In-Depth Benchmarking of Graph Database Systems with the Linked Data Benchmark Council (LDBC) Social Network Benchmark (SNB)
Pith reviewed 2026-05-24 20:01 UTC · model grok-4.3
The pith
TigerGraph outperforms Neo4j by two or more orders of magnitude on most LDBC SNB queries and alone scales to the largest datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
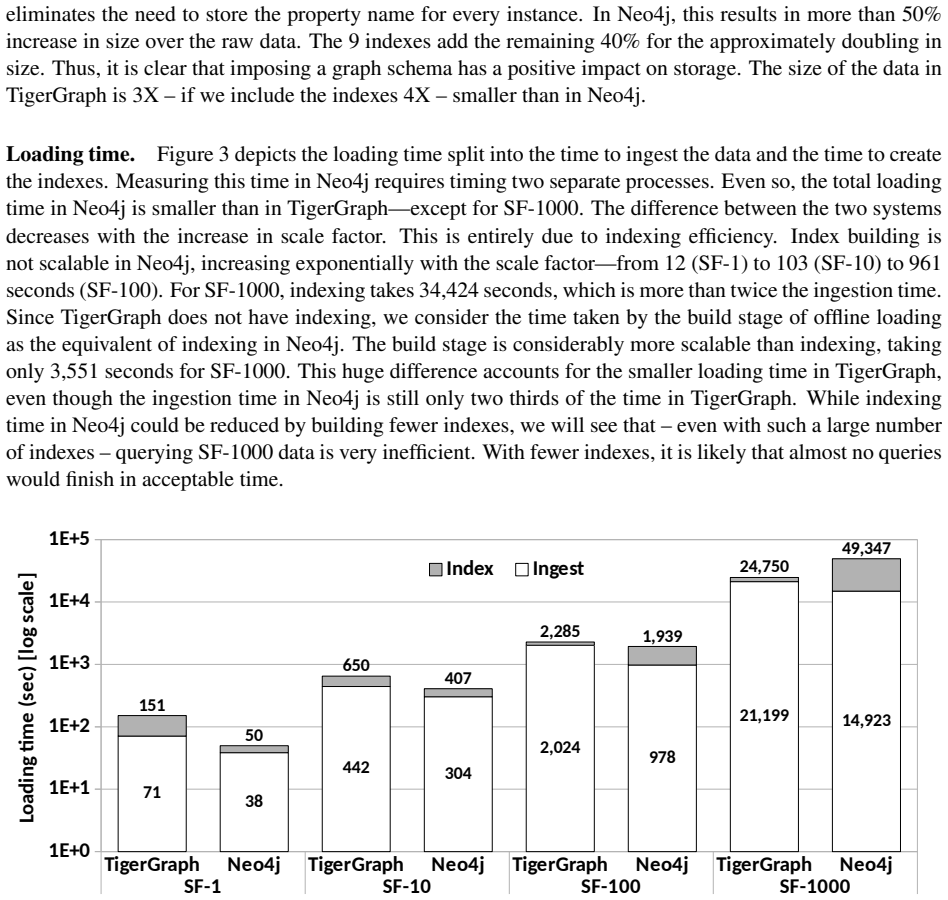
TigerGraph consistently outperforms Neo4j on the majority of the 46 LDBC SNB queries, reaching two or more orders of magnitude on certain interactive complex and business intelligence queries. The gap widens with data size because only TigerGraph finishes the entire SF-1000 workload while Neo4j completes just 12 of the 25 business intelligence queries. Neo4j remains faster at bulk loading up to SF-100. All platforms were tuned with active vendor participation, and the authors release code, scripts, and configuration files for reproducibility.
What carries the argument
Full LDBC SNB benchmark implementation (interactive short, interactive complex, and business intelligence query sets) executed on Neo4j and TigerGraph across scale factors SF-1 to SF-1000.
If this is right
- TigerGraph can be expected to handle social-network workloads at SF-1000 scale where Neo4j cannot complete all queries.
- The relative advantage of TigerGraph increases as dataset size grows from SF-100 to SF-1000.
- Neo4j retains an edge in bulk-loading time for datasets up to SF-100.
- Public release of the tuned configurations and query implementations enables direct reproduction or extension by other users.
Where Pith is reading between the lines
- Removing vendor assistance from the tuning process could alter the observed speed ratios and therefore merits a follow-up neutral study.
- The same benchmark suite could be applied to additional graph engines to produce a broader ranking beyond the two systems tested here.
- Query patterns in the LDBC SNB may appear in domains other than social networks, so the relative rankings could inform choices in fraud detection or recommendation workloads as well.
Load-bearing premise
Active involvement of the vendors in tuning their platforms produces representative and unbiased performance numbers for each system.
What would settle it
An independent execution of the same benchmark using only publicly available default configurations or neutral tuning that yields substantially smaller performance gaps or reverses the ranking.
Figures





read the original abstract
In this study, we present the first results of a complete implementation of the LDBC SNB benchmark -- interactive short, interactive complex, and business intelligence -- in two native graph database systems---Neo4j and TigerGraph. In addition to thoroughly evaluating the performance of all of the 46 queries in the benchmark on four scale factors -- SF-1, SF-10, SF-100, and SF-1000 -- and three computing architectures -- on premise and in the cloud -- we also measure the bulk loading time and storage size. Our results show that TigerGraph is consistently outperforming Neo4j on the majority of the queries---by two or more orders of magnitude (100X factor) on certain interactive complex and business intelligence queries. The gap increases with the size of the data since only TigerGraph is able to scale to SF-1000---Neo4j finishes only 12 of the 25 business intelligence queries in reasonable time. Nonetheless, Neo4j is generally faster at bulk loading graph data up to SF-100. A key to our study is the active involvement of the vendors in the tuning of their platforms. In order to encourage reproducibility, we make all the code, scripts, and configuration parameters publicly available online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports the first complete implementation of the LDBC SNB benchmark (interactive short, interactive complex, and business intelligence queries) on Neo4j and TigerGraph. It measures performance, bulk loading time, and storage across SF-1 to SF-1000 on on-premise and cloud hardware for all 46 queries. The central empirical claims are that TigerGraph outperforms Neo4j on the majority of queries (by two or more orders of magnitude on certain complex and BI queries), scales to SF-1000 while Neo4j completes only 12 of 25 BI queries, and that Neo4j is generally faster at loading up to SF-100. Vendor involvement in tuning is described as a key methodological feature, with all code, scripts, and configurations released publicly.
Significance. If the measured gaps can be attributed to intrinsic engine differences, the work supplies a useful, large-scale empirical comparison on a standard community benchmark. The public release of configurations and scripts is a clear strength that enables reproducibility and independent verification.
major comments (1)
- [Abstract] Abstract: The headline claims (TigerGraph outperforming Neo4j by up to 100X and scaling to SF-1000 while Neo4j does not) are presented as direct comparisons between the two systems. However, these results rest on configurations obtained via 'active involvement of the vendors in the tuning of their platforms,' with no described protocol, time budget, or verification mechanism ensuring equivalent tuning effort. This is load-bearing for the attribution of performance differences to the engines rather than unequal optimization investment.
minor comments (1)
- The manuscript would benefit from an explicit summary table (or figure) listing, for each scale factor, the number of queries completed by each system within the timeout; this would make the scaling claims immediately verifiable without scanning individual result tables.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the strengths in significance and reproducibility. We address the single major comment below and are willing to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims (TigerGraph outperforming Neo4j by up to 100X and scaling to SF-1000 while Neo4j does not) are presented as direct comparisons between the two systems. However, these results rest on configurations obtained via 'active involvement of the vendors in the tuning of their platforms,' with no described protocol, time budget, or verification mechanism ensuring equivalent tuning effort. This is load-bearing for the attribution of performance differences to the engines rather than unequal optimization investment.
Authors: We agree that the manuscript does not describe a formal protocol, time budget, or verification mechanism for the vendor tuning process, and that this detail would help readers assess whether performance gaps reflect engine differences. The paper already stresses public release of all configurations, scripts, and code to support reproducibility and independent verification. In revision we will add a dedicated methods subsection describing the tuning interactions, any time or resource constraints applied, and steps taken to ensure both vendors received comparable opportunity. The abstract claims will be qualified to note that results reflect expert-tuned configurations obtained via vendor involvement. revision: yes
Circularity Check
No circularity: purely empirical benchmark measurements
full rationale
The paper reports direct runtime, loading, and storage measurements obtained by executing the externally-defined LDBC SNB query workload on Neo4j and TigerGraph after vendor-assisted configuration. No equations, fitted parameters, predictions, or derivations appear anywhere in the text; the central claims are observational comparisons against a fixed external benchmark specification. The vendor-tuning detail is a methodological choice whose fairness can be debated, but it does not create any self-referential reduction of the reported numbers to the paper's own inputs. Consequently the derivation chain is empty and the circularity score is 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The LDBC SNB benchmark queries and data generator accurately model real-world social-network workloads.
- domain assumption Vendor-tuned configurations represent the best achievable and comparable performance for each system.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
TigerGraph: A Native MPP Graph Database
A. Deutsch, Y . Xu, M. Wu, and V . Lee. TigerGraph: A Native MPP Graph Database. arXiv:1901.08248, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
- [4]
-
[5]
A. Iosup, T. Hegeman, W.L. Ngai, S. Heldens, A. Prat-Perez, T. Manhardt, H. Chafi, M. Capota, N. Sundaram, M. Anderson, I.G. Tanase, Y . Xia, L. Nai, and P. Boncz. LDBC Graphalytics: A Benchmark for Large-Scale Graph Analysis on Parallel and Distributed Platforms. PVLDB, 9(13), 2016
work page 2016
-
[6]
Y . Low, J. Gonzalez, A. Kyrola, D. Bickson, C. Guestrin, and J. Hellerstein. GraphLab: A New Framework for Parallel Machine Learning. In UAI 2010. 18
work page 2010
-
[7]
G. Malewicz, M. Austern, A. Bik, J. Dehnert, I. Horn, N. Leiser, and G. Czajkowski. Pregel: A System for Large-Scale Graph Processing. In SIGMOD 2010
work page 2010
-
[8]
M. Needham and A.E. Hodler. Graph Algorithms—Practical Examples in Apache Spark and Neo4j. O’Reilly, 2019
work page 2019
- [9]
-
[10]
O. van Rest, S. Hong, J. Kim, X. Meng, and H. Chafi. PGQL: A Property Graph Query Language. In GRADES@SIGMOD 2016
work page 2016
-
[11]
I. Robinson, J. Webber, and E. Eifrem. Graph Databases—New Opportunities for Connected Data, 2nd Edition. O’Reilly, 2015
work page 2015
-
[12]
G. Szarnyas, A. Prat-Perez, A. Averbuch, J. Marton, M. Paradies, M. Kaufmann, O. Erling, P. Boncz, V . Haprian, and J.B. Antal. An Early Look at the LDBC Social Network Benchmark’s Business Intelligence Workload. In GRADES-NDA@SIGMOD 2018
work page 2018
-
[13]
M. Wu. A Property Graph Type System and Data Definition Language. arXiv:1810.08755, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [14]
-
[15]
Apache TinkerPop: The Gremlin Graph Traversal Machine and Language. https://tinkerpop. apache.org/gremlin.html
-
[16]
Z. Huang. LDBC SNB Benchmark. https://github.com/zhuang29/graph_database_ benchmark
- [17]
-
[18]
Linked Data Benchmark Council (LDBC). http://www.ldbcouncil.org/
-
[19]
http://ldbcouncil.org/benchmarks/snb
LDBC Social Network Benchmark (SNB). http://ldbcouncil.org/benchmarks/snb
-
[20]
https://github.com/ldbc/ldbc_snb_datagen
LDBC SNB Data Generator. https://github.com/ldbc/ldbc_snb_datagen
-
[21]
https://github.com/ldbc/ldbc_snb_docs
LDBC SNB Documentation. https://github.com/ldbc/ldbc_snb_docs
-
[22]
https://github.com/ldbc/ldbc_snb_ implementations
LDBC SNB Implementations. https://github.com/ldbc/ldbc_snb_ implementations
- [23]
-
[24]
https://neo4j.com/developer/ cypher-query-language/
Neo4j Cypher Query Language. https://neo4j.com/developer/ cypher-query-language/
- [25]
- [26]
-
[27]
https://www.tigergraph.com/gsql/
TigerGraph GSQL Query Language. https://www.tigergraph.com/gsql/
-
[28]
https://github.com/tigergraph/ecosys/ tree/ldbc/ldbc_benchmark/tigergraph/queries
TigerGraph GSQL Queries for LDBC SNB. https://github.com/tigergraph/ecosys/ tree/ldbc/ldbc_benchmark/tigergraph/queries. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.