GeoFlow-SLAM++: A Robust Multi-Camera Visual-Inertial SLAM System with Relocalization
Pith reviewed 2026-06-26 12:06 UTC · model grok-4.3
The pith
A multi-camera visual-inertial SLAM system unifies tracking and cross-view relocalization to reach LiDAR-comparable accuracy on handheld datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
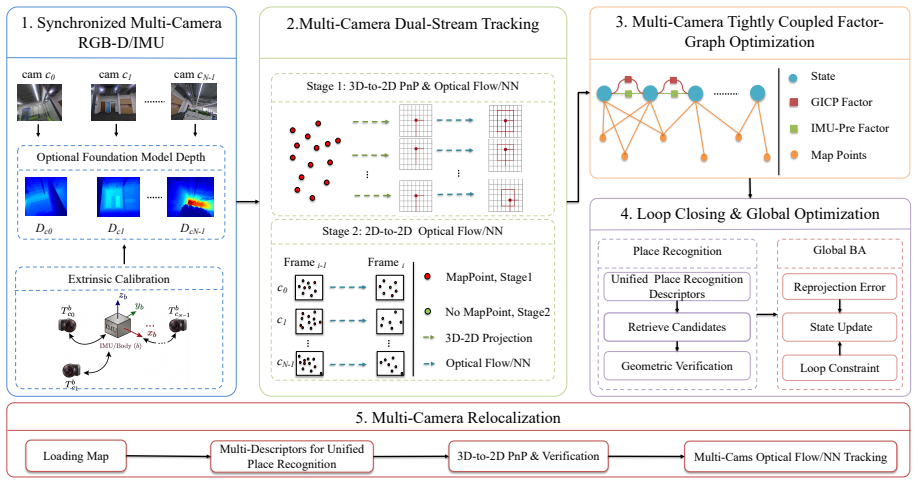
GeoFlow-SLAM++ replaces the single RGB-D sensor of the original system with a rigidly calibrated multi-camera rig and places tracking, mapping, and relocalization on a single body-centric state vector. The system accepts either an ORB or a SuperPoint-LightGlue front-end, enforces multi-camera reprojection constraints together with IMU pre-integration, and adds cross-view place recognition plus dual-stream optical-flow or NN-feature tracking. On the self-collected handheld multi-camera dataset this cross-view relocalization pipeline reaches accuracy levels reported for LiDAR-based systems.
What carries the argument
The unified body-centric formulation that merges multi-camera reprojection, IMU pre-integration, cross-view place recognition, and dual-stream tracking into one shared state.
If this is right
- The multi-camera formulation reduces failure from single-camera field-of-view limits or appearance change.
- Switching to the NN-Feature front-end improves robustness in appearance-challenging sequences relative to the ORB front-end.
- The same unified state and cross-view modules produce competitive accuracy on the Hilti dataset.
- The relocalization pipeline reaches LiDAR-comparable performance on the authors' handheld multi-camera collection.
- Optional pseudo-depth predictions from RGB images can be added as extra geometric constraints without changing the core formulation.
Where Pith is reading between the lines
- The same cross-view consistency mechanism could be tested on other rigidly mounted multi-camera rigs without re-deriving the body-centric state.
- If calibration remains stable, the dual-stream design suggests a route to recover from temporary loss of one or two cameras during long sessions.
- The reported gains on the handheld dataset imply that explicit cross-view place recognition may be more decisive for relocalization than simply adding more cameras.
Load-bearing premise
The multi-camera rig must be accurately pre-calibrated and the cross-view place recognition plus dual-stream tracking must stay reliable when any single camera sees limited field of view or appearance change.
What would settle it
A measurement on the handheld dataset in which the reported relocalization error exceeds the error range of the LiDAR reference system by more than the paper's stated margin would falsify the LiDAR-comparable claim.
Figures



read the original abstract
Monocular and RGB-D visual-inertial SLAM systems remain susceptible to limited field of view, sensor-specific failure modes, and unreliable cross-session relocalization. To address these issues, we present GeoFlow-SLAM++, a tightly coupled multi-camera visual-inertial SLAM system that extends GeoFlow-SLAM from a single RGB-D sensor to a calibrated multi-camera rig with a unified body-centric formulation. Within this multi-camera framework, GeoFlow-SLAM++ supports two interchangeable visual front-ends: a conventional ORB front-end and a neural network feature (NN-Feature) front-end built on SuperPoint and LightGlue. The system unifies tracking, mapping, and relocalization on a shared body state, and combines multi-camera reprojection constraints, IMU pre-integration, cross-view place recognition, and dual-stream optical flow/NN-Feature tracking for robust localization. As an optional extension, the system can further incorporate cross-view-consistent pseudo-depth predictions from RGB images as auxiliary geometric constraints. We evaluate GeoFlow-SLAM++ on EuRoC, OpenLORIS, TUM, Hilti, and a self-collected handheld multi-camera dataset. Results show that the NN-Feature front-end improves robustness in appearance-challenging scenarios, the multi-camera formulation achieves competitive localization accuracy on Hilti, and the unified cross-view relocalization design reaches LiDAR-comparable performance on the handheld dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GeoFlow-SLAM++, an extension of GeoFlow-SLAM to a calibrated multi-camera visual-inertial SLAM system using a unified body-centric formulation. It supports interchangeable ORB and NN-Feature (SuperPoint+LightGlue) front-ends, integrates multi-camera reprojection, IMU pre-integration, cross-view place recognition, and dual-stream tracking, with an optional pseudo-depth extension. Evaluations on EuRoC, OpenLORIS, TUM, Hilti, and a self-collected handheld dataset claim competitive accuracy, improved robustness in appearance-challenging scenarios, and LiDAR-comparable relocalization performance on the handheld set.
Significance. If the central claims hold, the unified multi-camera formulation with cross-view relocalization would represent a meaningful advance in handling limited FOV and appearance variation in VIO-SLAM, building on prior single-sensor work. The interchangeable front-ends and multi-dataset evaluation provide a practical contribution, though the absence of error bars, ablations, or calibration metrics limits immediate impact assessment.
major comments (2)
- [Abstract] Abstract: The claim that 'the unified cross-view relocalization design reaches LiDAR-comparable performance on the handheld dataset' is the central result, yet the manuscript provides no quantitative calibration residuals, no ablation on single-camera dropout, and no failure-case metrics for the place-recognition module. This directly undermines validation of the weakest assumption that the rig remains accurately pre-calibrated and cross-view matching remains reliable under limited FOV or appearance change.
- [Evaluation] Evaluation sections (referenced via dataset results): Performance numbers are stated on EuRoC, OpenLORIS, TUM, Hilti, and the self-collected set without error bars, exclusion criteria, or explicit baseline comparisons, making it impossible to assess post-hoc selection or statistical significance of the reported improvements over prior single-camera systems.
minor comments (1)
- [System description] The abstract and system description would benefit from explicit notation for the body-centric state vector and how cross-view constraints are formulated in the optimization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in validation and statistical presentation that we will address in revision. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'the unified cross-view relocalization design reaches LiDAR-comparable performance on the handheld dataset' is the central result, yet the manuscript provides no quantitative calibration residuals, no ablation on single-camera dropout, and no failure-case metrics for the place-recognition module. This directly undermines validation of the weakest assumption that the rig remains accurately pre-calibrated and cross-view matching remains reliable under limited FOV or appearance change.
Authors: We agree the central claim requires stronger supporting evidence. The evaluation section reports relocalization accuracy on the handheld dataset with LiDAR comparisons, but we acknowledge the absence of explicit calibration residuals, single-camera dropout ablations, and place-recognition failure metrics. In the revised manuscript we will add a calibration accuracy table, an ablation on camera dropout, and place-recognition failure-case analysis (e.g., recall under appearance variation). These additions will be included. revision: yes
-
Referee: [Evaluation] Evaluation sections (referenced via dataset results): Performance numbers are stated on EuRoC, OpenLORIS, TUM, Hilti, and the self-collected set without error bars, exclusion criteria, or explicit baseline comparisons, making it impossible to assess post-hoc selection or statistical significance of the reported improvements over prior single-camera systems.
Authors: We accept that greater statistical transparency is needed. The tables already contain comparisons to prior single-camera systems, but we will add error bars (standard deviations across runs), state exclusion criteria for failed sequences, and make baseline comparisons more explicit in text and tables. These changes will be incorporated to allow assessment of significance and selection. revision: yes
Circularity Check
No circularity in claims or formulations
full rationale
The paper describes an engineering SLAM system extending prior work and reports empirical accuracy on external public datasets (EuRoC, OpenLORIS, TUM, Hilti) plus a self-collected handheld set. No equations, fitted parameters, or predictions are shown that reduce reported performance to self-referential definitions or self-citation chains. The unified body-centric formulation and relocalization design are presented as system architecture choices whose validity is tested via independent benchmarks rather than derived by construction from inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM,
C. Campos, R. Elvira, J. J. G ´omez Rodr ´ıguez, J. M. M. Montiel, and J. D. Tard ´os, “ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM,”IEEE Transactions on Robotics, vol. 37, no. 6, pp. 1874–1890, 2021
2021
-
[2]
S-vio: Exploiting structural constraints for rgb- d visual inertial odometry,
P. Gu and Z. Meng, “S-vio: Exploiting structural constraints for rgb- d visual inertial odometry,”IEEE Robotics and Automation Letters, vol. 8, no. 6, pp. 3542–3549, 2023
2023
-
[3]
VINS-Mono: A robust and versa- tile monocular visual-inertial state estimator,
T. Qin, P. Li, and S. Shen, “VINS-Mono: A robust and versa- tile monocular visual-inertial state estimator,”IEEE Transactions on Robotics, vol. 34, no. 4, pp. 1004–1020, 2018
2018
-
[4]
T. Qin, S. Cao, J. Pan, and S. Shen, “VINS-Fusion: A general optimization-based framework for global pose estimation with multiple sensors,”arXiv preprint arXiv:1901.03642, 2019
Pith/arXiv arXiv 1901
-
[5]
Rgbd-inertial trajectory estima- tion and mapping for ground robots,
Z. Shan, R. Li, and S. Schwertfeger, “Rgbd-inertial trajectory estima- tion and mapping for ground robots,”Sensors, vol. 19, no. 10, p. 2251, 2019
2019
-
[6]
Keyframe-based visual-inertial odometry using nonlinear optimiza- tion,
S. Leutenegger, S. Lynen, M. Bosse, R. Siegwart, and P. Furgale, “Keyframe-based visual-inertial odometry using nonlinear optimiza- tion,”The International Journal of Robotics Research, vol. 34, no. 3, pp. 314–334, 2015
2015
-
[7]
Geoflow-slam: A robust tightly-coupled rgbd-inertial and legged odometry fusion slam for dynamic legged robotics,
T. Xiao, X. Zhou, L. Liu, W. Sui, W. Feng, J. Qiu, X. Wang, and Z. Su, “Geoflow-slam: A robust tightly-coupled rgbd-inertial and legged odometry fusion slam for dynamic legged robotics,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 15 181–15 188
2025
-
[8]
Generalized-ICP,
A. Segal, D. Haehnel, and S. Thrun, “Generalized-ICP,” inRobotics: Science and Systems, vol. 2, no. 4, 2009, p. 435
2009
-
[9]
MA VIS: Multi-camera augmented visual-inertial SLAM using SE2(3)based exact IMU pre-integration,
Y . Wang, Y . Ng, I. Sa, A. Parra, C. Rodriguez, T. J. Lin, and H. Li, “MA VIS: Multi-camera augmented visual-inertial SLAM using SE2(3)based exact IMU pre-integration,” inIEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 1694–1700
2024
-
[10]
Multicam-SLAM: Non-overlapping multi- camera SLAM for indirect visual localization and navigation,
S. Li, L. Pang, and X. Hu, “Multicam-SLAM: Non-overlapping multi- camera SLAM for indirect visual localization and navigation,”arXiv preprint arXiv:2406.06374, 2024
arXiv 2024
-
[11]
FAST-LIO2: Fast direct LiDAR-inertial odometry,
W. Xu, Y . Cai, D. He, J. Lin, and F. Zhang, “FAST-LIO2: Fast direct LiDAR-inertial odometry,”IEEE Transactions on Robotics, vol. 38, no. 4, pp. 2053–2073, 2022
2053
-
[12]
R 3LIVE: A robust, real-time, RGB-colored, LiDAR-inertial-visual tightly-coupled state estimation and mapping package,
J. Lin and F. Zhang, “R 3LIVE: A robust, real-time, RGB-colored, LiDAR-inertial-visual tightly-coupled state estimation and mapping package,” inIEEE International Conference on Robotics and Automa- tion (ICRA). IEEE, 2022, pp. 10 672–10 678
2022
-
[13]
FAST-LIVO2: Fast, direct LiDAR-inertial-visual odometry,
C. Zheng, W. Xu, Z. Zou, T. Hua, C. Yuan, D. He, B. Zhou, Z. Liu, J. Lin, F. Zhu, Y . Ren, R. Wang, F. Meng, and F. Zhang, “FAST-LIVO2: Fast, direct LiDAR-inertial-visual odometry,”IEEE Transactions on Robotics, vol. 41, pp. 326–346, 2024
2024
-
[14]
Y . Cao, C. Zhang, X. He, Y . Chen, C. Pu, B. Wang, K. Wu, S. Zhu, F. Han, S. Liu, C. Li, and J. Wang, “Omni-LIVO: Robust RGB- colored multi-camera visual-inertial-LiDAR odometry via photometric migration and ESIKF fusion,”IEEE Robotics and Automation Letters, 2026, early Access, arXiv:2509.15673
arXiv 2026
-
[15]
SuperPoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperPoint: Self- supervised interest point detection and description,” inIEEE Con- ference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018, pp. 224–236
2018
-
[16]
LightGlue: Local fea- ture matching at light speed,
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “LightGlue: Local fea- ture matching at light speed,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 17 627–17 638
2023
-
[17]
NetVLAD: CNN architecture for weakly supervised place recogni- tion,
R. Arandjelovi ´c, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “NetVLAD: CNN architecture for weakly supervised place recogni- tion,” inIEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2016, pp. 5297–5307
2016
-
[18]
MixVPR: Feature mixing for visual place recognition,
A. Ali-bey, B. Chaib-draa, and P. Gigu `ere, “MixVPR: Feature mixing for visual place recognition,” inIEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023, pp. 2998–3007
2023
-
[19]
BoQ: A place is worth a bag of learnable queries,
A. Ali-Bey, B. Chaib-Draa, and P. Giguere, “BoQ: A place is worth a bag of learnable queries,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 17 794–17 803
2024
-
[20]
Bags of binary words for fast place recognition in image sequences,
D. G ´alvez-L´opez and J. D. Tard´os, “Bags of binary words for fast place recognition in image sequences,”IEEE Transactions on Robotics, vol. 28, no. 5, pp. 1188–1197, 2012
2012
-
[21]
Supervins: A real-time visual-inertial slam framework for challenging imaging conditions,
H. Luo, Y . Liu, C. Guo, Z. Li, and W. Song, “Supervins: A real-time visual-inertial slam framework for challenging imaging conditions,” IEEE Sensors Journal, 2025
2025
-
[22]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 10 371–10 381
2024
-
[23]
Depth anything V2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything V2,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 37, 2024, pp. 21 875–21 911
2024
-
[24]
Depth anything 3: Recovering the visual space from any views,
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,”arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[25]
DUSt3R: Geometric 3D vision made easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “DUSt3R: Geometric 3D vision made easy,” inIEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2024, pp. 20 697– 20 709
2024
-
[26]
Grounding image matching in 3D with MASt3R,
V . Leroy, Y . Cabon, and J. Revaud, “Grounding image matching in 3D with MASt3R,” inEuropean Conference on Computer Vision (ECCV). Springer, 2024, pp. 71–91
2024
-
[27]
VGGT: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “VGGT: Visual geometry grounded transformer,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 5294–5306
2025
-
[28]
Iris-slam: Unified geo-instance representations for robust semantic localization and mapping,
T. Xiao, L. Liu, W. Feng, Z. Zou, X. Zhou, W. Sui, H. Li, D. Zhang, and Z. Su, “Iris-slam: Unified geo-instance representations for robust semantic localization and mapping,” 2026. [Online]. Available: https://arxiv.org/abs/2602.18709
arXiv 2026
-
[29]
The Hilti SLAM challenge dataset,
M. Helmberger, K. Morin, B. Berner, N. Kumar, G. Cioffi, and D. Scaramuzza, “The Hilti SLAM challenge dataset,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 7518–7525, 2022
2022
-
[30]
A benchmark for the evaluation of RGB-D SLAM systems,
J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of RGB-D SLAM systems,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012, pp. 573–580
2012
-
[31]
The EuRoC micro aerial vehicle datasets,
M. Burri, J. Nikolic, P. Gohl, T. Schneider, J. Rehder, S. Omari, M. W. Achtelik, and R. Siegwart, “The EuRoC micro aerial vehicle datasets,” The International Journal of Robotics Research, vol. 35, no. 10, pp. 1157–1163, 2016
2016
-
[32]
Are we ready for service robots? the OpenLORIS-Scene datasets for lifelong SLAM,
X. Shi, D. Li, P. Zhao, Q. Tian, Y . Tian, Q. Long, C. Zhu, J. Song, F. Qiao, L. Songet al., “Are we ready for service robots? the OpenLORIS-Scene datasets for lifelong SLAM,” inIEEE Interna- tional Conference on Robotics and Automation (ICRA), 2020, pp. 3139–3145
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.