Physics-Informed Neural Operator for Speech Production Analysis
Pith reviewed 2026-06-26 09:56 UTC · model grok-4.3
The pith
A neural operator solves the wave equations of speech production directly from vocal tract shapes without any precomputed examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
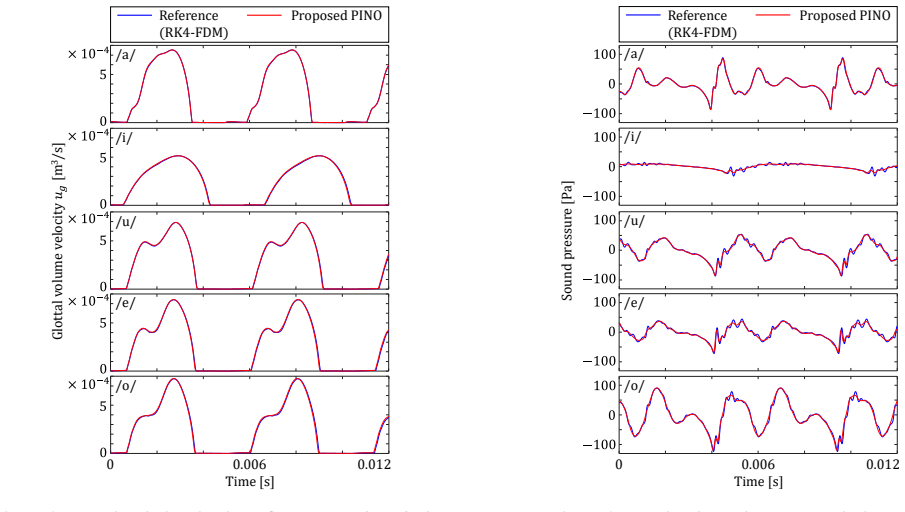
The model learns the governing one-dimensional wave equations directly without requiring pre-computed supervised training data. Using vocal tract shape data as input features, it predicts f0, glottal volume velocity and sound pressure at the lip for five static vowels, achieving errors of 0.8 percent for glottal volume flow and 3.2 percent for speech waveforms relative to a conventional Runge-Kutta finite-difference approach.
What carries the argument
The physics-informed neural operator that takes vocal tract shape as sole input and is trained to satisfy the one-dimensional wave equations.
If this is right
- Simulation of speech production becomes a single non-iterative forward pass.
- The computation can be executed in parallel across many vocal-tract shapes on a GPU.
- No library of pre-computed reference solutions is needed for training.
- The same architecture can be applied to other one-dimensional wave problems that share the same governing equations.
Where Pith is reading between the lines
- The method could be tested on continuously changing vocal-tract shapes to see whether the operator remains stable when the geometry is no longer static.
- If the operator is differentiable, it could be used inside an optimization loop to recover tract shape from observed sound pressure.
- Parallel evaluation over thousands of tract shapes at once would make large-scale statistical studies of vowel production feasible.
- Extending the input to include glottal source parameters might allow the operator to handle voiced versus unvoiced distinctions without retraining from scratch.
Load-bearing premise
A neural operator can be trained to satisfy the one-dimensional wave equations for speech production to high accuracy using only vocal tract shape data as input and without any pre-computed supervised training examples.
What would settle it
Running the trained operator on a held-out vowel geometry or on a time-varying tract and obtaining waveform errors well above 3.2 percent would show that the accuracy does not hold beyond the reported cases.
Figures

read the original abstract
Physics-informed neural operators (PINOs) have recently gained attention as fast numerical simulators with potential for solving inverse problems. This study proposes the first PINO-based method for speech production analysis. The model learns the governing one-dimensional wave equations directly without requiring pre-computed supervised training data. Using vocal tract shape data as input features, we compare the proposed model's predicted f0, glottal volume velocity and sound pressure at the lip for five static vowels to a conventional Runge Kutta/Finite difference approach. With errors of 0.8% for glottal volume flow and 3.2% for speech waveforms, the proposed model enables efficient GPU-parallelized simulation without iterative calculations. We conclude that PINO is a promising approach for fast analysis of speech.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the first physics-informed neural operator (PINO) for speech production analysis. It claims that the model learns the governing one-dimensional wave equations directly from vocal tract shape data as the sole input, without any pre-computed supervised training examples. For five static vowels, the PINO predictions of f0, glottal volume velocity, and lip sound pressure are compared to a conventional Runge-Kutta/finite-difference solver, with reported errors of 0.8% on glottal volume flow and 3.2% on speech waveforms, enabling GPU-parallelized simulation without iterative calculations.
Significance. If the central performance claims can be substantiated with complete methodological details and a resolution of the boundary-condition issue, the work would offer a fast, parallelizable alternative to traditional numerical methods for speech production modeling. This could be useful for real-time analysis and inverse problems in speech science, provided the approach generalizes beyond the static-vowel cases examined.
major comments (2)
- [Abstract / Model Description] Abstract / Model inputs and boundary conditions: The claim that vocal-tract shape alone suffices as input to predict glottal volume velocity (to 0.8 % error) while satisfying the 1D Webster horn equation via physics loss is not obviously consistent with the problem formulation. The glottal-end boundary condition is set by a separate glottal-flow oscillator whose parameters (subglottal pressure, vocal-fold tension, etc.) are not listed among the inputs; without an auxiliary equation for this oscillator inside the loss, the PDE residual cannot uniquely constrain the glottal flow, allowing arbitrary scaling or shifting at the glottis.
- [Abstract / Methods] Abstract / Experimental details: No information is supplied on network architecture, the precise form of the physics-informed loss, generation of vocal-tract training shapes, validation splits, or the manner in which the physics constraints are enforced (hard vs. soft). These omissions make it impossible to assess whether the reported errors reflect genuine satisfaction of the governing equations or merely a data-fitting artifact.
minor comments (1)
- [Abstract] The abstract states that the model is compared to a 'Runge Kutta/Finite difference approach' but does not specify the exact discretization scheme, time-stepping method, or spatial grid resolution used in the reference solver.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / Model Description] Abstract / Model inputs and boundary conditions: The claim that vocal-tract shape alone suffices as input to predict glottal volume velocity (to 0.8 % error) while satisfying the 1D Webster horn equation via physics loss is not obviously consistent with the problem formulation. The glottal-end boundary condition is set by a separate glottal-flow oscillator whose parameters (subglottal pressure, vocal-fold tension, etc.) are not listed among the inputs; without an auxiliary equation for this oscillator inside the loss, the PDE residual cannot uniquely constrain the glottal flow, allowing arbitrary scaling or shifting at the glottis.
Authors: We agree that the current abstract phrasing is imprecise. For the static-vowel experiments, glottal oscillator parameters (subglottal pressure, vocal-fold tension, and rest position) are fixed to standard values that produce the target f0 for each vowel; these values are not varied as inputs. The PINO therefore learns the solution of the Webster horn equation given vocal-tract area functions and these fixed boundary conditions. The reported 0.8 % error on glottal flow is measured against a reference Runge-Kutta solver that uses the identical fixed oscillator. We will revise the abstract, add an explicit statement of the fixed parameters, and include a short discussion of how the oscillator could be folded into the physics loss for future variable-f0 work. revision: yes
-
Referee: [Abstract / Methods] Abstract / Experimental details: No information is supplied on network architecture, the precise form of the physics-informed loss, generation of vocal-tract training shapes, validation splits, or the manner in which the physics constraints are enforced (hard vs. soft). These omissions make it impossible to assess whether the reported errors reflect genuine satisfaction of the governing equations or merely a data-fitting artifact.
Authors: We acknowledge that these implementation details were omitted. In the revised manuscript we will add a dedicated Methods section that specifies: (i) the Fourier Neural Operator architecture (number of layers, modes, and channel widths), (ii) the exact physics loss (PDE residual of the 1-D Webster equation plus soft boundary-condition penalty terms with their relative weights), (iii) the source of the vocal-tract area functions (parametric models fitted to MRI data for the five vowels), (iv) the train/validation/test split ratios, and (v) confirmation that constraints are enforced softly via weighted loss terms rather than hard projections. These additions will allow readers to reproduce and evaluate the results. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and context describe a PINO trained to satisfy 1D wave equations via physics loss on vocal-tract shape inputs, with no quoted equations, self-citations, or fitted parameters that reduce predictions to inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear. The central claim (learning governing equations without supervised data) remains independent of its own outputs. This is the expected non-finding for a physics-informed operator paper whose loss is external to the target quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The governing one-dimensional wave equations accurately describe speech production in the vocal tract for static vowels.
Reference graph
Works this paper leans on
-
[1]
Introduction Speech production analysis based on a coupled physical model of the vocal folds and the vocal tract plays an important role in investigating vocal-fold dynamics and diagnosing voice disor- ders [1, 2]. Such coupled models enable, for example, estima- tion of vocal-fold states from speech signals [3, 4] and simu- lation of voice changes associ...
-
[2]
A novelself-supervised,physics-informeddeep learning ap- proach for coupled vocal-fold–vocal-tract simulation across multiple vocal-tract shapes using PINO
-
[3]
The remainder of this paper is organized as follows
The first demonstration of high-speed inference for speech production simulation using a PINO. The remainder of this paper is organized as follows. Section 2 describes the physical model of speech production. Section 3 presents the proposed PINO framework. Section 4 reports forward-simulation results and demonstrates high-speed output for different vocal-...
-
[4]
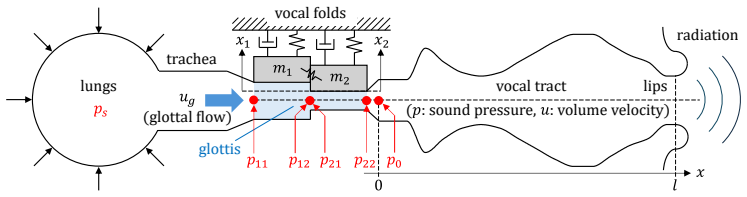
Physical Model of Speech Production 2.1. Two-mass Model of V ocal Folds In this study, we adopt the two-mass model proposed by Ishizaka and Flanagan [21] as the model of the vocal folds. As illustrated in Fig. 1, the vocal folds are modeled as a struc- ture with two masses, and the glottal flow is assumed to satisfy Bernoulli’s principle [23]. Letu g deno...
Pith/arXiv arXiv 2026
-
[5]
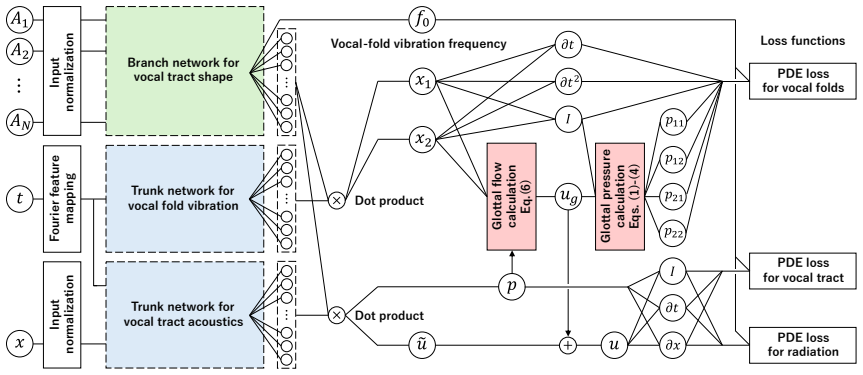
Network Architecture Figure 2 shows the network architecture of the proposed PINO
PINO for Speech Production 3.1. Network Architecture Figure 2 shows the network architecture of the proposed PINO. This architecture is based on PI-DeepONet [20], a type of neural operator, and consists of a branch network that takes the normal- ized vocal-tract shape as input and a trunk network that takes the collocation point (xandt) as input. For both...
-
[6]
Analysis Conditions The validity of the proposed method is evaluated through speech production simulations for multiple vowel configura- tions
Validation of the Proposed Method 4.1. Analysis Conditions The validity of the proposed method is evaluated through speech production simulations for multiple vowel configura- tions. We use five vowel-area functions for /a/, /i/, /u/, /e/, and /o/ reported by Arai [30], and train a single network on all five shapes. The vocal-tract shapes reported by Arai...
-
[7]
Conclusion In this study, we developed a PINO-based speech production analysis model for fast speech production simulation across di- verse vocal-tract shapes. The proposed model takes the vocal- tract shape as an input feature and outputs the correspond- ing vocal-fold vibration frequency, enabling computation of steady-state periodic solutions for multi...
-
[8]
Acknowledgments This work was supported by JSPS KAKENHI Grant Number JP25K03137, JSPS Program for Forming Japan’s Peak Research Universities (J-PEAKS) Grant Number JPJS00420240017 and the Ono Charitable Trust for Acoustics
-
[9]
Generative AI Use Disclosure There is no generative AI use to disclose for this study
-
[10]
Source-tract interaction with prescribed vocal fold motion,
R. S. McGowan and M. S. Howe, “Source-tract interaction with prescribed vocal fold motion,”The Journal of the Acoustical So- ciety of America, vol. 131, no. 4, pp. 2999–3016, 2012
2012
-
[11]
3d-fv-fe aeroacoustic larynx model for investigation of functional based voice disorders,
S. Falk, S. Kniesburges, S. Schoder, B. Jakubaß, P. Maurerlehner, M. Echternach, M. Kaltenbacher, and M. D ¨ollinger, “3d-fv-fe aeroacoustic larynx model for investigation of functional based voice disorders,”Frontiers in physiology, vol. 12, p. 616985, 2021
2021
-
[12]
V oice processing by dynamic glot- tal models with applications to speech enhancement
C. Drioli, A. Calancaet al., “V oice processing by dynamic glot- tal models with applications to speech enhancement.” inINTER- SPEECH, 2011, pp. 1789–1792
2011
-
[13]
Speech-based parameter estimation of an asymmetric vocal fold oscillation model and its application in dis- criminating vocal fold pathologies,
W. Zhao and R. Singh, “Speech-based parameter estimation of an asymmetric vocal fold oscillation model and its application in dis- criminating vocal fold pathologies,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2020, pp. 7344–7348
2020
-
[14]
Toward a simulation-based tool for the treat- ment of vocal fold paralysis,
R. Mittal, X. Zheng, R. Bhardwaj, J. H. Seo, Q. Xue, and S. Bielamowicz, “Toward a simulation-based tool for the treat- ment of vocal fold paralysis,”Frontiers in physiology, vol. 2, p. 19, 2011
2011
-
[15]
Computational fluid dynamics analy- sis of surgical approaches to bilateral vocal fold immobility,
G. Rios, R. J. Morrison, Y . Song, S. J. Fernando, C. Wootten, A. Gelbard, and H. Luo, “Computational fluid dynamics analy- sis of surgical approaches to bilateral vocal fold immobility,”The Laryngoscope, vol. 130, no. 2, pp. E57–E64, 2020
2020
-
[16]
Tuned two-dimensional vocal tracts with piriform fossae for the finite element simulation of vowels,
M. Arnela and D. Ure ˜na, “Tuned two-dimensional vocal tracts with piriform fossae for the finite element simulation of vowels,” Journal of Sound and Vibration, vol. 537, p. 117168, 2022
2022
-
[17]
Deriving vocal fold oscillation informa- tion from recorded voice signals using models of phonation,
W. Zhao and R. Singh, “Deriving vocal fold oscillation informa- tion from recorded voice signals using models of phonation,”En- tropy, vol. 25, no. 7, p. 1039, 2023
2023
-
[18]
Neural operators for accelerating sci- entific simulations and design,
K. Azizzadenesheli, N. Kovachki, Z. Li, M. Liu-Schiaffini, J. Kos- saifi, and A. Anandkumar, “Neural operators for accelerating sci- entific simulations and design,”Nature Reviews Physics, vol. 6, no. 5, pp. 320–328, 2024
2024
-
[19]
Sound propagation in realistic interac- tive 3d scenes with parameterized sources using deep neural op- erators,
N. Borrel-Jensen, S. Goswami, A. P. Engsig-Karup, G. E. Karni- adakis, and C.-H. Jeong, “Sound propagation in realistic interac- tive 3d scenes with parameterized sources using deep neural op- erators,”Proceedings of the National Academy of Sciences, vol. 121, no. 2, p. e2312159120, 2024
2024
-
[20]
Physics- informed deep neural operator networks,
S. Goswami, A. Bora, Y . Yu, and G. E. Karniadakis, “Physics- informed deep neural operator networks,” inMachine learning in modeling and simulation: methods and applications. Springer, 2023, pp. 219–254
2023
-
[21]
Physics-informed neural oper- ator for learning partial differential equations,
Z. Li, H. Zheng, N. Kovachki, D. Jin, H. Chen, B. Liu, K. Aziz- zadenesheli, and A. Anandkumar, “Physics-informed neural oper- ator for learning partial differential equations,”ACM/IMS Journal of Data Science, vol. 1, no. 3, pp. 1–27, 2024
2024
-
[22]
Applications of physics informed neural operators,
S. G. Rosofsky, H. Al Majed, and E. Huerta, “Applications of physics informed neural operators,”Machine Learning: Science and Technology, vol. 4, no. 2, p. 025022, 2023
2023
-
[23]
Learning the solu- tion operator of parametric partial differential equations with physics-informed deeponets,
S. Wang, H. Wang, and P. Perdikaris, “Learning the solu- tion operator of parametric partial differential equations with physics-informed deeponets,”Science advances, vol. 7, no. 40, p. eabi8605, 2021
2021
-
[24]
Physics- informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differ- ential equations,
M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics- informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differ- ential equations,”Journal of Computational physics, vol. 378, pp. 686–707, 2019
2019
-
[25]
Physics and geometry informed neural operator network with application to acoustic scattering,
S. Nair, T. F. Walsh, G. Pickrell, and F. Semperlotti, “Physics and geometry informed neural operator network with application to acoustic scattering,”Mechanical Systems and Signal Processing, vol. 239, p. 113293, 2025
2025
-
[26]
Synthesis of voiced sounds using physics-informed neural networks,
K. Yokota, M. Ogura, and M. Abe, “Synthesis of voiced sounds using physics-informed neural networks,”Acoustical Science and Technology, vol. 45, no. 6, pp. 333–336, 2024
2024
-
[27]
Physics- informed neural networks for speech production,
K. Yokota, R. Harakawa, M. Baba, and M. Iwahashi, “Physics- informed neural networks for speech production,”IEEE Trans- actions on Audio, Speech and Language Processing, vol. 34, pp. 3102–3115, 2026
2026
-
[28]
Learning vocal-tract area and radi- ation with a physics-informed webster model,
M. Lu and J. D. Reiss, “Learning vocal-tract area and radi- ation with a physics-informed webster model,”arXiv preprint arXiv:2602.13834, 2026
arXiv 2026
-
[29]
Learning nonlinear operators via deeponet based on the universal approxi- mation theorem of operators,
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis, “Learning nonlinear operators via deeponet based on the universal approxi- mation theorem of operators,”Nature machine intelligence, vol. 3, no. 3, pp. 218–229, 2021
2021
-
[30]
Synthesis of voiced sounds from a two-mass model of the vocal cords,
K. Ishizaka and J. L. Flanagan, “Synthesis of voiced sounds from a two-mass model of the vocal cords,”Bell system technical jour- nal, vol. 51, no. 6, pp. 1233–1268, 1972
1972
-
[31]
Physics-informed deep learning for nonlinear friction model of bow-string interaction,
X. Luan and G. Scavone, “Physics-informed deep learning for nonlinear friction model of bow-string interaction,” inProceed- ings of the International Conference on Digital Audio Effects (DAFx25), 2025, pp. 150–157
2025
-
[32]
Chaotic vibration induced by turbulent noise in a two-mass model of vocal folds,
J. J. Jiang and Y . Zhang, “Chaotic vibration induced by turbulent noise in a two-mass model of vocal folds,”The Journal of the Acoustical Society of America, vol. 112, no. 5, pp. 2127–2133, 2002
2002
-
[33]
J. L. Flanagan,Speech analysis synthesis and perception. Springer Science & Business Media, 2013
2013
-
[34]
Time-domain simulation of a dis- sipative reed instrument,
A. Thibault and J. Chabassier, “Time-domain simulation of a dis- sipative reed instrument,” ine-Forum Acusticum 2020, 2020
2020
-
[35]
Physics-informed neu- ral network for acoustic resonance analysis in a one-dimensional acoustic tube,
K. Yokota, T. Kurahashi, and M. Abe, “Physics-informed neu- ral network for acoustic resonance analysis in a one-dimensional acoustic tube,”The Journal of the Acoustical Society of America, vol. 156, no. 1, pp. 30–43, 2024
2024
-
[36]
Neural networks fail to learn periodic functions and how to fix it,
L. Ziyin, T. Hartwig, and M. Ueda, “Neural networks fail to learn periodic functions and how to fix it,”Advances in Neural Infor- mation Processing Systems, vol. 33, pp. 1583–1594, 2020
2020
-
[37]
When and why pinns fail to train: A neural tangent kernel perspective,
S. Wang, X. Yu, and P. Perdikaris, “When and why pinns fail to train: A neural tangent kernel perspective,”Journal of Computa- tional Physics, vol. 449, p. 110768, 2022
2022
-
[38]
Physics-informed neural networks with hard constraints for inverse design,
L. Lu, R. Pestourie, W. Yao, Z. Wang, F. Verdugo, and S. G. John- son, “Physics-informed neural networks with hard constraints for inverse design,”SIAM Journal on Scientific Computing, vol. 43, no. 6, pp. B1105–B1132, 2021
2021
-
[39]
Education system in acoustics of speech production us- ing physical models of the human vocal tract,
T. Arai, “Education system in acoustics of speech production us- ing physical models of the human vocal tract,”Acoustical science and technology, vol. 28, no. 3, pp. 190–201, 2007
2007
-
[40]
Monotone piecewise cubic in- terpolation,
F. N. Fritsch and R. E. Carlson, “Monotone piecewise cubic in- terpolation,”SIAM Journal on Numerical Analysis, vol. 17, no. 2, pp. 238–246, 1980
1980
-
[41]
A method for constructing local monotone piecewise cubic interpolants,
F. N. Fritsch and J. Butland, “A method for constructing local monotone piecewise cubic interpolants,”SIAM journal on scien- tific and statistical computing, vol. 5, no. 2, pp. 300–304, 1984
1984
-
[42]
Adam: A method for stochastic optimization,
D. P. Kingma, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[43]
On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks,
S. Wang, H. Wang, and P. Perdikaris, “On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks,”Computer Methods in Applied Mechanics and Engineering, vol. 384, p. 113938, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.