Joint Residual Reweighting for Classifier Free Guidance in Flow-Matching Zero-Shot TTS
Pith reviewed 2026-06-25 19:33 UTC · model grok-4.3
The pith
Joint residual reweighting disentangles speaker and joint residuals in CFG to improve speaker similarity in flow-matching zero-shot TTS without hurting text correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
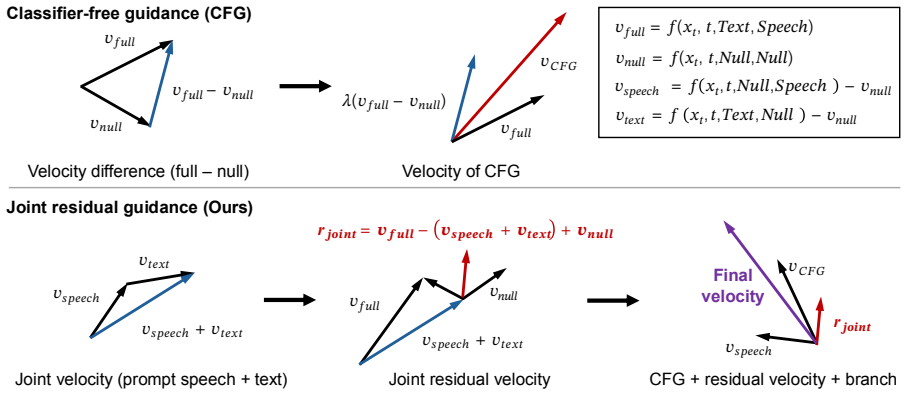
Under independently masked text and speech-prompt conditions, the CFG guidance field decomposes into a text residual, a speaker residual, and a joint residual. Speaker-selective guidance entangles the speaker residual with the joint residual and thereby disturbs text-related generation. Joint residual reweighting lets the speaker residual and the joint residual be scaled separately inside the ordinary CFG framework. On F5-TTS and CosyVoice2 this produces higher speaker similarity while text correctness remains competitive.
What carries the argument
Joint residual reweighting, which scales the speaker residual and the joint residual independently inside the decomposed CFG guidance field.
If this is right
- Speaker similarity rises while text correctness stays competitive on the tested flow-matching TTS models.
- The same reweighting operates inside the existing CFG code without new sampling branches.
- The joint residual itself becomes a tunable knob for trading speaker fidelity against text accuracy.
- The decomposition into text, speaker, and joint residuals applies to any CFG setup that masks conditions independently.
Where Pith is reading between the lines
- The same residual decomposition may be useful in other conditional flow-matching or diffusion tasks that have multiple independent conditions.
- Reweighting the joint term could be tried in image or video generation where prompt and style conditions interact.
- If the joint residual carries cross-condition information, similar reweighting might reduce unwanted leakage in other zero-shot cloning settings.
Load-bearing premise
The observed entanglement between speaker residual and joint residual is the main reason text generation is disturbed and that reweighting the joint residual alone can fix it without creating new problems.
What would settle it
A side-by-side run on F5-TTS or CosyVoice2 in which joint residual reweighting either fails to raise speaker similarity or lowers text correctness relative to standard CFG.
Figures
read the original abstract
Classifier-free guidance (CFG) is widely used in flow-matching-based zero-shot text-to-speech (TTS), where generation is typically controlled by two conditions: the target text and a prompt speech signal. Standard CFG strengthens these conditions jointly, while recent branch-selective guidance methods attempt to enhance text or speaker conditioning separately, often leading to a trade-off between text correctness and speaker similarity. In this paper, we revisit the CFG under independently masked text and speech-prompt conditions, and decompose the guidance field into text, speaker, and joint residuals. We show that conventional speaker-selective guidance entangles the speaker residual with the joint residual, which may disturb text-related generation. Based on this observation, we propose joint residual reweighting, which independently controls the speaker and joint residuals within the standard CFG framework. Experiments on F5-TTS and CosyVoice2 show that the proposed method improves speaker similarity while maintaining competitive text correctness, demonstrating the usefulness of the joint residual for balancing speaker fidelity and text accuracy in zero-shot TTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes joint residual reweighting for classifier-free guidance (CFG) in flow-matching zero-shot TTS. It decomposes the guidance field into text, speaker, and joint residuals under independently masked text and speech-prompt conditions, observes that conventional speaker-selective guidance entangles the speaker residual with the joint residual (potentially disturbing text generation), and introduces reweighting of the joint residual to independently control speaker and joint components. Experiments on F5-TTS and CosyVoice2 are reported to show improved speaker similarity while maintaining competitive text correctness.
Significance. If the reported improvements hold under fuller experimental scrutiny, the work supplies a lightweight, training-free adjustment to standard CFG that directly addresses an observed entanglement in branch-selective guidance. This is a practical contribution for flow-matching TTS pipelines, as it operates within the existing CFG framework and requires no new model components or retraining.
minor comments (3)
- [Abstract] Abstract: the claim of improved speaker similarity and competitive text correctness is stated without naming the concrete metrics (e.g., speaker embedding cosine similarity, WER/CER), the exact baselines (standard CFG, prior branch-selective methods), or any statistical details such as number of runs or significance tests.
- The manuscript does not describe how the test utterances or prompt conditions were selected for the F5-TTS and CosyVoice2 evaluations; a short statement on dataset construction and prompt diversity would clarify the scope of the reported gains.
- Notation for the decomposed residuals (text, speaker, joint) is introduced in the abstract but the precise mathematical definitions and the reweighting formula are not shown; including these equations early would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive recommendation of minor revision. The referee's summary accurately captures the core contribution of decomposing CFG into text, speaker, and joint residuals and introducing joint residual reweighting to address entanglement in branch-selective guidance. We are pleased that the work is recognized as a lightweight, training-free adjustment within the existing CFG framework.
Circularity Check
No significant circularity; empirical engineering adjustment
full rationale
The paper proposes joint residual reweighting as an empirical adjustment to CFG in flow-matching TTS. It decomposes the guidance field into text/speaker/joint residuals under independent masking and reweights the joint residual to address observed entanglement. No equations, derivations, or self-citations are presented that reduce the claimed improvement to a fitted quantity or input by construction. The central claim rests on direct experimental results on F5-TTS and CosyVoice2 rather than any self-referential mathematical reduction. This is the most common honest finding for an applied methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen et al., “F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 6255–6271
2025
-
[2]
E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts,
S. E. Eskimez et al., “E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts,” in2024 IEEE spoken language technology workshop (SLT), IEEE, 2024, pp. 682–689
2024
-
[3]
Cross-lingual f5-tts: Towards language- agnostic voice cloning and speech synthesis,
Q. Liu et al., “Cross-lingual f5-tts: Towards language- agnostic voice cloning and speech synthesis,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2026, pp. 17 362–17 366
2026
-
[4]
Eftts: Zero-shot emotional speech synthesis via conditional flow matching and self-supervised representations,
H. Wang, J. Chen, J. Li, S. Shan, and Y . Wang, “Eftts: Zero-shot emotional speech synthesis via conditional flow matching and self-supervised representations,” in 2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), IEEE, 2025, pp. 795–800
2025
-
[5]
Selective classifier-free guid- ance for zero-shot text-to-speech,
J. Zheng and F. Maleki, “Selective classifier-free guid- ance for zero-shot text-to-speech,” 2025.DOI: 10.48550/ arXiv.2509.19668 arXiv: 2509.19668
arXiv 2025
-
[6]
Dualspeech: Enhancing speaker-fidelity and text-intelligibility through dual classifier-free guidance,
J. Yang, J. Lee, H.-S. Choi, S. Ji, H. Kim, and J. Lee, “Dualspeech: Enhancing speaker-fidelity and text-intelligibility through dual classifier-free guidance,” 2024
2024
-
[7]
Matcha-tts: A fast tts architecture with condi- tional flow matching,
S. Mehta, R. Tu, J. Beskow, ´E. Sz ´ekely, and G. E. Henter, “Matcha-tts: A fast tts architecture with condi- tional flow matching,” inICASSP 2024-2024 IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2024, pp. 11 341–11 345
2024
-
[8]
Cosyvoice 2: Scalable streaming speech synthesis with large language models,
Z. Du et al., “Cosyvoice 2: Scalable streaming speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
Pith/arXiv arXiv 2024
-
[9]
Unsupervised single-channel audio sep- aration with diffusion source priors,
R. Shi et al., “Unsupervised single-channel audio sep- aration with diffusion source priors,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, 2026, pp. 25 348–25 356.DOI: 10 . 1609 / aaai . v40i30 . 39728
2026
-
[10]
Seed-tts: A family of high-quality versatile speech generation models,
P. Anastassiou et al., “Seed-tts: A family of high-quality versatile speech generation models,”arXiv preprint arXiv:2406.02430, 2024
Pith/arXiv arXiv 2024
-
[11]
Megatts 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthe- sis,
Z. Jiang et al., “Megatts 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthe- sis,”arXiv preprint arXiv:2502.18924, 2025
arXiv 2025
-
[12]
Dmp-tts: Disentangled multi-modal prompting for controllable text-to-speech with chained guidance,
K. Yin et al., “Dmp-tts: Disentangled multi-modal prompting for controllable text-to-speech with chained guidance,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2026, pp. 16 477–16 481
2026
-
[13]
Restyle-tts: Relative and continuous style con- trol for zero-shot speech synthesis,
H. Li, C. Jin, C. Li, W. Guan, Z. Huang, and X. Chen, “Restyle-tts: Relative and continuous style con- trol for zero-shot speech synthesis,”arXiv preprint arXiv:2601.03632, 2026
Pith/arXiv arXiv 2026
-
[14]
V oiceldm: Text-to-speech with environmental context,
Y . Lee, I. Yeon, J. Nam, and J. S. Chung, “V oiceldm: Text-to-speech with environmental context,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2024, pp. 12 566–12 571
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.