TeraGram: A Structured Longitudinal Dataset of the Telegram Messenger
Pith reviewed 2026-05-19 19:14 UTC · model grok-4.3
The pith
A dataset of 5.9 billion Telegram messages collected from 2015 to 2025 supplies raw data for examining social networks free of algorithmic curation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
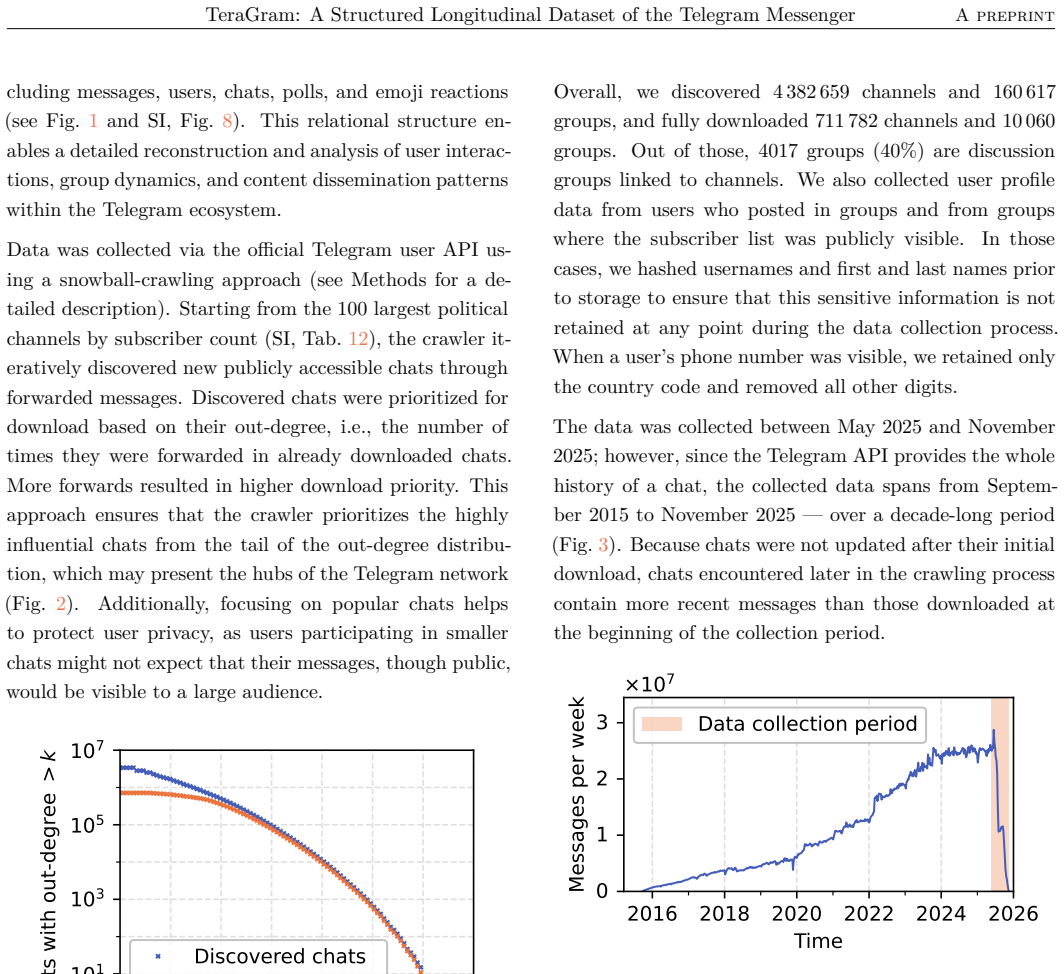
The authors present TeraGram as a structured longitudinal dataset of public Telegram messages that comprises over 5.9 billion items from 2015 to 2025 across 712 thousand channels and groups. The collection includes metadata on forwards, reactions, and polls and covers Russian, Farsi, and Western languages. The dataset is offered as an example of an algorithm-free platform that supports comparative studies of engagement patterns, network evolution, and community formation under identical platform affordances.
What carries the argument
The TeraGram dataset itself, which aggregates public messages and associated metadata to support analysis of engagement and network dynamics in the absence of content-curation algorithms.
If this is right
- Comparative studies of the same platform affordances become possible across languages and regions where Telegram serves different user bases.
- Longitudinal tracking of network growth and community formation can be performed without the confounding influence of recommendation algorithms.
- Analyses of engagement can use concrete signals such as reaction counts, forward chains, and poll participation.
- Researchers gain a shared data resource for testing claims about information spread in environments that lack opaque curation.
Where Pith is reading between the lines
- The dataset could be used to test whether network structures observed on algorithm-driven platforms arise mainly from user choices or from platform interventions.
- Cross-language subsets might reveal how mainstream adoption in one region differs from niche use in another under the same technical rules.
- Future work could link message-level metadata to external events to measure response times in uncurated channels.
Load-bearing premise
That messages drawn only from public channels and filtered by language give a representative picture of how users actually behave on Telegram.
What would settle it
A direct comparison showing that engagement rates or topic distributions in private Telegram groups differ substantially from those recorded in the public portion of the dataset.
Figures








read the original abstract
Here we present a massive longitudinal dataset of public Telegram content, comprising over 5.9 billion messages dating from 2015 to 2025, collected from 712 thousand channels and groups, enriched with metadata on forwards, reactions, and polls. The dataset spans multiple languages including Russian and Farsi, representing countries where Telegram shows mainstream adoption, as well as Western languages where Telegram is used in specific sub-communities. The dataset has several advantages. First, when restricted by language, it provides a versatile example of an algorithm-free platform, contrary to many other social media platforms that are strongly influenced by opaque content-curation algorithms. Second, it enables comparative studies across different languages, communities, and user bases under identical platform affordances. The dataset thus offers a foundation for studying engagement patterns, network evolution, and community formation in the absence of algorithmic curation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TeraGram, a longitudinal dataset of over 5.9 billion public Telegram messages collected from 712 thousand channels and groups between 2015 and 2025. The data include metadata on forwards, reactions, and polls, and span multiple languages (Russian, Farsi, and Western languages). The central claims are that language-restricted subsets offer a versatile example of an algorithm-free platform and enable comparative studies of engagement, network evolution, and community formation under identical platform affordances.
Significance. If the collection and documentation are completed to address sampling and bias concerns, the dataset's scale and longitudinal span would constitute a useful resource for social-physics and computational-social-science research on platform dynamics without algorithmic curation. The explicit framing for cross-language comparisons under fixed affordances is a constructive contribution that could support falsifiable analyses of engagement patterns.
major comments (2)
- [§2] §2 (Data Collection): The manuscript supplies no description of the channel/group discovery or sampling procedure. It is therefore impossible to assess whether the 712k sources were obtained via Telegram search, popularity signals, or exhaustive crawling; any reliance on discoverability metrics would introduce selection bias that directly undermines the abstract's claim that language-restricted subsets yield a representative view of algorithm-free user behavior.
- [Abstract, §4] Abstract and §4 (Advantages): The stated advantage that the dataset provides 'a versatile example of an algorithm-free platform' is load-bearing for the paper's utility argument, yet no validation steps, bias audits, or comparison against Telegram's full public population are reported. Without these, the representativeness required for studies of engagement and community formation cannot be evaluated.
minor comments (2)
- [Table 1] Table 1 (dataset statistics): clarify whether the 5.9B message count includes only text or also media and poll items; the current caption leaves this ambiguous.
- [§3] §3 (Metadata): the forward and reaction fields are described at a high level; explicit schema definitions or example JSON records would improve reproducibility for downstream users.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying key areas where additional documentation and clarification would strengthen the manuscript. We address each major comment below, indicating the revisions made to improve transparency around sampling and to moderate the claims regarding representativeness.
read point-by-point responses
-
Referee: [§2] §2 (Data Collection): The manuscript supplies no description of the channel/group discovery or sampling procedure. It is therefore impossible to assess whether the 712k sources were obtained via Telegram search, popularity signals, or exhaustive crawling; any reliance on discoverability metrics would introduce selection bias that directly undermines the abstract's claim that language-restricted subsets yield a representative view of algorithm-free user behavior.
Authors: We agree that the absence of a sampling description in §2 prevents proper evaluation of selection bias. The original manuscript omitted this detail, focusing instead on the resulting data volume and structure. Collection proceeded via Telegram's public search functionality using language-specific keywords and seed channels drawn from publicly available directories, followed by iterative expansion through forward metadata. This approach necessarily favors discoverable sources and may under-represent private or low-visibility groups. In the revised manuscript we have inserted a new subsection in §2 that fully documents the discovery pipeline, the temporal windows of crawling, the keyword sets employed, and an explicit discussion of the resulting coverage limitations and potential biases. These additions directly enable readers to assess the dataset's suitability for claims about algorithm-free behavior. revision: yes
-
Referee: [Abstract, §4] Abstract and §4 (Advantages): The stated advantage that the dataset provides 'a versatile example of an algorithm-free platform' is load-bearing for the paper's utility argument, yet no validation steps, bias audits, or comparison against Telegram's full public population are reported. Without these, the representativeness required for studies of engagement and community formation cannot be evaluated.
Authors: We accept that the original phrasing overstated the dataset's representativeness without supporting evidence. Telegram public channels and groups operate without the centralized recommendation algorithms that dominate other platforms, making discovery more dependent on explicit user actions such as search and forwarding; however, we did not perform a systematic audit against Telegram's complete public population. In the revised abstract and §4 we have replaced the stronger claim with more precise language stating that the dataset supplies a large-scale, longitudinal record of public content collected under Telegram's native affordances, which lack opaque algorithmic curation. We have added a limitations paragraph that acknowledges the absence of exhaustive population benchmarks and outlines how downstream users can mitigate sampling biases when conducting comparative or engagement analyses. This revision preserves the dataset's utility for cross-language studies while avoiding unsubstantiated representativeness assertions. revision: yes
Circularity Check
No circularity: data-release paper with no derivations or predictions
full rationale
This is a dataset description paper whose central claim is the existence, scale, and described utility of the collected TeraGram dataset for studying engagement on an algorithm-free platform. The abstract and full text contain no equations, fitted parameters, predictions, or derivation chains. No load-bearing steps reduce by construction to self-definitions, fitted inputs, or self-citation chains. Any self-citations (if present) support factual collection details rather than a mathematical result that is forced by the citation itself. The paper is self-contained against external benchmarks as a factual data release; the skeptic concern about selection bias is a question of representativeness, not circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Public Telegram content can be collected at scale in a manner that yields representative samples for studying natural engagement patterns.
- domain assumption Restricting the data by language produces a versatile example of an algorithm-free platform.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Atomicity.leanatomic_tick unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
snowball crawling method... prioritized for download based on their out-degree
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BERTopic... topic modeling pipeline
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Leo A Goodman. “Snowball sampling” . In: The an- nals of mathematical statistics (1961), pp. 148–170
work page 1961
-
[2]
Bag of Tricks for Efficient Text Classification
Armand Joulin et al. Bag of Tricks for Efficient Text Classification. 2016. doi: 10 . 48550 / arXiv . 1607 . 01759. Pre-published. 10 TeraGram: A Structured Longitudinal Dataset of the Telegram Messenger A preprint
work page 2016
-
[3]
FastText.zip: Compressing text classification models
Armand Joulin et al. FastText.Zip: Compressing Text Classification Models . 2016. doi: 10 . 48550 / arXiv.1612.03651. Pre-published
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
The F AIR Guiding Prin- ciples for scientific data management and steward- ship
Mark D Wilkinson et al. “The F AIR Guiding Prin- ciples for scientific data management and steward- ship” . In: Scientific data 3.1 (2016), pp. 1–9
work page 2016
-
[5]
Davood Ghorbanzadeh and Hamid Reza Saeednia. “Examining Telegram Users’ Motivations, Technical Characteristics, Trust, Attitudes, and Positive Word- of-Mouth: Evidence from Iran” . In: International Journal of Electronic Marketing and Retailing 9.4 (2018), pp. 344–365
work page 2018
-
[6]
Censorship and Collateral Damage: Analyzing the Telegram Ban in Iran
Simin Kargar and Keith McManamen. Censorship and Collateral Damage: Analyzing the Telegram Ban in Iran. SSRN Scholarly Paper. Rochester, NY, 2018. doi: 10.2139/ssrn.3244046. Pre-published
-
[7]
Social media as public opin- ion: How journalists use social media to repre- sent public opinion
Shannon C McGregor. “Social media as public opin- ion: How journalists use social media to repre- sent public opinion” . In: Journalism 20.8 (2019), pp. 1070–1086
work page 2019
-
[8]
The Pushshift Telegram Dataset
Jason Baumgartner et al. “The Pushshift Telegram Dataset” . In:Proceedings of the International AAAI Conference on Web and Social Media . International AAAI Conference on Web and Social Media. Vol. 14. 2020, pp. 840–847. doi: 10 . 1609 / icwsm . v14i1 . 7348
work page 2020
-
[9]
Timnit Gebru et al. Datasheets for Datasets . 2021. doi: 10.48550/arXiv.1803.09010. Pre-published
-
[10]
Aleksandra Urman, Justin Chun-ting Ho, and Stefan Katz. “Analyzing Protest Mobilization on Telegram: The Case of 2019 Anti-Extradition Bill Movement in Hong Kong” . In: PLoS ONE 16.10 (2021), e0256675. doi: 10.1371/journal.pone.0256675
-
[11]
US Ex- tremism on Telegram: Fueling Disinformation, Con- spiracy Theories, and Accelerationism
Samantha Walther and Andrew McCoy. “US Ex- tremism on Telegram: Fueling Disinformation, Con- spiracy Theories, and Accelerationism” . In: Perspec- tives on Terrorism 15.2 (2021), pp. 100–124. JSTOR: 27007298
work page 2021
-
[12]
Coordinated Inauthentic Be- havior and Information Spreading on Twitter
Matteo Cinelli et al. “Coordinated Inauthentic Be- havior and Information Spreading on Twitter” . In: Decision Support Systems 160 (2022), p. 113819. doi: 10.1016/j.dss.2022.113819
-
[13]
BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure
Maarten Grootendorst. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure
- [14]
-
[15]
Chris Chao Su, Michael Chan, and Sejin Paik. “Tele- gram and the Anti-ELAB Movement in Hong Kong: Reshaping Networked Social Movements through Symbolic Participation and Spontaneous Interac- tion” . In: Chinese Journal of Communication 15.3 (2022), pp. 431–448. doi: 10.1080/17544750.2022. 2092167
-
[16]
Is Telegram a “Harbinger of Freedom
Mariëlle Wijermars and Tetyana Lokot. “Is Telegram a “Harbinger of Freedom”? The Performance, Prac- tices, and Perception of Platforms as Political Ac- tors in Authoritarian States” . In: Post-Soviet Affairs 38.1–2 (2022), pp. 125–145. doi: 10.1080/1060586X. 2022.2030645
-
[17]
High Level of Correspondence across Different News Domain Quality Rating Sets
Hause Lin et al. “High Level of Correspondence across Different News Domain Quality Rating Sets” . In: PNAS Nexus 2.9 (2023), pgad286. doi: 10.1093/ pnasnexus/pgad286
work page 2023
-
[18]
Media Influence on Public Opinion and Political Decision-Making
Charles Okechukwu. “Media Influence on Public Opinion and Political Decision-Making” . In: Interna- tional Journal of Political Science Studies 1.1 (2023), pp. 13–24
work page 2023
-
[19]
Just Another Day on Twitter: A Complete 24 Hours of Twitter Data
Jürgen Pfeffer et al. “Just Another Day on Twitter: A Complete 24 Hours of Twitter Data” . In: Proceed- ings of the International AAAI Conference on Web and Social Media . Vol. 17. 2023, pp. 1073–1081. doi: 10.1609/icwsm.v17i1.22215
-
[20]
Yanai Elazar et al. What’s In My Big Data? 2024. doi: 10.48550/arXiv.2310.20707. Pre-published
-
[21]
My Profile, Recommended Channels and 15 More Features
Telegram. My Profile, Recommended Channels and 15 More Features . https://telegram.org/blog/my- profile-and-15-more. 2024. (Visited on 01/15/2026)
work page 2024
-
[22]
The Schwurbelarchiv: a German Language Telegram dataset for the Study of Conspiracy Theories
Mathias Angermaier et al. The Schwurbelarchiv: A German Language Telegram Dataset for the Study of Conspiracy Theories . 2025. doi: 10 . 48550 / arXiv . 2504.06318. Pre-published. 11 TeraGram: A Structured Longitudinal Dataset of the Telegram Messenger A preprint
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Telegram as a Battle- field: Kremlin-Related Communications During the Russia-Ukraine Conflict
Apaar Bawa et al. “Telegram as a Battle- field: Kremlin-Related Communications During the Russia-Ukraine Conflict” . In: Proceedings of the In- ternational AAAI Conference on Web and Social Me- dia. Vol. 19. 2025, pp. 2361–2370. doi: 10 . 1609 / icwsm.v19i1.35939
work page 2025
-
[24]
Leonardo Blas, Luca Luceri, and Emilio Ferrara. “Unearthing a Billion Telegram Posts about the 2024 U.S. Presidential Election: Development of a Public Dataset” . In:Companion Proceedings of the ACM on Web Conference 2025. WWW ’25. 2025, pp. 729–732. doi: 10.1145/3701716.3715297
-
[25]
Vincent C. Brockers, David A. Ehrlich, and Viola Priesemann. Disentangling Interaction and Bias Ef- fects in Opinion Dynamics of Large Language Mod- els. 2025. doi: 10.48550/arXiv.2509.06858 . Pre- published
work page internal anchor Pith review doi:10.48550/arxiv.2509.06858 2025
-
[26]
Elizaveta Chernenko and William H. Dutton. Who Trusts Telegram? The Dynamics of Trust and Use of Social Media in Wartime Ukraine . SSRN Schol- arly Paper. 2025. doi: 10.2139/ssrn.5227613. Pre- published
-
[27]
Ideological Fragmen- tation of the Social Media Ecosystem: From Echo Chambers to Echo Platforms
Edoardo Di Martino et al. “Ideological Fragmen- tation of the Social Media Ecosystem: From Echo Chambers to Echo Platforms” . In: PNAS Nexus 4.9 (2025), pgaf262. doi: 10.1093/pnasnexus/pgaf262
-
[28]
https://github.com/LlmKira/fast- langdetect
Fast-Langdetect. https://github.com/LlmKira/fast- langdetect. 2025. (Visited on 12/22/2025)
work page 2025
-
[29]
Susmita Gangopadhyay et al. “TeleScope A Longi- tudinal Dataset for Investigating Online Discourse and Information Interaction on Telegram” . In: Pro- ceedings of the International AAAI Conference on Web and Social Media 19 (2025), pp. 2423–2433. doi: 10.1609/icwsm.v19i1.35945
-
[30]
Johannes Kiess. “Euroscepticism and Local Far- Right Mobilization via Telegram in Light of the Fun- damental Transformation of the Public Sphere” . In: Political Studies Review 23.2 (2025), pp. 635–642. doi: 10.1177/14789299231190731
-
[31]
A Telegram Dataset of Propa- ganda and Its Moderation
Klim Kireev et al. “A Telegram Dataset of Propa- ganda and Its Moderation” . In: Proceedings of the International AAAI Conference on Web and Social Media. Vol. 19. 2025, pp. 2510–2518. doi: 10.1609/ icwsm.v19i1.35952
work page 2025
-
[32]
TGDataset: Collecting and Ex- ploring the Largest Telegram Channels Dataset
Massimo La Morgia, Alessandro Mei, and Alberto Maria Mongardini. “TGDataset: Collecting and Ex- ploring the Largest Telegram Channels Dataset” . In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 . KDD ’25. 2025, pp. 2325–2334. doi: 10 . 1145 / 3690624 . 3709397
work page 2025
-
[33]
https://github.com/pyrogram/pyrogram
Pyrogram: Elegant, Modern and Asynchronous Tele- gram MTProto API Framework in Python for Users and Bots . https://github.com/pyrogram/pyrogram
-
[34]
(Visited on 01/13/2025)
work page 2025
-
[35]
Roman David Ventzke. “Understanding Information Diffusion in Online Social Networks Through the Lens of Critical Processes: A Study on the Tele- gram Messenger Platform” . Master’s Thesis. Göttin- gen, Germany: University of Göttingen, 2025
work page 2025
-
[36]
Network Information En- hances Misinformation Detection on Social Media
Raphaela Keßler et al. Network Information En- hances Misinformation Detection on Social Media . Forthcoming. 2026. 12 Appendix Dataset Size Timespan T opic focus F ormat Includes text F eatures TeraGram 712k chats, 5.95B messages Sep. 2015 – Nov 2025 General purpose Parquet On request Discussion groups, reply trees, polls, emoji reactions Blas et. al 43k...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.