HYPIC: Accelerating Hybrid-Attention LLM Serving with Position-Independent Caching
Pith reviewed 2026-07-03 18:50 UTC · model grok-4.3
The pith
Hypic lets hybrid-attention LLMs reuse cached segments across requests by composing linear-layer states with a transition operator and fixing full-attention boundaries with small seam recomputes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
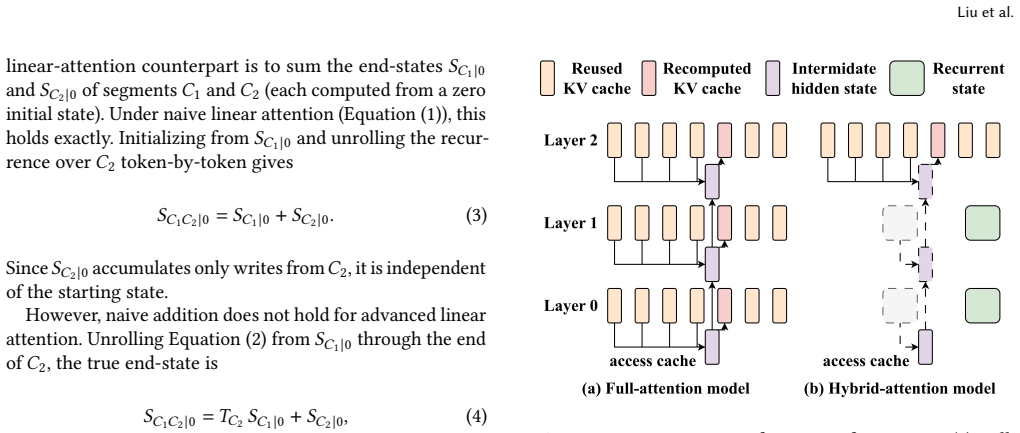
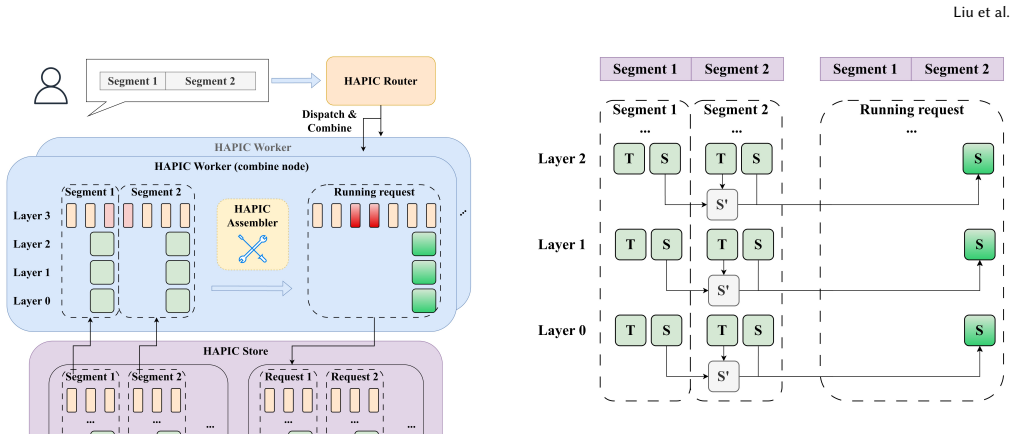
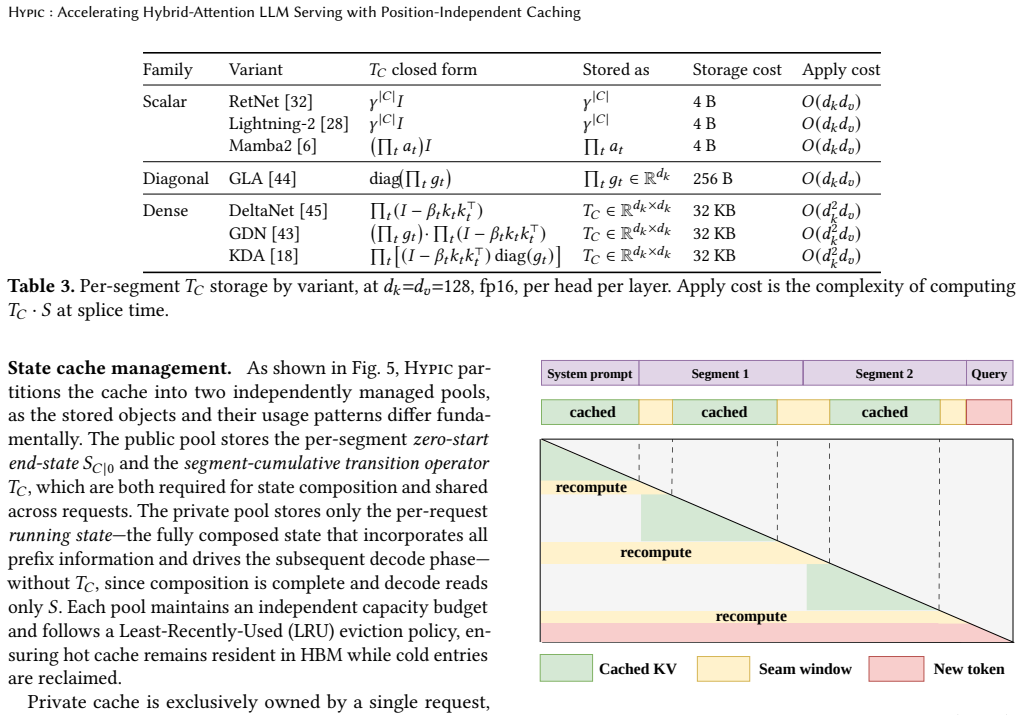
Hypic is the first serving system for hybrid-attention LLMs that supports position-independent caching. For linear-attention layers it caches the segment-cumulative transition operator together with each segment's zero-start end-state, allowing near-exact constant-time composition of independently stored segments. For the remaining full-attention layers it recomputes only a small seam window at each segment boundary to recover cross-segment lookback accuracy. Segment-level self-containment is further used to parallelize cache-miss prefill across instances.
What carries the argument
The segment-cumulative transition operator, the algebraic primitive that enables constant-time state composition of independently cached segments in linear-attention layers.
If this is right
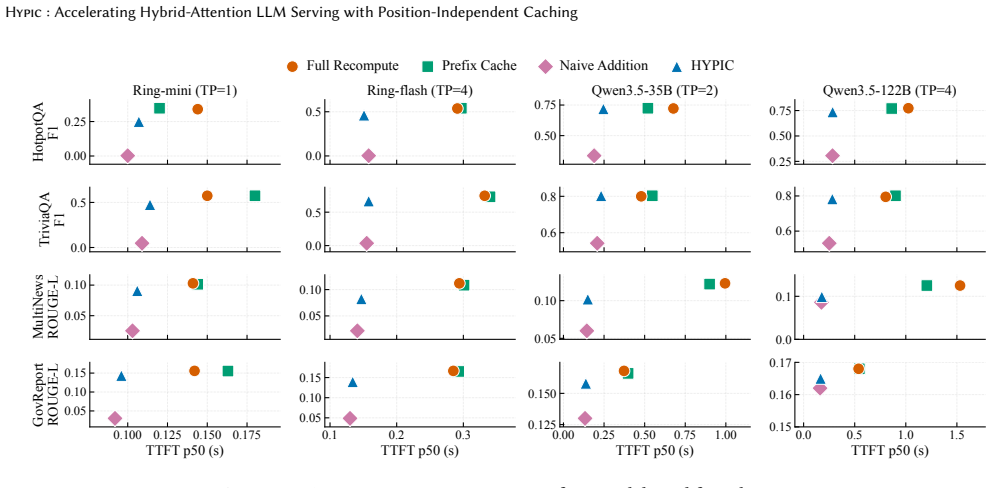
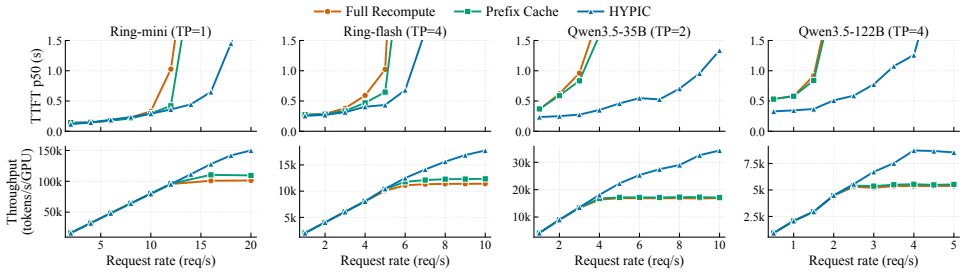
- Time-to-first-token drops 2.45x on average across tested workloads.
- Peak throughput rises by up to 2.0x while accuracy remains within 3.3 points of full recompute.
- Long cold requests become accelerable by parallel prefill across instances.
- The approach applies to four different hybrid-attention models and five workloads.
Where Pith is reading between the lines
- The same seam-window idea might reduce recompute cost in other mixed-attention or state-space models that lack per-token states.
- Segment self-containment could be leveraged for dynamic load balancing across serving clusters when requests share many segments.
- The transition operator might allow incremental updates when a cached segment is later extended rather than replaced.
Load-bearing premise
Recomputing only a small seam window at each segment boundary restores enough cross-segment lookback accuracy in full-attention layers without per-token hidden states from the linear layers.
What would settle it
Measure accuracy on a multi-segment prompt workload when the seam window size is forced to zero versus the paper's chosen window size, and compare both to full recompute.
Figures





read the original abstract
In retrieval augmented generation (RAG) and agentic LLM serving, prompts are assembled from independent segments into long contexts, making the prefill stage dominate the per-request computation cost. To this cost, two directions have emerged in parallel: position-independent caching (PIC) admits KV reuse for non-contiguous segments shared across different requests, while hybrid-attention models reduce computation complexity by replacing most full-attention layers with linear attention. However, they cannot coexist: applying PIC to hybrid-attention models breaks down because per-token KV-cache reuse primitives do not transfer to the per-request recurrent state. In this work, we present Hypic, the first serving system for hybrid-attention LLMs with position-independent caching. For linear-attention layers, we identify the segment-cumulative transition operator as the missing algebraic primitive, and cache it alongside each segment's zero-start end-state, enabling near-exact and constant-time state composition of independently cached segments. For the remaining full-attention layers, existing PIC methods also fail as linear layers do not expose the per-token hidden states for selective recomputation. We show that the most significant attention deviation concentrates at segment boundaries, so recomputing only a small seam window at each boundary suffices to restore cross-segment lookback. Finally, Hypic exploits segment-level self-containment to parallelize cache-miss prefill across instances, turning long cold requests -- a major tail-latency contributor under both prefix caching and prior PIC -- into an accelerable workload. Evaluated across four hybrid-attention models and five workloads, Hypic reduces time-to-first-token (TTFT) by 2.45x on average and improves peak throughput by up to 2.0x over existing systems, while staying within 3.3 points of full-recompute accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HYPIC, a serving system for hybrid-attention LLMs supporting position-independent caching. For linear-attention layers it caches the segment-cumulative transition operator together with each segment's zero-start end-state to enable constant-time composition of independently cached segments. For full-attention layers it recomputes only a small seam window at each segment boundary on the premise that attention deviation concentrates there. Segment self-containment is exploited to parallelize cache-miss prefill. Across four hybrid-attention models and five workloads the system is reported to reduce TTFT by 2.45× on average, improve peak throughput by up to 2.0×, and stay within 3.3 points of full-recompute accuracy.
Significance. If the accuracy and performance numbers hold, the work is significant for RAG and agentic serving workloads that assemble long contexts from non-contiguous segments. The algebraic identification of the segment-cumulative transition operator as a reusable primitive cleanly extends PIC to linear-attention layers; the parallelization of cold requests directly targets tail latency. These contributions are concrete and could influence practical serving-system design.
major comments (2)
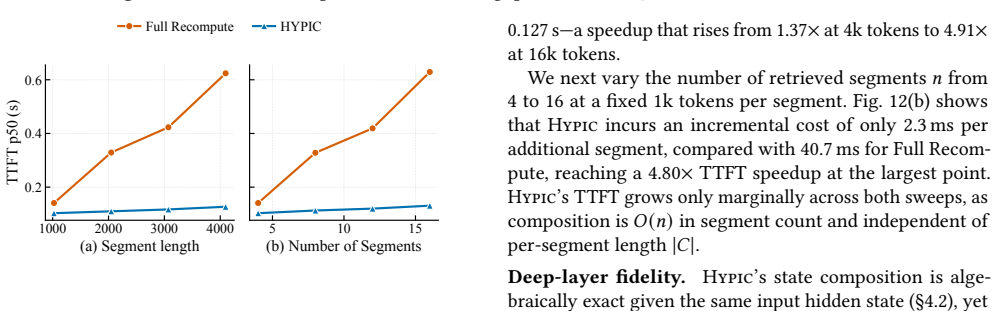
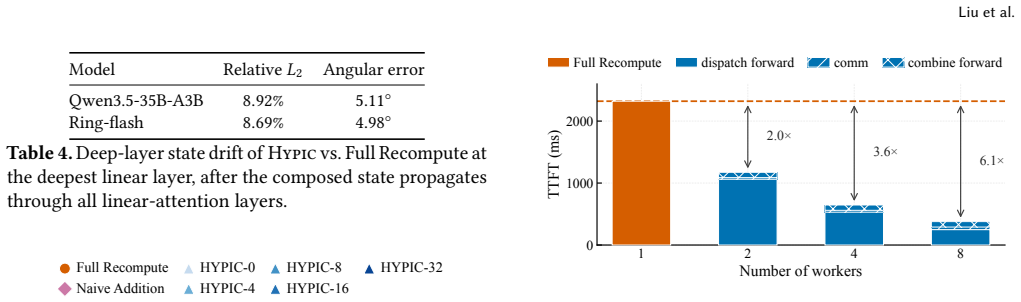
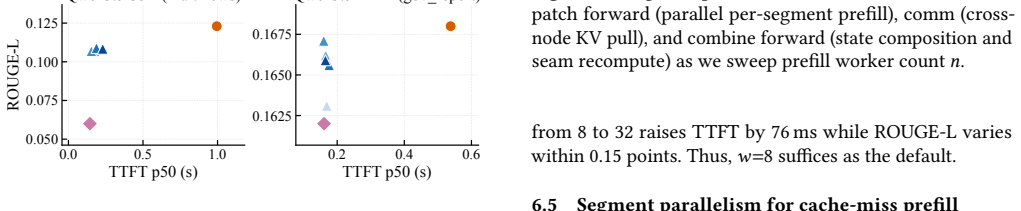
- [Full-attention handling description and accuracy evaluation] The accuracy claim (within 3.3 points of full recompute) rests on the assertion that attention deviation in full-attention layers concentrates at segment boundaries so that a fixed seam window suffices. No quantitative bound on deviation propagation through residual connections, layer stacking, or multi-head interactions is supplied, nor is there a sensitivity study relating seam size to model depth or segment length. This is load-bearing for the central accuracy guarantee.
- [Evaluation section] The reported 2.45× TTFT and 2.0× throughput figures are presented without workload definitions, baseline implementation details, measurement methodology, or statistical significance tests. These omissions prevent verification that the speedups are reproducible and not the result of post-hoc tuning or unstated workload characteristics.
minor comments (1)
- [Linear-attention caching subsection] Notation for the transition operator and zero-start end-state would benefit from an explicit equation or pseudocode block to make the constant-time composition claim immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Full-attention handling description and accuracy evaluation] The accuracy claim (within 3.3 points of full recompute) rests on the assertion that attention deviation in full-attention layers concentrates at segment boundaries so that a fixed seam window suffices. No quantitative bound on deviation propagation through residual connections, layer stacking, or multi-head interactions is supplied, nor is there a sensitivity study relating seam size to model depth or segment length. This is load-bearing for the central accuracy guarantee.
Authors: We agree that the manuscript would be strengthened by a quantitative characterization of deviation propagation. The current work relies on empirical measurements across four hybrid-attention models showing that a fixed seam window keeps accuracy within 3.3 points of full recompute. In the revision we will add a sensitivity study that varies seam-window size against model depth and segment length, reports per-layer deviation statistics, and discusses observed empirical bounds on propagation through residuals and stacking. revision: yes
-
Referee: [Evaluation section] The reported 2.45× TTFT and 2.0× throughput figures are presented without workload definitions, baseline implementation details, measurement methodology, or statistical significance tests. These omissions prevent verification that the speedups are reproducible and not the result of post-hoc tuning or unstated workload characteristics.
Authors: We acknowledge that additional detail is needed for reproducibility. The manuscript already names the four models and five workloads, but the revision will expand the evaluation section with explicit workload definitions (segment counts, lengths, and composition), baseline system configurations and code references, complete measurement methodology (hardware, software stack, timing methodology), and statistical reporting (means and standard deviations over repeated runs). revision: yes
Circularity Check
No circularity; empirical measurements independent of inputs
full rationale
The paper is a systems contribution presenting an implementation (Hypic) and its measured performance on four models and five workloads. No equations, algebraic derivations, fitted parameters, or predictions appear in the abstract or description. TTFT and throughput gains are reported as direct experimental outcomes, and the accuracy delta is an empirical comparison to full-recompute rather than a quantity obtained by construction from any input or self-citation. The seam-window claim is presented as an observed property enabling the design, not as a self-defined or fitted result. The derivation chain therefore contains no load-bearing steps that reduce to the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). USENIX Association, 117–134
2024
-
[2]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhid- ian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al
-
[3]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics
LongBench: A Bilingual, Multitask Benchmark for Long Con- text Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 3119–3137
-
[4]
Ziyi Cao, Qingsi Si, Jingbin Zhang, and Bingquan Liu. 2026. Sparse Attention Across Multiple-Context KV Cache. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 30165–30173. doi:10. 1609/aaai.v40i36.40266
2026
-
[5]
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. 2025. MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention.arXiv preprint arXiv:2506.13585
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Bing Li, and Ulf Schlichtmann. 2026. KV Packet: Recomputation-Free Context- Independent KV Caching for LLMs. arXiv:2604.13226 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Tri Dao and Albert Gu. 2024. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Du- ality. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, 10041–10071
2024
-
[8]
Alexander Richard Fabbri, Irene Li, Tianwei She, Suyi Li, and Dragomir Radev. 2019. Multi-News: A Large-Scale Multi-Document Summariza- tion Dataset and Abstractive Hierarchical Model. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 1074–1084
2019
-
[9]
In Gim, Guojun Chen, Seung-Seob Lee, Nikhil Sarda, Anurag Khandel- wal, and Lin Zhong. 2024. Prompt Cache: Modular Attention Reuse for Low-Latency Inference. InProceedings of Machine Learning and Systems, Vol. 6
2024
-
[10]
Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and Aleksander Wawer
-
[11]
InProceedings of the 2nd Workshop on New Frontiers in Summarization (EMNLP-IJCNLP 2019 Workshop)
SAMSum Corpus: A Human-Annotated Dialogue Dataset for Abstractive Summarization. InProceedings of the 2nd Workshop on New Frontiers in Summarization (EMNLP-IJCNLP 2019 Workshop). 70–79
2019
-
[12]
Chuanxiong Guo, Haitao Wu, Zhong Deng, Gaurav Soni, Jianxi Ye, Jitendra Padhye, and Marina Lipshteyn. 2016. RDMA over Commodity Ethernet at Scale. InProceedings of the ACM SIGCOMM Conference. 202–215. doi:10.1145/2934872.2934908
-
[13]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a Multi-hop QA Dataset for Compre- hensive Evaluation of Reasoning Steps. InProceedings of the 28th International Conference on Computational Linguistics. 6609–6625
2020
-
[14]
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie
-
[15]
InProceedings of the 42nd International Confer- ence on Machine Learning (Proceedings of Machine Learning Research, Vol
EPIC: Efficient Position-Independent Caching for Serving Large Language Models. InProceedings of the 42nd International Confer- ence on Machine Learning (Proceedings of Machine Learning Research, Vol. 267). PMLR, 24391–24402
-
[16]
Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, and Lu Wang. 2021. Efficient Attentions for Long Document Summarization. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics. 1419–1436
2021
-
[17]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. Swe-bench: Can language models resolve real-world github issues?. InInternational Conference on Learning Representations, Vol. 2024. 54107–54157
2024
-
[18]
Weld, and Luke Zettlemoyer
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer
-
[19]
InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vol
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vol. 1. 1601–1611
-
[20]
Fu, Christo- pher Ré, and Azalia Mirhoseini
Jordan Juravsky, Bradley Brown, Ryan Ehrlich, Daniel Y. Fu, Christo- pher Ré, and Azalia Mirhoseini. 2024. Hydragen: High-Throughput LLM Inference with Shared Prefixes. InProceedings of the 41st Interna- tional Conference on Machine Learning (ICML ’24)
2024
-
[21]
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. 2020. Transformers are RNNs: Fast Autoregressive Trans- formers with Linear Attention. InProceedings of the 37th International Conference on Machine Learning (ICML)
2020
-
[22]
Kimi Team. 2025. Kimi Linear: An Expressive, Efficient Attention Architecture. arXiv:2510.26692 [cs.CL]https://arxiv.org/abs/2510. 26692
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[24]
InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP ’23)
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP ’23). ACM, 611–626
-
[25]
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, et al . 2024. Jamba: A hybrid transformer-mamba language model.arXiv preprint arXiv:2403.19887(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. 74–81
2004
-
[27]
Yang Liu, Yunfei Gu, Liqiang Zhang, Chentao Wu, Guangtao Xue, Jie Li, Minyi Guo, Junhao Hu, and Jie Meng. 2026. CacheSlide: Unlocking Cross Position-Aware KV Cache Reuse for Accelerating LLM Serv- ing. InProceedings of the 24th USENIX Conference on File and Storage Technologies (FAST ’26). USENIX Association, 83–99
2026
-
[28]
Songshuo Lu, Hua Wang, Yutian Rong, Zhi Chen, and Yaohua Tang
-
[29]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
TurboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 6588–6601. doi:10.18653/v1/2025.emnlp-main.334
-
[30]
Dongyang Ma, Yan Wang, and Tian Lan. 2025. Block-Attention for Effi- cient Prefilling. InThe Thirteenth International Conference on Learning Representations
2025
-
[31]
2024.NCCL: NVIDIA Collective Communications Library
NVIDIA. 2024.NCCL: NVIDIA Collective Communications Library. https://github.com/NVIDIA/nccl
2024
-
[32]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. InProceedings of the 51st Annual International Symposium on Computer Architecture (ISCA ’24). IEEE, 118–132
2024
-
[33]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Minxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading More Storage for Less Computation – A KVCache-Centric Architecture for Serving LLM Chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST ’25). USENIX Association
2025
- [34]
-
[35]
Qwen Team. 2026. Qwen3.5: Towards Native Multimodal Agents. Qwen Technical Blog.https://qwen.ai/blog?id=qwen3.5 13 Liu et al
2026
-
[36]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang
-
[37]
InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing
SQuAD: 100,000+ Questions for Machine Comprehension of Text. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2383–2392
2016
-
[38]
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2024. RoFormer: Enhanced Transformer with Rotary Position Embedding.Neurocomputing568 (2024), 127063
2024
-
[39]
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. 2023. Retentive Net- work: A Successor to Transformer for Large Language Models. arXiv:2307.08621 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [40]
-
[41]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. MuSiQue: Multihop Questions via Single-hop Ques- tion Composition.Transactions of the Association for Computational Linguistics10 (2022), 539–554
2022
-
[42]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems, Vol. 30
2017
-
[43]
Jiahao Wang, Weiyu Xie, Mingxing Zhang, Boxing Zhang, Jianwei Dong, Yuening Zhu, Chen Lin, Jinqi Tang, Yaochen Han, Zhiyuan Ai, Xianglin Chen, Yongwei Wu, and Congfeng Jiang. 2026. From Prefix Cache to Fusion RAG Cache: Accelerating LLM Inference in Retrieval- Augmented Generation.Proceedings of the ACM on Management of Data4, 1 (2026). doi:10.1145/3786655
- [44]
- [45]
-
[46]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. InThe Twelfth International Conference on Learning Representa- tions
2024
-
[47]
Bin Yang, Qiuyu Leng, Jun Zeng, and Zhenhua Wu. 2025. CacheClip: Accelerating RAG with Effective KV Cache Reuse. arXiv:2510.10129 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [48]
-
[49]
Jingbo Yang, Bairu Hou, Wei Wei, Yujia Bao, and Shiyu Chang. 2025. KVLink: Accelerating Large Language Models via Efficient KV Cache Reuse. InAdvances in Neural Information Processing Systems, Vol. 38
2025
-
[50]
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. 2025. Gated Delta Networks: Improving Mamba2 with Delta Rule. InThe Thirteenth International Conference on Learning Representations
2025
-
[51]
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. 2024. Gated Linear Attention Transformers with Hardware- Efficient Training. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, 56501–56523
2024
-
[52]
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim
-
[53]
InAdvances in Neural Information Processing Systems, Vol
Parallelizing Linear Transformers with the Delta Rule over Se- quence Length. InAdvances in Neural Information Processing Systems, Vol. 37
-
[54]
2024.FLA: A Triton-Based Library for Hardware-Efficient Implementations of Linear Attention Mechanism
Songlin Yang and Yu Zhang. 2024.FLA: A Triton-Based Library for Hardware-Efficient Implementations of Linear Attention Mechanism. https://github.com/fla-org/flash-linear-attention
2024
-
[55]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2369–2380
2018
-
[56]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowl- edge Fusion. InProceedings of the Twentieth European Conference on Computer Systems (EuroSys ’25). ACM. doi:10.1145/3689031.3696098
-
[57]
Hancheng Ye, Zhengqi Gao, Mingyuan Ma, Qinsi Wang, Yuzhe Fu, Ming-Yu Chung, Yueqian Lin, Zhijian Liu, Jianyi Zhang, Danyang Zhuo, and Yiran Chen. 2025. KVCOMM: Online Cross-context KV Cache Communication for Efficient LLM-based Multi-agent Systems. InAdvances in Neural Information Processing Systems
2025
-
[58]
Lu Ye, Ze Tao, Yong Huang, and Yang Li. 2024. ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 11608–11620
2024
-
[59]
Qingfei Zhao, Ruobing Wang, Yukuo Cen, Daren Zha, Shicheng Tan, Yuxiao Dong, and Jie Tang. 2024. LongRAG: A Dual-Perspective Retrieval-Augmented Generation Paradigm for Long-Context Ques- tion Answering. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 22600–22632
2024
- [60]
-
[61]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Efficient Execution of Structured Language Model Programs. InAdvances in Neural Information Processing Systems
2024
-
[62]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-Optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). USENIX Association, 193–210
2024
- [63]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.