Minority Sentinel: When to Overturn Majority Voting in Multi-Agent LLM Debates
Pith reviewed 2026-06-30 02:21 UTC · model grok-4.3
The pith
A lightweight classifier can overturn majority votes in LLM debates when the minority answer is correct by reading behavioral signals in the logs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
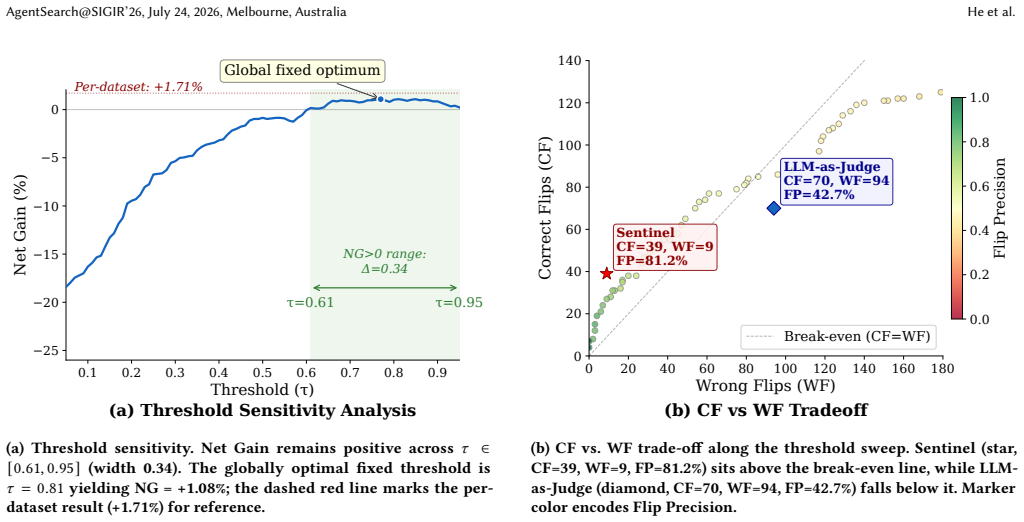
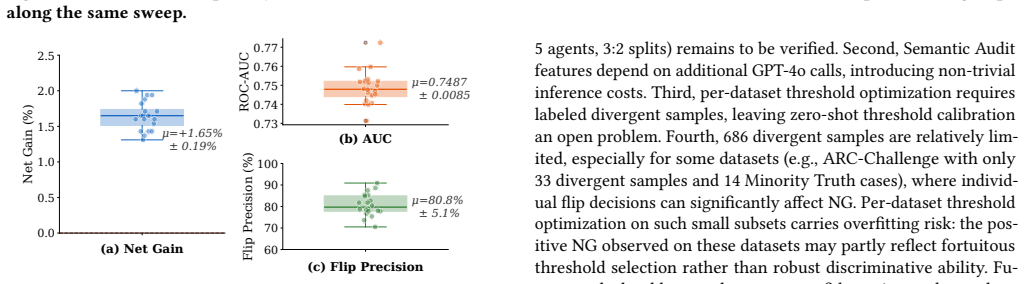
The paper claims that debate logs from three heterogeneous LLM agents contain sufficient behavioral signals for a LightGBM classifier trained on multi-dimensional debate fingerprints to identify cases where the minority answer is correct, achieving a stable 81.2 percent flip precision and positive net gain across all six benchmarks and all 20 random seed trials while avoiding the accuracy degradation seen with LLM-as-Judge baselines.
What carries the argument
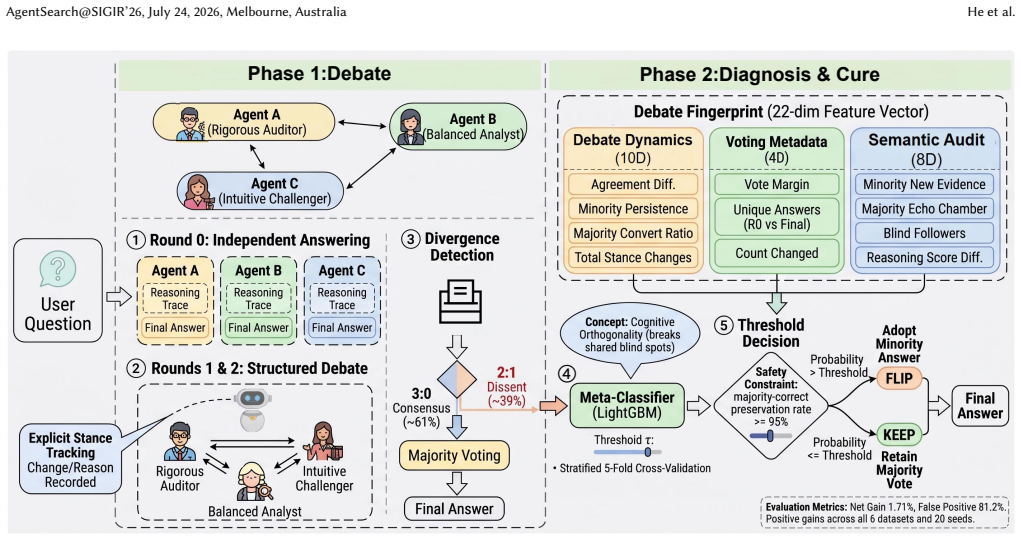
The multi-dimensional debate fingerprint extracted from debate logs, which LightGBM uses to predict when overturning the majority vote will recover a correct minority answer.
If this is right
- Selective overturns based on the classifier improve overall system accuracy without changing the base LLMs or adding more agents.
- Behavioral signals in the logs support safer flips than asking another LLM to judge the debate.
- The positive net gain holds across all tested datasets and random seeds, indicating stability of the signals.
- Roughly one in four divergent cases offers a recoverable minority truth that majority voting otherwise suppresses.
Where Pith is reading between the lines
- The same fingerprint approach could be tested on debates involving more than three agents to check whether disagreement patterns remain informative.
- Explicit logging of agent disagreement trajectories might eventually replace simple majority voting in multi-agent systems.
- Extending the method to open-ended or long-form tasks would test whether the behavioral signals generalize beyond the six benchmarks used here.
Load-bearing premise
The behavioral signals recorded in the debate logs are consistent enough that a LightGBM model trained on the six benchmarks will continue to produce high flip precision and positive net gain on new data.
What would settle it
Applying the trained Minority Sentinel to a fresh set of benchmarks or different LLMs and observing flip precision below 60 percent or negative net gain would show that the signals are not sufficient or generalizable.
Figures
read the original abstract
Multi-Agent Debate (MAD) with Majority Voting is a dominant paradigm for improving LLM reasoning, yet its effectiveness rests on the Condorcet Jury Theorem's assumption of independent errors. Because contemporary LLMs share similar pretraining corpora, their errors are strongly correlated, causing the majority to systematically suppress correct minority opinions, a phenomenon we term Minority Truth. Through debates among three heterogeneous LLM agents on six benchmarks, we find that roughly one in four divergent cases has the minority holding the correct answer, yielding a 10-percentage-point theoretical recovery margin. We propose Minority Sentinel, a lightweight meta-classifier that extracts a multi-dimensional debate fingerprint from debate logs and trains a LightGBM model to decide when to overturn majority voting. Minority Sentinel achieves a stable Flip Precision of 81.2% with positive Net Gain across all six datasets and all 20 random seed trials, demonstrating that debate logs contain sufficient behavioral signals for a non-LLM classifier to reliably recover suppressed minorities without degrading system accuracy. The LLM-as-Judge baseline yields negative Net Gain despite higher recall, confirming that flip safety, not recovery volume, determines intervention value.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies that majority voting in three-agent LLM debates systematically suppresses correct minority answers (Minority Truth) in roughly 25% of divergent cases across six benchmarks, creating a 10pp recovery margin. It introduces Minority Sentinel, a LightGBM meta-classifier trained on multi-dimensional debate fingerprints extracted from logs, which decides when to flip the majority vote. The method reports 81.2% flip precision and positive net gain on all datasets and all 20 random seeds, while an LLM-as-judge baseline yields negative net gain despite higher recall.
Significance. If the generalization claim holds, the work supplies concrete evidence that lightweight, non-LLM classifiers can recover suppressed correct answers from behavioral signals in debate logs, improving MAD accuracy without extra LLM inference cost. The consistent positive net gain across seeds and the direct comparison to LLM-as-judge baselines are notable strengths; the approach is falsifiable via the reported flip-precision and net-gain metrics.
major comments (2)
- [Experimental Evaluation / Results] Experimental section (implicit in abstract and results): training and test splits are performed within the same six benchmarks without reported leave-one-benchmark-out or external-task validation. This setup risks the LightGBM model capturing benchmark-specific response patterns or task formats rather than domain-agnostic debate signals, which directly weakens the claim that the fingerprint enables reliable recovery 'in general MAD settings.'
- [Results / Net Gain] § on Net Gain calculation: the definition of net gain and the precise weighting of false-positive flips versus true-positive recoveries are not fully specified, making it impossible to verify that the reported positive net gain is robust to alternative cost assumptions or to confirm it is not an artifact of post-hoc threshold selection on the same data.
minor comments (2)
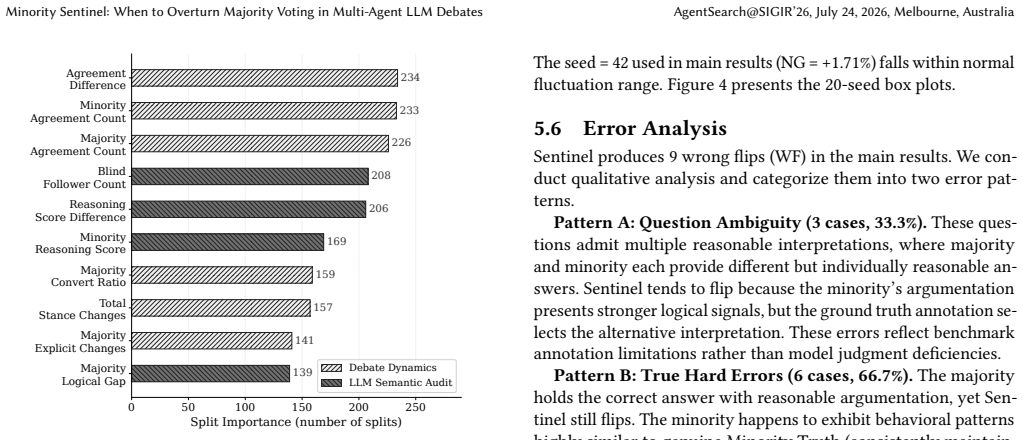
- [Method] The multi-dimensional fingerprint features are described at a high level; an explicit list or table of the features used (e.g., token entropy, agreement ratios, response length) would improve reproducibility.
- [Figures] Figure captions and axis labels for the flip-precision and net-gain plots should include the exact number of trials (20 seeds) and confidence intervals to allow readers to assess stability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Experimental section (implicit in abstract and results): training and test splits are performed within the same six benchmarks without reported leave-one-benchmark-out or external-task validation. This setup risks the LightGBM model capturing benchmark-specific response patterns or task formats rather than domain-agnostic debate signals, which directly weakens the claim that the fingerprint enables reliable recovery 'in general MAD settings.'
Authors: We agree that the current within-benchmark splits limit the strength of the generalization claim. In the revised version we will add leave-one-benchmark-out experiments (training on five benchmarks and evaluating on the held-out benchmark) together with a summary of performance variance across folds. These additional results will be reported in a new subsection of the experimental evaluation. revision: yes
-
Referee: § on Net Gain calculation: the definition of net gain and the precise weighting of false-positive flips versus true-positive recoveries are not fully specified, making it impossible to verify that the reported positive net gain is robust to alternative cost assumptions or to confirm it is not an artifact of post-hoc threshold selection on the same data.
Authors: We accept that the net-gain definition and weighting require explicit formalization. The revised manuscript will include the exact formula (net gain = TP recoveries imes benefit − FP flips imes cost) with the default 1:1 cost ratio, a sensitivity table for alternative ratios (1:2 and 2:1), and confirmation that the positive net gain remains stable under these weightings. We will also state that the threshold was selected via cross-validation on the training folds only. revision: yes
Circularity Check
No significant circularity; empirical metrics are measured outcomes
full rationale
The paper's core claim rests on experimental results: a LightGBM meta-classifier is trained on debate fingerprints extracted from logs generated by three LLMs across six benchmarks, then evaluated for Flip Precision (81.2%) and Net Gain. These quantities are reported as observed performance across datasets and random seeds, not quantities defined in terms of themselves or forced by construction from fitted parameters. No equations, self-citations, ansatzes, or uniqueness theorems are invoked to derive the result; the demonstration that 'debate logs contain sufficient behavioral signals' is an empirical finding rather than a self-referential reduction. Potential issues of train/eval overlap on the same benchmarks affect generalization validity but do not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (1)
- LightGBM model parameters
axioms (1)
- domain assumption Contemporary LLMs share similar pretraining corpora leading to strongly correlated errors
invented entities (1)
-
Minority Truth
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rui Ai, Yuqi Pan, David Simchi-Levi, Milind Tambe, and Haifeng Xu. 2025. Beyond Majority Voting: LLM Aggregation by Leveraging Higher-Order Information. arXiv preprint arXiv:2510.01499(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2024. ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate. InProceedings of the 12th International Conference on Learning Representations (ICLR)
2024
-
[3]
Chia-Yuan Chang, Zhimeng Jiang, Vineeth Rakesh, Menghai Pan, Chin- Chia Michael Yeh, Guanchu Wang, Mingzhi Hu, Zhichao Xu, Yan Zheng, Ma- hashweta Das, and Na Zou. 2025. MAIN-RAG: Multi-Agent Filtering Retrieval- Augmented Generation. InProceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics (ACL). 2607–2622
2025
-
[4]
Hyeong Kyu Choi, Xiaojin Zhu, and Sharon Li. 2025. Debate or Vote: Which Yields Better Decisions in Multi-Agent Large Language Models?. InAdvances in Neural Information Processing Systems (NeurIPS)
2025
-
[5]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think You Have Solved Question Answer- ing? Try ARC, the AI2 Reasoning Challenge.arXiv preprint arXiv:1803.05457 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Tenenbaum, and Igor Mor- datch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mor- datch. 2024. Improving Factuality and Reasoning in Language Models through Multiagent Debate. InProceedings of the 41st International Conference on Machine Learning (ICML)
2024
-
[8]
Andrew Estornell and Yang Liu. 2024. Multi-LLM Debate: Framework, Princi- ples, and Interventions. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[9]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Un- derstanding. InProceedings of the 9th International Conference on Learning Repre- sentations (ICLR)
2021
-
[10]
Tianyu Hu, Zixiang Tan, Shuaiqi Wang, Huiying Qu, and Tianyi Chen. 2025. Multi- Agent Debate for LLM Judges with Adaptive Stability Detection. InAdvances in Neural Information Processing Systems (NeurIPS)
2025
-
[11]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 30. 3146–3154
2017
-
[12]
Elliot Kim, Avi Garg, Kenny Peng, and Nikhil Garg. 2025. Correlated Errors in Large Language Models. InProceedings of the 42nd International Conference on Machine Learning (ICML)
2025
-
[13]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP). 17889–17904
2024
-
[14]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. Let’s Verify Step by Step. InProceedings of the 12th International Conference on Learning Representations (ICLR)
2024
-
[15]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. TruthfulQA: Measuring How Models Mimic Human Falsehoods. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL). 3214–3252
2022
-
[16]
1976.Social Influence and Social Change
Serge Moscovici. 1976.Social Influence and Social Change. Academic Press, London
1976
-
[17]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. WinoGrande: An Adversarial Winograd Schema Challenge at Scale.Commun. ACM64, 9 (2021), 99–106
2021
-
[18]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. Com- monsenseQA: A Question Answering Challenge Targeting World Knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)
2019
-
[19]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InProceedings of the 11th International Conference on Learning Representations (ICLR)
2023
- [20]
-
[21]
Wei Yang, Shixuan Li, Heng Ping, Peiyu Zhang, Paul Bogdan, and Jesse Thomason
- [22]
-
[23]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36. 46595–46623. A Prompt Templates This appendix ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.