Parallel Integer Sort: Theory and Practice
Pith reviewed 2026-05-24 04:42 UTC · model grok-4.3
The pith
DovetailSort merges integer and comparison sorting ideas to detect and exploit duplicate keys efficiently in parallel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DovetailSort is a parallel integer sorting algorithm that is asymptotically efficient while delivering strong practical speed by combining ideas from integer sorting and comparison sorting; the blend enables reliable detection and exploitation of duplicate keys, a step that prior parallel integer sorters handled poorly.
What carries the argument
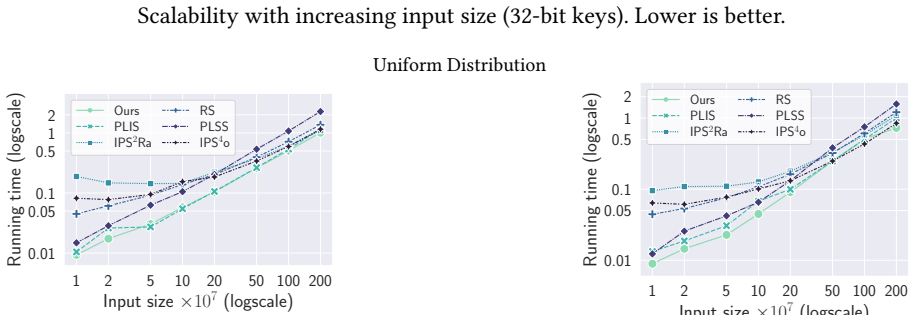
DovetailSort, a hybrid that interleaves integer-sorting radix steps with comparison-based merging to locate and use duplicate keys.
If this is right
- Existing practical integer sorters now rest on stronger asymptotic guarantees.
- DovetailSort can replace current integer sorters in libraries without loss of speed.
- The hybrid detection method scales to real-world inputs that contain many repeated keys.
- Parallel sorting code can safely exploit duplicates without custom preprocessing passes.
Where Pith is reading between the lines
- The same hybrid detection tactic may apply to other parallel primitives that suffer from duplicate-heavy inputs.
- Database engines and map-reduce frameworks could adopt the approach to accelerate grouping and aggregation steps.
- Future work could test whether the same blending pattern yields gains in external-memory or distributed sorting.
Load-bearing premise
Blending integer and comparison ideas can locate duplicate keys in parallel without adding prohibitive synchronization or cache costs.
What would settle it
A parallel run on a data set dominated by long duplicate runs where DovetailSort shows no speedup over a pure comparison-based parallel sort.
Figures



















read the original abstract
Integer sorting is a fundamental problem in computer science. This paper studies parallel integer sort both in theory and in practice. In theory, we show tighter bounds for a class of existing practical integer sort algorithms, which provides a solid theoretical foundation for their widespread usage in practice and strong performance. In practice, we design a new integer sorting algorithm, \textsf{DovetailSort}, that is theoretically-efficient and has good practical performance. In particular, \textsf{DovetailSort} overcomes a common challenge in existing parallel integer sorting algorithms, which is the difficulty of detecting and taking advantage of duplicate keys. The key insight in \textsf{DovetailSort} is to combine algorithmic ideas from both integer- and comparison-sorting algorithms. In our experiments, \textsf{DovetailSort} achieves competitive or better performance than existing state-of-the-art parallel integer and comparison sorting algorithms on various synthetic and real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish tighter theoretical bounds for a class of existing practical parallel integer sort algorithms and introduces DovetailSort, a new parallel integer sorting algorithm that is theoretically efficient while practically exploiting duplicate keys via a hybrid of integer- and comparison-sorting ideas; experiments reportedly show competitive or better performance than state-of-the-art algorithms on synthetic and real-world datasets.
Significance. If the tighter bounds and the efficiency/performance claims hold, the work would strengthen the theoretical grounding for widely used practical integer sorters and provide a concrete hybrid construction for handling duplicates in parallel settings, which is a recurring practical bottleneck. The explicit combination of theory and practice is a positive feature.
major comments (2)
- [Abstract] Abstract: the central claim that DovetailSort is 'theoretically-efficient' is load-bearing, yet the abstract supplies no proof sketch, recurrence, or reference to the analysis section that would establish the bound; without this the efficiency assertion cannot be evaluated.
- [Abstract] Abstract: the claim of 'tighter bounds' for existing algorithms is presented as a key theoretical contribution, but the abstract does not state the prior bounds, the new bounds, or the class of algorithms to which they apply, preventing assessment of whether the improvement is substantive.
minor comments (1)
- The abstract would be clearer if it briefly indicated the nature of the duplicate-key exploitation (e.g., a high-level description of the hybrid mechanism) rather than only naming the insight.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. The comments correctly identify that the abstract is too terse regarding the theoretical claims. We will revise the abstract in the next version to address both points while preserving its brevity. Responses to the major comments follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that DovetailSort is 'theoretically-efficient' is load-bearing, yet the abstract supplies no proof sketch, recurrence, or reference to the analysis section that would establish the bound; without this the efficiency assertion cannot be evaluated.
Authors: We agree the abstract should point readers to the supporting analysis. The full paper establishes the bound for DovetailSort via a recurrence in Section 4 (combining integer and comparison sorting phases to achieve the same asymptotic bound as the best practical integer sorters while handling duplicates). In revision we will append a parenthetical reference to Section 4 after the phrase 'theoretically-efficient'. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'tighter bounds' for existing algorithms is presented as a key theoretical contribution, but the abstract does not state the prior bounds, the new bounds, or the class of algorithms to which they apply, preventing assessment of whether the improvement is substantive.
Authors: The comment is fair; the abstract currently states only that tighter bounds are shown without quantifying them. The manuscript proves improved high-probability bounds (reducing the leading constant or the log-log factor) for the class of practical parallel radix-sort variants that use sampling-based partitioning. We will revise the abstract to name the class and briefly contrast the old and new bounds. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents tighter theoretical bounds on existing integer sort algorithms and introduces DovetailSort as a new hybrid construction that combines ideas from integer and comparison sorting to handle duplicates. No equations, fitted parameters, or predictions are shown to reduce to inputs by construction. The central claims rest on an independent algorithmic design and analysis rather than self-referential definitions, fitted inputs renamed as predictions, or load-bearing self-citations. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard parallel computation model (e.g., PRAM or work-depth) is assumed for deriving theoretical bounds.
Reference graph
Works this paper leans on
-
[1]
OpenStreetMap © OpenStreetMap contributors
2010. OpenStreetMap © OpenStreetMap contributors. https://www. openstreetmap.org/
work page 2010
-
[2]
Sarita V Adve and Mark D Hill. 1990. Weak ordering—a new definition. In ACM International Symposium on Computer Architecture (ISCA) , Vol. 18. 2–14
work page 1990
-
[3]
Susanne Albers and Torben Hagerup. 1997. Improved parallel integer sorting without concurrent writing. Information and Computation 136, 1 (1997), 25–51
work page 1997
-
[4]
Arne Andersson, Torben Hagerup, Stefan Nilsson, and Rajeev Raman
-
[5]
Computer and System Sciences 57, 1 (1998), 74–93
Sorting in Linear Time? J. Computer and System Sciences 57, 1 (1998), 74–93
work page 1998
-
[6]
N. S. Arora, R. D. Blumofe, and C. G. Plaxton. 2001. Thread Scheduling for Multiprogrammed Multiprocessors. Theory of Computing Systems 12 (TOCS) 34, 2 (01 Apr 2001)
work page 2001
-
[7]
Michael Axtmann, Sascha Witt, Daniel Ferizovic, and Peter Sanders
-
[8]
ACM Transactions on Parallel Computing (TOPC) 9, 1 (2022), 1–62
Engineering in-place (shared-memory) sorting algorithms. ACM Transactions on Parallel Computing (TOPC) 9, 1 (2022), 1–62
work page 2022
-
[9]
Lars Backstrom, Dan Huttenlocher, Jon Kleinberg, and Xiangyang Lan. 2006. Group formation in large social networks: membership, growth, and evolution. In ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD) . 44–54
work page 2006
-
[10]
Pramod Chandra P Bhatt, Krzysztof Diks, Torben Hagerup, VC Prasad, Tomasz Radzik, and Sanjeev Saxena. 1991. Improved deterministic parallel integer sorting. Information and Computation 94, 1 (1991), 29–47
work page 1991
-
[11]
Arghya Bhattacharya, Abiyaz Chowdhury, Helen Xu, Rathish Das, Rezaul A Chowdhury, Rob Johnson, Rishab Nithyanand, and Michael A Bender. 2022. When Are Cache-Oblivious Algorithms Cache Adap- tive? A Case Study of Matrix Multiplication and Sorting. In European Symposium on Algorithms (ESA)
work page 2022
-
[12]
Blelloch, Daniel Anderson, and Laxman Dhulipala
Guy E. Blelloch, Daniel Anderson, and Laxman Dhulipala. 2020. Par- layLib — a toolkit for parallel algorithms on shared-memory multicore machines. In ACM Symposium on Parallelism in Algorithms and Archi- tectures (SPAA). 507–509
work page 2020
-
[13]
Guy E Blelloch and Magdalen Dobson. 2022. Parallel Nearest Neighbors in Low Dimensions with Batch Updates. In Algorithm Engineering and Experiments (ALENEX). SIAM, 195–208
work page 2022
-
[14]
Blelloch, Daniel Ferizovic, and Yihan Sun
Guy E. Blelloch, Daniel Ferizovic, and Yihan Sun. 2016. Just Join for Parallel Ordered Sets. In ACM Symposium on Parallelism in Algorithms and Architectures (SPAA)
work page 2016
-
[15]
Guy E. Blelloch, Jeremy T. Fineman, Phillip B. Gibbons, and Julian Shun. 2012. Internally deterministic parallel algorithms can be fast. In ACM Symposium on Principles and Practice of Parallel Programming (PPOPP). 181–192
work page 2012
-
[16]
Guy E. Blelloch, Jeremy T. Fineman, Yan Gu, and Yihan Sun. 2020. Optimal parallel algorithms in the binary-forking model. In ACM Symposium on Parallelism in Algorithms and Architectures (SPAA) . 89– 102
work page 2020
- [17]
-
[18]
In ACM Symposium on Parallelism in Algorithms and Architectures (SPAA)
Low depth cache-oblivious algorithms. In ACM Symposium on Parallelism in Algorithms and Architectures (SPAA)
-
[19]
Blelloch, Yan Gu, Julian Shun, and Yihan Sun
Guy E. Blelloch, Yan Gu, Julian Shun, and Yihan Sun. 2020. Parallelism in Randomized Incremental Algorithms. J. ACM 67, 5 (2020), 1–27
work page 2020
-
[20]
Guy E. Blelloch, Charles E. Leiserson, Bruce M. Maggs, C. Greg Plaxton, Stephen J. Smith, and Marco Zagha. 1991. A Comparison of Sorting Algorithms for the Connection Machine CM-2. In ACM Symposium on Parallelism in Algorithms and Architectures (SPAA)
work page 1991
-
[21]
Robert D. Blumofe and Charles E. Leiserson. 1998. Space-Efficient Scheduling of Multithreaded Computations. SIAM J. on Computing 27, 1 (1998)
work page 1998
-
[22]
Minsik Cho, Daniel Brand, Rajesh Bordawekar, Ulrich Finkler, Vincent Kulandaisamy, and Ruchir Puri. 2015. PARADIS: an efficient parallel algorithm for in-place radix sort. Proceedings of the VLDB Endowment (PVLDB) 8, 12 (2015), 1518–1529
work page 2015
-
[23]
Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. 2009. Introduction to Algorithms (3rd edition) . MIT Press
work page 2009
-
[24]
Laxman Dhulipala, Guy E. Blelloch, and Julian Shun. 2021. Theoreti- cally efficient parallel graph algorithms can be fast and scalable. ACM Transactions on Parallel Computing (TOPC) 8, 1 (2021), 1–70
work page 2021
-
[25]
Xiaojun Dong, Laxman Dhulipala, Yan Gu, and Yihan Sun. 2023. DovetailSort: A Parallel Integer Sort Algorithm. https://github.com/ ucrparlay/DovetailSort
work page 2023
-
[26]
Xiaojun Dong, Yunshu Wu, Zhongqi Wang, Laxman Dhulipala, Yan Gu, and Yihan Sun. 2023. High-Performance and Flexible Parallel Algorithms for Semisort and Related Problems. In ACM Symposium on Parallelism in Algorithms and Architectures (SPAA)
work page 2023
-
[27]
Junhao Gan and Yufei Tao. 2017. On the hardness and approximation of Euclidean DBSCAN. ACM Transactions on Database Systems (TODS) 42, 3 (2017), 1–45
work page 2017
-
[28]
Kourosh Gharachorloo, Daniel Lenoski, James Laudon, Phillip Gibbons, Anoop Gupta, and John Hennessy. 1990. Memory consistency and event ordering in scalable shared-memory multiprocessors. In ACM International Symposium on Computer Architecture (ISCA) , Vol. 18. ACM New York, NY, USA, 15–26
work page 1990
-
[29]
Michael T Goodrich and Riko Jacob. 2023. Optimal Parallel Sorting with Comparison Errors. In ACM Symposium on Parallelism in Algorithms and Architectures (SPAA). 355–365
work page 2023
-
[30]
David Gries and Harlan Mills. 1981. Swapping sections. Technical Report. Cornell University
work page 1981
-
[31]
Yan Gu, Yong He, and Guy E Blelloch. 2015. Ray specialized contraction on bounding volume hierarchies. In Computer Graphics Forum, Vol. 34. 309–318
work page 2015
-
[32]
Yan Gu, Yong He, Kayvon Fatahalian, and Guy Blelloch. 2013. Efficient BVH construction via approximate agglomerative clustering. In High- Performance Graphics (HPG)
work page 2013
-
[33]
Yan Gu, Zachary Napier, and Yihan Sun. 2022. Analysis of Work- Stealing and Parallel Cache Complexity. In SIAM Symposium on Algo- rithmic Principles of Computer Systems (APOCS) . SIAM, 46–60
work page 2022
-
[34]
Yan Gu, Omar Obeya, and Julian Shun. 2021. Parallel In-Place Al- gorithms: Theory and Practice. In SIAM Symposium on Algorithmic Principles of Computer Systems (APOCS) . 114–128
work page 2021
- [35]
-
[36]
Torben Hagerup. 1991. Constant-time parallel integer sorting. In ACM Symposium on Theory of Computing (STOC) . 299–306
work page 1991
-
[37]
Hiroshi Inoue and Kenjiro Taura. 2015. SIMD-and cache-friendly algorithm for sorting an array of structures. Proceedings of the VLDB Endowment 8, 11 (2015), 1274–1285
work page 2015
-
[38]
Yuede Ji, Hang Liu, and H Howie Huang. 2018. ispan: Parallel iden- tification of strongly connected components with spanning trees. In International Conference for High Performance Computing, Networking, Storage, and Analysis (SC). IEEE, 731–742
work page 2018
-
[39]
Jyrki Katajainen and Jesper Larsson Träff. 1997. A meticulous anal- ysis of mergesort programs. In Italian Conference on Algorithms and Complexity (ICAC). Springer, 217–228
work page 1997
-
[40]
Marek Kokot, Sebastian Deorowicz, and Agnieszka Debudaj-Grabysz
-
[41]
In Beyond Databases, Architectures and Structures (BDAS)
Sorting data on ultra-large scale with RADULS: New incarnation of radix sort. In Beyond Databases, Architectures and Structures (BDAS). Springer, 235–245
-
[42]
Marek Kokot, Sebastian Deorowicz, and Maciej Długosz. 2018. Even faster sorting of (not only) integers. In Man-Machine Interactions 5: 5th International Conference on Man-Machine Interactions, ICMMI 2017 Held at Kraków, Poland, October 3-6, 2017 . Springer, 481–491
work page 2018
-
[43]
Haewoon Kwak, Changhyun Lee, Hosung Park, and Sue Moon. 2010. What is Twitter, a social network or a news media?. InInternational World Wide Web Conference (WWW). 591–600
work page 2010
-
[44]
YongChul Kwon, Dylan Nunley, Jeffrey P Gardner, Magdalena Bal- azinska, Bill Howe, and Sarah Loebman. 2010. Scalable clustering algorithm for N-body simulations in a shared-nothing cluster. In Inter- national Conference on Scientific and Statistical Database Management . Springer, 132–150
work page 2010
-
[45]
Shin-Jae Lee, Minsoo Jeon, Dongseung Kim, and Andrew Sohn. 2002. Partitioned parallel radix sort. J. Parallel Distrib. Comput. 62, 4 (2002), 656–668
work page 2002
-
[46]
Shengren Li, Lance C Simons, Jagaseesh Bhaskar Pakaravoor, Fatemeh Abbasinejad, John D Owens, and Nina Amenta. 2012. 𝑘ANN on the GPU with shifted sorting. In High-Performance Graphics (HPG)
work page 2012
-
[47]
Yossi Matias and Uzi Vishkin. 1991. On parallel hashing and integer sorting. J. Algorithms 12, 4 (1991), 573–606
work page 1991
-
[48]
Robert Meusel, Oliver Lehmberg, Christian Bizer, and Sebastiano Vigna. 2014. Web Data Commons — Hyperlink Graphs. http: 13 //webdatacommons.org/hyperlinkgraph
work page 2014
-
[49]
Omar Obeya, Endrias Kahssay, Edward Fan, and Julian Shun. 2019. Theoretically-Efficient and Practical Parallel In-Place Radix Sorting. In ACM Symposium on Parallelism in Algorithms and Architectures (SPAA). 213–224
work page 2019
-
[50]
Orestis Polychroniou and Kenneth A Ross. 2014. A comprehensive study of main-memory partitioning and its application to large-scale comparison-and radix-sort. In ACM SIGMOD International Conference on Management of Data (SIGMOD) . 755–766
work page 2014
-
[51]
Sanguthevar Rajasekaran and John H. Reif. 1989. Optimal and sublog- arithmic time randomized parallel sorting algorithms. SIAM J. on Computing 18, 3 (1989), 594–607
work page 1989
-
[52]
Hitoshi Sato, Ryo Mizote, Satoshi Matsuoka, and Hirotaka Ogawa. 2016. I/O chunking and latency hiding approach for out-of-core sorting ac- celeration using GPU and flash NVM. In IEEE International Conference on Big Data (Big Data) . 398–403
work page 2016
-
[53]
Hideyuki Shamoto, Koichi Shirahata, Aleksandr Drozd, Hitoshi Sato, and Satoshi Matsuoka. 2016. GPU-accelerated large-scale distributed sorting coping with device memory capacity. IEEE Trans. on Big Data 2, 1 (2016), 57–69
work page 2016
-
[54]
Xipeng Shen and Chen Ding. 2004. Adaptive data partition for sorting using probability distribution. In International Conference on Parallel Processing (ICPP). IEEE, 250–257
work page 2004
-
[55]
Slota, Sivasankaran Rajamanickam, and Kamesh Madduri
George M. Slota, Sivasankaran Rajamanickam, and Kamesh Madduri
-
[56]
InIEEE International Parallel and Distributed Processing Symposium (IPDPS)
BFS and coloring-based parallel algorithms for strongly con- nected components and related problems. InIEEE International Parallel and Distributed Processing Symposium (IPDPS) . IEEE, 550–559
-
[57]
Edgar Solomonik and Laxmikant V Kale. 2010. Highly scalable par- allel sorting. In IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 1–12
work page 2010
-
[58]
Yihan Sun, Guy E Blelloch, Wan Shen Lim, and Andrew Pavlo. 2019. On supporting efficient snapshot isolation for hybrid workloads with multi-versioned indexes. Proceedings of the VLDB Endowment (PVLDB) 13, 2 (2019), 211–225
work page 2019
-
[59]
Jesper Larsson Träff. 2018. Parallel quicksort without pairwise element exchange. arXiv preprint:1804.07494 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[60]
Uzi Vishkin. 2010. Thinking in parallel: Some basic data-parallel algorithms and techniques. (2010)
work page 2010
-
[61]
Letong Wang, Xiaojun Dong, Yan Gu, and Yihan Sun. 2023. Parallel Strong Connectivity Based on Faster Reachability. In ACM SIGMOD International Conference on Management of Data (SIGMOD)
work page 2023
-
[62]
Yiqiu Wang, Yan Gu, and Julian Shun. 2020. Theoretically-Efficient and Practical Parallel DBSCAN. In ACM SIGMOD International Conference on Management of Data (SIGMOD) . 2555–2571
work page 2020
-
[63]
Yiqiu Wang, Shangdi Yu, Laxman Dhulipala, Yan Gu, and Julian Shun
-
[64]
ACM SIGOPS Operating Systems Review 55, 1 (2021), 38–46
GeoGraph: A Framework for Graph Processing on Geometric Data. ACM SIGOPS Operating Systems Review 55, 1 (2021), 38–46
work page 2021
-
[65]
Jan Wassenberg and Peter Sanders. 2011. Engineering a multi-core radix sort. In European Conference on Parallel Processing (Euro-Par) . Springer, 160–169
work page 2011
-
[66]
Qingxuan Yang, John Ellis, Khalegh Mamakani, and Frank Ruskey
-
[67]
In-place permuting and perfect shuffling using involutions. Inform. Process. Lett. 113, 10-11 (2013), 386–391
work page 2013
-
[68]
Keliang Zhang and Baifeng Wu. 2012. A novel parallel approach of radix sort with bucket partition preprocess. InInternational Conference on High Performance Computing (HPCC) . IEEE, 989–994
work page 2012
-
[69]
Yu Zheng, Like Liu, Longhao Wang, and Xing Xie. 2008. Learning transportation mode from raw gps data for geographic applications on the web. In International World Wide Web Conference (WWW) . 247–256. A Determinacy Race A determinacy race is when two logically parallel opera- tions access the same memory location and at least one of them is a write [20]. ...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.