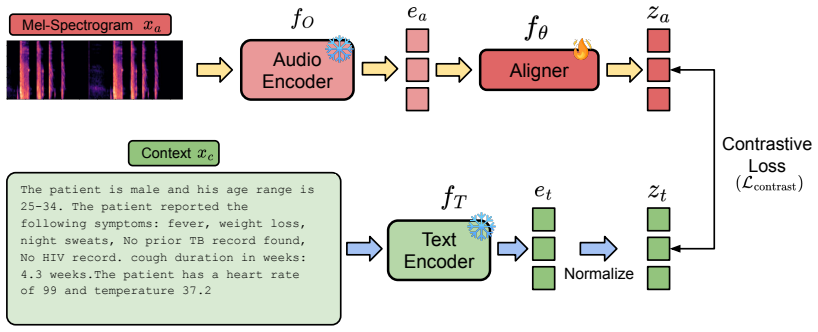
RespiraMFM integrates respiratory sounds with textual clinical information through an effective contrastive alignment strategy, enabling better cross-modal representations that lead to improved performance in identifying five major respiratory diseases across seven real-world datasets.
What carries the argument
The contrastive alignment strategy for audio-text multimodal integration, which learns representations between respiratory sounds and corresponding textual clinical information.
If this is right
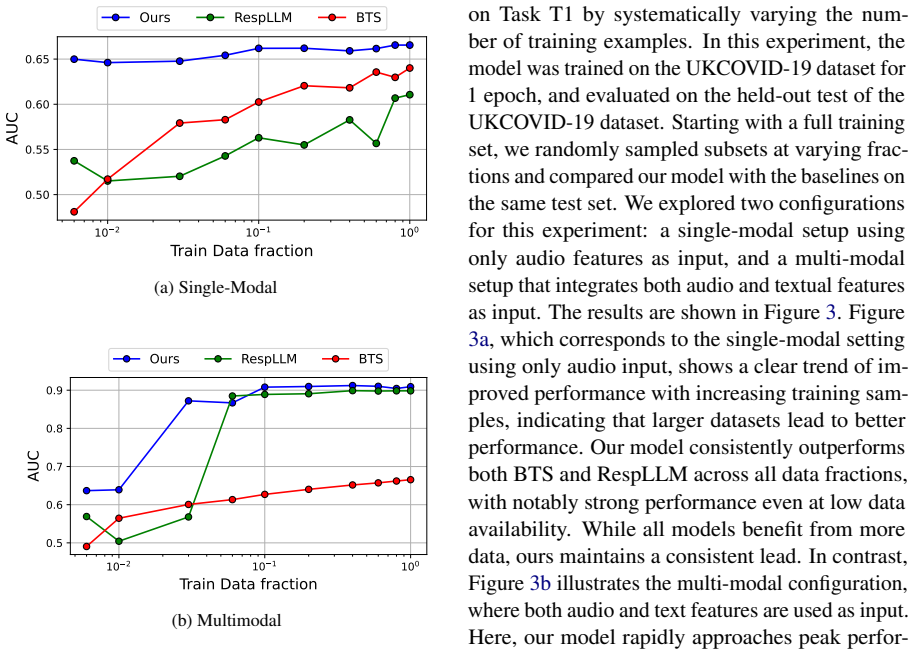
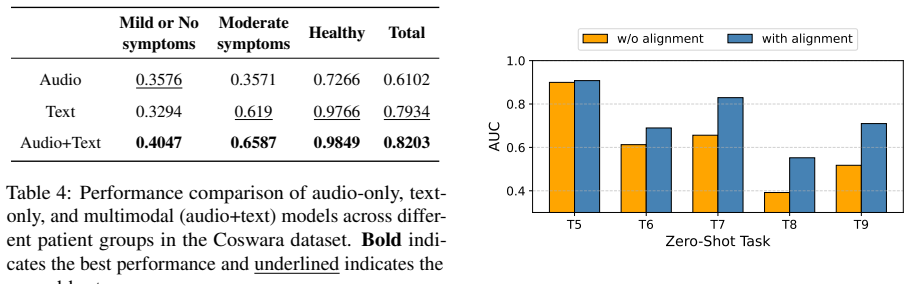
- Yields 9.15% higher AUROC than baselines on supervised fine-tuning tasks for five respiratory diseases.
- Yields 20.98% higher AUROC than baselines on zero-shot tasks across the same diseases.
- Improves generalizability of audio-based detection when textual clinical context is available.
- Supports earlier diagnosis and better clinical decision-making for respiratory conditions.
Where Pith is reading between the lines
- The same alignment technique could be tested on other audio medical signals such as cardiac or neurological sounds.
- Deployment in settings with electronic health records might amplify the zero-shot gains by supplying richer text context.
- Controlled trials that isolate alignment from capacity differences would strengthen causal claims about the mechanism.
Load-bearing premise
The reported AUROC gains result from the contrastive audio-text alignment rather than from differences in model capacity, training details, or dataset choices that were not controlled.
What would settle it
An ablation that removes only the contrastive alignment module, keeps model size and training data fixed, and measures whether the 9.15% supervised and 20.98% zero-shot AUROC gains disappear.
Figures
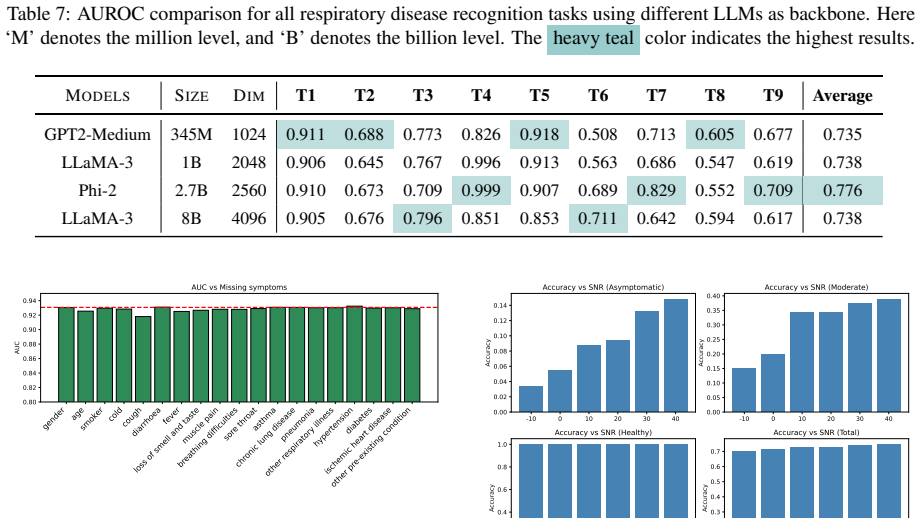
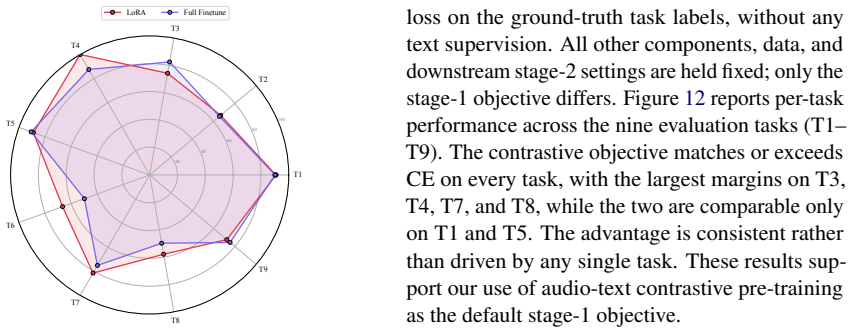
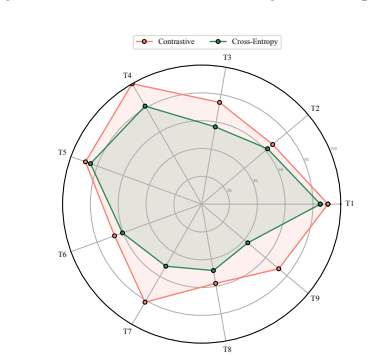
read the original abstract
Respiratory diseases remain a leading cause of global mortality, where timely and accurate diagnosis is critical to improving patient outcomes and reducing healthcare burdens. While prior work has explored audio-based models for respiratory disease detection, such unimodal approaches often suffer from limited generalizability and diagnostic precision. In this paper, we propose RespiraMFM, a Multimodal Foundation Model that integrates respiratory sounds with patient medical history and symptoms to enhance diagnostic accuracy and disease detection capabilities. We introduce an effective contrastive alignment strategy for audio-text multimodal integration, allowing the model to learn better cross-modal representations between respiratory sounds and corresponding textual clinical information. We evaluate RespiraMFM across five major respiratory diseases using seven real-world datasets in both supervised fine-tuning and zero-shot settings, achieving a 9.15% improvement in AUROC on supervised tasks and a 20.98% gain on zero-shot tasks over existing baselines. These findings underscore the potential of our framework to advance early diagnosis and improve clinical decision-making in respiratory disease management.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RespiraMFM, a multimodal foundation model that integrates respiratory audio signals with textual patient medical history and symptoms via a contrastive audio-language alignment strategy. It claims evaluation across five respiratory diseases on seven real-world datasets, reporting 9.15% AUROC gains in supervised fine-tuning and 20.98% gains in zero-shot settings relative to existing baselines.
Significance. If the reported AUROC improvements can be causally attributed to the contrastive alignment component after proper controls for model capacity and training procedure, the work would provide evidence that multimodal audio-text representations improve generalizability in respiratory disease detection over unimodal audio baselines.
major comments (2)
- [Abstract] Abstract: The central performance claims (9.15% supervised and 20.98% zero-shot AUROC gains) are stated without any description of the baseline models, their architectures, parameter counts, training data volume, or optimization schedules. This prevents verification that the gains arise from the contrastive alignment rather than uncontrolled differences in model scale or compute.
- [Abstract] Abstract and evaluation description: No information is supplied on statistical testing, dataset characteristics (size, demographics, exclusion criteria), ablation studies isolating the alignment loss, or whether baselines were re-trained under matched conditions. These omissions make the attribution of gains to the proposed method load-bearing and unverifiable from the provided text.
Simulated Author's Rebuttal
We thank the referee for these comments on the clarity of our claims and evaluation. We will revise the abstract and evaluation sections to include the requested details on baselines, controls, datasets, and ablations, ensuring the attribution to contrastive alignment is verifiable.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (9.15% supervised and 20.98% zero-shot AUROC gains) are stated without any description of the baseline models, their architectures, parameter counts, training data volume, or optimization schedules. This prevents verification that the gains arise from the contrastive alignment rather than uncontrolled differences in model scale or compute.
Authors: We agree the abstract should provide this context to support causal attribution. In the revision we will expand the abstract to name the baseline models, note their architectures and approximate parameter counts, state that all models were trained on the same data volumes with matched optimization schedules, and clarify that the reported gains are measured against these controlled baselines. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: No information is supplied on statistical testing, dataset characteristics (size, demographics, exclusion criteria), ablation studies isolating the alignment loss, or whether baselines were re-trained under matched conditions. These omissions make the attribution of gains to the proposed method load-bearing and unverifiable from the provided text.
Authors: We acknowledge these omissions in the current abstract and evaluation description. The revised manuscript will add: (i) results of statistical testing (e.g., paired t-tests or bootstrap confidence intervals on AUROC differences), (ii) explicit dataset sizes, demographics, and exclusion criteria for each of the seven datasets, (iii) ablation studies that isolate the contribution of the contrastive alignment loss, and (iv) explicit confirmation that baselines were re-trained under identical conditions. These additions will be placed in both the abstract and the main evaluation section. revision: yes
Circularity Check
No circularity; empirical claims rest on external datasets and baselines
full rationale
The paper proposes RespiraMFM and reports AUROC gains on seven real-world datasets in supervised and zero-shot settings. No derivation chain, equations, or self-citations are invoked that reduce any reported metric to a fitted input or self-defined quantity by construction. The evaluation uses external benchmarks, satisfying the condition for a self-contained result against independent data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature Machine Intelligence , volume=
Audio-based AI classifiers show no evidence of improved COVID-19 screening over simple symptoms checkers , author=. Nature Machine Intelligence , volume=. 2024 , publisher=
2024
-
[2]
Scientific Data , volume=
Coswara: A respiratory sounds and symptoms dataset for remote screening of SARS-CoV-2 infection , author=. Scientific Data , volume=. 2023 , publisher=
2023
-
[3]
Scientific Data , volume=
The COUGHVID crowdsourcing dataset, a corpus for the study of large-scale cough analysis algorithms , author=. Scientific Data , volume=. 2021 , publisher=
2021
-
[4]
Scientific Data , volume=
a dataset of Solicited Cough Sound for tuberculosis triage testing , author=. Scientific Data , volume=. 2024 , publisher=
2024
-
[5]
Science Advances , volume=
TBscreen: A passive cough classifier for tuberculosis screening with a controlled dataset , author=. Science Advances , volume=. 2024 , publisher=
2024
-
[6]
Physiological measurement , volume=
An open access database for the evaluation of respiratory sound classification algorithms , author=. Physiological measurement , volume=. 2019 , publisher=
2019
-
[7]
Journal of Ambient Intelligence and Humanized Computing , pages=
Recognition of pulmonary diseases from lung sounds using convolutional neural networks and long short-term memory , author=. Journal of Ambient Intelligence and Humanized Computing , pages=. 2022 , publisher=
2022
-
[8]
2017 ieee international conference on acoustics, speech and signal processing (icassp) , pages=
CNN architectures for large-scale audio classification , author=. 2017 ieee international conference on acoustics, speech and signal processing (icassp) , pages=. 2017 , organization=
2017
-
[9]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Clap learning audio concepts from natural language supervision , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[10]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[11]
ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection , author=. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2022 , organization=
2022
-
[12]
arXiv preprint arXiv:2406.16148 , year=
Towards open respiratory acoustic foundation models: Pretraining and benchmarking , author=. arXiv preprint arXiv:2406.16148 , year=
-
[13]
arXiv preprint arXiv:2410.05361 , year=
RespLLM: Unifying Audio and Text with Multimodal LLMs for Generalized Respiratory Health Prediction , author=. arXiv preprint arXiv:2410.05361 , year=
-
[14]
arXiv preprint arXiv:2403.02522 , year=
HeAR--Health Acoustic Representations , author=. arXiv preprint arXiv:2403.02522 , year=
-
[15]
ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Exploring automatic COVID-19 diagnosis via voice and symptoms from crowdsourced data , author=. ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2021 , organization=
2021
-
[16]
arXiv preprint arXiv:2406.06786 , year=
BTS: Bridging Text and Sound Modalities for Metadata-Aided Respiratory Sound Classification , author=. arXiv preprint arXiv:2406.06786 , year=
-
[17]
Proceedings of the 18th ACM international conference on Multimedia , pages=
Opensmile: the munich versatile and fast open-source audio feature extractor , author=. Proceedings of the 18th ACM international conference on Multimedia , pages=
-
[18]
arXiv preprint arXiv:2305.14032 , year=
Patch-mix contrastive learning with audio spectrogram transformer on respiratory sound classification , author=. arXiv preprint arXiv:2305.14032 , year=
-
[19]
ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Whosecough: In-the-wild cougher verification using multitask learning , author=. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2020 , organization=
2020
-
[20]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[21]
Communications medicine , volume=
Making cough count in tuberculosis care , author=. Communications medicine , volume=. 2022 , publisher=
2022
-
[22]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
JAMA internal medicine , volume=
Estimation of excess deaths associated with the COVID-19 pandemic in the United States, March to May 2020 , author=. JAMA internal medicine , volume=. 2020 , publisher=
2020
-
[24]
2024 , publisher=
Global tuberculosis report 2024 , author=. 2024 , publisher=
2024
-
[25]
Journal of medical Internet research , volume=
Diagnostic value of imaging modalities for COVID-19: scoping review , author=. Journal of medical Internet research , volume=. 2020 , publisher=
2020
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Domain Adaptation Explainability & Fairness in AI for Medical Image Analysis: Diagnosis of COVID-19 based on 3-D Chest CT-scans , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Neurocomputing , pages=
Automated detection and forecasting of covid-19 using deep learning techniques: A review , author=. Neurocomputing , pages=. 2024 , publisher=
2024
-
[28]
Nature medicine , volume=
Large language models in medicine , author=. Nature medicine , volume=. 2023 , publisher=
2023
-
[29]
Machine Learning for Health (ML4H) , pages=
Llms accelerate annotation for medical information extraction , author=. Machine Learning for Health (ML4H) , pages=. 2023 , organization=
2023
-
[30]
LoRA: Low-Rank Adaptation of Large Language Models
Lora: Low-rank adaptation of large language models , author=. arXiv preprint arXiv:2106.09685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Adventitious respiratory classification using attentive residual neural networks , author=
-
[32]
, author=
LungRN+ NL: An improved adventitious lung sound classification using non-local block resnet neural network with mixup data augmentation. , author=. Interspeech , pages=
-
[33]
arXiv preprint arXiv:2203.16141 , year=
Example-based explanations with adversarial attacks for respiratory sound analysis , author=. arXiv preprint arXiv:2203.16141 , year=
-
[34]
Nature Medicine , pages=
A generalist vision--language foundation model for diverse biomedical tasks , author=. Nature Medicine , pages=. 2024 , publisher=
2024
-
[35]
Nature Medicine , volume=
Collaboration between clinicians and vision--language models in radiology report generation , author=. Nature Medicine , volume=. 2025 , publisher=
2025
-
[36]
International Journal of Chronic Obstructive Pulmonary Disease , pages=
Current progress of COPD Early detection: key points and novel strategies , author=. International Journal of Chronic Obstructive Pulmonary Disease , pages=. 2023 , publisher=
2023
-
[37]
Respiratory Medicine , volume=
Mortality risk attributable to classification of chronic obstructive pulmonary disease and reduced lung function: a 21-year longitudinal cohort study , author=. Respiratory Medicine , volume=. 2021 , publisher=
2021
-
[38]
Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
2020
-
[39]
International journal of epidemiology , volume=
Reflection on modern methods: Revisiting the area under the ROC Curve , author=. International journal of epidemiology , volume=. 2020 , publisher=
2020
-
[40]
Macaw-llm: Multi-modal language modeling with image, audio, video, and text integration , author=. arXiv preprint arXiv:2306.09093 , year=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Unibind: Llm-augmented unified and balanced representation space to bind them all , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[43]
arXiv preprint arXiv:2508.06895 , year=
BASIC: Boosting Visual Alignment with Intrinsic Refined Embeddings in Multimodal Large Language Models , author=. arXiv preprint arXiv:2508.06895 , year=
-
[44]
An embarrassingly simple approach for LLM with strong ASR capacity,
An embarrassingly simple approach for llm with strong asr capacity , author=. arXiv preprint arXiv:2402.08846 , year=
-
[45]
Qwen2-audio technical report , author=. arXiv preprint arXiv:2407.10759 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
arXiv preprint arXiv:2502.12900 , year=
Soundwave: Less is More for Speech-Text Alignment in LLMs , author=. arXiv preprint arXiv:2502.12900 , year=
-
[47]
ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation , author=. ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2023 , organization=
2023
-
[48]
Textbooks are all you need , author=. arXiv preprint arXiv:2306.11644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Microsoft Research Blog , volume=
Phi-2: The surprising power of small language models , author=. Microsoft Research Blog , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.