WiSER: A Wireless Scene Encoder for Geometry-Grounded Multi-View Wireless Prediction
Pith reviewed 2026-06-28 05:06 UTC · model grok-4.3
The pith
Transmitter-conditioned sparse 3D scene memory supports joint radiomap and multipath channel predictions from one encoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
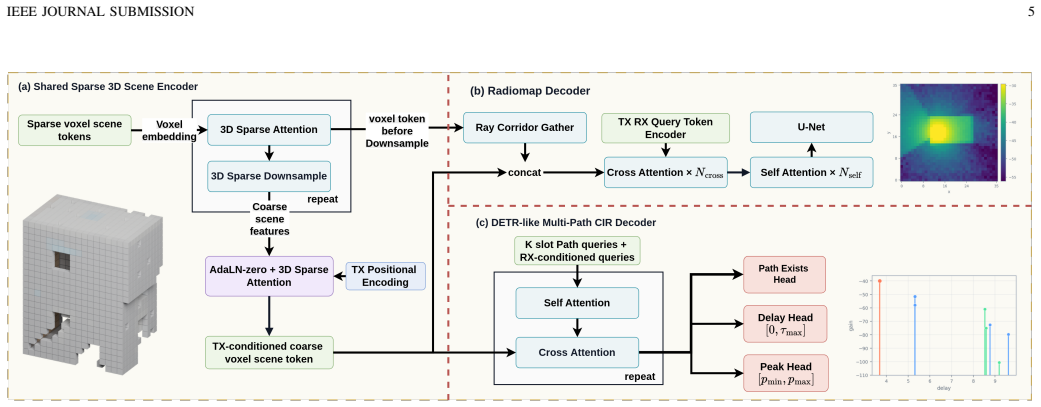
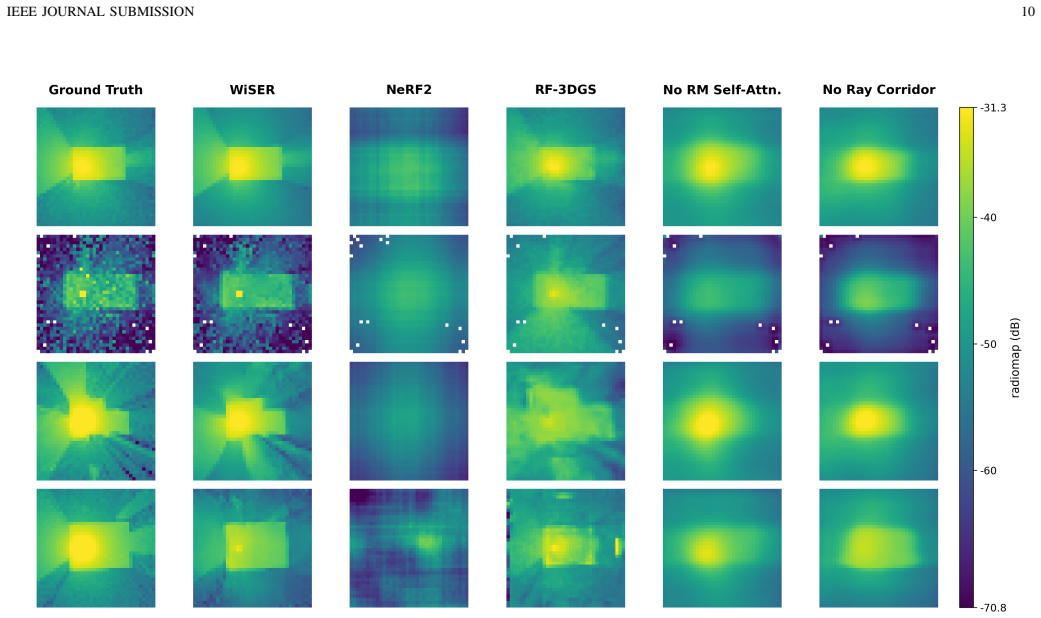
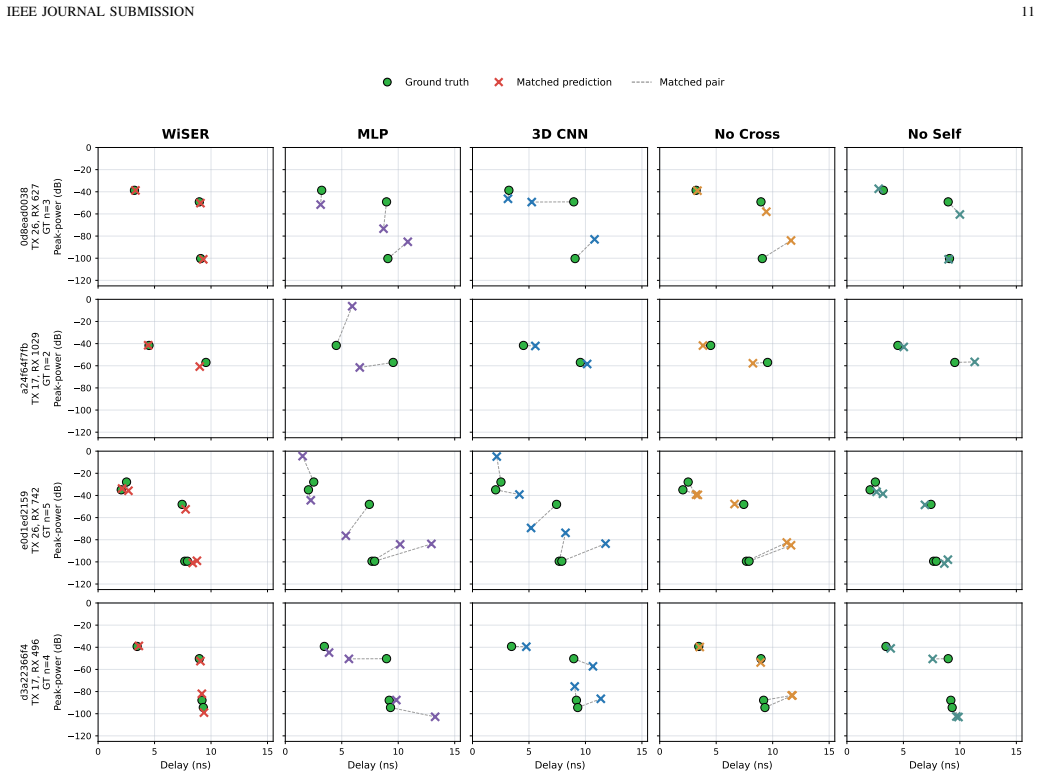
WiSER maps a sparse voxel representation of an indoor scene and a transmitter location into a transmitter-conditioned sparse 3D scene memory, which is queried by a ray-corridor decoder for dense receiver-plane path-gain prediction and a set decoder for variable cardinality delay and power tap prediction. Experiments on co-registered scene and wireless data show that this outperforms scene-specific radiomap baselines and substantially improves matched delay and power prediction over reference CIR baselines.
What carries the argument
transmitter-conditioned sparse 3D scene memory that encodes scene geometry for reuse across different wireless queries
If this is right
- The same encoder can serve heterogeneous propagation queries without separate training per task.
- Sharing the scene memory improves both aggregate coverage predictions and path-level multipath structure.
- Geometry-grounded representations become reusable building blocks for multiple wireless prediction problems.
Where Pith is reading between the lines
- The memory structure could support transfer to new transmitter locations or slight scene changes with limited additional data.
- Real-world measurements might be used to adapt the encoded memory beyond simulation-only training.
- The approach opens a path to combining the encoder with other sensor inputs for tasks such as localization.
Load-bearing premise
Simulated labels from 3D scenes accurately capture the joint statistics of radiomap and multipath structure that would appear in real indoor environments with actual materials and noise.
What would settle it
Compare the model's predicted path gains and delay-power tap sets against direct measurements collected in a physical indoor space whose geometry and transmitter positions match the input scenes.
Figures

read the original abstract
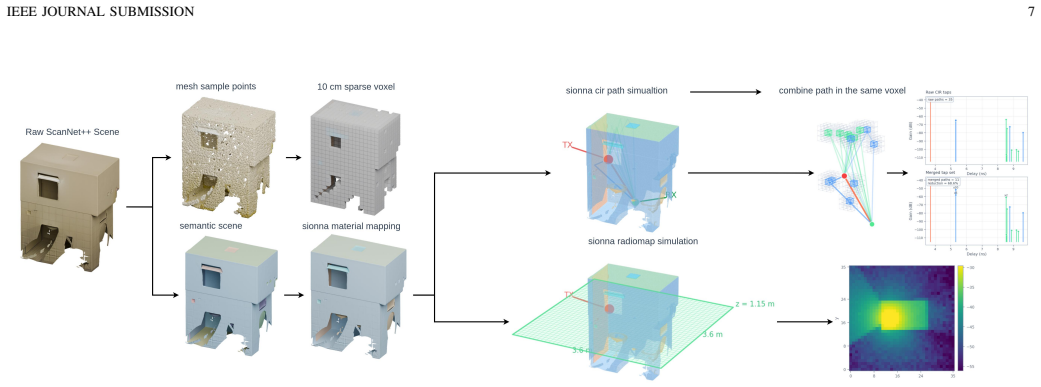
Indoor wireless propagation is governed by the interaction among three-dimensional (3D) scene geometry, radiomaterial properties, and transmitter and receiver configuration, which jointly determine both aggregate coverage behavior and path-level multipath structure. However, most learning-based site-specific prediction methods are designed for a single wireless representation, such as radiomap estimation or channel impulse response (CIR) prediction, and therefore do not explicitly exploit the propagation structure shared across heterogeneous wireless views. This paper introduces WiSER, a Wireless Scene Encoder for joint radiomap and multipath CIR prediction. WiSER maps a sparse voxel representation of an indoor scene and a transmitter location into a transmitter-conditioned sparse 3D scene memory, which is queried by two structure-aware decoders: a ray-corridor decoder for dense receiver-plane path-gain prediction and a Detection Transformer (DETR)-style set decoder for variable cardinality delay and power tap prediction. To train and evaluate this setting, we construct a co-registered indoor scene and wireless dataset pipeline using ScanNet++ indoor scenes and Sionna Ray Tracing, producing aligned sparse voxel inputs, dense radiomap labels, and unordered multipath CIR tap sets under a common coordinate frame and propagation configuration. Experimental results show that WiSER outperforms scene-specific radiomap baselines and substantially improves matched delay and power prediction over reference CIR baselines. These results suggest that transmitter-conditioned sparse 3D scene representations can serve as reusable wireless scene encoders for heterogeneous propagation queries, providing a geometry-grounded step toward representation learning and foundation-model development for AI-native wireless systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WiSER, a neural architecture that maps a sparse voxel representation of an indoor 3D scene plus transmitter location into a transmitter-conditioned sparse 3D scene memory. This memory is queried by a ray-corridor decoder for dense receiver-plane path-gain (radiomap) prediction and a DETR-style set decoder for variable-cardinality delay/power tap (CIR) prediction. The model is trained and evaluated on a co-registered dataset generated from ScanNet++ scenes via Sionna ray-tracing; the central claim is that the learned representations outperform scene-specific radiomap baselines and reference CIR baselines, enabling reusable geometry-grounded encoders for heterogeneous wireless queries.
Significance. If the performance gains are substantial, statistically validated, and the representations generalize beyond the synthetic training distribution, the work would constitute a concrete step toward multi-task, geometry-aware representation learning for wireless systems. The construction of an aligned sparse-voxel / radiomap / CIR dataset pipeline is a clear positive contribution that could support future foundation-model efforts in the field.
major comments (2)
- [Abstract] Abstract: the claim that 'WiSER outperforms scene-specific radiomap baselines and substantially improves matched delay and power prediction over reference CIR baselines' is presented without any quantitative metrics, baseline descriptions, ablation tables, or statistical significance tests. Because the central claim of reusable encoders rests on demonstrated superiority, the absence of these results is load-bearing and prevents verification of the asserted gains.
- [Dataset construction] Dataset construction (described in the abstract and implied experimental sections): all labels are generated exclusively by Sionna ray-tracing over ScanNet++ geometry with default or assumed material properties and no sensor noise. This choice directly affects whether the learned features capture genuine joint statistics of real indoor radiomaps and multipath structure; without real-world validation or sensitivity analysis to material/noise mismatch, the claim that the encoder reflects propagation physics rather than simulation artifacts cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'WiSER outperforms scene-specific radiomap baselines and substantially improves matched delay and power prediction over reference CIR baselines' is presented without any quantitative metrics, baseline descriptions, ablation tables, or statistical significance tests. Because the central claim of reusable encoders rests on demonstrated superiority, the absence of these results is load-bearing and prevents verification of the asserted gains.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports these metrics, baseline descriptions, ablation studies, and statistical details in Sections 4 and 5. We will revise the abstract to incorporate specific performance numbers (e.g., radiomap NMSE improvements and CIR matching accuracy gains) with references to the corresponding tables. revision: yes
-
Referee: [Dataset construction] Dataset construction (described in the abstract and implied experimental sections): all labels are generated exclusively by Sionna ray-tracing over ScanNet++ geometry with default or assumed material properties and no sensor noise. This choice directly affects whether the learned features capture genuine joint statistics of real indoor radiomaps and multipath structure; without real-world validation or sensitivity analysis to material/noise mismatch, the claim that the encoder reflects propagation physics rather than simulation artifacts cannot be assessed.
Authors: The co-registered dataset is generated via Sionna ray-tracing on ScanNet++ to ensure precise alignment between geometry, radiomaps, and CIRs under controlled conditions, which is essential for training the multi-view model. We will add an explicit limitations paragraph discussing the use of default material properties and absence of sensor noise, along with a brief sensitivity discussion where feasible. However, real-world measurements and full mismatch analysis require new data collection that is outside the scope of this work. revision: partial
- Comprehensive real-world validation or sensitivity analysis to material/noise mismatch, as this would require new measurement campaigns beyond the current simulation-based study.
Circularity Check
No circularity: standard supervised training on external simulation labels
full rationale
The paper presents a neural network architecture (transmitter-conditioned sparse voxel encoder plus ray-corridor and DETR-style decoders) trained end-to-end on labels generated by an independent external pipeline (Sionna ray-tracing over ScanNet++ geometry). No equation defines a quantity in terms of itself, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on a self-citation chain. The central claim that the learned representations are reusable across heterogeneous queries is an empirical outcome of supervised training and held-out evaluation, not a definitional identity. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural-network weights
axioms (1)
- domain assumption Sionna ray tracing on ScanNet++ scenes produces labels whose joint radiomap and multipath statistics match real indoor propagation
invented entities (1)
-
transmitter-conditioned sparse 3D scene memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The COST 2100 MIMO channel model,
L. Liu, C. Oestges, J. Poutanen, K. Haneda, P. Vainikainen, F. Quitin, F. Tufvesson, and P. De Doncker, “The COST 2100 MIMO channel model,”IEEE Wireless Commun., vol. 19, no. 6, pp. 92–99, Dec. 2012
2012
-
[2]
QuaDRiGa: A 3- D multi-cell channel model with time evolution for enabling virtual field trials,
S. Jaeckel, L. Raschkowski, K. Borner, and L. Thiele, “QuaDRiGa: A 3- D multi-cell channel model with time evolution for enabling virtual field trials,”IEEE Trans. Antennas Propag., vol. 62, no. 6, pp. 3242–3256, Jun. 2014
2014
-
[3]
A novel millimeter- wave channel simulator and applications for 5G wireless communica- tions,
S. Sun, G. R. MacCartney, and T. S. Rappaport, “A novel millimeter- wave channel simulator and applications for 5G wireless communica- tions,” inProc. IEEE Int. Conf. Commun. (ICC), Paris, France, May 2017, pp. 1–7
2017
-
[4]
Sionna: An open-source library for next-generation physical layer research,
J. Hoydis, S. Cammerer, F. A. Aoudia, A. Vem, N. Binder, G. Marcus, and A. Keller, “Sionna: An open-source library for next-generation physical layer research,”arXiv preprint arXiv:2203.11854, 2022
-
[5]
Sionna RT: Differentiable ray tracing for radio propagation modeling,
J. Hoydis, F. A. Aoudia, S. Cammerer, M. Nimier-David, N. Binder, G. Marcus, and A. Keller, “Sionna RT: Differentiable ray tracing for radio propagation modeling,”arXiv preprint arXiv:2303.11103, 2023
-
[6]
RadioUNet: Fast radio map estimation with convolutional neural networks,
R. Levie, C ¸ . Yapar, G. Kutyniok, and G. Caire, “RadioUNet: Fast radio map estimation with convolutional neural networks,”IEEE Trans. Wireless Commun., vol. 20, no. 6, pp. 4001–4015, Jun. 2021
2021
-
[7]
Radio map estimation: A data-driven approach to spectrum cartography,
D. Romero and S.-J. Kim, “Radio map estimation: A data-driven approach to spectrum cartography,”IEEE Signal Process. Mag., vol. 39, no. 6, pp. 53–72, Nov. 2022
2022
-
[8]
An I2I inpainting approach for efficient channel knowledge map construction,
Z. Jin, L. You, J. Wang, X.-G. Xia, and X. Gao, “An I2I inpainting approach for efficient channel knowledge map construction,”IEEE Trans. Wireless Commun., vol. 24, no. 2, pp. 1415–1429, Feb. 2025
2025
-
[9]
A tutorial on environment-aware communications via channel knowledge map for 6G,
Y . Zeng, J. Chen, J. Xu, D. Wu, X. Xu, S. Jin, X. Gao, D. Gesbert, S. Cui, and R. Zhang, “A tutorial on environment-aware communications via channel knowledge map for 6G,”IEEE Commun. Surveys Tuts., vol. 26, no. 3, pp. 1478–1519, 2024
2024
-
[10]
Deep learning for massive MIMO CSI feedback,
C.-K. Wen, W.-T. Shih, and S. Jin, “Deep learning for massive MIMO CSI feedback,”IEEE Wireless Commun. Lett., vol. 7, no. 5, pp. 748–751, Oct. 2018
2018
-
[11]
Convolutional neural network based multiple-rate compressive sensing for massive MIMO CSI feed- back: Design, simulation, and analysis,
J. Guo, C.-K. Wen, S. Jin, and G. Y . Li, “Convolutional neural network based multiple-rate compressive sensing for massive MIMO CSI feed- back: Design, simulation, and analysis,”IEEE Trans. Wireless Commun., vol. 19, no. 4, pp. 2827–2840, Apr. 2020
2020
-
[12]
Distributed deep convo- lutional compression for massive MIMO CSI feedback,
M. B. Mashhadi, Q. Yang, and D. G ¨und¨uz, “Distributed deep convo- lutional compression for massive MIMO CSI feedback,”IEEE Trans. Wireless Commun., vol. 20, no. 4, pp. 2621–2633, Apr. 2021
2021
-
[13]
Towards a wireless physical- layer foundation model: Challenges and strategies,
J. Fontaine, A. Shahid, and E. De Poorter, “Towards a wireless physical- layer foundation model: Challenges and strategies,” inProc. IEEE Int. Conf. Commun. Workshops (ICC Workshops), Denver, CO, USA, Jun. 2024
2024
-
[14]
Large wireless model (LWM): A foundation model for wireless channels,
S. Alikhani, G. Charan, and A. Alkhateeb, “Large wireless model (LWM): A foundation model for wireless channels,”arXiv preprint arXiv:2411.08872, 2024
-
[15]
WiFo: Wireless foun- dation model for channel prediction,
B. Liu, S. Gao, X. Liu, X. Cheng, and L. Yang, “WiFo: Wireless foun- dation model for channel prediction,”arXiv preprint arXiv:2412.08908, 2024
-
[16]
ScanNet++: A high- fidelity dataset of 3D indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “ScanNet++: A high- fidelity dataset of 3D indoor scenes,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Paris, France, Oct. 2023
2023
-
[17]
DeepMIMO: A Generic Deep Learning Dataset for Millimeter Wave and Massive MIMO Applications
A. Alkhateeb, “DeepMIMO: A generic deep learning dataset for millimeter-wave and massive MIMO applications,”arXiv preprint arXiv:1902.06435, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[18]
DeepSense 6G: A large-scale real- world multi-modal sensing and communication dataset,
A. Alkhateeb, G. Charan, T. Osman, A. Hredzak, J. Morais, U. Demirhan, and N. Srinivas, “DeepSense 6G: A large-scale real- world multi-modal sensing and communication dataset,”arXiv preprint arXiv:2211.09769, 2022
-
[19]
M 3SC: A generic dataset for mixed multi-modal sensing and communication integration,
X. Cheng, Z. Huang, L. Bai, H. Zhang, M. Sun, B. Liu, S. Li, J. Zhang, and M. Lee, “M 3SC: A generic dataset for mixed multi-modal sensing and communication integration,”China Commun., vol. 20, no. 11, pp. 13–29, Nov. 2023
2023
-
[20]
X. Wang, Q. Zhang, N. Cheng, J. Chen, Z. Zhang, Z. Li, S. Cui, and X. Shen, “RadioDiff-3D: A 3D×3D radio map dataset and generative diffusion based benchmark for 6G environment-aware communication,” arXiv preprint arXiv:2507.12166, 2025
-
[21]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” inProc. Eur . Conf. Comput. Vis. (ECCV), Virtual, Aug. 2020, pp. 213–229
2020
-
[22]
Native and Compact Structured Latents for 3D Generation
J. Xiang, X. Chen, S. Xu, R. Wang, Z. Lv, Y . Deng, H. Zhu, Y . Dong, H. Zhao, N. J. Yuan, and J. Yang, “Native and compact structured latents for 3D generation,”arXiv preprint arXiv:2512.14692, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
RadioGen3D: 3D radio map generation via adversarial learning on large-scale synthetic data,
J. Chen, A. Xu, Z. Zhang, S. Zhang, J. Chen, and S. Cui, “RadioGen3D: 3D radio map generation via adversarial learning on large-scale synthetic data,”arXiv preprint arXiv:2602.18744, 2026
-
[24]
Deep Learning-Based Site-Specific Channel Modeling and Inference
J. Song, R. He, M. Yang, Z. Zhang, S. Gao, B. Ai, and Z. Zhong, “Deep learning-based site-specific channel modeling and inference,” arXiv preprint arXiv:2603.28083, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Deformable DETR: Deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable DETR: Deformable transformers for end-to-end object detection,” inProc. Int. Conf. Learn. Representations (ICLR), Virtual, May 2021
2021
-
[26]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskillet al., “On the opportunities and risks of foundation models,”arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Multitask learning,
R. Caruana, “Multitask learning,”Mach. Learn., vol. 28, no. 1, pp. 41– 75, Jul. 1997
1997
-
[28]
Multi-task learning using uncer- tainty to weigh losses for scene geometry and semantics,
A. Kendall, Y . Gal, and R. Cipolla, “Multi-task learning using uncer- tainty to weigh losses for scene geometry and semantics,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, USA, Jun. 2018, pp. 7482–7491
2018
-
[29]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,” inProc. Eur . Conf. Comput. Vis. (ECCV), Virtual, Aug. 2020, pp. 405–421
2020
-
[30]
3D gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D gaussian splatting for real-time radiance field rendering,”ACM Trans. Graph., vol. 42, no. 4, pp. 139:1–139:14, Jul. 2023
2023
-
[31]
NeRF2: Neural radio-frequency radiance fields,
X. Zhao, Z. An, Q. Pan, and L. Yang, “NeRF2: Neural radio-frequency radiance fields,”arXiv preprint arXiv:2305.06118, 2023
-
[32]
NeWRF: A deep learning framework for wireless radiation field reconstruction and channel prediction,
H. Lu, C. Vattheuer, B. Mirzasoleiman, and O. Abari, “NeWRF: A deep learning framework for wireless radiation field reconstruction and channel prediction,”arXiv preprint arXiv:2403.03241, 2024
-
[33]
RF-3DGS: Wireless channel modeling with radio radiance field and 3D gaussian splatting,
L. Zhang, H. Sun, S. Berweger, C. Gentile, and R. Q. Hu, “RF-3DGS: Wireless channel modeling with radio radiance field and 3D gaussian splatting,”arXiv preprint arXiv:2411.19420, 2024
-
[34]
WiNeRT: Towards neural ray tracing for wireless channel modelling and differentiable simulations,
T. Orekondy, P. Kumar, S. Kadambi, H. Ye, J. Soriaga, and A. Behboodi, “WiNeRT: Towards neural ray tracing for wireless channel modelling and differentiable simulations,” inProc. Int. Conf. Learn. Representa- tions (ICLR), Kigali, Rwanda, May 2023
2023
-
[35]
4D spatio-temporal convnets: Minkowski convolutional neural networks,
C. Choy, J. Gwak, and S. Savarese, “4D spatio-temporal convnets: Minkowski convolutional neural networks,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, CA, USA, Jun. 2019
2019
-
[36]
Point transformer V2: Grouped vector attention and partition-based pooling,
X. Wu, Y . Lao, L. Jiang, X. Liu, and H. Zhao, “Point transformer V2: Grouped vector attention and partition-based pooling,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), New Orleans, LA, USA, Nov. 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.