MotionDuet: Dual-Conditioned 3D Human Motion Generation with Video-Regularized Text Learning
Pith reviewed 2026-05-21 19:38 UTC · model grok-4.3
The pith
MotionDuet aligns 3D motion generation to video feature distributions while using text for semantic control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MotionDuet is a multimodal framework that aligns motion generation with the distribution of video-derived representations. In this dual-conditioning paradigm, video cues extracted from a pretrained model ground low-level motion dynamics while textual prompts provide semantic intent. To bridge the distribution gap across modalities, Dual-stream Unified Encoding and Transformation fuses video-informed cues into the motion latent space via unified encoding and dynamic attention, while Distribution-Aware Structural Harmonization aligns motion trajectories with both distributional and structural statistics of video features. An auto-guidance mechanism balances the two signals by leveraging a weak
What carries the argument
Dual-stream Unified Encoding and Transformation (DUET) together with Distribution-Aware Structural Harmonization (DASH) loss, which inject video cues into the motion latent space and enforce statistical and structural agreement with video features.
If this is right
- Generated motions exhibit temporal coherence closer to real video statistics.
- Semantic control from text remains effective while low-level dynamics improve.
- The auto-guidance step increases controllability without reducing output diversity.
- The same alignment principle applies to other motion domains such as hand or object trajectories.
Where Pith is reading between the lines
- Pretrained video encoders could serve as regularizers for other conditional generative models in graphics.
- The dual-stream design suggests a general template for fusing high-level language with low-level sensory data in embodied AI tasks.
- If the distribution alignment holds across datasets, the method may reduce the need for large motion-capture collections.
Load-bearing premise
Video cues extracted from a pretrained model accurately ground low-level motion dynamics and the DUET and DASH components reliably bridge the distribution gap between text and video modalities.
What would settle it
Generate motions with the video-conditioning path disabled and measure whether the resulting joint-velocity and acceleration histograms diverge measurably from those computed on real captured videos.
Figures









read the original abstract
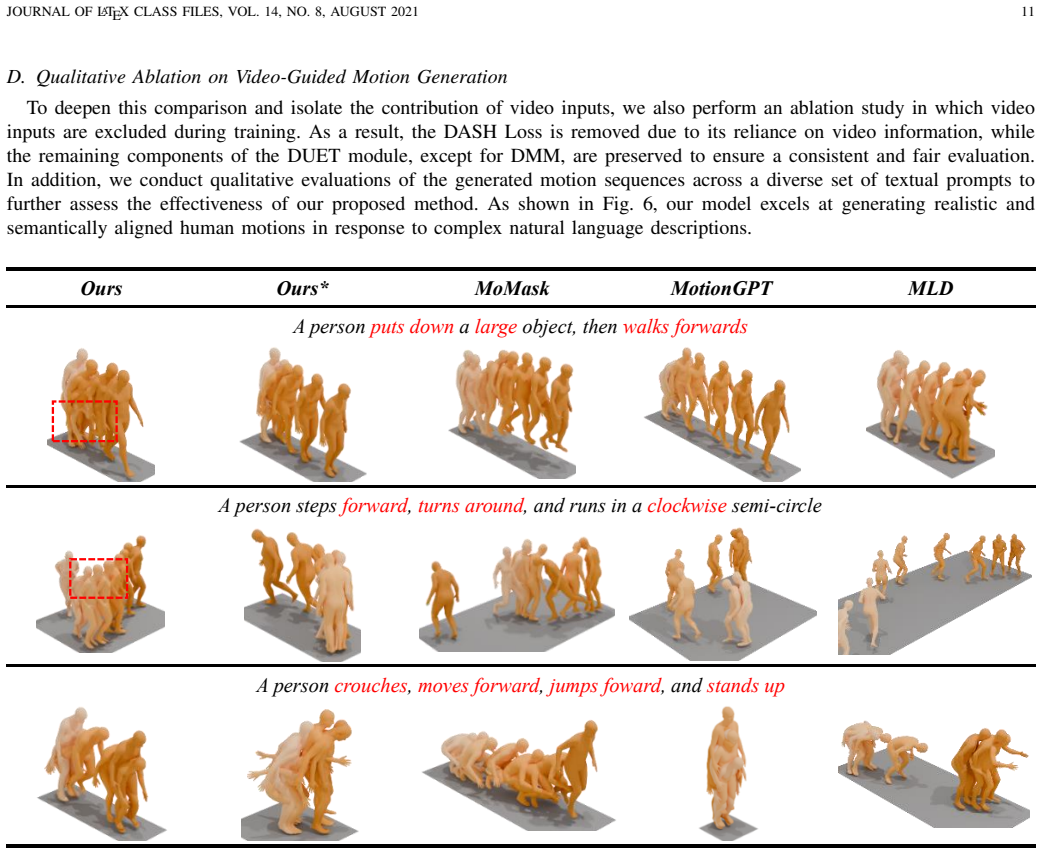
3D Human motion generation is pivotal across film, animation, gaming, and embodied intelligence. Traditional 3D motion synthesis relies on costly motion capture, while recent work shows that 2D videos provide rich, temporally coherent observations of human behavior. Existing approaches, however, either map high-level text descriptions to motion or rely solely on video conditioning, leaving a gap between generated dynamics and real-world motion statistics. We introduce MotionDuet, a multimodal framework that aligns motion generation with the distribution of video-derived representations. In this dual-conditioning paradigm, video cues extracted from a pretrained model (e.g., VideoMAE) ground low-level motion dynamics, while textual prompts provide semantic intent. To bridge the distribution gap across modalities, we propose Dual-stream Unified Encoding and Transformation (DUET) and a Distribution-Aware Structural Harmonization (DASH) loss. DUET fuses video-informed cues into the motion latent space via unified encoding and dynamic attention, while DASH aligns motion trajectories with both distributional and structural statistics of video features. An auto-guidance mechanism further balances textual and visual signals by leveraging a weakened copy of the model, enhancing controllability without sacrificing diversity. Extensive experiments demonstrate that MotionDuet generates realistic and controllable human motions, surpassing strong state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MotionDuet, a dual-conditioned framework for 3D human motion generation. Text prompts supply semantic intent while video cues from a pretrained model (e.g., VideoMAE) are intended to ground low-level dynamics. The method proposes Dual-stream Unified Encoding and Transformation (DUET) to fuse video-informed cues into the motion latent space via unified encoding and dynamic attention, together with a Distribution-Aware Structural Harmonization (DASH) loss that aligns motion trajectories with both distributional and structural statistics of the video features. An auto-guidance mechanism balances the two conditioning signals. The central claim is that the resulting motions are realistic and controllable and surpass strong state-of-the-art baselines.
Significance. If the alignment claims are substantiated, the work would offer a concrete route to close the modality gap between high-level text and temporally coherent video observations, potentially improving fidelity in animation, gaming, and embodied-AI pipelines. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described, so the significance rests entirely on the empirical demonstration of gap reduction and baseline improvement.
major comments (2)
- [Abstract] Abstract: the headline claim that 'extensive experiments demonstrate that MotionDuet generates realistic and controllable human motions, surpassing strong state-of-the-art baselines' is unsupported by any visible quantitative results, ablation tables, MMD/Wasserstein distances, or failure-case analysis. Without these data the central claim cannot be evaluated.
- [Method] Method description of DUET and DASH: the text states that DUET 'fuses video-informed cues into the motion latent space via unified encoding and dynamic attention' and that DASH 'aligns motion trajectories with both distributional and structural statistics,' yet supplies no explicit loss equations, feature-space distance formulations, or implementation details. This prevents verification that the proposed components actually close the modality gap for complex or fast motions, which is load-bearing for the dual-conditioning claim.
minor comments (1)
- [Abstract] The acronym expansions for DUET and DASH are introduced without a short parenthetical gloss on first use; a one-sentence high-level gloss would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below and have revised the paper to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'extensive experiments demonstrate that MotionDuet generates realistic and controllable human motions, surpassing strong state-of-the-art baselines' is unsupported by any visible quantitative results, ablation tables, MMD/Wasserstein distances, or failure-case analysis. Without these data the central claim cannot be evaluated.
Authors: We thank the referee for highlighting this issue. The full manuscript contains quantitative results in Section 4, including MMD and Wasserstein distances, ablation studies, and baseline comparisons that support the claim. To make this immediately visible, we have revised the abstract to explicitly reference these experiments and key metrics. We have also added a concise failure-case discussion in the main text with further details moved to the supplement. revision: yes
-
Referee: [Method] Method description of DUET and DASH: the text states that DUET 'fuses video-informed cues into the motion latent space via unified encoding and dynamic attention' and that DASH 'aligns motion trajectories with both distributional and structural statistics,' yet supplies no explicit loss equations, feature-space distance formulations, or implementation details. This prevents verification that the proposed components actually close the modality gap for complex or fast motions, which is load-bearing for the dual-conditioning claim.
Authors: We agree that the original description lacked sufficient mathematical detail. In the revised manuscript we have added the explicit loss equations for DASH (including distributional and structural alignment terms with their feature-space distance formulations), the precise formulation of the unified encoding and dynamic attention mechanism in DUET, and additional implementation details such as hyper-parameters and how the components behave on fast or complex motions. These additions directly enable verification of the modality-gap reduction. revision: yes
Circularity Check
No circularity in derivation; components introduced as independent contributions
full rationale
The paper defines DUET (Dual-stream Unified Encoding and Transformation) and DASH (Distribution-Aware Structural Harmonization) loss as new architectural and objective elements to align video-derived features with motion latents. No equations or steps in the abstract or described framework reduce a claimed prediction or result back to a fitted parameter or self-citation by construction. The dual-conditioning paradigm and auto-guidance are presented as design choices justified by the goal of bridging modality gaps, with performance claims resting on external experiments rather than internal redefinitions. This is a standard non-circular introduction of a multimodal model.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained video models such as VideoMAE provide representations that ground low-level human motion dynamics
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DUET fuses video-informed cues into the motion latent space via unified encoding and dynamic attention, while DASH aligns motion trajectories with both distributional and structural statistics of video features.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
An auto-guidance mechanism further balances textual and visual signals by leveraging a weakened copy of the model
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
AnchorRoute: Human Motion Synthesis with Interval-Routed Sparse Contro
AnchorRoute couples anchor-conditioned generation via AnchorKV on a frozen text-to-motion diffusion prior with residual-routed refinement through RouteSolver on piecewise-affine interval bases.
Reference graph
Works this paper leans on
-
[1]
Motiondiffuse: Text-driven human motion generation with diffusion model,
M. Zhang, Z. Cai, L. Pan, F. Hong, X. Guo, L. Yang, and Z. Liu, “Motiondiffuse: Text-driven human motion generation with diffusion model,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 46, no. 6, pp. 4115–4128, 2024. I, II
work page 2024
-
[2]
Revideo: Remake a video with motion and content control,
C. Mou, M. Cao, X. Wang, Z. Zhang, Y . Shan, and J. Zhang, “Revideo: Remake a video with motion and content control,”Advances in Neural Information Processing Systems, vol. 37, pp. 18 481–18 505, 2024. I
work page 2024
-
[3]
Continuous, subject-specific attribute control in t2i models by identifying semantic directions,
S. A. Baumann, F. Krause, M. Neumayr, N. Stracke, M. Sevi, V . T. Hu, and B. Ommer, “Continuous, subject-specific attribute control in t2i models by identifying semantic directions,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 13 231– 13 241. I
work page 2025
-
[4]
Fg-t2m++: Llms-augmented fine-grained text driven human motion generation,
Y . Wang, M. Li, J. Liu, Z. Leng, F. W. Li, Z. Zhang, and X. Liang, “Fg-t2m++: Llms-augmented fine-grained text driven human motion generation,”International Journal of Computer Vision, pp. 1–17, 2025. I
work page 2025
-
[5]
H. Jeong, G. Y . Park, and J. C. Ye, “Vmc: Video motion customization using temporal attention adaption for text-to-video diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9212–9221. I
work page 2024
-
[6]
Intergen: Diffusion- based multi-human motion generation under complex interactions,
H. Liang, W. Zhang, W. Li, J. Yu, and L. Xu, “Intergen: Diffusion- based multi-human motion generation under complex interactions,” International Journal of Computer Vision, vol. 132, no. 9, pp. 3463– 3483, 2024. I
work page 2024
-
[7]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023. I
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
S. Yu, S. Kwak, H. Jang, J. Jeong, J. Huang, J. Shin, and S. Xie, “Rep- resentation alignment for generation: Training diffusion transformers is easier than you think,”arXiv preprint arXiv:2410.06940, 2024. I
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Parco: Part-coordinating text-to-motion synthesis,
Q. Zou, S. Yuan, S. Du, Y . Wang, C. Liu, Y . Xu, J. Chen, and X. Ji, “Parco: Part-coordinating text-to-motion synthesis,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 126–143. II
work page 2024
-
[10]
Exploring text-to-motion generation with human preference,
J. Sheng, M. Lin, A. Zhao, K. Pruvost, Y .-H. Wen, Y . Li, G. Huang, and Y .-J. Liu, “Exploring text-to-motion generation with human preference,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1888–1899. II
work page 2024
-
[11]
Learning variational motion prior for video-based motion capture,
X. Chen, Z. Su, L. Yang, P. Cheng, L. Xu, B. Fu, and G. Yu, “Learning variational motion prior for video-based motion capture,”arXiv preprint arXiv:2210.15134, 2022. II
-
[12]
Dancecamera3d: 3d camera movement synthesis with music and dance,
Z. Wang, J. Jia, S. Sun, H. Wu, R. Han, Z. Li, D. Tang, J. Zhou, and J. Luo, “Dancecamera3d: 3d camera movement synthesis with music and dance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7892–7901. II
work page 2024
-
[13]
Bidirectional autoregessive diffusion model for dance generation,
C. Zhang, Y . Tang, N. Zhang, R.-S. Lin, M. Han, J. Xiao, and S. Wang, “Bidirectional autoregessive diffusion model for dance generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 687–696. II
work page 2024
-
[14]
Modi: Unconditional motion synthesis from diverse data,
S. Raab, I. Leibovitch, P. Li, K. Aberman, O. Sorkine-Hornung, and D. Cohen-Or, “Modi: Unconditional motion synthesis from diverse data,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, June 2023, pp. 13 873–13 883. II
work page 2023
-
[15]
Fg-t2m: Fine-grained text-driven human motion generation via diffusion model,
Y . Wang, Z. Leng, F. W. B. Li, S.-C. Wu, and X. Liang, “Fg-t2m: Fine-grained text-driven human motion generation via diffusion model,” inInternational Conference on Computer Vision, October 2023, pp. 22 035–22 044. II
work page 2023
-
[16]
Synthesis of compositional animations from textual descriptions,
A. Ghosh, N. Cheema, C. Oguz, C. Theobalt, and P. Slusallek, “Synthesis of compositional animations from textual descriptions,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 1396–1406. II
work page 2021
-
[17]
Motiongpt: Human motion as a foreign language,
B. Jiang, X. Chen, W. Liu, J. Yu, G. Yu, and T. Chen, “Motiongpt: Human motion as a foreign language,”Advances in neural information processing systems, vol. 36, 2024. II
work page 2024
-
[18]
Momask: Generative masked modeling of 3d human motions,
C. Guo, Y . Mu, M. G. Javed, S. Wang, and L. Cheng, “Momask: Generative masked modeling of 3d human motions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1900–1910. II
work page 2024
-
[19]
Smpler-x: Scaling up expressive human pose and shape estimation,
Z. Cai, W. Yin, A. Zeng, C. Wei, Q. Sun, W. Yanjun, H. E. Pang, H. Mei, M. Zhang, L. Zhanget al., “Smpler-x: Scaling up expressive human pose and shape estimation,”Advances in neural information processing systems, vol. 36, 2024. II
work page 2024
-
[20]
Smpl: A skinned multi-person linear model,
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black, “Smpl: A skinned multi-person linear model,” inSeminal Graphics Papers: Pushing the Boundaries, Volume 2, 2023, pp. 851–866. II
work page 2023
-
[21]
Disentangled clothed avatar generation from text descriptions,
J. Wang, Y . Liu, Z. Dou, Z. Yu, Y . Liang, C. Lin, R. Xie, L. Song, X. Li, and W. Wang, “Disentangled clothed avatar generation from text descriptions,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 381–401. II
work page 2024
-
[22]
Sesdf: Self-evolved signed distance field for implicit 3d clothed human reconstruction,
Y . Cao, K. Han, and K.-Y . K. Wong, “Sesdf: Self-evolved signed distance field for implicit 3d clothed human reconstruction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4647–4657. II
work page 2023
-
[23]
Generating diverse and natural 3d human motions from text,
C. Guo, S. Zou, X. Zuo, S. Wang, W. Ji, X. Li, and L. Cheng, “Generating diverse and natural 3d human motions from text,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5152–5161. II, IV-A, A
work page 2022
-
[24]
Deepphase: Periodic autoencoders for learning motion phase manifolds,
S. Starke, I. Mason, and T. Komura, “Deepphase: Periodic autoencoders for learning motion phase manifolds,”ACM Transactions on Graphics (TOG), vol. 41, no. 4, pp. 1–13, 2022. II
work page 2022
-
[25]
Executing your commands via motion diffusion in latent space,
X. Chen, B. Jiang, W. Liu, Z. Huang, B. Fu, T. Chen, and G. Yu, “Executing your commands via motion diffusion in latent space,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 000–18 010. II, III-D1, IV-A
work page 2023
-
[26]
Mcre: Multimodal conditional representation and editing for text-motion generation,
T. Sun, X. Li, T. Shi, J. Peng, S. Zheng, and H. Kim, “Mcre: Multimodal conditional representation and editing for text-motion generation,” in European Conference on Computer Vision. Springer, 2024, pp. 406–
work page 2024
-
[27]
Tl- control: Trajectory and language control for human motion synthesis,
W. Wan, Z. Dou, T. Komura, W. Wang, D. Jayaraman, and L. Liu, “Tl- control: Trajectory and language control for human motion synthesis,” in European Conference on Computer Vision. Springer, 2024, pp. 37–54. II
work page 2024
-
[28]
Rethinking the spa- tial inconsistency in classifier-free diffusion guidance,
D. Shen, G. Song, Z. Xue, F.-Y . Wang, and Y . Liu, “Rethinking the spa- tial inconsistency in classifier-free diffusion guidance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9370–9379. II
work page 2024
-
[29]
Tcfg: Tangential damping classifier-free guidance,
M. Kwon, J. Jeong, Y . T. Hsiao, Y . Uhet al., “Tcfg: Tangential damping classifier-free guidance,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 2620–2629. II
work page 2025
-
[30]
Videomae v2: Scaling video masked autoencoders with dual masking,
L. Wang, B. Huang, Z. Zhao, Z. Tong, Y . He, Y . Wang, Y . Wang, and Y . Qiao, “Videomae v2: Scaling video masked autoencoders with dual masking,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14 549–14 560. III-A1
work page 2023
-
[31]
Guiding a diffusion model with a bad version of itself,
T. Karras, M. Aittala, T. Kynk ¨a¨anniemi, J. Lehtinen, T. Aila, and S. Laine, “Guiding a diffusion model with a bad version of itself,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 52 996– 53 021, 2024. III-A2, III-C, IV-B2, K
work page 2024
-
[32]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763. III-D2
work page 2021
-
[33]
Facenet: A unified embed- ding for face recognition and clustering,
F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embed- ding for face recognition and clustering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–
work page 2015
-
[34]
Computational optimal transport: With applications to data science,
G. Peyr ´e, M. Cuturiet al., “Computational optimal transport: With applications to data science,”Foundations and Trends® in Machine Learning, vol. 11, no. 5-6, pp. 355–607, 2019. III-D2
work page 2019
-
[35]
Generating diverse and natural 3d human motions from text,
C. Guo, S. Zou, X. Zuo, S. Wang, W. Ji, X. Li, and L. Cheng, “Generating diverse and natural 3d human motions from text,” in JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 9 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 5152–5161. B
work page 2021
-
[36]
Action2motion: Conditioned generation of 3d human motions,
C. Guo, X. Zuo, S. Wang, S. Zou, Q. Sun, A. Deng, M. Gong, and L. Cheng, “Action2motion: Conditioned generation of 3d human motions,” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 2021–2029. B
work page 2020
-
[37]
Amass: Archive of motion capture as surface shapes,
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black, “Amass: Archive of motion capture as surface shapes,” in International Conference on Computer Vision), Oct 2019. [Online]. Available: https://amass.is.tue.mpg.de B
work page 2019
-
[38]
Motion capture from internet videos,
J. Dong, Q. Shuai, Y . Zhang, X. Liu, X. Zhou, and H. Bao, “Motion capture from internet videos,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 210–227. E JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10 APPENDIX Appendix A. Evaluation Metrics (1) Motion Quality: Fr ´echet Inception Distance (FID) quantifies the similarity betw...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.