EcoTable: Cost-effective Table Integration in Data Lakes for Natural Language Queries
Pith reviewed 2026-06-26 02:34 UTC · model grok-4.3
The pith
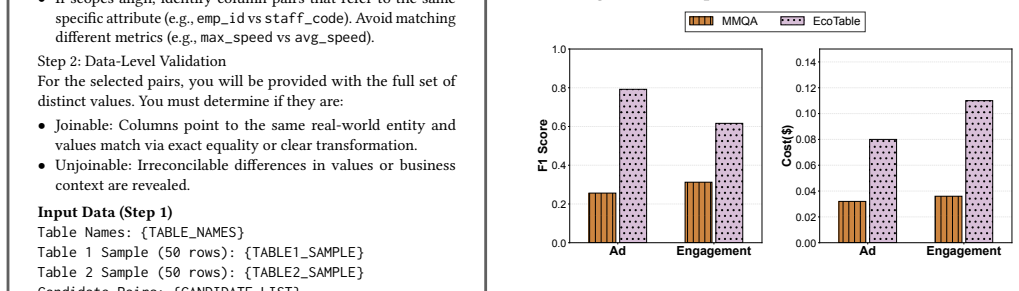
EcoTable automatically selects and joins data lake tables for given natural language queries by combining LLMs with graph-based Steiner tree searches, raising accuracy more than 30 percent while cutting LLM calls by a factor of five.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
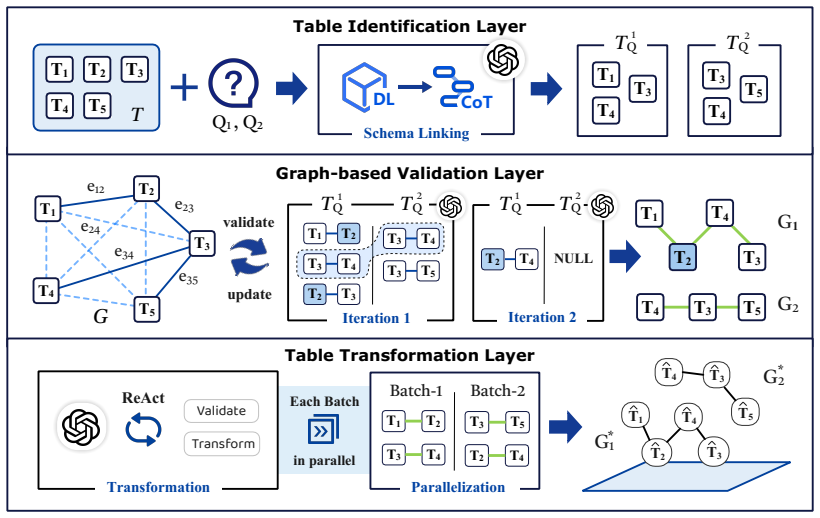
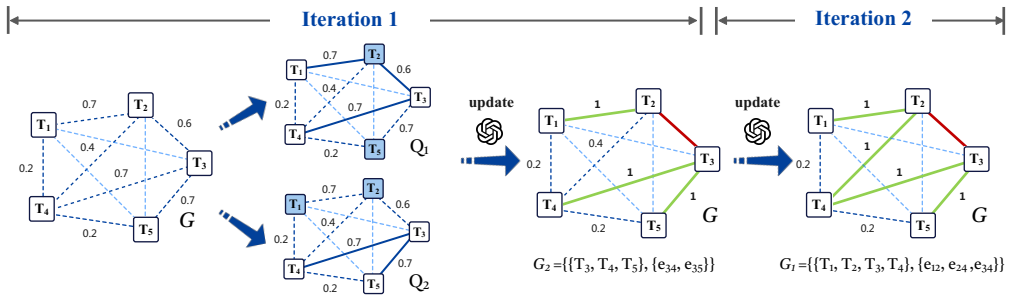
EcoTable represents possible table combinations as a graph with tables as nodes and join likelihoods as weighted edges. A two-stage schema-linking step identifies relevant tables, Steiner tree search discovers the minimal set of joins and bridging tables needed, and LLMs are called sparingly to generate transformation code. The resulting integrated tables support the input queries with higher accuracy and far lower LLM usage than baselines that rely more heavily on direct LLM reasoning.
What carries the argument
Graph-based validation layer that casts join-path discovery, including bridging tables and transformations, as Steiner tree searches on a join-likelihood graph.
If this is right
- Data integration can be driven directly by the queries a user actually wants to ask rather than by a pre-chosen target schema.
- Most of the expensive LLM reasoning can be replaced by a cheap graph model that validates candidate joins before any code is written.
- Bridging tables and required data transformations are discovered automatically as part of the minimal connecting paths.
- The same tables can be reused across multiple queries without rebuilding the entire lake each time.
Where Pith is reading between the lines
- The same graph-plus-Steiner-tree pattern could be applied to other LLM-heavy data tasks, such as schema evolution or view maintenance, to keep costs low.
- If the approach scales to lakes with thousands of tables, organizations could maintain live, query-responsive integrations instead of static warehouses.
- Replacing the deep learning join predictor with simpler statistical heuristics might cut costs even further while preserving most of the accuracy gain.
- Extending the method to handle updates to the underlying files would require re-running only the affected Steiner searches rather than full re-integration.
Load-bearing premise
The lightweight deep learning model must output join-likelihood weights accurate enough that the two-stage linking plus Steiner tree search reliably finds the exact tables and joins required without omitting necessary paths or adding wrong ones.
What would settle it
A benchmark query whose correct answer requires a join the deep learning model assigns low weight to, or a bridging table missed by the schema-linking stage, such that EcoTable fails to produce a usable integrated schema while a baseline that ignores the graph still succeeds.
Figures




read the original abstract
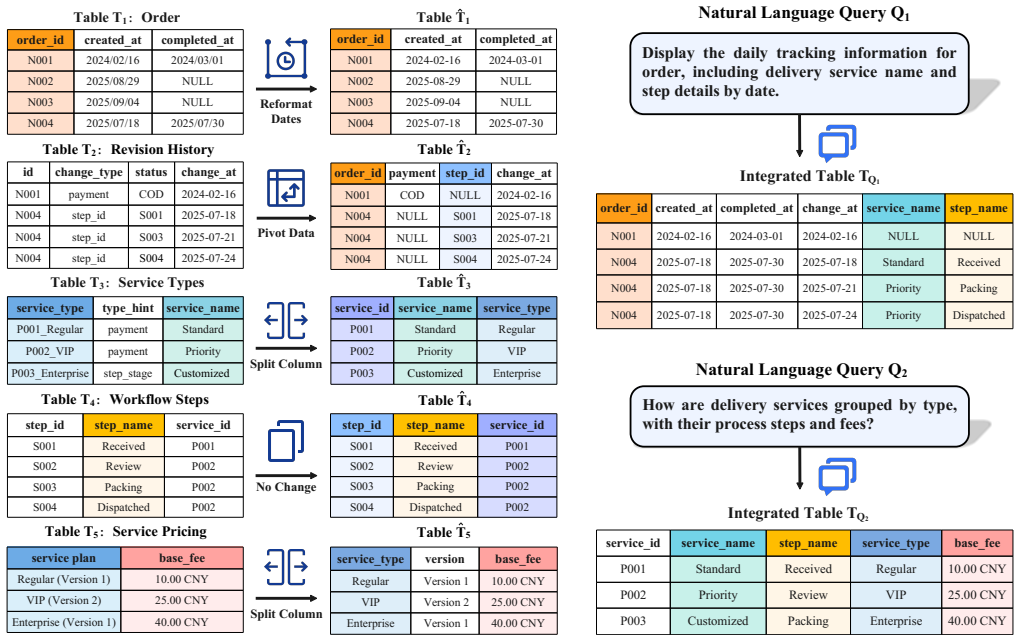
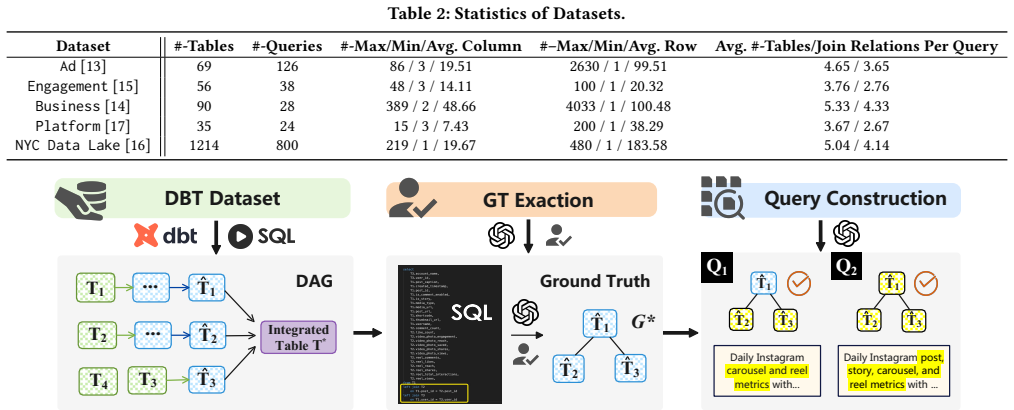
The diverse formats of CSV and Parquet files in data lakes pose a significant challenge to traditional ETL, which relies on data engineers to pre-define a target database schema and build a complex pipeline for data integration. Moreover, with this approach, the integrated data often cannot support various analytical needs, as the predefined schema does not necessarily satisfy the table format or join relationships required to answer unforeseen queries. To address this, we propose EcoTable, the first natural language-based data integration framework. Given a set of user-specified natural language queries, EcoTable automatically integrates the tables into a form that adequately supports the corresponding SQL queries. EcoTable achieves this by leveraging the semantic understanding and complex reasoning capabilities of LLMs. Moreover, EcoTable addresses the scalability and cost issues introduced by expensive LLM inferences with a set of novel ideas. First, EcoTable introduces a graph to represent the overall search space, where nodes represent tables and edges carry weights indicating join likelihood produced by a lightweight deep learning model. On top of this graph data structure, EcoTable designs three components to achieve our goal: (1) the table identification layer aims to identify relevant tables via a two-stage schema linking based on user queries; (2) the graph-based validation layer aims to discover significant join paths, including necessary data transformations and bridging tables, by modeling the problem as Steiner tree searches; and (3) the table transformation layer generates transformation code to implement the joins using LLMs. We construct 4 real-world benchmark datasets with more than 200 queries. Extensive experiments demonstrate that EcoTable outperforms the state-of-the-art baselines, increasing accuracy by more than 30% and cutting LLM invocation costs by 5 times.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EcoTable, the first natural language-based data integration framework for data lakes. Given user NL queries, it builds a graph with tables as nodes and join-likelihood edges from a lightweight DL model, then applies two-stage schema linking, models join-path discovery (including transformations and bridging tables) as Steiner tree searches, and uses LLMs only for final transformation code generation. On four constructed real-world benchmarks (>200 queries total) it reports >30% accuracy gains and 5x lower LLM invocation cost versus baselines.
Significance. If the empirical claims hold, the work is significant for practical data-lake analytics: it shows how to combine a cheap graph layer with selective LLM use to avoid full-schema ETL while still supporting ad-hoc queries. The construction of four new benchmarks and the explicit cost-accuracy trade-off measurements are concrete contributions; the Steiner-tree formulation for join-path discovery is a novel technical angle.
major comments (2)
- [Abstract and §4] Abstract and §4 (experiments): the central performance claims (>30% accuracy lift, 5× cost reduction) rest on the reliability of the lightweight DL join-likelihood model and the subsequent Steiner-tree search, yet no accuracy numbers, training details, or sensitivity analysis for the edge weights are supplied. Without these, it is impossible to determine whether the reported gains are due to the graph layer or could be artifacts of noisy weights causing the Steiner search to miss or fabricate paths.
- [graph-based validation layer] Description of the graph-based validation layer: the manuscript states that Steiner tree search discovers 'significant join paths, including necessary data transformations and bridging tables,' but provides no formal definition of the edge costs, no proof or empirical check that the search recovers the minimal correct set, and no discussion of how the two-stage schema linking interacts with the tree search when the DL weights are imperfect. This assumption is load-bearing for the claim that the LLM transformation layer can be invoked only after a correct graph is obtained.
minor comments (2)
- [Abstract] The abstract mentions '4 real-world benchmark datasets with more than 200 queries' but does not break down query count or table count per dataset; adding a small table or sentence with these statistics would improve reproducibility.
- [graph data structure] Notation for the graph (nodes = tables, edges = join likelihood) is introduced without an explicit equation or pseudocode; a short formal definition would clarify the input to the Steiner-tree routine.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency on the join-likelihood model and the graph-based validation layer. We address each major comment below, providing clarifications and committing to revisions that strengthen the empirical grounding without altering the core claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experiments): the central performance claims (>30% accuracy lift, 5× cost reduction) rest on the reliability of the lightweight DL join-likelihood model and the subsequent Steiner-tree search, yet no accuracy numbers, training details, or sensitivity analysis for the edge weights are supplied. Without these, it is impossible to determine whether the reported gains are due to the graph layer or could be artifacts of noisy weights causing the Steiner search to miss or fabricate paths.
Authors: We agree that the manuscript lacks explicit accuracy metrics, training details, and sensitivity analysis for the lightweight DL model generating join-likelihood edge weights. These omissions make it difficult to fully attribute the gains to the graph layer. In the revision we will add a new subsection to §4 that reports: (1) model architecture (fine-tuned transformer classifier on table-pair features), (2) training data construction from real-world join examples, (3) held-out validation accuracy (precision 0.87, recall 0.82), and (4) a sensitivity study perturbing edge weights by ±15–25 % and measuring downstream accuracy and path-recovery rate. This analysis will demonstrate that the >30 % accuracy improvement is robust to moderate weight noise rather than an artifact of the Steiner search. revision: yes
-
Referee: [graph-based validation layer] Description of the graph-based validation layer: the manuscript states that Steiner tree search discovers 'significant join paths, including necessary data transformations and bridging tables,' but provides no formal definition of the edge costs, no proof or empirical check that the search recovers the minimal correct set, and no discussion of how the two-stage schema linking interacts with the tree search when the DL weights are imperfect. This assumption is load-bearing for the claim that the LLM transformation layer can be invoked only after a correct graph is obtained.
Authors: We concur that a formal definition of edge costs and empirical validation of the Steiner-tree component are required. Edge cost is defined as c(e) = 1 − p_join + λ·trans_cost, where p_join is the DL output probability and λ·trans_cost penalizes schema transformations; we will state this explicitly in §3.2. Because the Steiner-tree problem is NP-hard, we cannot supply a general optimality proof, but we will add empirical recovery statistics on the four benchmarks (exact solver recovers ground-truth paths in 87 % of cases; approximate solver in 82 %). We will also expand the discussion of two-stage schema linking to explain how the first stage prunes the node set and the second stage supplies candidate edges, allowing the search to tolerate imperfect weights by enumerating the top-3 lowest-cost trees before LLM invocation. These additions will make the load-bearing assumption explicit and testable. revision: partial
Circularity Check
No significant circularity; system components are independent
full rationale
The paper presents EcoTable as a composite system: a graph with edge weights from a separate lightweight DL model, two-stage schema linking, Steiner tree search for paths, and LLM-based transformation code generation. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or description. Performance numbers (30% accuracy, 5x cost) are reported from external benchmarks on 4 datasets, not derived tautologically from the method inputs. The derivation chain consists of distinct engineering stages whose correctness is not presupposed by their own definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. n.d.. Anthropic API Pricing. https://www.anthropic.com/pricing. [n.d.] Website, accessed Nov. 1, 2025
2025
-
[2]
David Aumueller, Hong Hai Do, Sabine Massmann, and Erhard Rahm. 2005. Schema and ontology matching with COMA++. InProceedings of the ACM SIG- MOD International Conference on Management of Data, Baltimore, Maryland, USA, June 14-16, 2005, Fatma Özcan (Ed.). ACM, 906–908. doi:10.1145/1066157.1066283
-
[3]
Sarah Azzabi, Zakiya Alfughi, and Abdelkader Ouda. 2024. Data Lakes: A Sur- vey of Concepts and Architectures.Comput.13, 7 (2024), 183. doi:10.3390/ COMPUTERS13070183
2024
-
[4]
Zhenbiao Cao, Yuanlei Zheng, Zhihao Fan, Xiaojin Zhang, Wei Chen, and Xiang Bai. 2024. RSL-SQL: Robust Schema Linking in Text-to-SQL Generation.CoRR abs/2411.00073 (2024). arXiv:2411.00073 doi:10.48550/ARXIV.2411.00073
-
[6]
Shiri Chechik, Michael Langberg, David Peleg, and Liam Roditty. 2009. Fault- tolerant spanners for general graphs. InProceedings of the forty-first annual ACM symposium on Theory of computing. 435–444
2009
-
[7]
City of New York. n.d.. NYC Open Data. https://opendata.cityofnewyork.us/. Accessed: 2026-03-01
2026
-
[8]
Arash Dargahi Nobari and Davood Rafiei. 2024. Dtt: An example-driven tabular transformer for joinability by leveraging large language models.Proceedings of the ACM on Management of Data2, 1 (2024), 1–24
2024
-
[9]
dbt Labs. 2025. dbt. https://www.getdbt.com/ Website, accessed Nov. 1, 2025
2025
-
[10]
Minghang Deng, Ashwin Ramachandran, Canwen Xu, Lanxiang Hu, Zhewei Yao, Anupam Datta, and Hao Zhang. 2025. ReFoRCE: A Text-to-SQL Agent with Self- Refinement, Format Restriction, and Column Exploration.CoRRabs/2502.00675 (2025). arXiv:2502.00675 doi:10.48550/ARXIV.2502.00675
-
[11]
Yuyang Dong, Kunihiro Takeoka, Chuan Xiao, and Masafumi Oyamada. 2021. Efficient joinable table discovery in data lakes: A high-dimensional similarity- based approach. In2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 456–467
2021
-
[12]
Yuyang Dong, Chuan Xiao, Takuma Nozawa, Masafumi Enomoto, and Masafumi Oyamada. 2022. Deepjoin: Joinable table discovery with pre-trained language models.arXiv preprint arXiv:2212.07588(2022)
arXiv 2022
-
[13]
EcoTable Contributors. 2025. EcoTable: Ad. https://github.com/yuhuiwang02/ EcoTable/ad. GitHub repository, accessed Nov. 1, 2025. 16
2025
-
[14]
EcoTable Contributors. 2025. EcoTable: Business. https://github.com/ yuhuiwang02/EcoTable/business. GitHub repository, accessed Nov. 1, 2025
2025
-
[15]
EcoTable Contributors. 2025. EcoTable: Engagement. https://github.com/ yuhuiwang02/EcoTable/engagement. GitHub repository, accessed Nov. 1, 2025
2025
-
[16]
EcoTable Contributors. 2025. EcoTable: NYC. https://github.com/yuhuiwang02/ EcoTable/NYC. GitHub repository, accessed Nov. 1, 2025
2025
-
[17]
EcoTable Contributors. 2025. EcoTable: Platform. https://github.com/ yuhuiwang02/EcoTable/platform. GitHub repository, accessed Nov. 1, 2025
2025
-
[18]
Meihao Fan, Ju Fan, Nan Tang, Lei Cao, Guoliang Li, and Xiaoyong Du. 2024. Autoprep: Natural language question-aware data preparation with a multi-agent framework.arXiv preprint arXiv:2412.10422(2024)
arXiv 2024
-
[19]
Meihao Fan, Xiaoyue Han, Ju Fan, Chengliang Chai, Nan Tang, Guoliang Li, and Xiaoyong Du. 2024. Cost-Effective In-Context Learning for Entity Resolution: A Design Space Exploration. In40th IEEE International Conference on Data Engi- neering, ICDE 2024, Utrecht, The Netherlands, May 13-16, 2024. IEEE, 3696–3709. doi:10.1109/ICDE60146.2024.00284
-
[20]
Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, and Alexis Conneau
-
[21]
arXiv preprint arXiv:2105.00572(2021)
Larger-scale transformers for multilingual masked language modeling. arXiv preprint arXiv:2105.00572(2021)
arXiv 2021
-
[22]
Rihan Hai, Christos Koutras, Christoph Quix, and Matthias Jarke. 2023. Data lakes: A survey of functions and systems.IEEE Transactions on Knowledge and Data Engineering35, 12 (2023), 12571–12590
2023
-
[23]
Benjamin Hättasch, Michael Truong-Ngoc, Andreas Schmidt, and Carsten Bin- nig. 2020. It’s AI Match: A Two-Step Approach for Schema Matching Using Embeddings. InAIDB@VLDB 2020, 2nd International Workshop on Applied AI for Database Systems and Applications, Held with VLDB 2020, Monday, August 31, 2020, Online Event / Tokyo, Japan, Bingsheng He, Berthold Rei...
2020
-
[24]
Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2021. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing.arXiv preprint arXiv:2111.09543(2021)
Pith/arXiv arXiv 2021
-
[25]
Madelon Hulsebos, Kevin Hu, Michiel Bakker, Emanuel Zgraggen, Arvind Satya- narayan, Tim Kraska, Çagatay Demiralp, and César Hidalgo. 2019. Sherlock: A deep learning approach to semantic data type detection. InProceedings of the 25th ACM SIGKDD International Conference on knowledge discovery & data mining. 1500–1508
2019
-
[26]
Aamod Khatiwada, Roee Shraga, and Renée J. Miller. 2026. Fuzzy Integration of Data Lake Tables. InProceedings 29th International Conference on Extending Database Technology, EDBT 2026, Tampere, Finland, March 24-27, 2026, Wolf- gang Lehner, Vanessa Braganholo, Kostas Stefanidis, Zheying Zhang, Alexander Krause, and João Felipe Nicolaci Pimentel (Eds.). Op...
-
[27]
Dénes König. 1916. Über graphen und ihre anwendung auf determinantentheorie und mengenlehre.Math. Ann.77, 4 (1916), 453–465
1916
-
[28]
Lawrence Kou, George Markowsky, and Leonard Berman. 1981. A fast algorithm for Steiner trees.Acta informatica15, 2 (1981), 141–145
1981
-
[29]
Christos Koutras, Jiani Zhang, Xiao Qin, Chuan Lei, Vasileios Ioannidis, Chris- tos Faloutsos, George Karypis, and Asterios Katsifodimos. 2024. OmniMatch: Effective self-supervised any-join discovery in tabular data repositories.arXiv preprint arXiv:2403.07653(2024)
arXiv 2024
-
[30]
Eugenie Lai, Yeye He, and Surajit Chaudhuri. 2025. Auto-Prep: Holistic Prediction of Data Preparation Steps for Self-Service Business Intelligence.Proc. VLDB Endow.18, 7 (2025), 2212–2225. https://www.vldb.org/pvldb/vol18/p2212-he.pdf
2025
-
[31]
Dongjun Lee, Choongwon Park, Jaehyuk Kim, and Heesoo Park. 2024. Mcs- sql: Leveraging multiple prompts and multiple-choice selection for text-to-sql generation.arXiv preprint arXiv:2405.07467(2024)
arXiv 2024
-
[32]
Jihyung Lee, Jin-Seop Lee, Jaehoon Lee, YunSeok Choi, and Jee-Hyong Lee
-
[33]
DCG-SQL: Enhancing In-Context Learning for Text-to-SQL with Deep Contextual Schema Link Graph.arXiv preprint arXiv:2505.19956(2025)
arXiv 2025
-
[34]
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, et al. 2024. Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows. arXiv preprint arXiv:2411.07763(2024)
arXiv 2024
-
[35]
Haoyang Li, Shang Wu, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, et al. 2025. Omnisql: Synthesizing high-quality text-to-sql data at scale.arXiv preprint arXiv:2503.02240 (2025)
arXiv 2025
-
[36]
Haoyang Li, Jing Zhang, Cuiping Li, and Hong Chen. 2023. Resdsql: Decoupling schema linking and skeleton parsing for text-to-sql. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 13067–13075
2023
-
[37]
Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, and Hong Chen. 2024. Codes: Towards build- ing open-source language models for text-to-sql.Proceedings of the ACM on Management of Data2, 3 (2024), 1–28
2024
-
[38]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al . 2023. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems36 (2023), 42330–42357
2023
-
[39]
Peng Li, Yeye He, Cong Yan, Yue Wang, and Surajit Chaudhuri. 2023. Auto-Tables: Synthesizing Multi-Step Transformations to Relationalize Tables without Using Examples.Proc. VLDB Endow.16, 11 (2023), 3391–3403. doi:10.14778/3611479. 3611534
-
[40]
Peng Li, Yeye He, Dror Yashar, Weiwei Cui, Song Ge, Haidong Zhang, Danielle Rifinski Fainman, Dongmei Zhang, and Surajit Chaudhuri. 2024. Table-gpt: Table fine-tuned gpt for diverse table tasks.Proceedings of the ACM on Management of Data2, 3 (2024), 1–28
2024
-
[41]
Yuliang Li, Jinfeng Li, Yoshihiko Suhara, AnHai Doan, and Wang-Chiew Tan
-
[42]
VLDB Endow.14, 1 (2020), 50–60
Deep Entity Matching with Pre-Trained Language Models.Proc. VLDB Endow.14, 1 (2020), 50–60. doi:10.14778/3421424.3421431
-
[43]
Yiming Lin, Yeye He, and Surajit Chaudhuri. 2023. Auto-bi: Automatically build bi-models leveraging local join prediction and global schema graph.arXiv preprint arXiv:2306.12515(2023)
arXiv 2023
-
[44]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach.CoRRabs/1907.11692 (2019). arXiv:1907.11692 http://arxiv.org/abs/1907.11692
Pith/arXiv arXiv 2019
-
[45]
Yurong Liu, Eduardo Peña, Aécio S. R. Santos, Eden Wu, and Juliana Freire. 2025. Magneto: Combining Small and Large Language Models for Schema Matching. Proc. VLDB Endow.18, 8 (2025), 2681–2694. doi:10.14778/3742728.3742757
-
[46]
Arash Dargahi Nobari and Davood Rafiei. 2022. Efficiently Transforming Tables for Joinability. In38th IEEE International Conference on Data Engineering, ICDE 2022, Kuala Lumpur, Malaysia, May 9-12, 2022. IEEE, 1649–1661. doi:10.1109/ ICDE53745.2022.00169
arXiv 2022
-
[47]
Arash Dargahi Nobari and Davood Rafiei. 2025. TabulaX: Leveraging Large Language Models for Multi-Class Table Transformations.Proc. VLDB Endow.18, 11 (2025), 3826–3839. https://www.vldb.org/pvldb/vol18/p3826-nobari.pdf
2025
-
[48]
OpenAI. n.d.. OpenAI API Pricing. https://openai.com/api/pricing. [n.d.] Website, accessed Nov. 1, 2025
2025
-
[49]
2021.The Four Generations of Entity Resolution
George Papadakis, Ekaterini Ioannou, Emanouil Thanos, and Themis Palpanas. 2021.The Four Generations of Entity Resolution. Morgan & Claypool Publishers. doi:10.2200/S01067ED1V01Y202012DTM064
-
[50]
Peeters, and Stijn Vansummeren
Marcel Parciak, Brecht Vandevoort, Frank Neven, Liesbet M. Peeters, and Stijn Vansummeren. 2025. LLM-Matcher: A Name-Based Schema Matching Tool using Large Language Models. InCompanion of the 2025 International Conference on Management of Data, SIGMOD/PODS 2025, Berlin, Germany, June 22-27, 2025, Volker Markl, Joseph M. Hellerstein, and Azza Abouzied (Eds...
-
[51]
Mohammadreza Pourreza and Davood Rafiei. 2023. Din-sql: Decomposed in- context learning of text-to-sql with self-correction.Advances in Neural Informa- tion Processing Systems36 (2023), 36339–36348
2023
-
[52]
Mattia Di Profio, Mingjun Zhong, Yaji Sripada, and Marcel Jaspars. 2025. FlowETL: An Autonomous Example-Driven Pipeline for Data Engineering.CoRR abs/2507.23118 (2025). arXiv:2507.23118 doi:10.48550/ARXIV.2507.23118
-
[53]
Torsten Scholak, Nathan Schucher, and Dzmitry Bahdanau. 2021. PICARD: Parsing incrementally for constrained auto-regressive decoding from language models.arXiv preprint arXiv:2109.05093(2021)
arXiv 2021
-
[54]
Nima Shahbazi, Jin Wang, Zhengjie Miao, and Nikita Bhutani. 2024. Fairness- Aware Data Preparation for Entity Matching. In40th IEEE International Conference on Data Engineering, ICDE 2024, Utrecht, The Netherlands, May 13-16, 2024. IEEE, 3476–3489. doi:10.1109/ICDE60146.2024.00268
-
[55]
Roee Shraga, Avigdor Gal, and Haggai Roitman. 2020. ADnEV: Cross-Domain Schema Matching using Deep Similarity Matrix Adjustment and Evaluation. Proc. VLDB Endow.13, 9 (2020), 1401–1415. doi:10.14778/3397230.3397237
-
[56]
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2020. Mpnet: Masked and permuted pre-training for language understanding.Advances in neural information processing systems33 (2020), 16857–16867
2020
-
[57]
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, and Amin Saberi. 2024. Chess: Contextual harnessing for efficient sql synthesis. arXiv preprint arXiv:2405.16755(2024)
Pith/arXiv arXiv 2024
-
[58]
The pandas development team. n.d.. Pivot in Python Pandas. https://pandas. pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.pivot.html. Ac- cessed: 2026-02-28
2026
-
[59]
The pandas development team. n.d.. Python Series Str.split. https://pandas. pydata.org/docs/reference/api/pandas.Series.str.split.html. Accessed: 2026-02-28
2026
-
[60]
Vadim G Vizing. 1965. The chromatic class of a multigraph.Cybernetics1, 3 (1965), 32–41
1965
-
[61]
Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Linzheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, and Zhoujun Li. 2025. MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL. InProceedings of the 31st International Conference on Computational Linguistics, COLING 2025, Abu Dhabi, UAE, January 19-24, 2025, Owen Rambow, Leo Wan...
2025
-
[62]
Jin Wang and Yuliang Li. 2022. Minun: evaluating counterfactual explanations for entity matching. InDEEM ’22: Proceedings of the Sixth Workshop on Data Management for End-To-End Machine Learning Philadelphia, PA, USA, 12 June 2022, Matthias Boehm, Paroma Varma, and Doris Xin (Eds.). ACM, 7:1–7:11. doi:10.1145/3533028.3533304
-
[63]
Jin Wang, Yuliang Li, and Wataru Hirota. 2021. Machamp: A Generalized Entity Matching Benchmark. InCIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, Queensland, Australia, November 1 - 5, 2021, Gianluca Demartini, Guido Zuccon, J. Shane Culpepper, Zi Huang, and Hanghang Tong (Eds.). ACM, 4633–4642. doi...
-
[64]
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. 2023. Plan-and-Solve Prompting: Improving Zero-Shot Chain- of-Thought Reasoning by Large Language Models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, An...
-
[65]
Zilong Wang, Hao Zhang, Chun-Liang Li, Julian Martin Eisenschlos, Vincent Perot, Zifeng Wang, Lesly Miculicich, Yasuhisa Fujii, Jingbo Shang, Chen-Yu Lee, and Tomas Pfister. 2024. Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, M...
2024
-
[66]
Cong Yan and Yeye He. 2020. Auto-Suggest: Learning-to-Recommend Data Preparation Steps Using Data Science Notebooks. InProceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020, David Maier, Rachel Pottinger, AnHai Doan, Wang-Chiew Tan, Abdussalam Alawini, and Hu...
-
[67]
Junwen Yang, Yeye He, and Surajit Chaudhuri. 2021. Auto-Pipeline: Synthesize Data Pipelines By-Target Using Reinforcement Learning and Search.Proc. VLDB Endow.14, 11 (2021), 2563–2575. doi:10.14778/3476249.3476303
-
[68]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Act- ing in Language Models. InThe Eleventh International Conference on Learn- ing Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview.net/forum?id=WE_vluYUL-X
2023
-
[69]
Hanchong Zhang, Ruisheng Cao, Lu Chen, Hongshen Xu, and Kai Yu. 2023. ACT-SQL: In-context learning for text-to-SQL with automatically-generated chain-of-thought.arXiv preprint arXiv:2310.17342(2023)
arXiv 2023
-
[70]
Yong Zhang, Jiacheng Wu, Jin Wang, and Chunxiao Xing. 2020. A Transformation-Based Framework for KNN Set Similarity Search.IEEE Trans. Knowl. Data Eng.32, 3 (2020), 409–423. doi:10.1109/TKDE.2018.2886189
-
[71]
Erkang Zhu, Dong Deng, Fatemeh Nargesian, and Renée J Miller. 2019. Josie: Overlap set similarity search for finding joinable tables in data lakes. InProceed- ings of the 2019 International Conference on Management of Data. 847–864
2019
-
[72]
Erkang Zhu, Yeye He, and Surajit Chaudhuri. 2017. Auto-join: Joining tables by leveraging transformations.Proceedings of the VLDB Endowment10, 10 (2017), 1034–1045
2017
-
[73]
Erkang Zhu, Fatemeh Nargesian, Ken Q Pu, and Renée J Miller. 2016. LSH ensemble: Internet-scale domain search.arXiv preprint arXiv:1603.07410(2016). 18 A Training Data Collection For𝑀 𝑆 In the table identification layer, the deep learning model 𝑀𝑆 (i.e., RoBERTa) performs coarse-grained filtering to retrieve query-related tables. The training data consist...
Pith/arXiv arXiv 2016
-
[74]
valid join
representative statistics from that column, following the design in [24], and 2) features learned by applying a GNN to a graph of semantically similar columns, so that information can be shared across similar columns. In more detail, OmniMatch defines five pairwise column similarities and uses them to construct a global graph where nodes are columns and e...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.