A Rank-One Popularity Component in Dot-Product Recommender Scores:Population Theory and Prior-Separation Evidence
Pith reviewed 2026-06-26 13:11 UTC · model grok-4.3
The pith
Dot-product softmax decoders embed a rank-one popularity component from the item marginal log p(i).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For any encoder using a dot-product softmax decoder, the population-optimal score decomposes into pointwise mutual information, an item-marginal term log p(i), and a context-dependent offset. After centering, the item marginal produces a context-shared rank-one score component, while time-varying marginals induce a low-rank popularity subspace. This score-level result does not imply universal embedding collapse because its transfer to embeddings depends on factorization geometry.
What carries the argument
The decomposition of the population-optimal dot-product score into PMI(i|c) + log p(i) + offset(c), where the centered log p(i) term supplies the rank-one popularity component.
If this is right
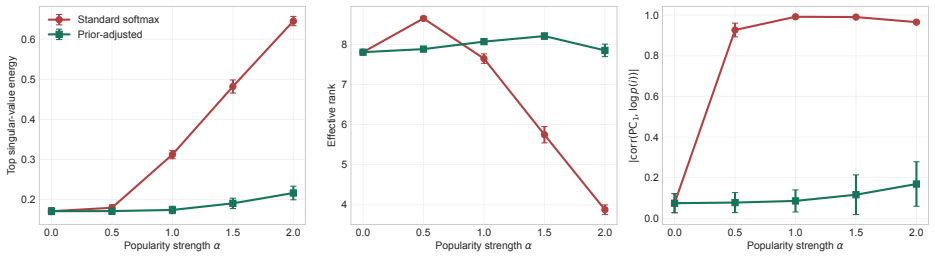
- Explicitly separating log p(i) from the learned dot product reduces measured popularity-aligned score energy by 98.6 percent.
- The rank-one component appears for any dot-product softmax decoder, independent of Transformer architecture.
- Time-varying item marginals create an additional low-rank popularity subspace in the scores.
- Representation anisotropy is explained as a decoder-level effect of long-tailed marginals rather than an encoder property.
Where Pith is reading between the lines
- If deployed inference uses a different decoder than the training softmax, the exact decomposition may not hold at test time.
- The separation technique could be applied at inference to reduce unintended popularity bias in live recommendations.
- The result suggests testing whether similar marginal-induced components appear in non-softmax dot-product models.
Load-bearing premise
The derivation requires that the decoder is exactly dot-product softmax and that training matches the conditional distribution over contexts.
What would settle it
No reduction in popularity-aligned score energy after explicit separation of log p(i) when the decoder is dot-product softmax and marginals are known.
Figures
read the original abstract
Representation anisotropy in recommender systems is often attributed to Transformer architectures. We identify a more general source in the conditional training distribution. For any encoder using a dot-product softmax decoder, the population-optimal score decomposes into pointwise mutual information, an item-marginal term log p(i), and a context-dependent offset. After centering, the item marginal produces a context-shared rank-one score component, while time-varying marginals induce a low-rank popularity subspace. This score-level result does not imply universal embedding collapse because its transfer to embeddings depends on factorization geometry. Experiments on synthetic data and public Alibaba and Tianchi interaction logs support the proposed mechanism. Separating log p(i) from the learned dot product reduces the measured popularity-aligned score energy by 98.6 percent in a matched intervention. Permutation tests confirm that this reduction is specific to the empirical popularity direction. These results explain a class of apparent representation degeneration as a decoder-level consequence of long-tailed item marginals rather than a property unique to Transformer encoders.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for encoders using a dot-product softmax decoder trained on the conditional distribution, the population-optimal scores decompose exactly as PMI(i; c) + log p(i) + f(c). Centering over items isolates the item-marginal term as a context-shared rank-one component in the score matrix; time-varying marginals extend this to a low-rank popularity subspace. The score-level result does not imply embedding collapse. Experiments on synthetic data and Alibaba/Tianchi logs show that an intervention separating log p(i) reduces measured popularity-aligned score energy by 98.6 percent, with permutation tests confirming the reduction is specific to the empirical popularity direction.
Significance. If the result holds, it supplies a decoder-level, architecture-independent account of a frequently observed form of representation anisotropy in recommenders, grounded in the item marginal under standard training. The central decomposition is an algebraic identity with no free parameters. The matched intervention experiment reports a large, permutation-validated effect size that directly tests the proposed mechanism.
major comments (1)
- [§2] §2 (population derivation): the manuscript states the decomposition follows from the definition of conditional probability under dot-product softmax, but does not display the full centering argument that isolates the rank-one log p(i) term. Because this step is load-bearing for the central claim, the derivation should be written out explicitly in the main text or a numbered appendix.
minor comments (2)
- [§5] §5 (experiments): the exact functional form of the modified score used in the 98.6 percent intervention should be stated as an equation so that the ablation is reproducible from the text alone.
- [Notation] Notation: the distinction between population p(i) and its empirical estimate is not always typographically clear in the experimental sections; consistent use of hats or subscripts would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the significance evaluation, and the recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [§2] §2 (population derivation): the manuscript states the decomposition follows from the definition of conditional probability under dot-product softmax, but does not display the full centering argument that isolates the rank-one log p(i) term. Because this step is load-bearing for the central claim, the derivation should be written out explicitly in the main text or a numbered appendix.
Authors: We agree that the full centering argument is load-bearing and should be shown explicitly. In the revised manuscript we will expand §2 to include the complete derivation: starting from the population-optimal dot-product softmax scores, applying the definition of conditional probability to obtain the PMI term, then performing the explicit centering over items to isolate the shared rank-one log p(i) component (with the context-dependent offset made visible). We will place the expanded steps in the main text of §2 rather than an appendix. revision: yes
Circularity Check
Central decomposition is algebraic identity from conditional probability and softmax optimality
specific steps
-
self definitional
[Abstract]
"For any encoder using a dot-product softmax decoder, the population-optimal score decomposes into pointwise mutual information, an item-marginal term log p(i), and a context-dependent offset. After centering, the item marginal produces a context-shared rank-one score component, while time-varying marginals induce a low-rank popularity subspace."
The stated decomposition is exactly the definition of pointwise mutual information applied to the conditional probability that the dot-product softmax decoder is assumed to optimize. Centering then isolates log p(i) by algebraic construction, so the rank-one component equals the input marginal without any additional derivation or external principle.
full rationale
The paper's core population theory states that under a dot-product softmax decoder the optimal scores decompose into PMI + log p(i) + offset, with centering isolating a rank-one log p(i) term. This follows immediately from the definition of PMI (log p(i|c) = PMI(i;c) + log p(i)) and the known fact that softmax logits match log conditionals up to additive context term. The abstract and skeptic analysis both confirm the result is an identity under the stated assumptions rather than a derived prediction. Experiments on separation are downstream and do not rescue the theory section from being tautological. No self-citations or fitted parameters appear in the load-bearing step, so the circularity is partial and limited to the theoretical claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The decoder is a dot-product softmax
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining , year =
Qiu, Ruihong and Huang, Zi and Yin, Hongzhi and Wang, Zijian , title =. Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining , year =
-
[2]
International Conference on Learning Representations , year =
Gao, Jun and He, Di and Tan, Xu and Qin, Tao and Wang, Liwei and Liu, Tie-Yan , title =. International Conference on Learning Representations , year =
-
[3]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages =
Ethayarajh, Kawin , title =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages =. 2019 , doi =
2019
-
[4]
Proceedings of the 37th International Conference on Machine Learning , series =
Wang, Tongzhou and Isola, Phillip , title =. Proceedings of the 37th International Conference on Machine Learning , series =
-
[5]
International Conference on Learning Representations , year =
Menon, Aditya Krishna and Jayasumana, Sadeep and Rawat, Ankit Singh and Jain, Himanshu and Veit, Andreas and Kumar, Sanjiv , title =. International Conference on Learning Representations , year =
-
[6]
Advances in Neural Information Processing Systems , volume =
Ren, Jiawei and Yu, Cunjun and Ma, Xiao and Zhao, Haiyu and Yi, Shuai , title =. Advances in Neural Information Processing Systems , volume =
-
[7]
2018 IEEE International Conference on Data Mining , pages =
Kang, Wang-Cheng and McAuley, Julian , title =. 2018 IEEE International Conference on Data Mining , pages =. 2018 , doi =
2018
-
[8]
Proceedings of the 28th ACM International Conference on Information and Knowledge Management , pages =
Sun, Fei and Liu, Jun and Wu, Jian and Pei, Changhua and Lin, Xiao and Ou, Wenwu and Jiang, Peng , title =. Proceedings of the 28th ACM International Conference on Information and Knowledge Management , pages =. 2019 , doi =
2019
-
[9]
Session-based Recommendations with Recurrent Neural Networks , booktitle =
Hidasi, Bal. Session-based Recommendations with Recurrent Neural Networks , booktitle =
-
[10]
Advances in Neural Information Processing Systems , volume =
Levy, Omer and Goldberg, Yoav , title =. Advances in Neural Information Processing Systems , volume =
-
[11]
Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , year =
Wang, Chenyang and Yu, Yuanqing and Ma, Weizhi and Zhang, Min and Chen, Chong and Liu, Yiqun and Ma, Shaoping , title =. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , year =
-
[12]
Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , year =
Yu, Junliang and Yin, Hongzhi and Xia, Xin and Chen, Tong and Cui, Lizhen and Nguyen, Quoc Viet Hung , title =. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , year =
-
[13]
Adaptive Importance Sampling to Accelerate Training of a Neural Probabilistic Language Model , journal =
Bengio, Yoshua and Sen. Adaptive Importance Sampling to Accelerate Training of a Neural Probabilistic Language Model , journal =. 2008 , doi =
2008
-
[14]
On Using Very Large Target Vocabulary for Neural Machine Translation , booktitle =
Jean, S. On Using Very Large Target Vocabulary for Neural Machine Translation , booktitle =. 2015 , doi =
2015
-
[15]
and Soudry, Daniel and Srebro, Nathan , title =
Gunasekar, Suriya and Lee, Jason D. and Soudry, Daniel and Srebro, Nathan , title =. Advances in Neural Information Processing Systems , volume =
-
[16]
Advances in Neural Information Processing Systems , volume =
Arora, Sanjeev and Cohen, Nadav and Hu, Wei and Luo, Yuping , title =. Advances in Neural Information Processing Systems , volume =
-
[17]
Proceedings of the 13th Asian Conference on Machine Learning , series =
Lin, Fangquan and Jiang, Wei and Zhang, Jihai and Yang, Cheng , title =. Proceedings of the 13th Asian Conference on Machine Learning , series =. 2021 , publisher =
2021
-
[18]
Alibaba Mobile Recommendation Algorithm Competition , year =
-
[19]
Proceedings of the 33rd International Conference on Machine Learning , series =
Schnabel, Tobias and Swaminathan, Adith and Singh, Ashudeep and Chandak, Navin and Joachims, Thorsten , title =. Proceedings of the 33rd International Conference on Machine Learning , series =. 2016 , url =
2016
-
[20]
Proceedings of the 13th ACM International Conference on Web Search and Data Mining , pages =
Saito, Yuta and Yaginuma, Suguru and Nishino, Yuta and Sakata, Hayato and Nakata, Kazuhide , title =. Proceedings of the 13th ACM International Conference on Web Search and Data Mining , pages =. 2020 , doi =
2020
-
[21]
Proceedings of the Web Conference 2021 , pages =
Zheng, Yu and Gao, Chen and Li, Xiang and He, Xiangnan and Jin, Depeng and Li, Yong , title =. Proceedings of the Web Conference 2021 , pages =. 2021 , doi =
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.