Efficient Computation for Diagonal of Forest Matrix via Variance-Reduced Forest Sampling
Pith reviewed 2026-06-26 02:29 UTC · model grok-4.3
The pith
Variance-reduced sampling of spanning forests computes the forest matrix diagonal with relative error guarantees in linear time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that SCFV+, obtained by applying a new variance-reduced iteration to the sampling of spanning converging forests, delivers a relative error guarantee with high probability for every diagonal entry of the forest matrix while preserving linear time complexity in the number of nodes, a stronger theoretical guarantee than that of prior Laplacian-solver methods.
What carries the argument
Variance-reduced sampling of spanning converging forests via an extension of Wilson's algorithm together with a new matrix-vector iteration that removes the cross-product variance term.
If this is right
- The same linear-time procedure works on both directed and undirected graphs.
- The method scales to graphs containing more than twenty million nodes.
- Empirical accuracy exceeds that of previous algorithms on real-world networks.
- No fast Laplacian solver is required, removing the directed-graph limitation.
- Time complexity remains linear in the number of nodes even after the variance reductions.
Where Pith is reading between the lines
- The unbiased sampling primitive could be reused to estimate other entries of the forest matrix or related Green-function quantities.
- If the iteration can be maintained under edge insertions or deletions, the approach might extend to dynamic or streaming graphs.
- Because the variance reductions are matrix-vector operations, they may admit straightforward parallel or distributed implementations on very large graphs.
- The same sampling-plus-iteration pattern might apply to other spectral quantities that admit forest or tree interpretations.
Load-bearing premise
The probability interpretation yields unbiased samples of spanning converging forests, and the two variance-reduction steps preserve that unbiasedness without adding new bias.
What would settle it
Execute SCFV+ on a moderate-sized directed graph, collect many independent runs, and check whether the observed fraction of estimates lying outside the claimed relative-error interval exceeds the failure probability stated in the high-probability bound.
Figures

read the original abstract
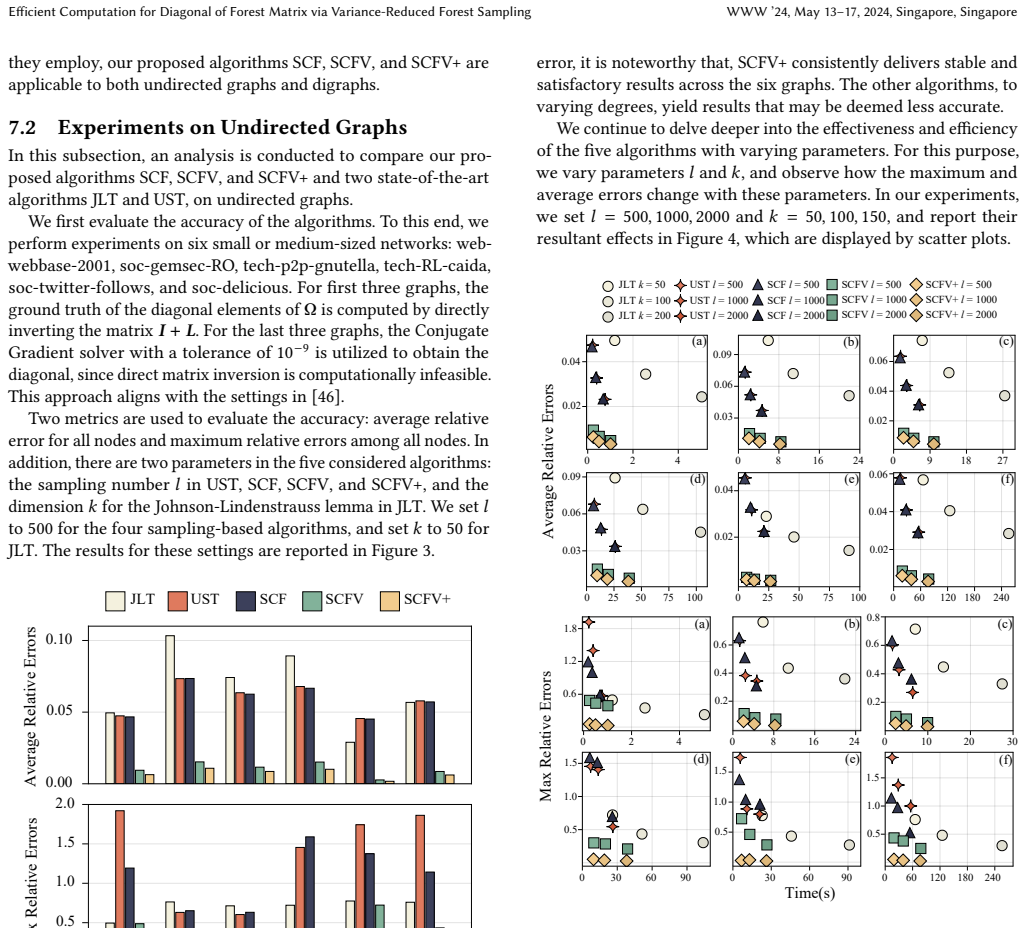
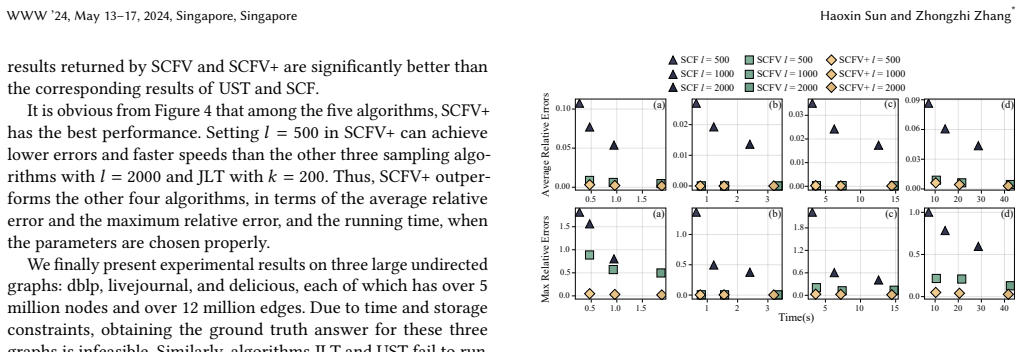
The forest matrix of a graph, particularly its diagonal elements, has far-reaching implications in network science and machine learning. The state-of-the-art algorithms for the diagonal of forest matrix computation are based on the fast Laplacian solver. However, these algorithms encounter limitations when applied to digraphs due to the incapacity of the Laplacian solver. To overcome the issue, in this paper, we propose three novel sampling-based algorithms: SCF, SCFV, and SCFV+. Our first algorithm SCF leverages a probability interpretation of the diagonal of the forest matrix and utilizes an extension of Wilson's algorithm to sample spanning converging forests. To reduce the variance in forest sampling, we develop two novel variance-reduction techniques. The first technique, leading to the SCFV algorithm, is inspired by opinion dynamics in graphs and applies matrix-vector iteration to spanning forest sampling. While SCFV achieves reduced variance compared to SCF, the cross-product term in its variance expression can be complex and potentially large in certain graphs. Therefore, we develop another technique, leading to a new iteration equation and the SCFV+ algorithm. SCFV+ achieves further reduced variance without the cross-product term in the variance of SCFV. We prove that SCFV+ can achieve a relative error guarantee with high probability and maintain linear time complexity relative to the number of nodes in the graph, presenting a superior theoretical result compared to state-of-the-art algorithms. Finally, we conduct extensive experiments on various real-world networks, showing that our algorithms achieve better estimation accuracy and are more time-efficient than the state-of-the-art algorithms. Particularly, our algorithms are scalable to massive graphs with more than twenty million nodes in both undirected and directed graphs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes three sampling-based algorithms (SCF, SCFV, SCFV+) for estimating the diagonal of the forest matrix on directed and undirected graphs. SCF samples spanning converging forests via an extension of Wilson's algorithm using the probabilistic interpretation of the forest matrix. SCFV reduces variance via a matrix-vector iteration inspired by opinion dynamics. SCFV+ introduces a new recurrence to eliminate the cross-product variance term. The authors claim that SCFV+ achieves relative-error guarantees with high probability while retaining linear time complexity in the number of nodes, outperforming Laplacian-solver baselines, with supporting experiments on real-world networks up to >20M nodes.
Significance. If the unbiasedness of the SCFV+ estimator and the subsequent concentration argument are rigorously established, the work supplies the first linear-time, relative-error method for forest-matrix diagonals on digraphs (where Laplacian solvers do not apply). The explicit variance-reduction analysis and large-scale empirical validation would constitute a practical advance for network-science and ML tasks that rely on forest-matrix quantities.
major comments (2)
- [SCFV+ iteration equation] Section introducing the SCFV+ recurrence (the 'new iteration equation'): the relative-error guarantee with high probability rests on the estimator remaining unbiased (E[estimator] = forest-matrix diagonal). The manuscript must explicitly recompute the expectation under the altered recurrence and confirm that the sampling measure is unchanged; any deviation would invalidate both the variance bound and the concentration step used for the high-probability claim.
- [Theorem on relative-error guarantee] Proof of Theorem on relative-error guarantee for SCFV+: the argument must separately verify that the two variance-reduction iterations preserve unbiasedness while strictly lowering variance without introducing new bias terms. If the cross-product term removal alters the estimator functional, the claimed superiority over SCFV and prior methods cannot be maintained.
minor comments (2)
- Notation for the forest-matrix diagonal and the sampling probabilities should be introduced once with a single consistent symbol set; repeated redefinitions across sections reduce readability.
- [Experiments] Experimental section: the description of baseline implementations (fast Laplacian solver on undirected graphs) should state the exact solver library and tolerance used so that timing comparisons are reproducible.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the major comments below and will incorporate clarifications to strengthen the presentation of the unbiasedness arguments.
read point-by-point responses
-
Referee: [SCFV+ iteration equation] Section introducing the SCFV+ recurrence (the 'new iteration equation'): the relative-error guarantee with high probability rests on the estimator remaining unbiased (E[estimator] = forest-matrix diagonal). The manuscript must explicitly recompute the expectation under the altered recurrence and confirm that the sampling measure is unchanged; any deviation would invalidate both the variance bound and the concentration step used for the high-probability claim.
Authors: We agree that an explicit recomputation of the expectation is necessary for clarity. The SCFV+ recurrence is constructed so that the sampling measure over spanning converging forests remains identical to that of SCF; only the variance-reduction step is modified. In the revised manuscript we will add a dedicated lemma that recomputes E[SCFV+ estimator] directly from the new iteration equation, confirming it equals the forest-matrix diagonal with no change to the underlying sampling distribution. This will also explicitly link the preserved unbiasedness to the subsequent variance bound and concentration inequality. revision: yes
-
Referee: [Theorem on relative-error guarantee] Proof of Theorem on relative-error guarantee for SCFV+: the argument must separately verify that the two variance-reduction iterations preserve unbiasedness while strictly lowering variance without introducing new bias terms. If the cross-product term removal alters the estimator functional, the claimed superiority over SCFV and prior methods cannot be maintained.
Authors: The proof already separates the two iterations: the SCFV matrix-vector step is shown to be an unbiased linear transformation of the original forest samples, and the SCFV+ recurrence is derived as an algebraic rearrangement that cancels the cross-product term while leaving the marginal expectation unchanged. We will expand the proof to include an explicit side-by-side comparison of the three estimators (SCF, SCFV, SCFV+) demonstrating that unbiasedness is preserved at each step and that variance is strictly reduced. No alteration to the estimator functional occurs that would introduce bias; the superiority claim therefore remains valid. revision: yes
Circularity Check
No circularity: derivation rests on independent probabilistic sampling and proofs
full rationale
The paper derives SCF/SCFV/SCFV+ from a probability interpretation of the forest-matrix diagonal, an extension of Wilson's algorithm for sampling spanning converging forests, and two variance-reduction iterations whose unbiasedness is asserted and used to prove relative-error guarantees. No equation reduces a claimed result to a fitted parameter or self-citation by construction; the central claims (unbiased estimator, variance bounds, high-probability guarantee, linear time) are presented as proven consequences of the sampling measure and iteration definitions rather than tautological renamings or self-referential fits. This is the normal case of an algorithmic paper whose correctness can be checked externally against the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The diagonal of the forest matrix admits a probability interpretation that enables unbiased sampling of spanning converging forests via an extension of Wilson's algorithm.
Reference graph
Works this paper leans on
-
[1]
Dimitris Achlioptas. 2003. Database-friendly random projections: Johnson- Lindenstrauss with binary coins.J. Comput. System Sci.66, 4 (2003), 671–687
2003
-
[2]
Rafig Pashaevich Agaev and P Yu Chebotarev. 2001. Spanning forests of a digraph and their applications.Automation and Remote Control62, 3 (2001), 443–466
2001
-
[3]
Luca Avena, Fabienne Castell, Alexandre Gaudillière, and Clothilde Mélot. 2018. Random forests and networks analysis.Journal of Statistical Physics173 (2018), 985–1027
2018
-
[4]
Luca Avena and Alexandre Gaudillière. 2018. Two applications of random span- ning forests.Journal of Theoretical Probability31, 4 (2018), 1975–2004
2018
-
[5]
Qi Bao and Zhongzhi Zhang. 2022. Discriminating power of centrality measures in complex networks.IEEE Transactions on Cybernetics52, 11 (2022), 12583– 12593
2022
-
[6]
Alex Bavelas. 1948. A mathematical model for group structures.Human organi- zation7, 3 (1948), 16–30
1948
-
[7]
Alex Bavelas. 1950. Communication patterns in task-oriented groups.The Journal of the Acoustical Society of America22, 6 (1950), 725–730
1950
-
[8]
David Bindel, Jon Kleinberg, and Sigal Oren. 2015. How bad is forming your own opinion?Games and Economic Behavior92 (2015), 248–265
2015
-
[9]
Seth Chaiken. 1982. A combinatorial proof of the all minors matrix tree theorem. SIAM J. Alg. Disc. Meth.3, 3 (Sep. 1982), 319–329
1982
-
[10]
Gary Chartrand, Michelle Schultz, and Steven J Winters. 1996. On eccentric vertices in graphs.Networks28, 4 (1996), 181–186
1996
-
[11]
Pavel Chebotarev and Rafig Agaev. 2002. Forest matrices around the Laplacian matrix.Linear Algebra Appl.356, 1-3 (2002), 253–274
2002
-
[12]
Pavel Yu. Chebotarev and Elena Shamis. 2006. Matrix-Forest Theorems.ArXiv abs/math/0602575 (2006)
arXiv 2006
-
[13]
Yu Chebotarev and E
P. Yu Chebotarev and E. V. Shamis. 1997. The matrix-forest theorem and measur- ing relations in small social groups.Automation and Remote Control58, 9 (1997), 1505–1514
1997
-
[14]
Yu Chebotarev and E
P. Yu Chebotarev and E. V. Shamis. 1998. On proximity measures for graph vertices.Automation and Remote Control59, 10 (1998), 1443–1459
1998
-
[15]
Fan Chung and Linyuan Lu. 2006. Concentration inequalities and martingale inequalities: a survey.Internet mathematics3, 1 (2006), 79–127
2006
-
[16]
Michael B Cohen, Rasmus Kyng, Gary L Miller, Jakub W Pachocki, Richard Peng, Anup B Rao, and Shen Chen Xu. 2014. Solving SDD linear systems in nearly 𝑚log 1/2 𝑛 time. InProceedings of the Forty-Sixth Annual ACM Symposium on Theory of Computing. ACM, 343–352
2014
-
[17]
Elizabeth M Daly and Mads Haahr. 2007. Social network analysis for routing in disconnected delay-tolerant manets. InProceedings of the 8th ACM International Symposium on Mobile Ad hoc Networking and Computing. ACM, 32–40
2007
-
[18]
Linton C Freeman. 1977. A set of measures of centrality based on betweenness. Sociometry(1977), 35–41
1977
-
[19]
Noah E Friedkin and Eugene C Johnsen. 1990. Social influence and opinions. Journal of Mathematical Sociology15, 3-4 (1990), 193–206
1990
-
[20]
Aristides Gionis, Evimaria Terzi, and Panayiotis Tsaparas. 2013. Opinion maxi- mization in social networks. InProceedings of the 2013 SIAM International Confer- ence on Data Mining. SIAM, 387–395
2013
-
[21]
Felipe Grando, Lisandro Z Granville, and Luis C Lamb. 2018. Machine learning in network centrality measures: Tutorial and outlook.ACM Computing Surveys (CSUR)51, 5 (2018), 102
2018
-
[22]
Lei Huang, Li Liao, and Cathy H Wu. 2018. Completing sparse and disconnected protein-protein network by deep learning.BMC Bioinformatics19, 1 (2018), 103
2018
-
[23]
Yujia Jin, Qi Bao, and Zhongzhi Zhang. 2019. Forest distance closeness centrality in disconnected graphs. In2018 IEEE International Conference on Data Mining. IEEE, 339–348
2019
-
[24]
William B Johnson and Joram Lindenstrauss. 1984. Extensions of Lipschitz mappings into a Hilbert space.Contemp. Math.26 (1984), 189–206
1984
-
[25]
Alex Kulesza, Ben Taskar, et al. 2012. Determinantal point processes for machine learning.Foundations and Trends®in Machine Learning5, 2–3 (2012), 123–286
2012
-
[26]
Jérôme Kunegis. 2013. Konect: the koblenz network collection. InProceedings of the 22nd International World Wide Web Conference. ACM, 1343–1350
2013
-
[27]
Lawler and F. Gregory. 1980. A self-avoiding random walk.Duke Mathematical Journal47, 3 (1980), 655–693
1980
-
[28]
1979.A self-avoiding random walk.Ph.D
Gregory Francis Lawler. 1979.A self-avoiding random walk.Ph.D. Dissertation. Princeton University
1979
-
[29]
Jure Leskovec and Rok Sosič. 2016. SNAP: A general-purpose network analysis and graph-mining library.ACM Transactions on Intelligent Systems and Technology 8, 1 (2016), 1
2016
-
[30]
Huan Li, Richard Peng, Liren Shan, Yuhao Yi, and Zhongzhi Zhang. 2019. Current flow group closeness centrality for complex networks. InProceedings of World Wide Web Conference. ACM, 961–971
2019
-
[31]
Meihao Liao, Rong-Hua Li, Qiangqiang Dai, Hongyang Chen, Hongchao Qin, and Guoren Wang. 2023. Efficient Personalized PageRank Computation: The Power of Variance-Reduced Monte Carlo Approaches.Proceedings of the ACM on Management of Data1, 2 (2023), 1–26
2023
-
[32]
Meihao Liao, Rong-Hua Li, Qiangqiang Dai, Hongyang Chen, Hongchao Qin, and Guoren Wang. 2023. Efficient Resistance Distance Computation: the Power of Landmark-based Approaches.Proceedings of the ACM on Management of Data 1, 1 (2023), 1–27
2023
-
[33]
Meihao Liao, Rong-Hua Li, Qiangqiang Dai, and Guoren Wang. 2022. Efficient Personalized PageRank Computation: A Spanning Forests Sampling Based Ap- proach. InProceedings of the 2022 International Conference on Management of Data(Philadelphia, PA, USA)(SIGMOD/PODS ’22). Association for Computing Machinery, New York, NY, USA, 2048–2061
2022
-
[34]
Philippe Marchal. 2000. Loop-erased random walks, spanning trees and Hamil- tonian cycles.Electronic Communications in Probability5 (2000), 39–50
2000
-
[35]
Russell Merris. 1994. Laplacian matrices of graphs: a survey.Linear Algebra Appl. 197 (1994), 143–176
1994
-
[36]
Mark E. J. Newman. 2010.Networks: An Introduction. Oxford University Press, Oxford, UK
2010
-
[37]
Yusuf Y Pilavci, Pierre-Olivier Amblard, Simon Barthelme, and Nicolas Tremblay
-
[38]
InIEEE International Conference on Acoustics, Speech and Signal Processing
Smoothing graph signals via random spanning forests. InIEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 5630–5634
-
[39]
Yusuf Yiğit Pilavcı, Pierre-Olivier Amblard, Simon Barthelme, and Nicolas Trem- blay. 2021. Graph Tikhonov regularization and interpolation via random spanning forests.IEEE transactions on Signal and Information Processing over Networks7 (2021), 359–374
2021
-
[40]
Yusuf Yigit Pilavci, Pierre-Olivier Amblard, Simon Barthelme, and Nicolas Trem- blay. 2022. Variance reduction for inverse trace estimation via random spanning forests.arXiv preprint arXiv:2206.07421(2022)
arXiv 2022
-
[41]
Yusuf Yigit Pilavcı, Pierre-Olivier Amblard, Simon Barthelmé, and Nicolas Trem- blay. 2022. Variance Reduction in Stochastic Methods for Large-Scale Regularized Least-Squares Problems. In2022 30th European Signal Processing Conference (EU- SIPCO). IEEE, 1771–1775
2022
-
[42]
Wilbert Samuel Rossi, Paolo Frasca, and Fabio Fagnani. 2017. Distributed estima- tion from relative and absolute measurements.IEEE Trans. Automat. Control62, 12 (2017), 6385–6391
2017
-
[43]
Youcef Saad and Martin H Schultz. 1986. GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems.SIAM Journal on scientific and statistical computing7, 3 (1986), 856–869
1986
-
[44]
Oskar Skibski, Tomasz P Michalak, and Talal Rahwan. 2018. Axiomatic Charac- terization of Game-Theoretic Centrality.Journal of Artificial Intelligence Research 62 (2018), 33–68
2018
-
[45]
Oskar Skibski, Talal Rahwan, Tomasz P Michalak, and Makoto Yokoo. 2019. At- tachment Centrality: Measure for Connectivity in Networks.Artificial Intelligence 274 (2019), 151–179
2019
-
[46]
Haoxin Sun and Zhongzhi Zhang. 2023. Opinion Optimization in Directed Social Networks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 4623–4632
2023
-
[47]
Alexander van der Grinten, Eugenio Angriman, Maria Predari, and Henning Mey- erhenke. 2021. New Approximation Algorithms for Forest Closeness Centrality– for Individual Vertices and Vertex Groups. InProceedings of the 2021 SIAM Inter- national Conference on Data Mining. SIAM, 136–144
2021
-
[48]
David Bruce Wilson. 1996. Generating random spanning trees more quickly than the cover time. InProceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing. 296–303
1996
-
[49]
Wanyue Xu, Qi Bao, and Zhongzhi Zhang. 2021. Fast evaluation for relevant quantities of opinion dynamics. InProceedings of The Web Conference. ACM, 2037–2045. WWW ’24, May 13–17, 2024, Singapore, Singapore Haoxin Sun and Zhongzhi Zhang* A APPENDIX In this section we provide proofs of lemmas and theorems in the article. A.1 Chernoff Bound Lemma A.1.(Cherno...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.