InquiTree: Evaluating AI Agents in the Scientific Inquiry Loop with Paper-Derived Research Trees
Pith reviewed 2026-06-27 14:05 UTC · model grok-4.3
The pith
LLM agents develop cognitive tunneling and lose anomaly detection ability during extended scientific inquiry sessions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
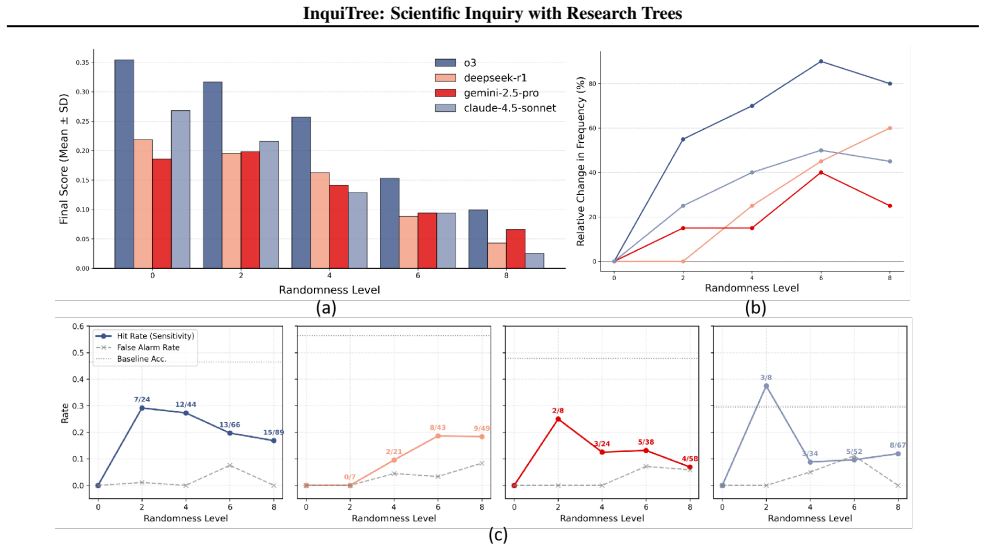
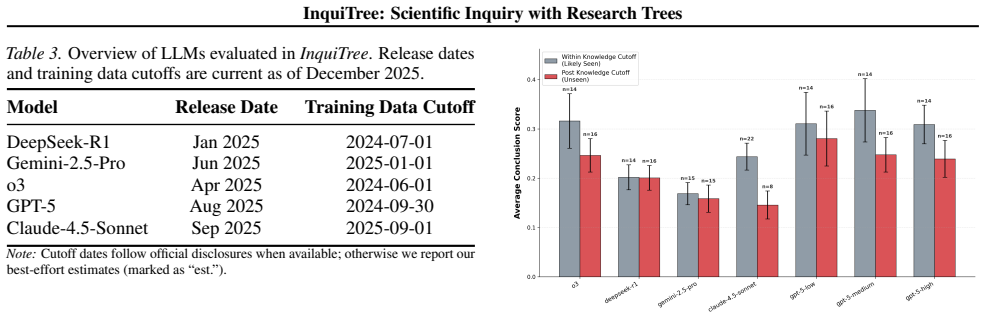
InquiTree formalizes scientific inquiry as Research Trees, directed acyclic graphs that track dependencies across hypothesis formulation, study design, result interpretation, and belief updating. Evaluation on a 30-paper pool reveals two limitations: agents exhibit erosion of marginal capabilities through cognitive tunneling, where critical judgment degrades in long-horizon interactions, and they perform worse on papers published after training cutoffs, showing a boundary between interpolation and extrapolation that suggests reliance on parametric memory.
What carries the argument
Research Trees: directed acyclic graphs capturing logical dependencies among hypothesis formulation, study design, result interpretation, and belief updating, used as the interactive diagnostic environment.
If this is right
- Agents develop cognitive tunneling where critical judgment and anomaly detection degrade relative to their intrinsic baselines during long-horizon tasks.
- Performance drops on papers after model training cutoffs reveal a boundary between interpolation within training data and extrapolation to new information.
- Scaling context length alone proves insufficient for reliable performance in the uncertain process of discovery.
- Stronger architectures or human oversight become necessary to preserve critical evaluation and generalization.
Where Pith is reading between the lines
- The same tunneling effect could appear in other long-horizon agent applications outside science.
- Evaluations could add dynamically generated papers to separate memorization from genuine discovery more cleanly.
- Hybrid setups that pair agents with external verification steps might reduce the observed degradation.
Load-bearing premise
The 30-paper test pool and the Research Trees derived from them provide a faithful, unbiased representation of the dynamic and uncertain process of scientific discovery.
What would settle it
No degradation in critical judgment or anomaly detection across long interactions, or equal performance on pre- and post-cutoff papers, would refute the claimed limitations.
Figures


read the original abstract
While LLM-based agents are increasingly used in scientific workflows, it remains unclear whether they are truly qualified for the dynamic and uncertain process of discovery. Existing static evaluations often conflate genuine reasoning with rote memorization. We introduce InquiTree, a diagnostic environment that formalizes scientific inquiry as interactive Research Trees: directed acyclic graphs capturing the logical dependencies among hypothesis formulation, study design, result interpretation, and belief updating. Evaluating agents on a 30-paper test pool and releasing the open-access InquidTree-18(IT-18) subset, we identify two key limitations. First, agents exhibit an "Erosion of Marginal Capabilities": during long-horizon interactions, they develop "cognitive tunneling," where critical judgment and anomaly detection degrade relative to their intrinsic baselines. Second, performance drops on papers published after model training cutoffs, revealing a boundary between interpolation and extrapolation and suggesting that apparent competence is partly driven by parametric memory. These findings indicate that scaling context alone is insufficient for reliable AI scientists; stronger architectures or human oversight may be required to preserve critical evaluation and generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InquiTree, a diagnostic environment that models scientific inquiry as interactive Research Trees (directed acyclic graphs capturing dependencies among hypothesis formulation, study design, result interpretation, and belief updating). Agents are evaluated on a 30-paper test pool (with the open-access InquiTree-18 subset released), yielding two main claims: (1) an 'Erosion of Marginal Capabilities' in which long-horizon interactions produce 'cognitive tunneling' that degrades critical judgment and anomaly detection relative to intrinsic baselines, and (2) performance drops on papers published after model training cutoffs, indicating a boundary between interpolation and extrapolation driven partly by parametric memory. The authors conclude that scaling context alone is insufficient for reliable AI scientists.
Significance. If the evaluation methodology proves robust, the work would be significant for moving beyond static benchmarks to interactive, tree-structured tests that better approximate the uncertain, multi-step nature of discovery. The explicit identification of cognitive tunneling and post-cutoff degradation supplies concrete, falsifiable failure modes that could inform architecture design and the necessity of human oversight. Releasing the IT-18 subset is a clear strength for reproducibility and follow-on work.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: the 30-paper test pool is presented without selection criteria, domain stratification, inter-paper variance controls, or validation that the derived Research Trees reproduce dynamic discovery steps rather than static logical chains. This directly undermines the central claims of cognitive tunneling and post-cutoff extrapolation limits, because observed degradations could arise from paper-specific difficulty or recency artifacts rather than intrinsic agent properties.
- [Abstract and §4 (experimental setup)] Abstract and §4 (experimental setup): no information is supplied on agent selection, baseline construction, statistical tests, or error analysis. Without these, it is impossible to determine whether the reported performance drops and tunneling effects are statistically reliable or generalizable beyond the specific 30-paper pool.
minor comments (1)
- [Abstract] Abstract: 'InquidTree-18' appears to be a typographical error for 'InquiTree-18'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will incorporate the requested details into a revised manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the 30-paper test pool is presented without selection criteria, domain stratification, inter-paper variance controls, or validation that the derived Research Trees reproduce dynamic discovery steps rather than static logical chains. This directly undermines the central claims of cognitive tunneling and post-cutoff extrapolation limits, because observed degradations could arise from paper-specific difficulty or recency artifacts rather than intrinsic agent properties.
Authors: We agree that the manuscript would be strengthened by explicit documentation of these aspects. In the revision we will add a dedicated subsection to the Evaluation section describing the paper selection process (including domain stratification across biology, physics, and computer science), variance controls (matching on length, citation count, and topic breadth), and the procedure used to construct and validate the Research Trees against the original papers' logical flow to confirm they model iterative discovery steps. revision: yes
-
Referee: [Abstract and §4 (experimental setup)] Abstract and §4 (experimental setup): no information is supplied on agent selection, baseline construction, statistical tests, or error analysis. Without these, it is impossible to determine whether the reported performance drops and tunneling effects are statistically reliable or generalizable beyond the specific 30-paper pool.
Authors: We acknowledge the absence of these details in the current draft. The revised §4 will specify the LLMs and agent architectures evaluated, the construction of intrinsic and single-step baselines, the statistical tests (e.g., paired comparisons with reported p-values and effect sizes), and a categorized error analysis of tunneling and extrapolation failures. These additions will support claims of reliability and generalizability. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical evaluation framework using Research Trees derived from an external 30-paper test pool. Claims of cognitive tunneling and post-cutoff performance drops are observational results from agent interactions on these trees, not reductions of outputs to fitted parameters, self-definitions, or self-citation chains. No equations, ansatzes, or uniqueness theorems are invoked that would make results tautological by construction. The setup is self-contained against external benchmarks (real papers) with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scientific inquiry can be represented as directed acyclic graphs capturing logical dependencies among hypothesis formulation, study design, result interpretation, and belief updating
invented entities (1)
-
Research Trees
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Socratic agents for autonomous scientific discovery in high-dimensional physical systems
AHOIS is a Socratic multi-agent AI that autonomously discovers and validates a random-interference encoding strategy for multimode fiber optics, achieving 76.97% MNIST and 83.17% Fashion-MNIST accuracy with 16x16 meas...
Reference graph
Works this paper leans on
-
[1]
A Survey of
Tie, Guiyao and Zhou, Pan and Sun, Lichao , journal =. A Survey of
-
[2]
Huang, Qian and Vora, Jian and Liang, Percy and Leskovec, Jure , journal =
-
[3]
arXiv preprint arXiv:2502.14499 , year=
Mlgym: A new framework and benchmark for advancing ai research agents , author=. arXiv preprint arXiv:2502.14499 , year=
-
[4]
arXiv preprint arXiv:2410.05080 , year=
Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery , author=. arXiv preprint arXiv:2410.05080 , year=
-
[5]
arXiv preprint arXiv:2503.00096 , year=
Bixbench: a comprehensive benchmark for llm-based agents in computational biology , author=. arXiv preprint arXiv:2503.00096 , year=
-
[6]
Benchmarking
Luo, Erpai and Jia, Jinmeng and Xiong, Yifan and Li, Xiangyu and Guo, Xiaobo and Yu, Baoqi and Wei, Lei and Zhang, Xuegong , journal =. Benchmarking. 2025 , note =
2025
-
[7]
arXiv preprint arXiv:2411.02429 , year =
IdeaBench: Benchmarking Large Language Models for Research Idea Generation , author =. arXiv preprint arXiv:2411.02429 , year =
-
[8]
arXiv preprint arXiv:2510.24891 , year=
Idea2Plan: Exploring AI-Powered Research Planning , author=. arXiv preprint arXiv:2510.24891 , year=
-
[9]
arXiv preprint arXiv:2411.15114 , year=
Re-bench: Evaluating frontier ai r&d capabilities of language model agents against human experts , author=. arXiv preprint arXiv:2411.15114 , year=
-
[10]
arXiv preprint arXiv:2504.01848 , year=
PaperBench: Evaluating AI's Ability to Replicate AI Research , author=. arXiv preprint arXiv:2504.01848 , year=
-
[11]
arXiv preprint arXiv:2502.18864 , year=
Towards an AI co-scientist , author=. arXiv preprint arXiv:2502.18864 , year=
-
[12]
arXiv preprint arXiv:2505.24785 , year=
EXP-Bench: Can AI Conduct AI Research Experiments? , author=. arXiv preprint arXiv:2505.24785 , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Scicode: A research coding benchmark curated by scientists, 2024 , author=. URL https://arxiv. org/abs/2407.13168 , volume=
arXiv 2024
-
[15]
Jun Shern Chan and Lunjun Zhang and Shijie Zhang and Xinyu Zhang and Jianbo Zhang and Zihan Wang and Zhiyu Yao and Xiaohan Wang and Yilin Niu and Xiang Zhang and Kimin Lee and Percy Liang and Atri Rudra , journal =
-
[16]
arXiv preprint arXiv:2510.27130 , year=
AI Agents in Drug Discovery , author=. arXiv preprint arXiv:2510.27130 , year=
-
[17]
bioRxiv , year=
OmniCellAgent: Towards AI Co-Scientists for Scientific Discovery in Precision Medicine , author=. bioRxiv , year=
-
[18]
arXiv preprint arXiv:2408.06292 , year=
The ai scientist: Towards fully automated open-ended scientific discovery , author=. arXiv preprint arXiv:2408.06292 , year=
-
[19]
Nature human behaviour , volume=
Large language models surpass human experts in predicting neuroscience results , author=. Nature human behaviour , volume=. 2025 , publisher=
2025
-
[20]
arXiv preprint arXiv:2204.14211 , year=
Temporalwiki: A lifelong benchmark for training and evaluating ever-evolving language models , author=. arXiv preprint arXiv:2204.14211 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.