Eidola: Modeling Multi-GPU Network Communication Traffic in Distributed AI Workloads
Pith reviewed 2026-06-27 08:08 UTC · model grok-4.3
The pith
Eidola extends gem5 to emulate inter-GPU peer-to-peer writes at cycle level from annotated real-application timing profiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Eidola provides a succinct eidolon representation of GPUs that emulates only the minimal traits required for traffic modeling, using annotated timing profiles to achieve cycle-level accuracy on peer-to-peer writes and thereby supporting analysis of synchronization across large configurations.
What carries the argument
The succinct eidolon GPU model that emulates minimal characteristics for traffic modeling from annotated timing profiles.
If this is right
- Enables simulation of synchronization behavior across arbitrary large multi-GPU configurations.
- Supports isolated performance analysis of different per-GPU traffic patterns and communication scenarios.
- Reproduces variability in fused kernel execution times.
- Confirms that SyncMon-inspired synchronization reduces polling-related memory traffic.
Where Pith is reading between the lines
- The same profile-driven method could be adapted to study emerging interconnects such as optical or chiplet-based links.
- Results from Eidola runs on synthetic large-scale topologies could inform early sizing decisions for next-generation AI clusters.
- Integration with other gem5 GPU models might allow joint study of compute-communication overlap effects.
Load-bearing premise
Annotated timing profiles extracted from real applications are sufficient to drive cycle-level accurate emulation of peer-to-peer GPU writes without needing full GPU state.
What would settle it
Compare Eidola's predicted communication volumes and synchronization latencies against measurements taken on real multi-GPU hardware running the same fused-kernel workloads.
Figures






read the original abstract
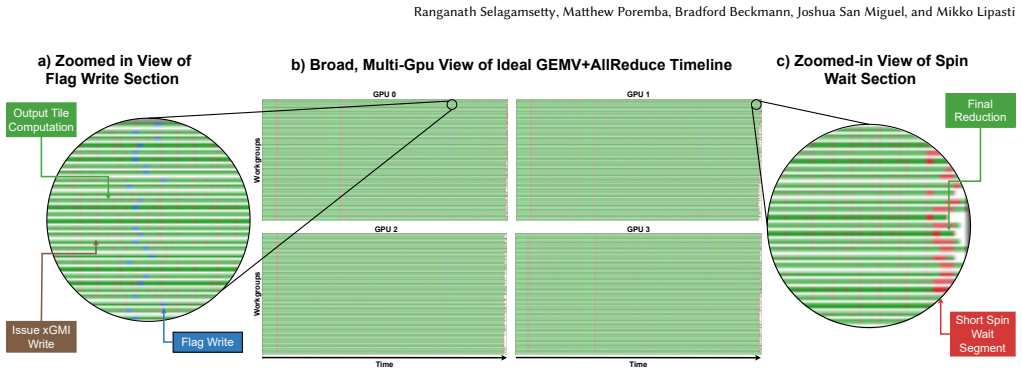
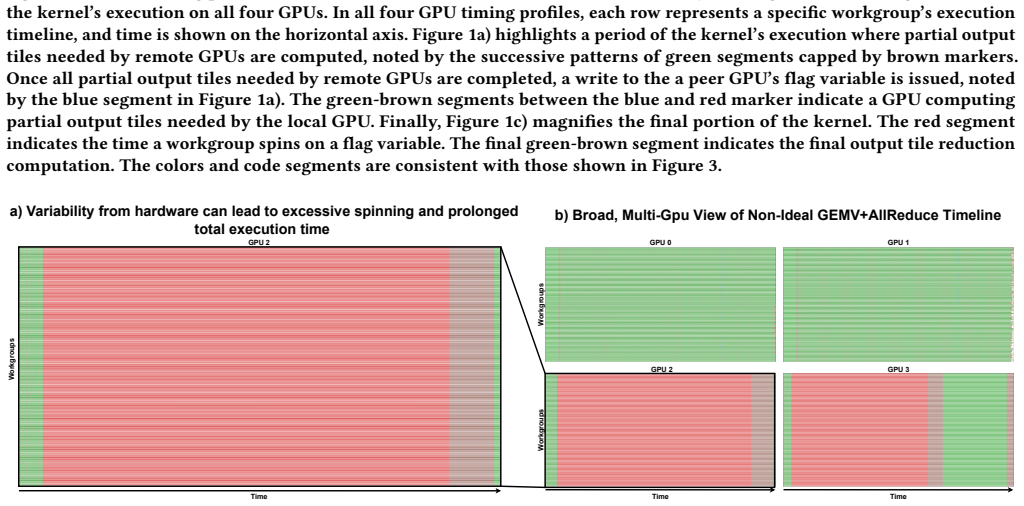
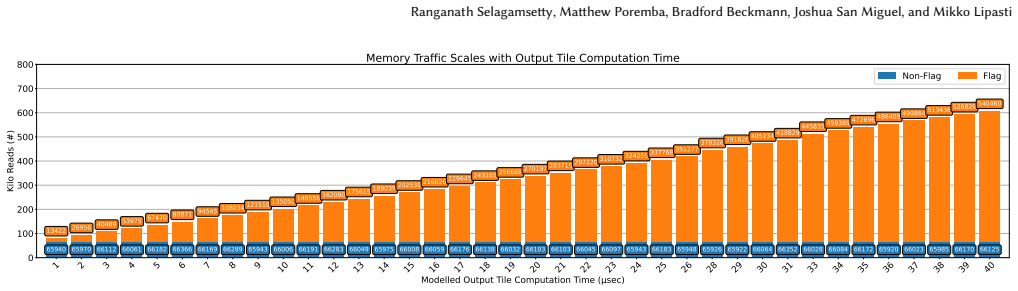
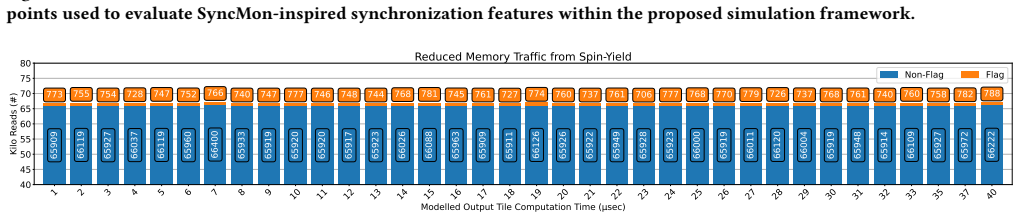
As distributed AI workloads grow in scale, multi-GPU systems have become essential for training large models. Although techniques like kernel fusion and overlapping communication with computation help reduce delays, they also introduce irregular and transient traffic patterns that are difficult to model using existing tools. These techniques rely heavily on fine-grained synchronization and peer-to-peer communication, which place significant pressure on interconnect bandwidth and latency. In this work, we introduce Eidola, a scalable extension to the gem5 simulation framework that enables detailed modeling of inter-GPU communication traffic. The extension is scalable as our GPU model serves as a succinct eidolon, emulating the minimal characteristics needed for traffic modeling. Eidola uses annotated timing profiles from real applications to emulate peer-to-peer GPU writes with cycle-level precision. This allows researchers to simulate and analyze synchronization behavior across large multi-GPU configurations. The simulator supports configurable per-GPU traffic patterns and enables isolated performance analysis under different communication scenarios. We demonstrate Eidola's effectiveness by reproducing variability in fused kernel execution and by implementing a SyncMon-inspired synchronization mechanism, confirming reductions in polling-related memory traffic. Our results show that Eidola provides a flexible and scalable platform for studying inter-GPU communication and supports architectural exploration in modern distributed GPU systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Eidola, a scalable extension to the gem5 framework for modeling inter-GPU communication traffic in distributed AI workloads. It employs a minimal 'eidolon' GPU model driven by annotated timing profiles extracted from real applications to emulate peer-to-peer GPU writes at cycle-level precision. The work claims to reproduce variability in fused-kernel execution, implement a SyncMon-inspired synchronization mechanism that reduces polling-related memory traffic, and provide a flexible platform for studying communication patterns and architectural exploration across large multi-GPU configurations.
Significance. If the reproduction claims and modeling assumptions hold with supporting data, Eidola could offer a practical tool for analyzing irregular traffic from kernel fusion and fine-grained synchronization in modern multi-GPU systems, filling a gap left by existing simulators. However, the absence of any quantitative validation, error metrics, or baselines makes it difficult to evaluate whether the approach delivers accurate or generalizable results beyond the profiled runs.
major comments (2)
- [Abstract] Abstract: the claims of reproducing fused-kernel variability and confirming polling-traffic reductions via SyncMon-style synchronization are asserted without any quantitative validation data, error metrics, comparison baselines, or statistical measures; this directly undermines assessment of the central accuracy and effectiveness claims.
- [Abstract] Modeling approach (described in abstract): the core assumption that annotated timing profiles suffice to drive cycle-level accurate P2P emulation across arbitrary multi-GPU configurations without modeling internal GPU state (caches, memory consistency, warp scheduling) is load-bearing for the scalability and generalization claims, yet no test or evidence is supplied to rule out state-dependent deviations that would produce incorrect traffic and latency results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and modeling assumptions. We agree that the presentation of claims would be strengthened by explicit quantitative support and additional evidence for the core modeling choices. We will revise the manuscript to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of reproducing fused-kernel variability and confirming polling-traffic reductions via SyncMon-style synchronization are asserted without any quantitative validation data, error metrics, comparison baselines, or statistical measures; this directly undermines assessment of the central accuracy and effectiveness claims.
Authors: We acknowledge that the abstract summarizes the contributions without embedding specific quantitative metrics. The evaluation section of the manuscript presents the supporting results on variability reproduction and traffic reduction, but we agree this should be reflected more directly in the abstract. We will revise the abstract to include key quantitative highlights, such as measured variability reproduction accuracy and polling traffic reduction percentages with comparison to baseline synchronization. revision: yes
-
Referee: [Abstract] Modeling approach (described in abstract): the core assumption that annotated timing profiles suffice to drive cycle-level accurate P2P emulation across arbitrary multi-GPU configurations without modeling internal GPU state (caches, memory consistency, warp scheduling) is load-bearing for the scalability and generalization claims, yet no test or evidence is supplied to rule out state-dependent deviations that would produce incorrect traffic and latency results.
Authors: The eidolon model is intentionally minimal and driven by real-application timing profiles to focus computational effort on inter-GPU traffic while preserving cycle-level P2P write timing. This design trades full internal GPU state for scalability. We recognize that explicit validation of the assumption is required. In the revised manuscript we will add a validation subsection that compares Eidola-generated traffic and latency against hardware measurements and/or full GPU simulations on representative configurations to quantify any state-dependent deviations. revision: yes
Circularity Check
No circularity: simulator tool description with no derived predictions or self-referential equations
full rationale
The paper introduces Eidola as a gem5 extension that uses externally extracted annotated timing profiles to drive a minimal eidolon GPU model for P2P traffic emulation. No equations, fitted parameters, or predictions are claimed; the contribution is the described platform and its use in reproducing observed variability and testing a SyncMon-inspired mechanism. No self-citation chains, ansatzes, or renamings appear. The modeling assumptions (profiles suffice without full GPU state) are explicit but constitute an engineering choice, not a reduction of outputs to inputs by construction. This matches the default non-circular case for tool-building papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieved November 6, 2025 from https://pytorch.org/blog/introducing-pytorch- profiler-the-new-and-improved-performance-tool/
2021.Introducing PyTorch Profiler – the new and improved performance tool. Retrieved November 6, 2025 from https://pytorch.org/blog/introducing-pytorch- profiler-the-new-and-improved-performance-tool/
2021
-
[2]
Retrieved November 6, 2025 from https://extremecomputingtraining.anl.gov/wp-content/ uploads/sites/96/2022/11/ATPESC-2022-Track-6-Talk-4-Tandon-AMD.pdf
2022.ROC-profiler and debugger: An Overview of AMD ROCmTM Tools. Retrieved November 6, 2025 from https://extremecomputingtraining.anl.gov/wp-content/ uploads/sites/96/2022/11/ATPESC-2022-Track-6-Talk-4-Tandon-AMD.pdf
2022
-
[3]
Retrieved November 6, 2025 from https://docs.nvidia.com/https:/docs.nvidia.com/dgx-superpod-reference- architecture-dgx-h100.pdf
2023.NVIDIA DGX SuperPOD: Next Generation Scalable Infrastructure for AI Leadership, Reference Architecture. Retrieved November 6, 2025 from https://docs.nvidia.com/https:/docs.nvidia.com/dgx-superpod-reference- architecture-dgx-h100.pdf
2023
-
[4]
Retrieved November 6, 2025 from https://www.amd.com/content/dam/amd/en/documents/ instinct-tech-docs/other/instinct-mi300-series-cluster-reference-guide.pdf
2025.AMD Instinct™MI300 Series Cluster Reference Architecture Guide. Retrieved November 6, 2025 from https://www.amd.com/content/dam/amd/en/documents/ instinct-tech-docs/other/instinct-mi300-series-cluster-reference-guide.pdf
2025
-
[5]
Retrieved November 6, 2025 from https://developer
2025.NVIDIA Nsight Systems. Retrieved November 6, 2025 from https://developer. nvidia.com/nsight-systems
2025
-
[6]
Jennifer M. Anderson, Lance M. Berc, Jeffrey Dean, Sanjay Ghemawat, Monika R. Henzinger, Shun-Tak A. Leung, Richard L. Sites, Mark T. Vandevoorde, Carl A. Waldspurger, and William E. Weihl. 1997. Continuous profiling: where have all the cycles gone?ACM Trans. Comput. Syst.15, 4 (Nov. 1997), 357–390. https: //doi.org/10.1145/265924.265925
-
[7]
Mario Badr, Carlo Delconte, Isak Edo, Radhika Jagtap, Matteo Andreozzi, and Natalie Enright Jerger. 2020. Mocktails: Capturing the Memory Behaviour of Proprietary Mobile Architectures. In2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). 460–472. https://doi.org/10.1109/ ISCA45697.2020.00046
arXiv 2020
-
[8]
Mario Badr and Natalie Enright Jerger. 2014. SynFull: Synthetic traffic models capturing cache coherent behaviour. In2014 ACM/IEEE 41st International Sympo- sium on Computer Architecture (ISCA). 109–120. https://doi.org/10.1109/ISCA. 2014.6853236
-
[9]
Ali Bakhoda, George L. Yuan, Wilson W. L. Fung, Henry Wong, and Tor M. Aamodt. 2009. Analyzing CUDA workloads using a detailed GPU simulator. In2009 IEEE International Symposium on Performance Analysis of Systems and Software. 163–174. https://doi.org/10.1109/ISPASS.2009.4919648
-
[10]
Reinhardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R
Nathan Binkert, Bradford Beckmann, Gabriel Black, Steven K. Reinhardt, Ali Saidi, Arkaprava Basu, Joel Hestness, Derek R. Hower, Tushar Krishna, Somayeh Sardashti, Rathijit Sen, Korey Sewell, Muhammad Shoaib, Nilay Vaish, Mark D. Hill, and David A. Wood. 2011. The gem5 simulator.SIGARCH Comput. Archit. News39, 2 (Aug. 2011), 1–7. https://doi.org/10.1145/2...
-
[11]
Long Chen, Oreste Villa, Sriram Krishnamoorthy, and Guang R. Gao. 2010. Dynamic load balancing on single- and multi-GPU systems. In2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS). 1–12. https://doi.org/10.1109/IPDPS.2010.5470413
-
[12]
Tianshi Chen, Zidong Du, Ninghui Sun, Jia Wang, Chengyong Wu, Yunji Chen, and Olivier Temam. 2014. DianNao: a small-footprint high-throughput accel- erator for ubiquitous machine-learning. InProceedings of the 19th International Conference on Architectural Support for Programming Languages and Operating Systems(Salt Lake City, Utah, USA)(ASPLOS ’14). Asso...
-
[13]
Derek Christ, Lukas Steiner, Matthias Jung, and Norbert Wehn. 2024. PIMSys: A Virtual Prototype for Processing in Memory. InProceedings of the Interna- tional Symposium on Memory Systems (MEMSYS ’24). Association for Computing Machinery, New York, NY, USA, 26–33. https://doi.org/10.1145/3695794.3695797
-
[14]
Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V
Jeffrey Dean, Greg S. Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao, Marc’Aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, and Andrew Y. Ng. 2012. Large scale distributed deep networks. InProceedings of the 26th International Conference on Neural Information Processing Systems - Volume 1(Lake Tahoe, Nevada)(NIPS’12). Curran ...
2012
-
[15]
Advanced Micro Devices. [n. d.]. ROCm OpenSHMEM (rocSHMEM). Accessed November 10, 2025
2025
-
[16]
Alexandru Duţu, Matthew D. Sinclair, Bradford M. Beckmann, David A. Wood, and Marcus Chow. 2020. Independent Forward Progress of Work-groups. In 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). 1022–1035. https://doi.org/10.1109/ISCA45697.2020.00087
-
[17]
L. Eeckhout, K. de Bosschere, and H. Neefs. 2000. Performance analysis through synthetic trace generation. In2000 IEEE International Symposium on Performance Analysis of Systems and Software. ISPASS (Cat. No.00EX422). 1–6. https://doi.org/ 10.1109/ISPASS.2000.842273
-
[18]
Cebrian, Ricardo Fernández-Pascual, and Manuel E
Joaquín Ferrer, Juan M. Cebrian, Ricardo Fernández-Pascual, and Manuel E. Acacio. 2025. Precise characterization of coherence activity in multicores using gem5. InThe Journal of Supercomputing, Vol. 81. https://doi.org/10.1007/s11227- 025-07434-0
-
[19]
Arnaud Fiorini and Michel R. Dagenais. 2022. Visualization of profiling and tracing in CPU-GPU programs.Concurrency and Computation: Prac- tice and Experience34, 23 (2022), e7188. https://doi.org/10.1002/cpe.7188 arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/cpe.7188
-
[20]
Hanchen Jin, Zichao Yue, Zhongyuan Zhao, Yixiao Du, Chenhui Deng, Nitish Srivastava, and Zhiru Zhang. 2025. Vesper: A Versatile Sparse Linear Alge- bra Accelerator With Configurable Compute Patterns.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems44, 5 (2025), 1731–1744. https://doi.org/10.1109/TCAD.2024.3496882
-
[21]
Matthew Leinhauser, Jeffrey Young, Sergei Bastrakov, Rene Widera, Ronnie Chatterjee, and Sunita Chandrasekaran. 2021.Performance Analysis of PIConGPU: Particle-in-Cell on GPUs using NVIDIA’s NSight Systems and NSight Compute. Technical Report. Oak Ridge National Laboratory (ORNL), Oak Ridge, TN (United States). https://doi.org/10.2172/1761619
-
[22]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, and Soumith Chintala
-
[23]
arXiv:2006.15704 [cs.DC] https://arxiv.org/abs/2006.15704
PyTorch Distributed: Experiences on Accelerating Data Parallel Training. arXiv:2006.15704 [cs.DC] https://arxiv.org/abs/2006.15704
Pith/arXiv arXiv 2006
-
[24]
Wenhai Lin, Yiquan Chen, Jiexiong Xu, Zhen Jin, Peiyu Liu, Shishun Cai, Yuzhong Zhang, Jingchang Qin, Yiquan Lin, and Wenzhi Chen. 2024. CINDA: Don’t Ignore Instructions When Cloning Memory Access Behavior. In2024 IEEE 24th International Symposium on Cluster, Cloud and Internet Computing (CCGrid). 507–513. https://doi.org/10.1109/CCGrid59990.2024.00063
-
[25]
Qunyou Liu, Marina Zapater, and David Atienza. 2025. Gem5-AcceSys: Enabling System-Level Exploration of Standard Interconnects for Novel Accelerators. In Proceedings of the 62nd Annual ACM/IEEE Design Automation Conference(San Francisco, California, United States)(DAC ’25). IEEE Press, Article 444, 7 pages. https://doi.org/10.1109/DAC63849.2025.11133394
-
[26]
Denny, and Johannes Doerfert
Ethan Luis McDonough, Joel E. Denny, and Johannes Doerfert. 2026. Profile Generation for GPU Targets. InOpenMP: Balancing Productivity and Performance Portability, Yonghong Yan, Michael Klemm, Bronis R. de Supinski, Erik Saule, Jannis Klinkenberg, and Swaroop Pophale (Eds.). Springer Nature Switzerland, Cham, 99–113
2026
-
[27]
2025.WHITEPAPER: AT-SCALE AI TRAINING ON AMD INSTINCT™MI350/MI300X SERIES GPUS
Aditya Nandakumar, Shobha Vissapragada, Ashish Panday, Wen Xie, Matt Ouel- lette, Zhenyu Gu, and Ram Sivaramakrishnan. 2025.WHITEPAPER: AT-SCALE AI TRAINING ON AMD INSTINCT™MI350/MI300X SERIES GPUS. Technical Report. Advanced Micro Devices, Inc
2025
-
[28]
Reena Panda, Xinnian Zheng, Jiajun Wang, Andreas Gerstlauer, and Lizy K. John
-
[29]
In Proceedings of the 54th Annual Design Automation Conference 2017(Austin, TX, USA)(DAC ’17)
Statistical Pattern Based Modeling of GPU Memory Access Streams. In Proceedings of the 54th Annual Design Automation Conference 2017(Austin, TX, USA)(DAC ’17). Association for Computing Machinery, New York, NY, USA, Article 81, 6 pages. https://doi.org/10.1145/3061639.3062320
-
[30]
James, Shirshendu Das, Palash Das, and Daleesha M Viswanathan
Josna Philomina, Rekha K. James, Shirshendu Das, Palash Das, and Daleesha M Viswanathan. 2026. NeSTAR: Hardware Trojans and its mitigation strategy in NoC routers.Integration107 (2026), 102603. https://doi.org/10.1016/j.vlsi.2025. 102603
-
[31]
Jason Power, Joel Hestness, Marc S. Orr, Mark D. Hill, and David A. Wood. 2015. gem5-gpu: A Heterogeneous CPU-GPU Simulator.IEEE Computer Architecture Letters14, 1 (2015), 34–36. https://doi.org/10.1109/LCA.2014.2299539
-
[32]
Kishore Punniyamurthy, Khaled Hamidouche, and Bradford M. Beckmann. 2024. Optimizing Distributed ML Communication with Fused Computation-Collective Operations. InSC24: International Conference for High Performance Computing, Networking, Storage and Analysis(Atlanta, GA, USA). IEEE Press, 1–17. https: //doi.org/10.1109/SC41406.2024.00094
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41406.2024.00094 2024
-
[33]
Sinclair
Vishnu Ramadas, Daniel Kouchekinia, Ndubuisi Osuji, and Matthew D. Sinclair
-
[34]
Closing the Gap: Improving the Accuracy of gem5’s GPU Models. (2023). https://par.nsf.gov/biblio/10468163
arXiv 2023
-
[35]
Vishnu Ramadas, Daniel Kouchekinia, and Matthew D Sinclair. 2024. Further Closing the GAP: Improving the Accuracy of gem5’s GPU Models. (2024). https: //par.nsf.gov/biblio/10542852
arXiv 2024
-
[36]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deep- Speed: System Optimizations Enable Training Deep Learning Models with Over 12 Eidola: Modeling Multi-GPU Network Communication Traffic in Distributed AI Workloads 100 Billion Parameters. InProceedings of the 26th ACM SIGKDD International Con- ference on Knowledge Discovery & Dat...
-
[37]
Achref Rebai, Mubarak Adetunji Ojewale, Anees Ullah, Marco Canini, and Suhaib A. Fahmy. 2024. SqueezeNIC: Low-Latency In-NIC Compression for Distributed Deep Learning. InProceedings of the 2024 SIGCOMM Workshop on Networks for AI Computing(Sydney, NSW, Australia)(NAIC ’24). Association for Computing Machinery, New York, NY, USA, 61–68. https://doi.org/10....
arXiv 2024
-
[38]
Gang Ren, Eric Tune, Tipp Moseley, Yixin Shi, Silvius Rus, and Robert Hundt
-
[39]
https://doi.org/10.1109/MM.2010.68
Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers.IEEE Micro30, 4 (2010), 65–79. https://doi.org/10.1109/MM.2010.68
- [40]
-
[41]
Gabin Schieffer, Ruimin Shi, Stefano Markidis, Andreas Herten, Jennifer Faj, and Ivy Peng. 2024. Understanding Data Movement in AMD Multi-GPU Systems with Infinity Fabric. InSC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. 567–576. https: //doi.org/10.1109/SCW63240.2024.00079
-
[42]
A. N. Semakin. 2021. Simulation of a multi-core computer system in the gem5 simulator.AIP Conference Proceedings2318, 1 (02 2021), 090006. https://doi.org/ 10.1063/5.0035841
-
[43]
Alexander Sergeev and Mike Del Balso. 2018. Horovod: fast and easy distributed deep learning in TensorFlow. arXiv:1802.05799 [cs.LG] https://arxiv.org/abs/ 1802.05799
Pith/arXiv arXiv 2018
-
[44]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv:1909.08053 [cs.CL] https: //arxiv.org/abs/1909.08053
Pith/arXiv arXiv 2020
-
[45]
Wei Sun, Ang Li, Sander Stuijk, and Henk Corporaal. 2024. How Much Can We Gain From Tensor Kernel Fusion on GPUs?IEEE Access12 (2024), 126135–126144. https://doi.org/10.1109/ACCESS.2024.3411473
-
[46]
Yifan Sun, Trinayan Baruah, Saiful A. Mojumder, Shi Dong, Xiang Gong, Shane Treadway, Yuhui Bao, Spencer Hance, Carter McCardwell, Vincent Zhao, Har- rison Barclay, Amir Kavyan Ziabari, Zhongliang Chen, Rafael Ubal, José L. Abellán, John Kim, Ajay Joshi, and David Kaeli. 2019. MGPUSim: enabling multi-GPU performance modeling and optimization. InProceeding...
-
[47]
Zhuo Tang, Lifan Du, Xuedong Zhang, Li Yang, and Kenli Li. 2022. AEML: An Acceleration Engine for Multi-GPU Load-Balancing in Distributed Hetero- geneous Environment.IEEE Trans. Comput.71, 6 (2022), 1344–1357. https: //doi.org/10.1109/TC.2021.3084407
-
[48]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony H...
Pith/arXiv arXiv 2023
-
[49]
Rafael Ubal, Byunghyun Jang, Perhaad Mistry, Dana Schaa, and David Kaeli. 2012. Multi2Sim: a simulation framework for CPU-GPU computing. InProceedings of the 21st International Conference on Parallel Architectures and Compilation Tech- niques(Minneapolis, Minnesota, USA)(PACT ’12). Association for Computing Ma- chinery, New York, NY, USA, 335–344. https:/...
-
[50]
Guibin Wang, YiSong Lin, and Wei Yi. 2010. Kernel Fusion: An Effective Method for Better Power Efficiency on Multithreaded GPU. In2010 IEEE/ACM Int’l Con- ference on Green Computing and Communications & Int’l Conference on Cyber, Physical and Social Computing. 344–350. https://doi.org/10.1109/GreenCom- CPSCom.2010.102
-
[51]
Yipeng Wang, Ganesh Balakrishnan, and Yan Solihin. 2015. MeToo: Stochastic Modeling of Memory Traffic Timing Behavior. In2015 International Conference on Parallel Architecture and Compilation (PACT). 457–467. https://doi.org/10. 1109/PACT.2015.36
2015
-
[52]
Haicheng Wu, Gregory Diamos, Srihari Cadambi, and Sudhakar Yalamanchili
-
[53]
In2012 45th Annual IEEE/ACM International Symposium on Microarchitecture
Kernel Weaver: Automatically Fusing Database Primitives for Efficient GPU Computation. In2012 45th Annual IEEE/ACM International Symposium on Microarchitecture. 107–118. https://doi.org/10.1109/MICRO.2012.19
-
[54]
Kan Wu, Zejia Lin, Mengyue Xi, Zhongchun Zheng, Wenxuan Pan, Xianwei Zhang, and Yutong Lu. 2025. GoPTX: Fine-grained GPU Kernel Fusion by PTX- level Instruction Flow Weaving. In2025 62nd ACM/IEEE Design Automation Conference (DAC). 1–7. https://doi.org/10.1109/DAC63849.2025.11132627
-
[55]
Ehsan Yousefzadeh-Asl-Miandoab, Ties Robroek, and Pinar Tozun. 2023. Profiling and Monitoring Deep Learning Training Tasks. InProceedings of the 3rd Workshop on Machine Learning and Systems(Rome, Italy)(EuroMLSys ’23). Association for Computing Machinery, New York, NY, USA, 18–25. https://doi.org/10.1145/ 3578356.3592589
arXiv 2023
-
[56]
Yichao Yuan, Advait Iyer, Lin Ma, and Nishil Talati. 2024. Vortex: Overcoming Memory Capacity Limitations in GPU-Accelerated Large-Scale Data Analytics. Proc. VLDB Endow.18, 4 (12 2024), 1250–1263. https://doi.org/10.14778/3717755. 3717780 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.