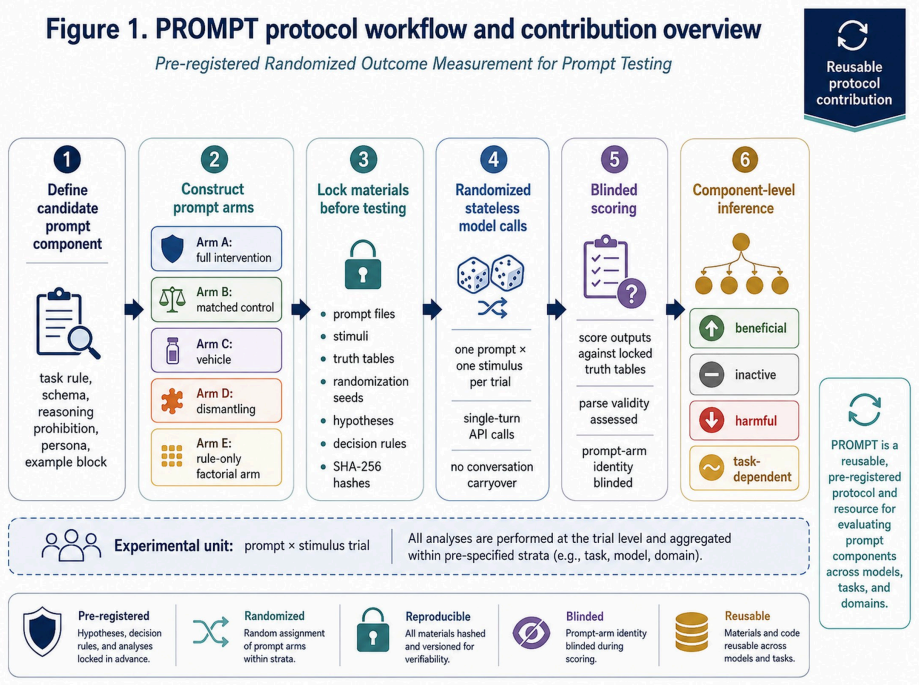
PROMPT: A Pre-registered Randomized Protocol for Component-Level Evaluation of Clinical AI Prompts
Pith reviewed 2026-06-26 09:45 UTC · model grok-4.3
The pith
PROMPT protocol isolates effects of single prompt components in clinical AI using randomized matched controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
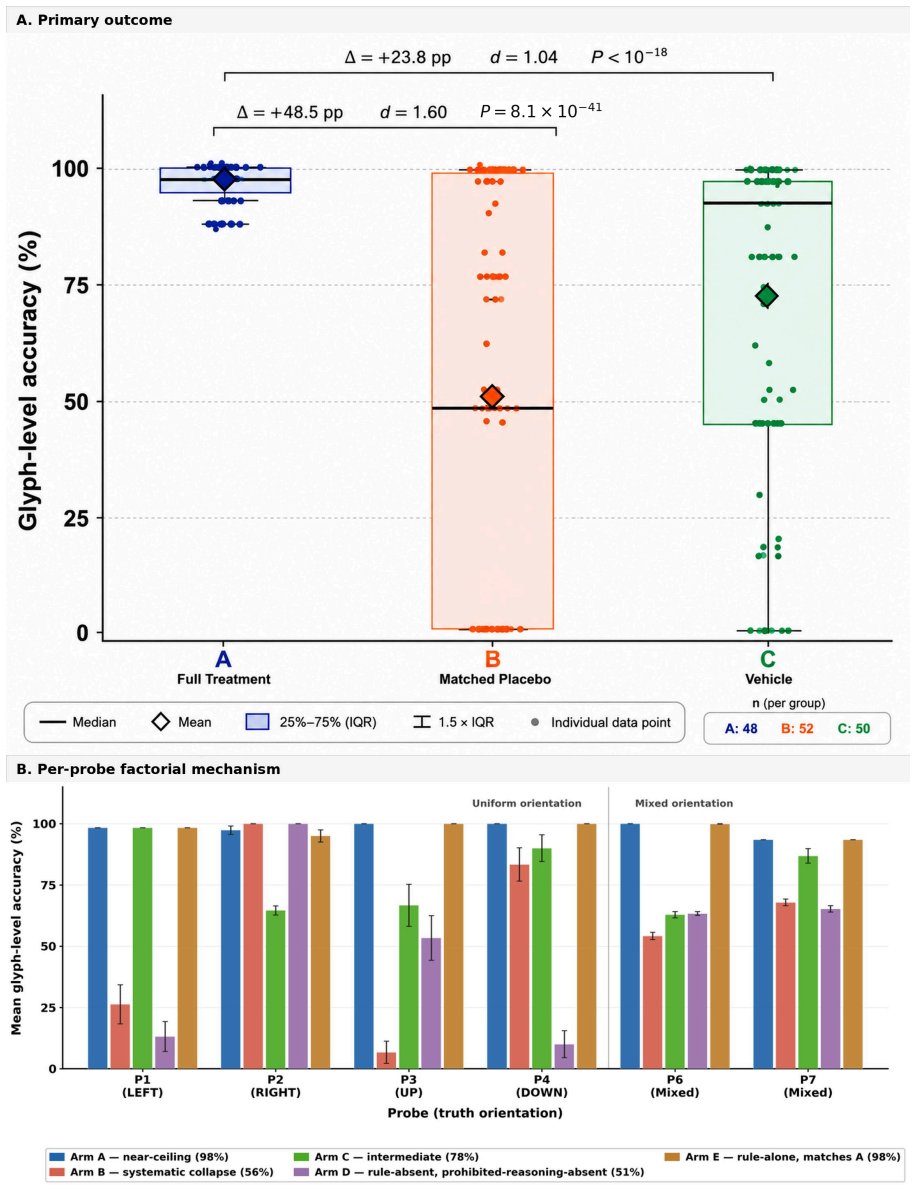
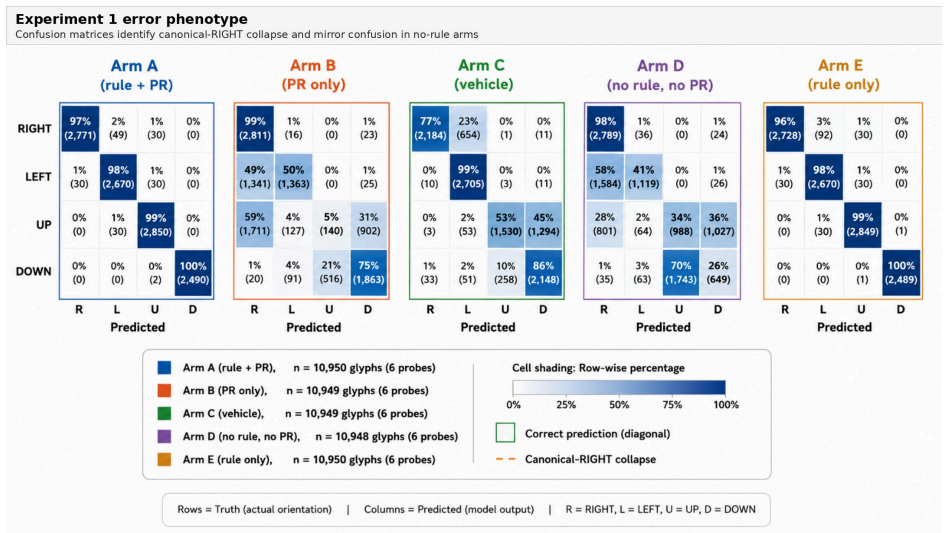
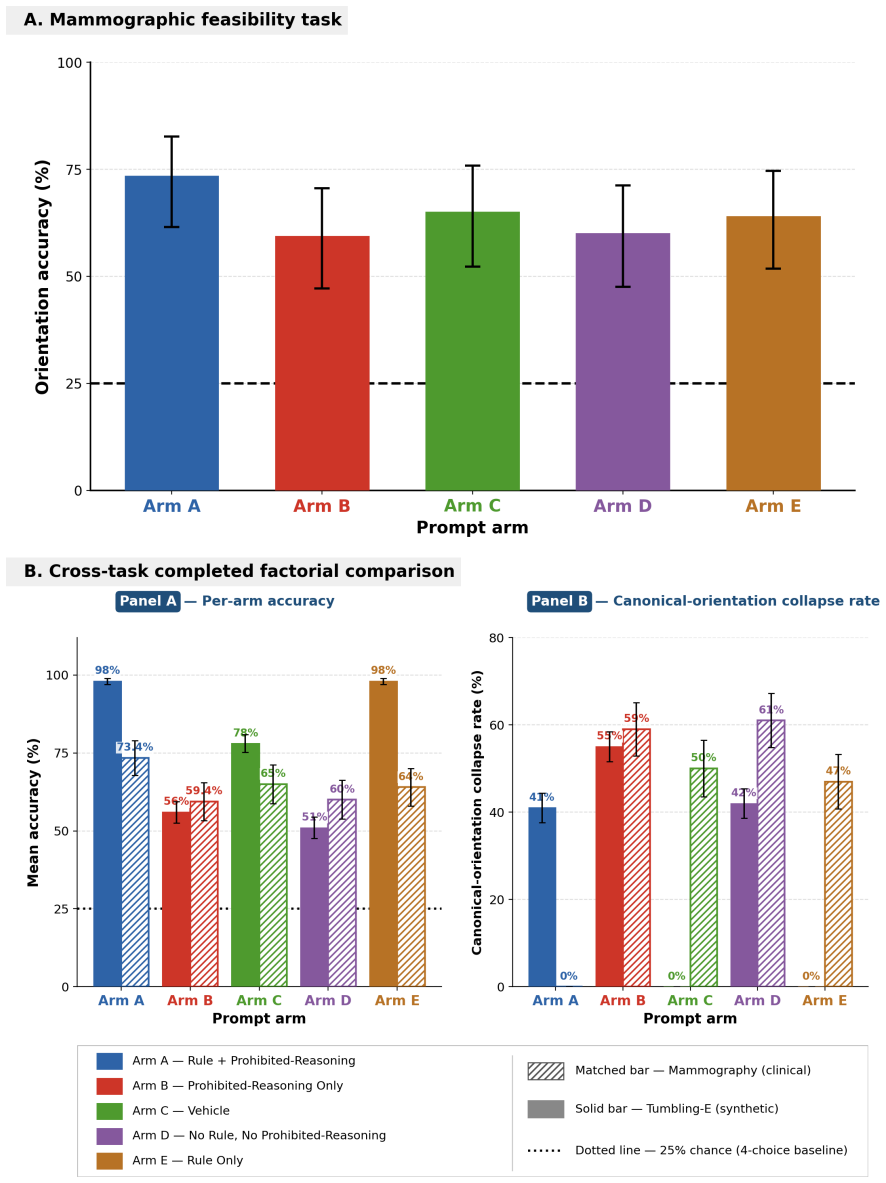
PROMPT applies pre-specification, randomization, matched controls, dismantling, and decision rules to evaluate prompt components separately. In the synthetic task the full prompt reached 98.6 percent accuracy while removal of the decoding rule dropped performance to 50.1 percent; a rule-only arm matched the full prompt, the prohibited-reasoning block showed no effect, and scaffolding without the rule underperformed the vehicle. The same error phenotype appeared on mammographic images, although the rule benefit was smaller and did not meet the pre-specified threshold.
What carries the argument
Matched controls that remove one active component while preserving framing, structure, and output format.
If this is right
- A decoding rule alone accounts for the full accuracy gain observed with the complete prompt.
- A prohibited-reasoning safety block produces no measurable benefit.
- Prompt scaffolding without the task-specific rule reduces performance relative to a minimal vehicle prompt.
- A canonical orientation error pattern appears consistently in arms lacking the rule.
- Component effects observed on synthetic tasks attenuate when transferred to real medical images.
Where Pith is reading between the lines
- The protocol could be adapted to test prompt-component interactions in multi-turn clinical dialogues.
- Regular use of component dismantling before deployment would surface model-specific priors that whole-prompt tests miss.
- Decision thresholds in the protocol may require recalibration when moving from synthetic to real clinical data distributions.
Load-bearing premise
Matched controls can remove a single component without introducing new confounds or changing the model's response in unaccounted ways.
What would settle it
A replication in which removing the decoding rule produces no accuracy drop while all other elements stay fixed would indicate the controls failed to isolate the component.
Figures
read the original abstract
BACKGROUND:Prompt engineering shapes medical AI outcomes, but prompt components are rarely tested as clinical interventions. We developed PROMPT (Pre-registered Randomized Outcome Measurement for Prompt Testing), a protocol using pre-specification, randomization, matched controls, dismantling, and decision rules.METHODS:Two pre-registered demonstrations used Claude Sonnet 4.6. Exp 1 used a synthetic tumbling-E orientation task: 630-trial main study, 480-trial dismantling study, and 1,050-trial 2x2 factorial extension. Exp 2 used the same arms on 16 label-masked CBIS-DDSM mammographic crops in four orientations: 256 confirmatory trials and a 64-trial Arm E extension. Matched controls removed the active component while preserving framing, structure, and output format.RESULTS:PROMPT identified beneficial, inactive, harmful, and task-dependent effects. In Exp 1, the full prompt achieved 98.6% orientation accuracy; removing the decoding rule reduced accuracy to 50.1% (difference, +48.5 pp; 95% CI, +43.2 to +53.7; P<0.001). A rule-only arm matched the full prompt (maximum difference, 2.3 pp), identifying the decoding rule as the sole measurable active component. A prohibited-reasoning block assumed to improve safety was inactive, an effect missed by whole-prompt comparison. Scaffolding without the task-specific rule underperformed the vehicle prompt, showing prompt structure alone was harmful. Exp 1 revealed a canonical-RIGHT error phenotype in no-rule arms, consistent with a RIGHT-orientation prior. In Exp 2, the phenotype recurred on mammographic images, but the rule's benefit was attenuated and did not meet the threshold (+14.1 pp; bootstrap 95% CI, -3.1 to +29.7; post-hoc mixed-model 95% CI, +3.5 to +24.6).CONCLUSION:PROMPT revealed component effects missed by whole-prompt evaluations, identifying safety vulnerabilities and performance failures before clinical AI deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the PROMPT protocol, a pre-registered randomized dismantling design with matched controls for component-level evaluation of clinical AI prompts. Two demonstration experiments on Claude Sonnet 4.6 are reported: Exp 1 (synthetic tumbling-E task, 630+480+1050 trials) identifies the decoding rule as the sole active component (98.6% to 50.1% accuracy) while a prohibited-reasoning block is inactive; Exp 2 (mammographic crops, 256+64 trials) shows attenuated and non-threshold effects with recurrence of a RIGHT-orientation error phenotype.
Significance. If the dismantling succeeds, the work supplies a reproducible, pre-registered framework for isolating prompt-component effects before clinical deployment, with explicit credit for randomization, pre-specification, and the ability to detect inactive safety blocks and harmful scaffolding that whole-prompt comparisons miss. This could materially improve prompt safety assessment in medical AI.
major comments (2)
- [Methods] Methods (dismantling and matched-controls description): The central claim that PROMPT isolates component effects (e.g., decoding rule as sole active component driving the +48.5 pp difference) depends on matched controls removing only the target element while preserving framing, structure, and output format. No side-by-side prompt texts, token-distribution checks, or sensitivity analyses are supplied to confirm absence of unaccounted confounds such as altered attention scope; this assumption is load-bearing for attribution in both experiments.
- [Results] Results (Exp 2 confirmatory analysis): The pre-specified threshold is not met (+14.1 pp, bootstrap CI -3.1 to +29.7), yet the post-hoc mixed-model CI (+3.5 to +24.6) is presented as supportive of task-dependence; the manuscript must clarify whether this analysis was pre-specified and how it affects the claim that PROMPT reveals effects missed by whole-prompt evaluation.
minor comments (2)
- [Abstract] Abstract: The 1,050-trial 2x2 factorial and 64-trial Arm E extensions would benefit from explicit per-arm sample sizes to allow immediate assessment of power.
- [Abstract] Abstract: The statement that the prohibited-reasoning block was 'assumed to improve safety' is used to label it a vulnerability, but the source or rationale for that assumption is not referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the importance of transparent control construction and pre-specification. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods] Methods (dismantling and matched-controls description): The central claim that PROMPT isolates component effects (e.g., decoding rule as sole active component driving the +48.5 pp difference) depends on matched controls removing only the target element while preserving framing, structure, and output format. No side-by-side prompt texts, token-distribution checks, or sensitivity analyses are supplied to confirm absence of unaccounted confounds such as altered attention scope; this assumption is load-bearing for attribution in both experiments.
Authors: We agree that explicit verification of matched-control fidelity is necessary to support component-level attribution. The Methods section describes the dismantling procedure and states that matched controls preserved framing, structure, and output format, but we did not provide side-by-side prompt texts or quantitative checks. In the revision we will add (i) the complete prompt text for every arm in a supplementary table, (ii) token-count and structural-element comparisons confirming that only the target component differed, and (iii) a brief statement on why attention-scope confounds are unlikely given the fixed output format. These additions will be presented as post-hoc transparency measures that do not alter the pre-registered analysis plan. revision: yes
-
Referee: [Results] Results (Exp 2 confirmatory analysis): The pre-specified threshold is not met (+14.1 pp, bootstrap CI -3.1 to +29.7), yet the post-hoc mixed-model CI (+3.5 to +24.6) is presented as supportive of task-dependence; the manuscript must clarify whether this analysis was pre-specified and how it affects the claim that PROMPT reveals effects missed by whole-prompt evaluation.
Authors: The bootstrap comparison against the pre-registered threshold was the confirmatory analysis and correctly showed that the threshold was not met. The mixed-model analysis is labeled 'post-hoc' in the current text and was not pre-specified. We will revise the Results and Discussion sections to (i) state explicitly that the mixed-model result is exploratory, (ii) present it only as suggestive of attenuation relative to Exp 1, and (iii) adjust the language around task-dependence so that the primary claim rests on the pre-registered threshold test while noting that the point estimate is consistent with a smaller effect in the mammogram task. This clarification will not change the overall conclusion that PROMPT can surface task-dependent patterns missed by whole-prompt comparisons, but it will make the evidential weight of each analysis transparent. revision: yes
Circularity Check
No circularity: empirical protocol with independent experimental measurements
full rationale
The paper describes a pre-registered randomized protocol (PROMPT) for component-level prompt evaluation using dismantling studies, matched controls, and direct accuracy measurements across experimental arms. No mathematical derivations, parameter fits presented as predictions, or self-citation chains appear in the provided text. Claims rest on observed performance differences (e.g., 98.6% vs 50.1% accuracy) from randomized trials rather than any quantity defined in terms of itself or reduced by construction to inputs. The work is self-contained against external benchmarks of prompt performance.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of randomized controlled trials hold, including no interference between trials and that matched controls isolate the target component effect.
invented entities (1)
-
PROMPT protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Large language models encode clinical knowledge
Singhal K, Azizi S, Tu T, et al. Large language models encode clinical knowledge. Nature. 2023;620(7972):172-180
2023
-
[2]
Large language models in medicine
Thirunavukarasu AJ, Ting DSJ, Elangovan K, et al. Large language models in medicine. Nat Med. 2023;29(8):1930-1940
2023
-
[3]
Chain-of-thought prompting elicits reasoning in large language models
Wei J, Wang X, Schuurmans D, et al. Chain-of-thought prompting elicits reasoning in large language models. Adv Neural Inf Process Syst. 2022;35:24824-24837
2022
-
[4]
Calibrate before use: improving few-shot performance of language models
Zhao Z, Wallace E, Feng S, Klein D, Singh S. Calibrate before use: improving few-shot performance of language models. Proc Mach Learn Res. 2021;139:12697-12706
2021
-
[5]
Visual prompt engineering for medical vision language models in radiology
Denner S, Bujotzek M, Bounias D, et al. Visual prompt engineering for medical vision language models in radiology. arXiv preprint arXiv:2408.15802
-
[6]
On large visual language models for medical imaging analysis: an empirical study
Van M-H, Verma P, Wu X. On large visual language models for medical imaging analysis: an empirical study. arXiv preprint arXiv:2402.14162
-
[7]
State of what art? A call for multi-prompt LLM evaluation
Mizrahi M, Kaplan G, Malkin D, Dror R, Shahaf D, Stanovsky G. State of what art? A call for multi-prompt LLM evaluation. Trans Assoc Comput Linguist. 2024;12:933-949
2024
-
[8]
Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: the CONSORT-AI extension
Liu X, Cruz Rivera S, Moher D, et al. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: the CONSORT-AI extension. Nat Med. 2020;26(9):1364-1374
2020
-
[9]
Guidelines for clinical trial protocols for interventions involving artificial intelligence: the SPIRIT-AI extension
Cruz Rivera S, Liu X, Chan AW, et al. Guidelines for clinical trial protocols for interventions involving artificial intelligence: the SPIRIT-AI extension. Nat Med. 2020;26(9):1351-1363
2020
-
[10]
The TRIPOD-LLM reporting guideline for studies using large language models
Gallifant J, Afshar M, Ameen S, et al. The TRIPOD-LLM reporting guideline for studies using large language models. Nat Med. 2025;31(1):60-69
2025
-
[11]
Foundation models for generalist medical artificial intelligence
Moor M, Banerjee O, Abad ZSH, et al. Foundation models for generalist medical artificial intelligence. Nature. 2023;616(7956):259-265
2023
-
[12]
A multimodal generative AI copilot for human pathology
Lu MY, Chen B, Williamson DFK, et al. A multimodal generative AI copilot for human pathology. Nat Med. 2024;30(4):1083-1092
2024
-
[13]
A curated mammography data set for use in computer-aided detection and diagnosis research
Lee RS, Gimenez F, Hoogi A, et al. A curated mammography data set for use in computer-aided detection and diagnosis research. Sci Data. 2017;4:170177
2017
-
[14]
The Cancer Imaging Archive (TCIA): maintaining and operating a public information repository
Clark K, Vendt B, Smith K, et al. The Cancer Imaging Archive (TCIA): maintaining and operating a public information repository. J Digit Imaging. 2013;26(6):1045-1057
2013
-
[15]
The preregistration revolution
Nosek BA, Ebersole CR, DeHaven AC, Mellor DT. The preregistration revolution. Proc Natl Acad Sci USA. 2018;115(11):2600-2606
2018
-
[16]
Reporting guideline for the early-stage clinical evaluation of decision support systems driven by artificial intelligence: DECIDE-AI
Vasey B, Nagendran M, Campbell B, et al. Reporting guideline for the early-stage clinical evaluation of decision support systems driven by artificial intelligence: DECIDE-AI. Nat Med. 2022;28(5):924-933
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.