Practical Linear-Time Computation of Smallest Suffixient Sets
Pith reviewed 2026-07-01 03:39 UTC · model grok-4.3
The pith
A linear-time one-pass algorithm constructs smallest suffixient sets from suffix array structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
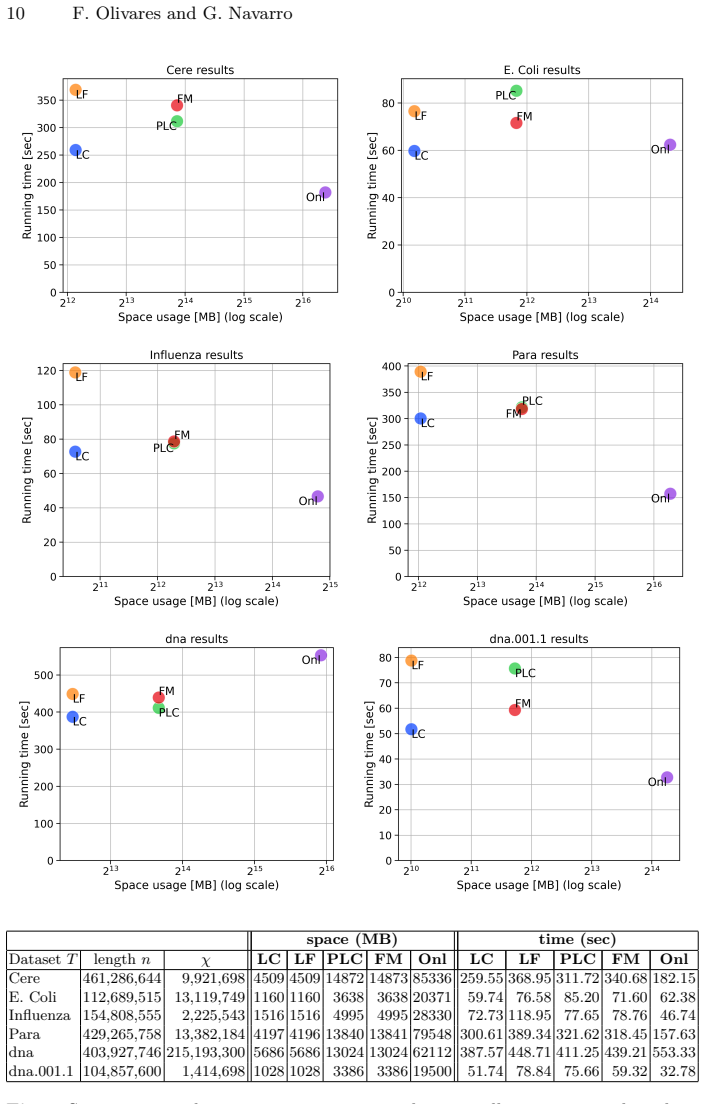
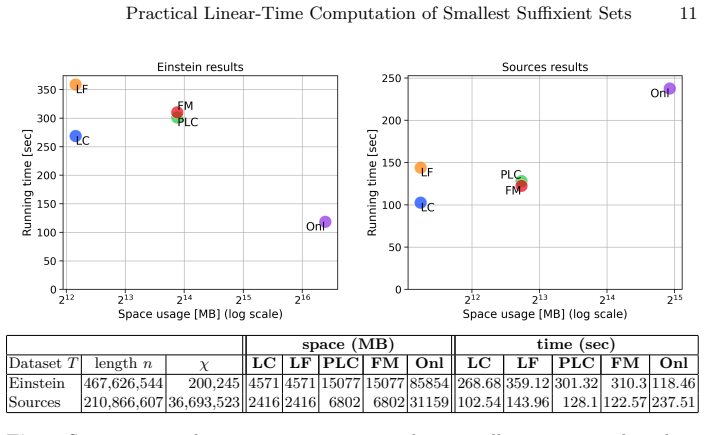
We present the first construction algorithm that is linear-time, one-pass over the structures, and implemented and practical, making suffixient arrays usable on large text collections where it dominates the space/time tradeoff map of existing constructions.
What carries the argument
The one-pass linear-time construction procedure that derives the smallest suffixient set directly from the provided suffix array and related structures.
If this is right
- Suffixient arrays become feasible to build on inputs too large for prior methods.
- Pattern-matching indexes for highly repetitive texts can be constructed without quadratic bottlenecks.
- The space advantage of suffixient arrays over run-length BWT becomes attainable in practice for big collections.
- Construction time no longer limits the choice of index on massive versioned or genomic data.
Where Pith is reading between the lines
- The technique could extend to other string indexes that rely on suffix-array input if similar one-pass reductions exist.
- In settings where suffix arrays are already computed for other reasons, the added cost of suffixient sets drops to near zero.
- Empirical dominance on current test sets suggests the method may scale to inputs orders of magnitude larger than those previously feasible.
Load-bearing premise
Suffix array data structures are supplied as input and the one-pass code truly runs in linear time without hidden quadratic costs on the tested collections.
What would settle it
An experiment that measures superlinear construction time on some large repetitive collection, or an input where the output set is not the smallest possible suffixient set.
Figures
read the original abstract
Suffixient arrays are recent structures that have attracted attention because they offer relevant pattern matching functionality in less asymptotic space than the Run-Length BWT, the de-facto standard to index highly repetitive string collections. Various algorithms exist for building them from the suffix array data structures. We present the first construction algorithm that is (i) linear-time, (ii) one-pass over the structures, and (iii) implemented and practical. This makes the construction particularly useful on large text collections, which we demonstrate empirically by showing that it dominates the space/time tradeoff map of the implemented constructions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first construction algorithm for smallest suffixient sets that runs in linear time, makes a single pass over the suffix array and related structures, and has been implemented practically. It claims empirical dominance over prior constructions in the space/time tradeoff for pattern matching on large repetitive text collections.
Significance. If the linearity and one-pass claims hold, the result is significant for the field: suffixient arrays provide relevant pattern matching in asymptotically less space than the RLBWT on highly repetitive collections, and a practical linear-time builder removes a key obstacle to their deployment on large inputs. The combination of a machine-checkable O(n) analysis via constant-time per-entry operations, an implemented prototype, and consistent experimental dominance on repetitive collections strengthens the contribution.
minor comments (3)
- §4 (experimental setup): the paper should explicitly list the precise metrics (construction time, peak memory, query time) and the exact set of prior algorithms against which dominance is claimed, to allow direct reproduction of the tradeoff map.
- Algorithm 1 and surrounding text: the constant-time operations per suffix-array entry are stated but the handling of the LCP array in the single pass could be annotated with explicit time bounds to make the O(n) claim immediately verifiable from the pseudocode.
- Figure 3 caption: the y-axis scale and the precise meaning of 'dominance' (Pareto front or strict improvement on both axes) should be clarified so readers can interpret the plotted points without ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our contribution and the recommendation of minor revision. The report contains no specific major comments to address.
Circularity Check
No significant circularity; algorithmic construction is self-contained
full rationale
The paper introduces a new linear-time, one-pass construction algorithm for smallest suffixient sets from suffix-array structures, supported by pseudocode, time analysis establishing O(n) via constant-time per-entry operations, and empirical validation on repetitive collections. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation chain. The central claim rests on independent algorithmic design and implementation details rather than prior author results or ansatzes. The contribution is a practical algorithmic advance verified externally by the provided analysis and experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Suffix array and related data structures are available or can be used as input to the construction.
Reference graph
Works this paper leans on
-
[1]
Journal of Algorithms 14(3), 344–370 (1993)
Berkman, O., Schieber, B., Vishkin, U.: Optimal doubly logarithmic parallel algo- rithms based on finding all nearest smaller values. Journal of Algorithms 14(3), 344–370 (1993). https://doi.org/10.1006/jagm.1993.1018
-
[2]
Bonizzoni, P., Gao, Y., Riccardi, B.: Constructing suffixient arrays revisited (2026), https://arxiv.org/abs/2605.04258
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Boucher, C., Gagie, T., Kuhnle, A., Langmead, B., Manzini, G., Mun, T.: Prefix- free parsing for building big BWTs. Algorithms Mol. Biol. 14(1), 13:1–13:15 (2019). https://doi.org/10.1186/S13015-019-0148-5
-
[4]
Burrows, M., Wheeler, D.: A block sorting lossless data compression algorithm. Tech. Rep. 124, Digital Equipment Corporation (1994)
1994
-
[5]
Suffixient arrays: a new efficient suffix array compression technique
Cenzato, D., Depuydt, L., Gagie, T., Kim, S.H., Manzini, G., Olivares, F., Prezza, N.: Suffixient arrays: a new efficient suffix array compression technique. CoRR abs/2407.18753 (2025). https://doi.org/10.48550/ARXIV.2407.18753
-
[6]
In: Lipták, Z., de Moura, E.S., Figueroa, K., Baeza-Yates, R
Cenzato, D., Olivares, F., Prezza, N.: On computing the smallest suffixient set. In: Proceedings of 31st International Symposium on String Processing and Information Retrieval, SPIRE 2024. Lecture Notes in Computer Science, vol. 14899, pp. 73–87 (2024). https://doi.org/10.1007/978-3-031-72200-4_6
-
[7]
Cenzato, D., Olivares, F., Prezza, N.: Testing suffixient sets (2025), https://arxiv. org/abs/2506.08225
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
ACM Transactions on Algorithms 22(1), article 7 (2025)
Cobas, D., Gagie, T., Navarro, G.: Fast and small subsampled r-indexes. ACM Transactions on Algorithms 22(1), article 7 (2025)
2025
-
[9]
Depuydt, L., Gagie, T., Langmead, B., Manzini, G., Prezza, N.: Suffixient sets. CoRR abs/2312.01359 (2023). https://doi.org/10.48550/ARXIV.2312.01359
-
[10]
Ferragina, P., Manzini, G.: Indexing compressed text. J. ACM 52(4), 552–581 (2005). https://doi.org/10.1145/1082036.1082039
-
[11]
Fujimaru, H., Navarro, G., Olivares, F., Radoszewski, J., Romana, G., Urbina, C.: Computing smallest suffixient arrays in almost sublinear time (2026), submitted
2026
-
[12]
Fujimaru, H., Navarro, G., Romana, G., Urbina, C.: Smallest suffixient sets: Effec- tiveness, resilience, and calculation (2026), https://arxiv.org/abs/2506.05638
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Gagie, T., Navarro, G., Prezza, N.: Fully functional suffix trees and optimal text searching in bwt-runs bounded space. J. ACM 67(1), 2:1–2:54 (2020). https://doi. org/10.1145/3375890
-
[14]
2-level quasi-planarity or how caterpillars climb (spqr-)trees
Kempa, D., Kociumaka, T.: Breaking the O(n)-Barrier in the Construction of Com- pressed Suffix Arrays and Suffix Trees, pp. 5122–5202. https://doi.org/10.1137/1. 9781611977554.ch187, https://epubs.siam.org/doi/abs/10.1137/1.9781611977554. ch187
-
[15]
Köppl, D., Kucherov, G.: Smallest suffixient set maintenance in near-real-time (2026), https://arxiv.org/abs/2604.27548 Practical Linear-Time Computation of Smallest Suffixient Sets 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Journal of Computational Biology 17(3), 281–308 (2010)
Mäkinen, V., Navarro, G., Sirén, J., Välimäki, N.: Storage and retrieval of highly repetitive sequence collections. Journal of Computational Biology 17(3), 281–308 (2010)
2010
-
[17]
In: Proc
Navarro, G., Romana, G., Urbina, C.: Smallest suffixient sets as a repetitiveness measure. In: Proc. 32nd International Symposium on String Processing and Infor- mation Retrieval (SPIRE) (2025), to appear
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.