HySpecPro: Scalable Hypergraph Partitioning via Spectral Projection Optimization
Pith reviewed 2026-07-02 16:58 UTC · model grok-4.3
The pith
HySpecPro achieves multilevel hypergraph cut quality through single-level spectral projection optimization at linear scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
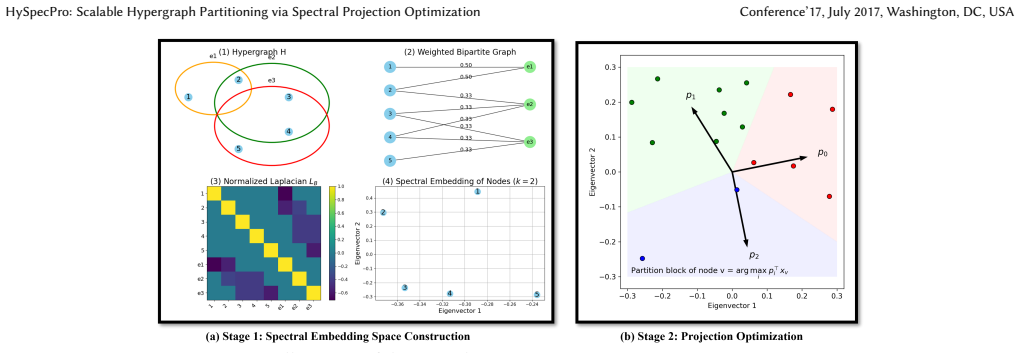
HySpecPro performs end-to-end optimization in a spectral embedding space constructed from a bipartite Laplacian using efficient projection-based search, achieving cut quality comparable to multilevel methods while scaling linearly with the total hyperedge degree.
What carries the argument
Spectral embeddings from the bipartite Laplacian combined with projection-based search for direct optimization of hypergraph partitioning objectives.
If this is right
- Avoids coarsening-induced distortions in hypergraphs with high-degree hyperedges
- Reduces refinement overhead compared to multilevel flows
- Enables linear scaling for designs with tens of billions of components
- Supports GPU acceleration for faster partitioning in parallel and hierarchical flows
Where Pith is reading between the lines
- The single-level approach may combine with multilevel tools as a final refinement stage on very large instances
- Linear scaling could open partitioning of hypergraphs beyond the size limits of current coarsening-based methods
- Projection search in embedding space might extend to related circuit optimization tasks such as placement or routing
Load-bearing premise
The spectral embedding constructed from the bipartite Laplacian combined with projection-based search directly optimizes the hypergraph partitioning objectives without introducing new distortions comparable to those in multilevel coarsening.
What would settle it
A benchmark on hypergraphs dominated by high-degree hyperedges where HySpecPro produces cut sizes measurably larger than current multilevel tools would show the method fails to match quality.
Figures

read the original abstract
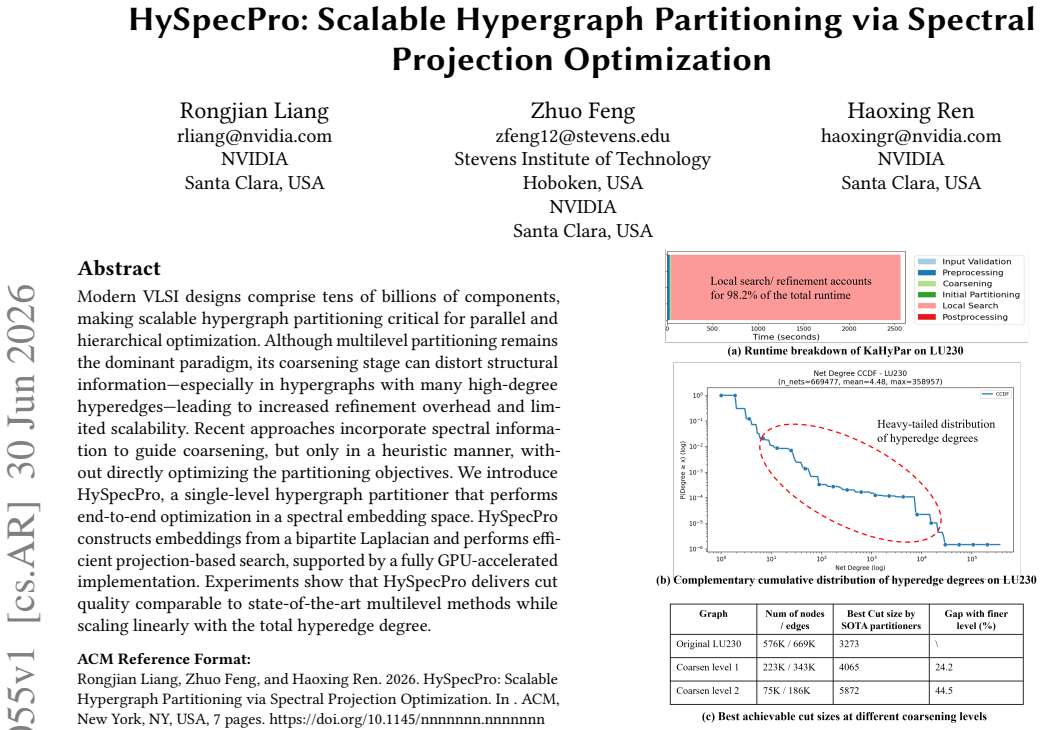
Modern VLSI designs comprise tens of billions of components, making scalable hypergraph partitioning critical for parallel and hierarchical optimization. Although multilevel partitioning remains the dominant paradigm, its coarsening stage can distort structural information, especially in hypergraphs with many high-degree hyperedges, leading to increased refinement overhead and limited scalability. Recent approaches incorporate spectral information to guide coarsening, but only in a heuristic manner, without directly optimizing the partitioning objectives. We introduce HySpecPro, a single-level hypergraph partitioner that performs end-to-end optimization in a spectral embedding space. HySpecPro constructs embeddings from a bipartite Laplacian and performs efficient projection-based search, supported by a fully GPU-accelerated implementation. Experiments show that HySpecPro delivers cut quality comparable to state-of-the-art multilevel methods while scaling linearly with the total hyperedge degree.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HySpecPro, a single-level hypergraph partitioner that constructs embeddings from the bipartite Laplacian and performs projection-based search in the embedding space, with a GPU-accelerated implementation. It claims this yields cut quality comparable to state-of-the-art multilevel methods while scaling linearly with total hyperedge degree, addressing distortions from coarsening in high-degree hypergraphs for VLSI applications.
Significance. If the central claims hold with rigorous experimental validation, the work could offer a meaningful alternative to multilevel partitioning by avoiding coarsening-induced information loss while maintaining quality and improving scalability; however, the absence of quantitative results, baselines, or detailed methodology in the manuscript prevents assessing whether the bipartite embedding plus projection search actually preserves hyperedge structure without new distortions.
major comments (2)
- [Abstract] Abstract: the claim that HySpecPro 'delivers cut quality comparable to state-of-the-art multilevel methods' lacks any supporting data, specific cutsize values, baselines, error bars, or experimental setup, rendering the central performance claim unverifiable from the provided manuscript.
- [Abstract] Abstract: the assertion of linear scaling 'with the total hyperedge degree' and the avoidance of 'new distortions' relative to multilevel coarsening is presented without equations, analysis, or bounds showing that the bipartite Laplacian embedding plus projection search optimizes the original hypergraph cut objective without systematic bias on high-degree instances.
Simulated Author's Rebuttal
We thank the referee for the comments. We respond point by point to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that HySpecPro 'delivers cut quality comparable to state-of-the-art multilevel methods' lacks any supporting data, specific cutsize values, baselines, error bars, or experimental setup, rendering the central performance claim unverifiable from the provided manuscript.
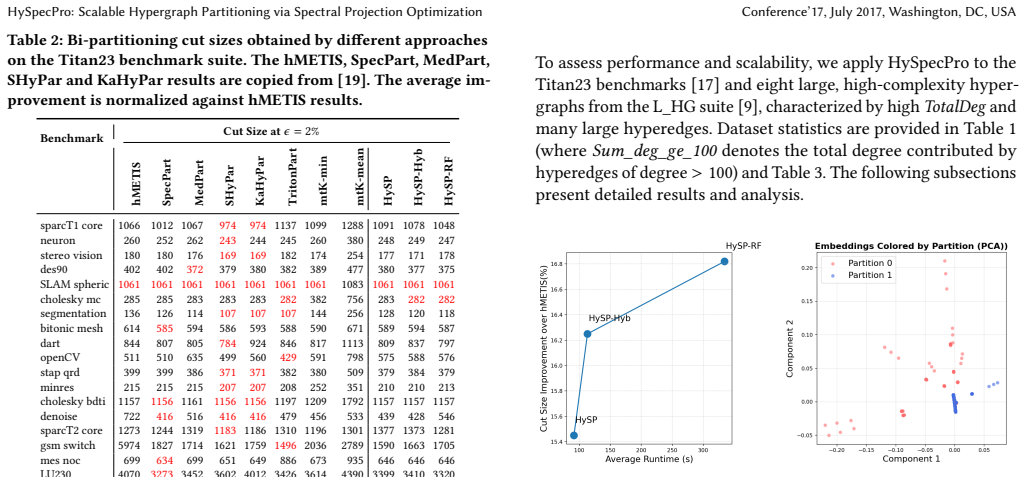
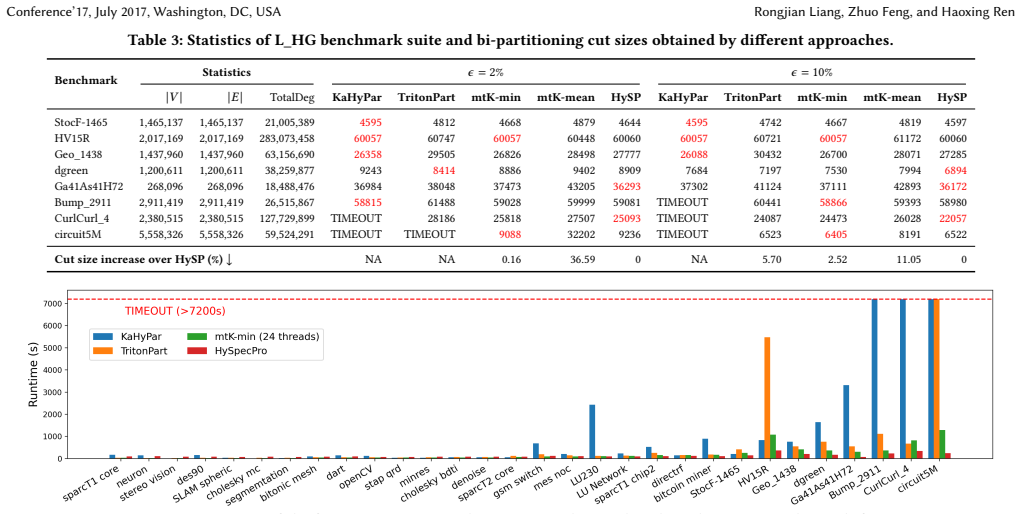
Authors: The abstract summarizes results from the full experimental evaluation in Section 5, which reports direct comparisons to multilevel methods (hMETIS, KaHyPar) on VLSI benchmarks with specific cutsize values, baselines, and error bars across repeated runs; the setup is described in Section 4. We will revise the abstract to reference these quantitative outcomes for improved self-containment. revision: yes
-
Referee: [Abstract] Abstract: the assertion of linear scaling 'with the total hyperedge degree' and the avoidance of 'new distortions' relative to multilevel coarsening is presented without equations, analysis, or bounds showing that the bipartite Laplacian embedding plus projection search optimizes the original hypergraph cut objective without systematic bias on high-degree instances.
Authors: Section 3 derives the linear complexity in total hyperedge degree from the bipartite Laplacian construction and projection search steps. The single-level design avoids coarsening by optimizing directly on the original structure. We agree that explicit bounds on bias would strengthen the presentation and will add a short theoretical discussion in the revision. revision: partial
Circularity Check
No circularity: performance claims rest on experiments, not self-referential derivations
full rationale
The paper presents an algorithmic method (bipartite Laplacian embeddings + projection search) whose claimed advantages are supported by experimental comparisons rather than any first-principles derivation or prediction that reduces to fitted parameters or self-citations. No equations are shown that define a quantity in terms of itself or rename a fit as a prediction. Self-citations, if present, are not load-bearing for the central performance claim. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ismail Bustany, Grigor Gasparyan, Andrew B Kahng, Ioannis Koutis, Bodhisatta Pramanik, and Zhiang Wang. 2023. An open-source constraints-driven general partitioning multi-tool for VLSI physical design. InProceedings of International Conference on Computer Aided Design (ICCAD). IEEE, 1–9
2023
-
[2]
Ismail Bustany, Grigor Gasparyan, Andrew B Kahng, Ioannis Koutis, Bodhisatta Pramanik, and Zhiang Wang. 2023. TritonPart Official Implementation. https: //github.com/ABKGroup/TritonPart
2023
-
[3]
Ismail Bustany, Andrew B Kahng, Ioannis Koutis, Bodhisatta Pramanik, and Zhiang Wang. 2022. SpecPart: A supervised spectral framework for hypergraph partitioning solution improvement. InProceedings of International Conference on Computer-Aided Design (ICCAD). 1–9
2022
-
[4]
Ismail Bustany, Andrew B Kahng, Ioannis Koutis, Bodhisatta Pramanik, and Zhiang Wang. 2023. K-SpecPart: Supervised embedding algorithms and cut overlay for improved hypergraph partitioning.IEEE Transactions on Computer- Aided Design of Integrated Circuits and Systems (TCAD)43, 4 (2023), 1232–1245
2023
-
[5]
T-H Hubert Chan and Zhibin Liang. 2020. Generalizing the hypergraph laplacian via a diffusion process with mediators.Theoretical Computer Science (TCS)806 (2020), 416–428
2020
-
[6]
T-H Hubert Chan, Anand Louis, Zhihao Gavin Tang, and Chenzi Zhang. 2018. Spectral properties of hypergraph laplacian and Titaaapproximation algorithms. Journal of the ACM (JACM)65, 3 (2018), 1–48
2018
-
[7]
Alex Fender, Brad Rees, and Joe Eaton. 2022. Rapids cugraph. InMassive Graph Analytics. Chapman and Hall/CRC, 483–493
2022
-
[8]
Zhuo Feng. 2018. Similarity-Aware Spectral Sparsification by Edge Filtering. In Proceedings of Design Automation Conference (DAC). 1–6
2018
-
[9]
Lars Gottesbüren, Tobias Heuer, Nikolai Maas, Peter Sanders, and Sebastian Schlag. 2024. Scalable high-quality hypergraph partitioning.ACM Transactions on Algorithms (TALG)20, 1 (2024), 1–54
2024
-
[10]
Nikolaus Hansen, Youhei Akimoto, and Petr Baudis. 2019. CMA-ES/pycma on Github. https://doi.org/10.5281/zenodo.2559634
-
[11]
Juris Hartmanis. 1982. Computers and intractability: a guide to the theory of np-completeness.Siam Review (SIREV)24, 1 (1982), 90
1982
-
[12]
George Karypis. 1998. hMETIS 1.5: A hypergraph partitioning package. http://www.cs.umn.edu/metis(1998)
1998
-
[13]
George Karypis, Rajat Aggarwal, Vipin Kumar, and Shashi Shekhar. 1997. Mul- tilevel hypergraph partitioning: Application in VLSI domain. InProceedings of Design Automation Conference (DAC). 526–529
1997
-
[14]
Wan Luan Lee, Dian-Lun Lin, Cheng-Hsiang Chiu, Ulf Schlichtmann, and Tsung- Wei Huang. 2025. HyperG: Multilevel GPU-Accelerated k-way hypergraph par- titioner. InProceedings of Asia and South Pacific Design Automation Conference (ASP-DAC). 1031–1040
2025
-
[15]
Rongjian Liang, Anthony Agnesina, and Haoxing Ren. 2024. Medpart: A multi- level evolutionary differentiable hypergraph partitioner. InProceedings of Inter- national Symposium on Physical Design (ISPD). 3–11
2024
-
[16]
Andreas Loukas and Pierre Vandergheynst. 2018. Spectrally Approximating Large Graphs with Smaller Graphs. InProceedings of International Conference on Machine Learning (ICML). 3243–3252
2018
-
[17]
Kevin E Murray, Scott Whitty, Suya Liu, Jason Luu, and Vaughn Betz. 2013. Titan: Enabling large and complex benchmarks in academic CAD. InProceedings of International Conference on Field programmable Logic and Applications (FPL). 1–8
2013
-
[18]
Royud Nishino and Shohei Hido Crissman Loomis. 2017. Cupy: A numpy- compatible library for nvidia gpu calculations.Proceedings of Confernce on Neural Information Processing Systems (NeurIPS)151, 7 (2017)
2017
-
[19]
Hamed Sajadinia, Ali Aghdaei, and Zhuo Feng. 2025. SHyPar: A Spectral Coarsen- ing Approach to Hypergraph Partitioning.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD)(2025)
2025
-
[20]
Sebastian Schlag, Vitali Henne, Tobias Heuer, Henning Meyerhenke, Peter Sanders, and Christian Schulz. 2016. K-way hypergraph partitioning via n-level recursive bisection. InProceedings of Workshop on Algorithm Engineering and Experiments (ALENEX). 53–67
2016
-
[21]
Daniel Spielman and ShangHua Teng. 2011. Spectral sparsification of graphs. SIAM Journal on Computing (SIAM J. Comput.)40, 4 (2011), 981–1025
2011
-
[22]
Spielman and S
D. Spielman and S. Teng. 2014. Nearly Linear Time Algorithms for Precondi- tioning and Solving Symmetric, Diagonally Dominant Linear Systems.SIAM Journal on Matrix Analysis and Applications (SIAM J. Matrix Anal. Appl.)35, 3 (2014), 835–885
2014
-
[23]
Shang-Hua Teng. 2016. Scalable Algorithms for Data and Network Analysis. Foundations and Trends in Theoretical Computer Science (FnT)12, 1–2 (2016), 1–274
2016
-
[24]
Minjie Yu Wang. 2019. Deep graph library: Towards efficient and scalable deep learning on graphs. InProceedings of International Conference on Learning Repre- sentations Workshop on Representation Learning on Graphs and Manifolds (ICLR)
2019
-
[25]
Xueqian Zhao, Zhuo Feng, and Cheng Zhuo. 2014. An Efficient Spectral Graph Sparsification Approach to Scalable Reduction of Large Flip-chip Power Grids. InProceedings of Internation Conference on Computer-Aided Design (ICCAD). 218– 223
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.