ChartWalker: Benchmarking the Cross-Chart RAG Task with Hierarchical Knowledge Graphs
Pith reviewed 2026-06-26 06:00 UTC · model grok-4.3
The pith
ChartWalker uses hierarchical knowledge graphs to build cross-chart RAG benchmarks with controlled multi-hop questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
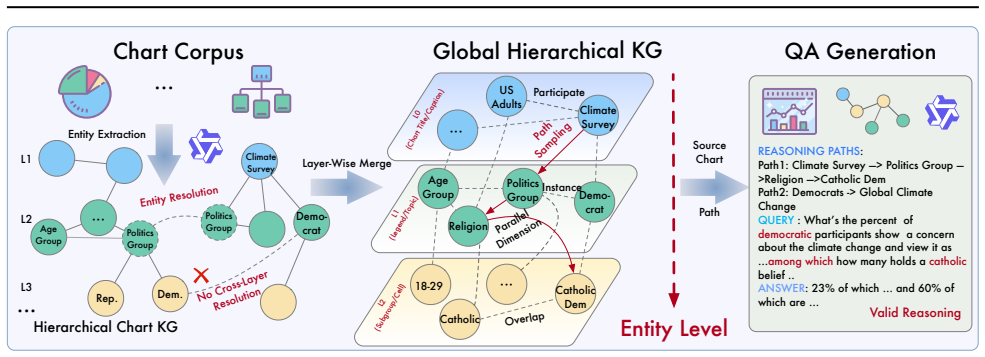
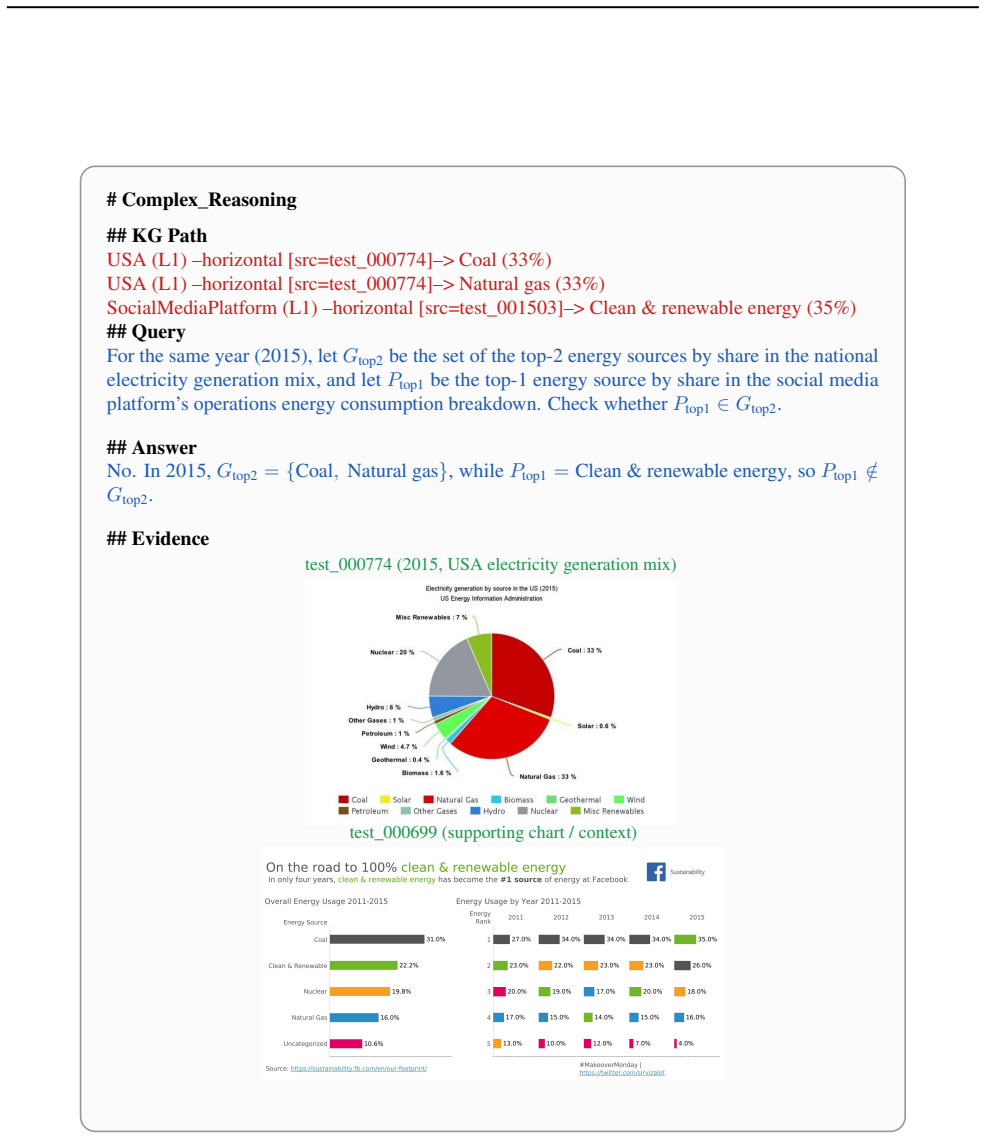
ChartWalker features a hierarchical knowledge graph construction method tailored to charts, which organizes entities and relations by granularity to preserve analytical structure. We then propose a structure-aware sampling algorithm that synthesizes semantically coherent, multi-hop reasoning paths, enabling explicit control over query difficulty and granularity for QA generation. Built with this framework, we release ChartWalker-Bench, a comprehensive benchmark spanning diverse domains and cross-chart query types. Extensive evaluations across major RAG paradigms reveal significant performance gaps, underscoring the benchmark's difficulty and utility. Furthermore, we provide ChartWalker-Agent
What carries the argument
The hierarchical knowledge graph tailored to charts that organizes entities and relations by granularity, together with the structure-aware sampling algorithm that creates multi-hop reasoning paths.
Load-bearing premise
The hierarchical knowledge graph construction and structure-aware sampling produce semantically coherent, logically consistent reasoning chains without lexical overlap between queries and evidence.
What would settle it
Manual inspection of the generated questions revealing either high lexical overlap with chart text or reasoning steps that do not follow logically from the sampled paths would show the method fails to create challenging benchmarks.
Figures







read the original abstract
Cross-Chart Retrieval-Augmented Generation (RAG) is critical for complex multi-modal analytical tasks in scientific, business, and political domains. However, existing benchmarks either focus on tables, which are well-structured and textualized, or generate cross-chart questions by simply extracting key points, which often induces lexical overlap between queries and evidence and yields logically inconsistent reasoning chains. To address this, we introduce ChartWalker, a novel framework for constructing challenging cross-chart RAG tasks. ChartWalker features a hierarchical knowledge graph construction method tailored to charts, which organizes entities and relations by granularity to preserve analytical structure. We then propose a structure-aware sampling algorithm that synthesizes semantically coherent, multi-hop reasoning paths, enabling explicit control over query difficulty and granularity for QA generation. Built with this framework, we release ChartWalker-Bench, a comprehensive benchmark spanning diverse domains and cross-chart query types. Extensive evaluations across major RAG paradigms reveal significant performance gaps, underscoring the benchmark's difficulty and utility. Furthermore, we provide ChartWalker-Agent, an agentic baseline to facilitate analysis and inspire future system design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChartWalker, a framework for constructing cross-chart RAG benchmarks. It proposes a hierarchical knowledge graph construction method that organizes chart entities and relations by granularity, paired with a structure-aware sampling algorithm to synthesize multi-hop reasoning paths for QA generation. This yields ChartWalker-Bench, spanning domains and query types, which is used to evaluate major RAG paradigms (revealing performance gaps) and to provide an agentic baseline (ChartWalker-Agent).
Significance. If the hierarchical KG construction and sampling reliably deliver semantically coherent, logically consistent multi-hop chains without lexical overlap between queries and evidence, the benchmark would address a clear gap in existing chart/table RAG evaluations and support more rigorous testing of cross-chart retrieval and reasoning systems.
major comments (2)
- [Abstract] Abstract: the central claim that the structure-aware sampling algorithm produces 'semantically coherent, multi-hop reasoning paths' that are 'logically consistent' and free of 'lexical overlap between queries and evidence' is load-bearing for the benchmark's claimed utility, yet the abstract (and the reader's summary of the full text) provides no mechanism, predicate, filter, or post-generation empirical check to verify these properties hold for the released dataset.
- [Abstract] Abstract: the statement that 'extensive evaluations across major RAG paradigms reveal significant performance gaps' is presented without any reported metrics, error bars, dataset statistics, or verification that the sampling procedure yields consistent chains; this undermines assessment of the benchmark's difficulty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract point by point below. Both comments correctly identify that the abstract is too high-level; we will revise it accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the structure-aware sampling algorithm produces 'semantically coherent, multi-hop reasoning paths' that are 'logically consistent' and free of 'lexical overlap between queries and evidence' is load-bearing for the benchmark's claimed utility, yet the abstract (and the reader's summary of the full text) provides no mechanism, predicate, filter, or post-generation empirical check to verify these properties hold for the released dataset.
Authors: We agree the abstract does not reference the verification steps. Section 3 details the hierarchical KG construction that organizes entities and relations by granularity. Section 4 describes the structure-aware sampling algorithm, which incorporates explicit predicates and filters for semantic coherence, logical consistency, and absence of lexical overlap. Section 5 reports post-generation empirical checks (including manual validation and automated metrics) confirming these properties on the released dataset. We will revise the abstract to briefly mention these mechanisms and checks. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'extensive evaluations across major RAG paradigms reveal significant performance gaps' is presented without any reported metrics, error bars, dataset statistics, or verification that the sampling procedure yields consistent chains; this undermines assessment of the benchmark's difficulty.
Authors: The abstract summarizes results at a high level without numbers. The full manuscript reports concrete metrics, error bars, dataset statistics (e.g., number of queries, domains, hop distributions), and sampling verification in the evaluation section. We will revise the abstract to include key quantitative results (such as average performance gaps across RAG paradigms) and a brief note on sampling consistency to strengthen the claim. revision: yes
Circularity Check
No circularity: benchmark construction is self-contained
full rationale
The paper describes a constructive framework for building ChartWalker-Bench via hierarchical knowledge graph organization by granularity and a structure-aware sampling algorithm to generate multi-hop QA pairs. No equations, fitted parameters, predictions of derived quantities, or self-citations are invoked as load-bearing steps in any derivation chain. The central claims concern the properties of the released benchmark rather than any result that reduces to its own inputs by construction. This is the expected non-finding for a benchmark-release paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Charts can be represented as hierarchical knowledge graphs that organize entities and relations by granularity to preserve analytical structure.
- domain assumption Structure-aware sampling can synthesize semantically coherent multi-hop reasoning paths with explicit control over difficulty.
invented entities (2)
-
hierarchical knowledge graph tailored to charts
no independent evidence
-
structure-aware sampling algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report, 2025 a
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
Pith/arXiv arXiv 2025
-
[2]
Qwen2.5-vl technical report, 2025 b
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., and Lin, J. Qwen2.5-vl technical report, 2025 b . URL https://arxiv.org/abs/2502.13923
Pith/arXiv arXiv 2025
-
[4]
Cheng, K., Lin, G., Fei, H., zhai, Y., Yu, L., Ali, M. A., Hu, L., and Wang, D. Multi-hop question answering under temporal knowledge editing, 2024. URL https://arxiv.org/abs/2404.00492
arXiv 2024
-
[6]
Webwatcher: Breaking new frontier of vision-language deep research agent, 2025
Geng, X., Xia, P., Zhang, Z., Wang, X., Wang, Q., Ding, R., Wang, C., Wu, J., Zhao, Y., Li, K., Jiang, Y., Xie, P., Huang, F., and Zhou, J. Webwatcher: Breaking new frontier of vision-language deep research agent, 2025. URL https://arxiv.org/abs/2508.05748
Pith/arXiv arXiv 2025
-
[7]
Rag-anything: All-in-one rag framework, 2025
Guo, Z., Ren, X., Xu, L., Zhang, J., and Huang, C. Rag-anything: All-in-one rag framework, 2025. URL https://arxiv.org/abs/2510.12323
arXiv 2025
-
[8]
J., Shu, Y., Qi, W., Zhou, S., and Su, Y
Gutiérrez, B. J., Shu, Y., Qi, W., Zhou, S., and Su, Y. From rag to memory: Non-parametric continual learning for large language models, 2025. URL https://arxiv.org/abs/2502.14802
Pith/arXiv arXiv 2025
-
[9]
Han, H., Wang, Y., Shomer, H., Guo, K., Ding, J., Lei, Y., Halappanavar, M., Rossi, R. A., Mukherjee, S., Tang, X., He, Q., Hua, Z., Long, B., Zhao, T., Shah, N., Javari, A., Xia, Y., and Tang, J. Retrieval-augmented generation with graphs (graphrag), 2025. URL https://arxiv.org/abs/2501.00309
Pith/arXiv arXiv 2025
-
[10]
Herzig, J., Müller, T., Krichene, S., and Eisenschlos, J. M. Open domain question answering over tables via dense retrieval, 2021. URL https://arxiv.org/abs/2103.12011
arXiv 2021
-
[14]
Open-wikitable: Dataset for open domain question answering with complex reasoning over table, 2023
Kweon, S., Kwon, Y., Cho, S., Jo, Y., and Choi, E. Open-wikitable: Dataset for open domain question answering with complex reasoning over table, 2023. URL https://arxiv.org/abs/2305.07288
arXiv 2023
-
[16]
Mimotable: A multi-scale spreadsheet benchmark with meta operations for table reasoning, 2024
Li, Z., Du, Y., Zheng, M., and Song, M. Mimotable: A multi-scale spreadsheet benchmark with meta operations for table reasoning, 2024. URL https://arxiv.org/abs/2412.11711
arXiv 2024
-
[17]
Graphsearchnet: Enhancing gnns via capturing global dependencies for semantic code search, 2023
Liu, S., Xie, X., Siow, J., Ma, L., Meng, G., and Liu, Y. Graphsearchnet: Enhancing gnns via capturing global dependencies for semantic code search, 2023. URL https://arxiv.org/abs/2111.02671
arXiv 2023
-
[18]
Deepdive: Advancing deep search agents with knowledge graphs and multi-turn rl, 2025
Lu, R., Hou, Z., Wang, Z., Zhang, H., Liu, X., Li, Y., Feng, S., Tang, J., and Dong, Y. Deepdive: Advancing deep search agents with knowledge graphs and multi-turn rl, 2025. URL https://arxiv.org/abs/2509.10446
arXiv 2025
-
[20]
Multi-hop question answering, 2024
Mavi, V., Jangra, A., and Jatowt, A. Multi-hop question answering, 2024. URL https://arxiv.org/abs/2204.09140
arXiv 2024
-
[21]
Norasaed, W. and Siriborvornratanakul, T. Market movement prediction using chart patterns and attention mechanism. Discover Analytics, 2 0 (1), 2024. doi:10.1007/s44257-023-00007-6. URL https://doi.org/10.1007/s44257-023-00007-6
-
[22]
Hello GPT-4
OpenAI . Hello GPT-4 . https://openai.com/index/hello-gpt-4o/, 2024
2024
-
[24]
Robertson, S. E. and Walker, S. Some Simple Effective Approximations to the 2-Poisson Model for Probabilistic Weighted Retrieval . In Proceedings of the 17th International ACM SIGIR Conference on Research and Development in Information Retrieval (Special Issue of the SIGIR Forum) , pp.\ 232--241. Springer-Verlag , 1994. ISBN 3-540-19889-X
1994
-
[25]
Proximal policy optimization algorithms, 2017
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms, 2017. URL https://arxiv.org/abs/1707.06347
Pith/arXiv arXiv 2017
-
[26]
Reasoning in trees: Improving retrieval-augmented generation for multi-hop question answering, 2026
Shi, Y., Sun, M., Liu, Z., Yang, M., Fang, Y., Sun, T., and Gu, X. Reasoning in trees: Improving retrieval-augmented generation for multi-hop question answering, 2026. URL https://arxiv.org/abs/2601.11255
arXiv 2026
-
[27]
Mtabvqa: Evaluating multi-tabular reasoning of language models in visual space, 2025 a
Singh, A., Biemann, C., and Strich, J. Mtabvqa: Evaluating multi-tabular reasoning of language models in visual space, 2025 a . URL https://arxiv.org/abs/2506.11684
arXiv 2025
-
[28]
Singh, A., Ehtesham, A., Kumar, S., and Khoei, T. T. Agentic retrieval-augmented generation: A survey on agentic rag, 2025 b . URL https://arxiv.org/abs/2501.09136
Pith/arXiv arXiv 2025
-
[29]
Vagen:reinforcing world model reasoning for multi-turn vlm agents, 2025
Wang*, K., Zhang*, P., Wang*, Z., Gao*, Y., Li*, L., Wang, Q., Chen, H., Wan, C., Lu, Y., Yang, Z., Wang, L., Krishna, R., Wu, J., Fei-Fei, L., Choi, Y., and Li, M. Vagen:reinforcing world model reasoning for multi-turn vlm agents, 2025. URL https://vagen-ai.github.io/
2025
-
[31]
Infochartqa: A benchmark for multimodal question answering on infographic charts, 2025
Xie, T., Lin, M., Liu, M., Ye, Y., Chen, C., and Liu, S. Infochartqa: A benchmark for multimodal question answering on infographic charts, 2025. URL https://arxiv.org/abs/2505.19028
arXiv 2025
-
[33]
W., Salakhutdinov, R., and Manning, C
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., and Manning, C. D. Hotpotqa: A dataset for diverse, explainable multi-hop question answering, 2018. URL https://arxiv.org/abs/1809.09600
Pith/arXiv arXiv 2018
-
[34]
Tablerag: A retrieval augmented generation framework for heterogeneous document reasoning, 2025
Yu, X., Jian, P., and Chen, C. Tablerag: A retrieval augmented generation framework for heterogeneous document reasoning, 2025. URL https://arxiv.org/abs/2506.10380
arXiv 2025
-
[35]
A graph representation of semi-structured data for web question answering, 2020
Zhang, X., Shou, L., Pei, J., Gong, M., Wen, L., and Jiang, D. A graph representation of semi-structured data for web question answering, 2020. URL https://arxiv.org/abs/2010.06801
arXiv 2020
-
[37]
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023. URL https://arxiv.org/abs/2306.05685
Pith/arXiv arXiv 2023
-
[38]
Seq2sql: Generating structured queries from natural language using reinforcement learning, 2017
Zhong, V., Xiong, C., and Socher, R. Seq2sql: Generating structured queries from natural language using reinforcement learning, 2017. URL https://arxiv.org/abs/1709.00103
Pith/arXiv arXiv 2017
-
[39]
Rag over tables: Hierarchical memory index, multi-stage retrieval, and benchmarking, 2025
Zou, J., Fu, D., Chen, S., He, X., Li, Z., Zhu, Y., Han, J., and He, J. Rag over tables: Hierarchical memory index, multi-stage retrieval, and benchmarking, 2025. URL https://arxiv.org/abs/2504.01346
arXiv 2025
-
[40]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[41]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[42]
M. J. Kearns , title =
-
[43]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[44]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[45]
Suppressed for Anonymity , author=
-
[46]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[47]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[48]
arXiv preprint arXiv:2502.14864 , year=
Benchmarking Multimodal RAG through a Chart-based Document Question-Answering Generation Framework , author=. arXiv preprint arXiv:2502.14864 , year=
-
[49]
arXiv preprint arXiv:2504.05506 , year=
ChartQAPro: A more diverse and challenging benchmark for chart question answering , author=. arXiv preprint arXiv:2504.05506 , year=
-
[50]
2024 , eprint=
MiMoTable: A Multi-scale Spreadsheet Benchmark with Meta Operations for Table Reasoning , author=. 2024 , eprint=
2024
-
[51]
arXiv preprint arXiv:2510.24701 , year=
Tongyi DeepResearch Technical Report , author=. arXiv preprint arXiv:2510.24701 , year=
-
[52]
2025 , eprint=
MTabVQA: Evaluating Multi-Tabular Reasoning of Language Models in Visual Space , author=. 2025 , eprint=
2025
-
[53]
2025 , eprint=
DeepDive: Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL , author=. 2025 , eprint=
2025
-
[54]
2025 , eprint=
TableRAG: A Retrieval Augmented Generation Framework for Heterogeneous Document Reasoning , author=. 2025 , eprint=
2025
-
[55]
2025 , eprint=
RAG over Tables: Hierarchical Memory Index, Multi-Stage Retrieval, and Benchmarking , author=. 2025 , eprint=
2025
-
[56]
Compositional Semantic Parsing on Semi-Structured Tables
Pasupat, Panupong and Liang, Percy. Compositional Semantic Parsing on Semi-Structured Tables. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2015. doi:10.3115/v1/P15-1142
-
[57]
2023 , eprint=
Open-WikiTable: Dataset for Open Domain Question Answering with Complex Reasoning over Table , author=. 2023 , eprint=
2023
-
[58]
2025 , url=
VAGEN:Reinforcing World Model Reasoning for Multi-Turn VLM Agents , author=. 2025 , url=
2025
-
[59]
2025 , eprint=
Retrieval-Augmented Generation with Graphs (GraphRAG) , author=. 2025 , eprint=
2025
-
[60]
2025 , eprint=
RAG-Anything: All-in-One RAG Framework , author=. 2025 , eprint=
2025
-
[61]
The anatomy of a large-scale hypertextual Web search engine , journal =
Sergey Brin and Lawrence Page , keywords =. The anatomy of a large-scale hypertextual Web search engine , journal =. 1998 , note =. doi:https://doi.org/10.1016/S0169-7552(98)00110-X , url =
-
[62]
2017 , eprint=
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning , author=. 2017 , eprint=
2017
-
[63]
2025 , eprint=
InfoChartQA: A Benchmark for Multimodal Question Answering on Infographic Charts , author=. 2025 , eprint=
2025
-
[64]
2021 , eprint=
Open Domain Question Answering over Tables via Dense Retrieval , author=. 2021 , eprint=
2021
-
[65]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[66]
2020 , eprint=
A Graph Representation of Semi-structured Data for Web Question Answering , author=. 2020 , eprint=
2020
-
[67]
2025 , eprint=
From RAG to Memory: Non-Parametric Continual Learning for Large Language Models , author=. 2025 , eprint=
2025
-
[68]
arXiv preprint arXiv:2601.04720 , year=
Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking , author=. arXiv preprint arXiv:2601.04720 , year=
-
[69]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[70]
Robertson and Steve Walker
Stephen E. Robertson and Steve Walker. Some Simple Effective Approximations to the 2-Poisson Model for Probabilistic Weighted Retrieval. Proceedings of the 17th International ACM SIGIR Conference on Research and Development in Information Retrieval (Special Issue of the SIGIR Forum)
-
[71]
2024 , howpublished =
Hello. 2024 , howpublished =
2024
-
[72]
Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems , pages =
Kim, Dae Hyun and Hoque, Enamul and Agrawala, Maneesh , title =. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems , pages =. 2020 , isbn =. doi:10.1145/3313831.3376467 , abstract =
-
[73]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[74]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[75]
2025 , eprint=
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG , author=. 2025 , eprint=
2025
-
[76]
2025 , eprint=
WebWatcher: Breaking New Frontier of Vision-Language Deep Research Agent , author=. 2025 , eprint=
2025
-
[77]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[78]
2020 , eprint=
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps , author=. 2020 , eprint=
2020
-
[79]
2018 , eprint=
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. 2018 , eprint=
2018
-
[80]
A key review on graph data science: The power of graphs in scientific studies , journal =
Resul Das and Mucahit Soylu , keywords =. A key review on graph data science: The power of graphs in scientific studies , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.chemolab.2023.104896 , url =
-
[81]
Discover Analytics , volume =
Norasaed, Witawat and Siriborvornratanakul, Thitirat , title =. Discover Analytics , volume =. 2024 , doi =
2024
-
[82]
Perspectives on Politics , author=
Using Graphs Instead of Tables in Political Science , volume=. Perspectives on Politics , author=. 2007 , pages=. doi:10.1017/S1537592707072209 , number=
-
[83]
2024 , eprint=
Multi-hop Question Answering , author=. 2024 , eprint=
2024
-
[84]
Kumar, Vishwajeet and Hua, Yuncheng and Ramakrishnan, Ganesh and Qi, Guilin and Gao, Lianli and Li, Yuan-Fang , title =. 2019 , isbn =. doi:10.1007/978-3-030-30793-6_22 , booktitle =
-
[85]
2023 , eprint=
GraphSearchNet: Enhancing GNNs via Capturing Global Dependencies for Semantic Code Search , author=. 2023 , eprint=
2023
-
[86]
KCS : Diversify Multi-hop Question Generation with Knowledge Composition Sampling
Wang, Yangfan and Liu, Jie and Tang, Chen and Yan, Lian and Jiang, Jingchi. KCS : Diversify Multi-hop Question Generation with Knowledge Composition Sampling. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1181
-
[87]
2026 , eprint=
Reasoning in Trees: Improving Retrieval-Augmented Generation for Multi-Hop Question Answering , author=. 2026 , eprint=
2026
-
[88]
2024 , eprint=
Multi-hop Question Answering under Temporal Knowledge Editing , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.