Cache-Aware I/O Cost Modeling for Disk-Based Learned Indexes
Pith reviewed 2026-06-26 11:22 UTC · model grok-4.3
The pith
CAM is the first cache-aware I/O cost model for disk-based learned indexes that accounts for practical cache eviction policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
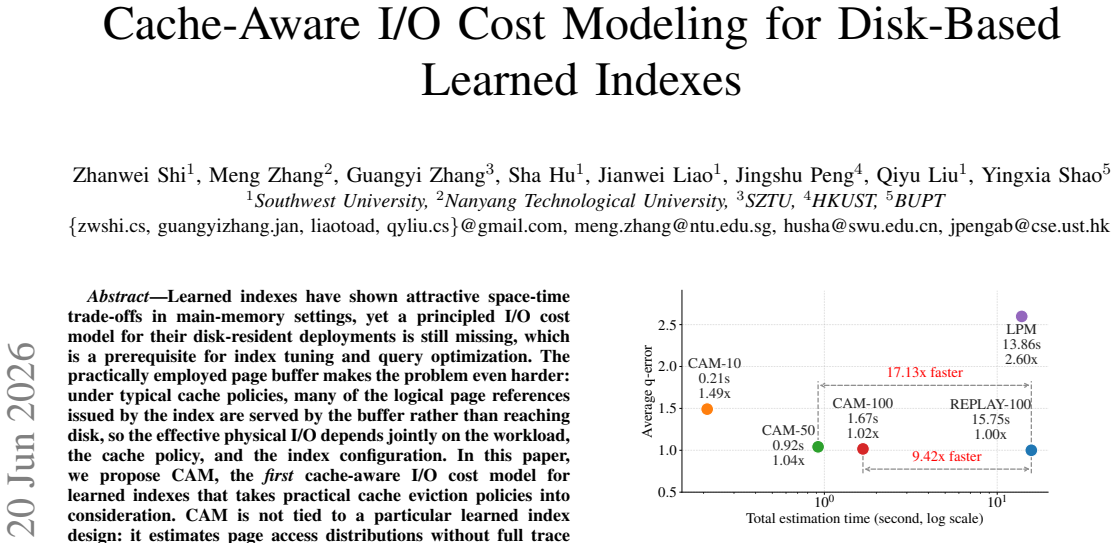
CAM estimates page access distributions without full trace replay for mainstream learned index designs, combines them with I/O cost models to estimate effective physical I/Os, and enables principled knob tuning by explicitly modeling the trade-off between index footprint and buffer capacity. When instantiated for disk-based PGM-index and RMI it produces accurate I/O estimates and yields throughput improvements of 1.17× and 1.66× respectively; the same modeling principle extends to learned-index-based joins through a hybrid strategy that adaptively chooses point or range probes.
What carries the argument
CAM, a cache-aware I/O cost model that estimates page access distributions from index structure and workload statistics for mainstream learned index designs then folds in cache eviction policies.
If this is right
- CAM-guided tuning improves PGM throughput by 1.17× over multicriteria PGM tuning.
- CAM-guided tuning improves RMI throughput by 1.66× over CDFShop with I/O-related considerations.
- A hybrid probe strategy for learned-index-based joins improves end-to-end performance by up to 8.8× over disk-based index nested-loop join.
- The model applies across different learned index designs without being tied to one particular structure.
Where Pith is reading between the lines
- The same distribution-estimation approach could be reused for other index families if their page access patterns admit analytical descriptions.
- Query optimizers could use CAM-style physical costs when choosing between learned indexes and conventional structures.
- Buffer capacity should be treated as a first-class tuning parameter alongside index parameters.
Load-bearing premise
Page access distributions for learned indexes can be estimated accurately from the index structure and workload statistics alone without needing full trace replay.
What would settle it
Running actual query executions on disk with a real buffer manager and comparing the measured physical I/O counts against CAM's predictions; substantial divergence would refute the model's accuracy.
Figures





read the original abstract
Learned indexes have shown attractive space-time trade-offs in main-memory settings, yet a principled I/O cost model for their disk-resident deployments is still missing, which is a prerequisite for index tuning and query optimization. The practically employed page buffer makes the problem even harder: under typical cache policies, many of the logical page references issued by the index are served by the buffer rather than reaching disk, so the effective physical I/O depends jointly on the workload, the cache policy, and the index configuration. In this paper, we propose CAM, the \textit{first} cache-aware I/O cost model for learned indexes that takes practical cache eviction policies into consideration. CAM is not tied to a particular learned index design: it estimates page access distributions without full trace replay for mainstream learned index designs, and then combines them with I/O cost models to estimate effective physical I/Os. This formulation enables principled knob tuning by explicitly modeling the trade-off between index footprint and buffer capacity. We instantiate CAM for disk-based PGM-index and RMI, and further apply the same modeling principle to learned-index-based joins through a hybrid strategy that adaptively chooses point or range probes based on local key density. Extensive experiments on real benchmarks show that CAM provides \textit{accurate and efficient} I/O estimation across diverse workloads: CAM-guided tuning improves PGM throughput by \textbf{1.17$\times$} over multicriteria PGM tuning and improves RMI throughput by \textbf{1.66$\times$} over CDFShop with I/O-related considerations. For learned-index-based joins, our hybrid strategy improves end-to-end performance by up to \textbf{8.8$\times$} over disk-based index nested-loop join.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAM, the first cache-aware I/O cost model for disk-based learned indexes. It estimates page access distributions for mainstream designs (PGM-index, RMI) from index structure and workload statistics without full trace replay, incorporates practical cache eviction policies, and models the footprint-vs-buffer-capacity trade-off to enable principled tuning. Instantiations are provided for PGM, RMI, and learned-index joins (via adaptive point/range probes). Experiments on real benchmarks claim accurate I/O estimation and throughput gains of 1.17× (PGM over multicriteria tuning), 1.66× (RMI over CDFShop), and up to 8.8× (joins over disk-based index nested-loop join).
Significance. If the page-access-distribution estimates hold, CAM would fill a notable gap by providing a practical, non-replay-based I/O model for disk-resident learned indexes that accounts for buffer-cache effects. This could support better index configuration and query optimization in database systems. The hybrid join strategy and explicit modeling of cache policies are additional strengths. The work's value hinges on whether the estimation procedure generalizes beyond the evaluated workloads without introducing circularity or post-hoc fitting.
major comments (2)
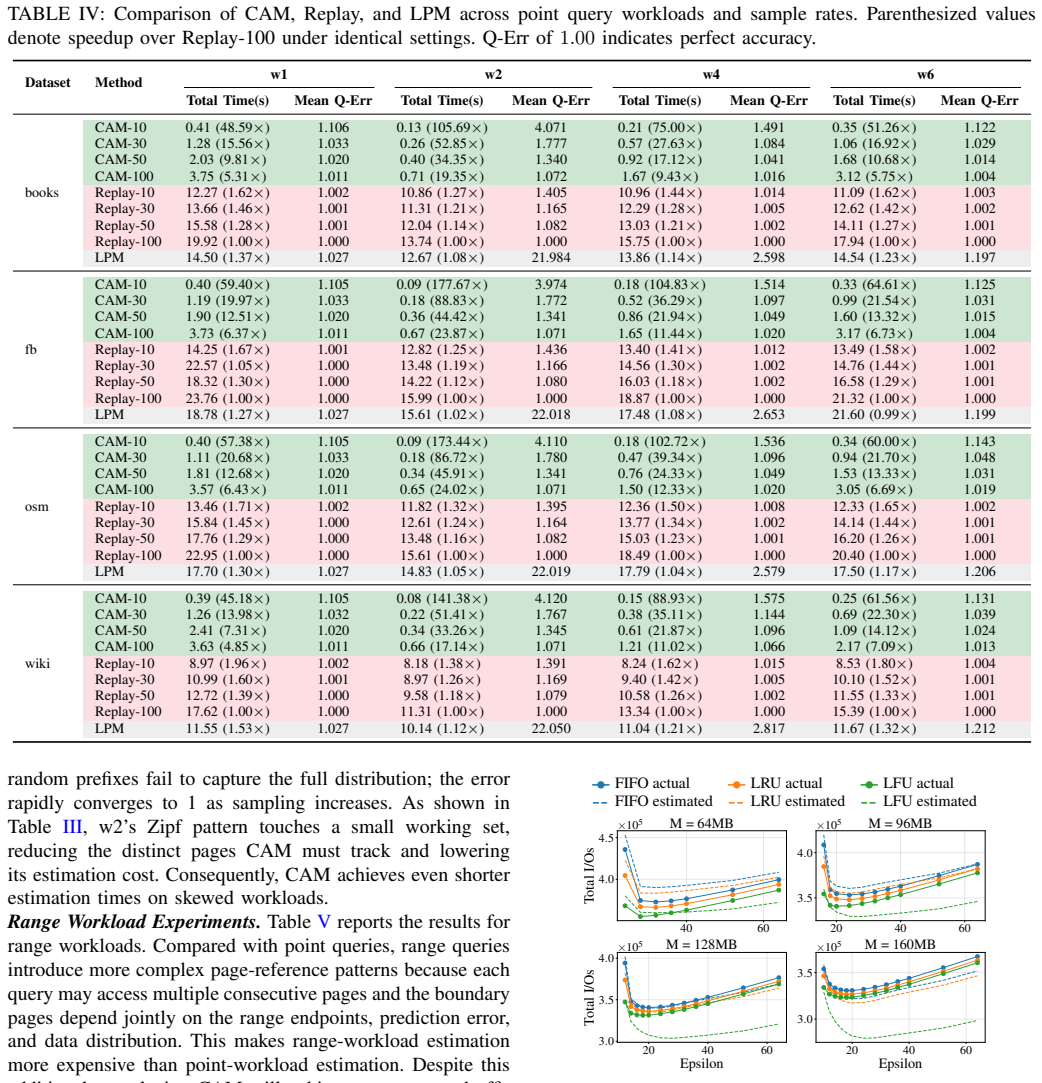
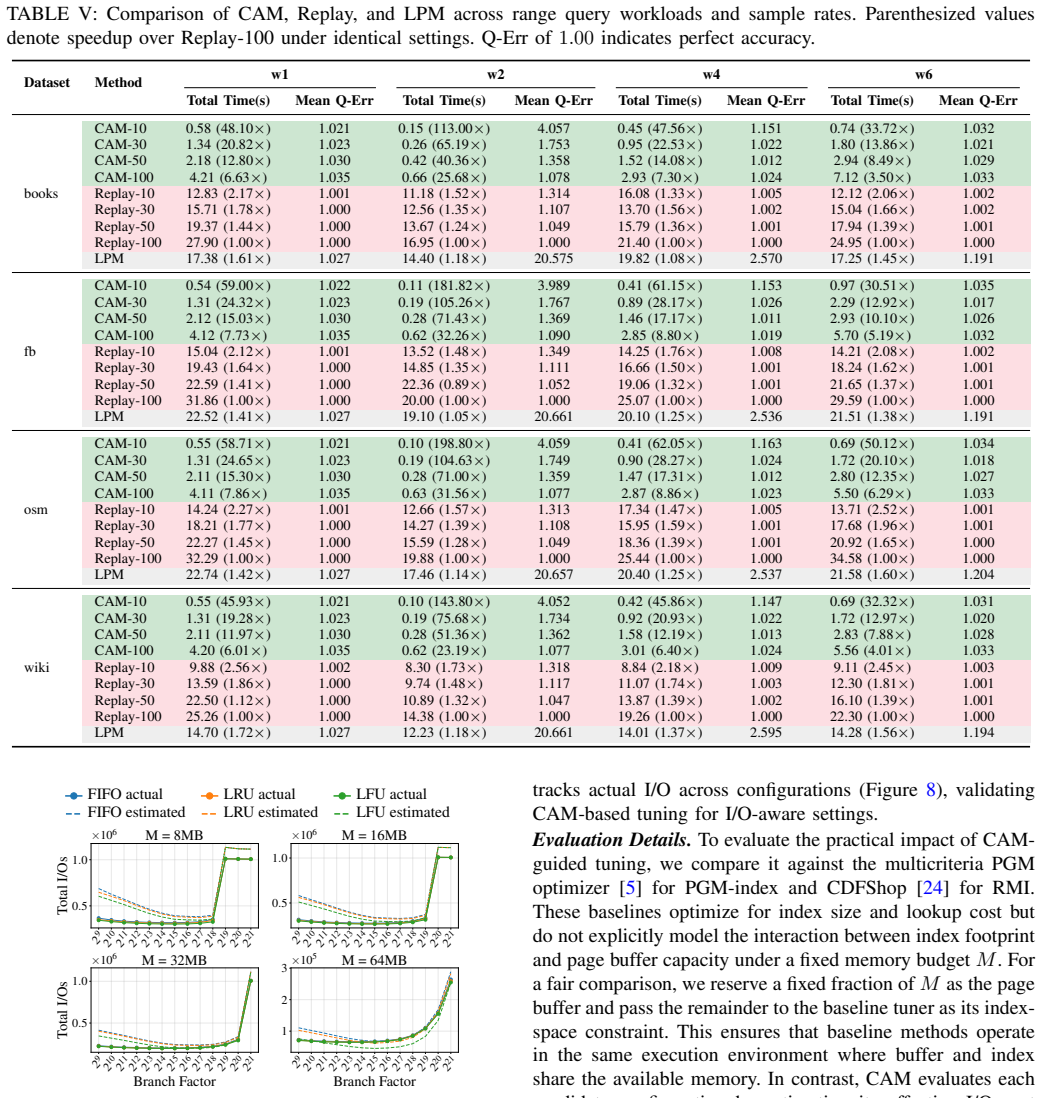
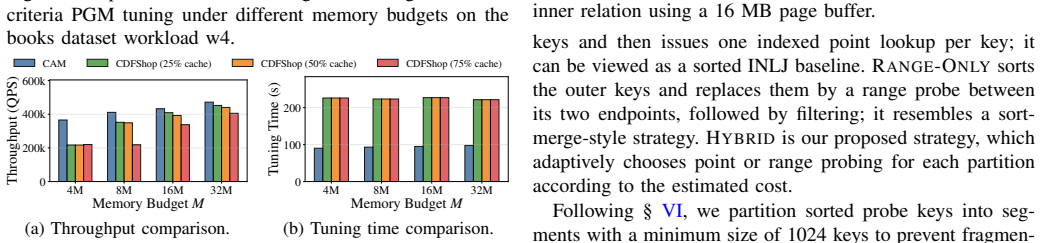
- [§3 (page access distribution estimation)] The central technical claim (abstract and §3) is that page access distributions for PGM-index and RMI can be derived directly from the learned model structure (e.g., segments or CDF) plus workload statistics, without full trace replay or workload-specific fitting. This feeds the cache-aware I/O model and the reported tuning gains. The manuscript must demonstrate, via explicit error metrics or side-by-side comparison against replayed traces under LRU (or equivalent), that the derived distributions match actual reference patterns closely enough for the 1.17×/1.66× claims to be reliable; absent such validation the downstream predictions rest on an unverified assumption.
- [Table 2 / Figure 5] Table 2 / Figure 5 (I/O estimation accuracy): the reported accuracy must be broken down by workload and eviction policy, with confidence intervals or per-query error distributions. If the largest errors occur precisely on the workloads used for the tuning experiments, the claimed speedups cannot be attributed to the model rather than to post-hoc parameter selection.
minor comments (2)
- [Abstract] The abstract states CAM is 'not tied to a particular learned index design' yet only instantiates PGM and RMI; a brief discussion of the interface required for a new design would clarify generality.
- [§4] Notation for the cache-eviction component (e.g., the function mapping logical references to physical I/Os) should be introduced once with a single equation rather than re-derived in multiple places.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will strengthen the validation of the page-access distribution estimates and accuracy breakdowns in the revision.
read point-by-point responses
-
Referee: [§3 (page access distribution estimation)] The central technical claim (abstract and §3) is that page access distributions for PGM-index and RMI can be derived directly from the learned model structure (e.g., segments or CDF) plus workload statistics, without full trace replay or workload-specific fitting. This feeds the cache-aware I/O model and the reported tuning gains. The manuscript must demonstrate, via explicit error metrics or side-by-side comparison against replayed traces under LRU (or equivalent), that the derived distributions match actual reference patterns closely enough for the 1.17×/1.66× claims to be reliable; absent such validation the downstream predictions rest on an unverified assumption.
Authors: We appreciate the referee's call for direct validation of the derived page access distributions. Section 3 presents an analytical derivation from index structure and workload statistics (without trace replay or per-workload fitting), and the end-to-end accuracy of the resulting I/O predictions is evaluated on real benchmarks in Table 2 and Figure 5. These results support the reported tuning gains. To make the validation more explicit, we will add side-by-side comparisons of the estimated distributions versus full LRU trace replay, together with quantitative error metrics (e.g., total variation distance or per-page frequency error), in a revised §3 and/or new appendix. revision: yes
-
Referee: [Table 2 / Figure 5] Table 2 / Figure 5 (I/O estimation accuracy): the reported accuracy must be broken down by workload and eviction policy, with confidence intervals or per-query error distributions. If the largest errors occur precisely on the workloads used for the tuning experiments, the claimed speedups cannot be attributed to the model rather than to post-hoc parameter selection.
Authors: We agree that finer-grained reporting is valuable. The current aggregates in Table 2 and Figure 5 cover multiple real benchmarks and both LRU and other policies, and the tuning experiments select parameters via the model (using only structure and workload statistics) before measuring throughput. In the revision we will expand these tables/figures to report accuracy broken down by workload and eviction policy, include confidence intervals, and add per-query error distributions. We will also clarify that the tuning workloads are the same as the evaluation workloads but that no post-hoc fitting to I/O traces occurs. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives page access distributions for PGM-index and RMI directly from their structural properties (segments, CDF models) plus workload statistics, then feeds those into separate cache-aware I/O formulas under eviction policies. No equations or descriptions in the abstract or skeptic summary reduce the distribution estimates to the final I/O predictions or tuning gains by construction; the estimation step is presented as an independent modeling choice that avoids trace replay. Experiments on real benchmarks serve as external validation rather than self-referential fitting. The central claim therefore remains non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Organization and maintenance of large ordered indices,
R. Bayer and E. M. McCreight, “Organization and maintenance of large ordered indices,”Acta Informatica, vol. 1, pp. 173–189, 1972
1972
-
[2]
utree: a persistent b+- tree with low tail latency,
Y . Chen, Y . Lu, K. Fang, Q. Wang, and J. Shu, “utree: a persistent b+- tree with low tail latency,”Proc. VLDB Endow., vol. 13, no. 11, pp. 2634–2648, 2020
2020
-
[3]
Making b +-trees cache conscious in main memory,
J. Rao and K. A. Ross, “Making b +-trees cache conscious in main memory,” inSIGMOD Conference. ACM, 2000, pp. 475–486
2000
-
[4]
The case for learned index structures,
T. Kraska, A. Beutel, E. H. Chi, J. Dean, and N. Polyzotis, “The case for learned index structures,” inSIGMOD Conference. ACM, 2018, pp. 489–504
2018
-
[5]
The pgm-index: a fully-dynamic compressed learned index with provable worst-case bounds,
P. Ferragina and G. Vinciguerra, “The pgm-index: a fully-dynamic compressed learned index with provable worst-case bounds,”Proc. VLDB Endow., vol. 13, no. 8, pp. 1162–1175, 2020
2020
-
[6]
ALEX: an updatable adaptive learned index,
J. Ding, U. F. Minhas, J. Yu, C. Wang, J. Do, Y . Li, H. Zhang, B. Chandramouli, J. Gehrke, D. Kossmann, D. B. Lomet, and T. Kraska, “ALEX: an updatable adaptive learned index,” inSIGMOD Conference. ACM, 2020, pp. 969–984
2020
-
[7]
APEX: A high- performance learned index on persistent memory,
B. Lu, J. Ding, E. Lo, U. F. Minhas, and T. Wang, “APEX: A high- performance learned index on persistent memory,”Proc. VLDB Endow., vol. 15, no. 3, pp. 597–610, 2021
2021
-
[8]
Updatable learned index with precise positions,
J. Wu, Y . Zhang, S. Chen, Y . Chen, J. Wang, and C. Xing, “Updatable learned index with precise positions,”Proc. VLDB Endow., vol. 14, no. 8, pp. 1276–1288, 2021
2021
-
[9]
PLIN: A persistent learned index for non-volatile memory with high performance and instant recovery,
Z. Zhang, Z. Chu, P. Jin, Y . Luo, X. Xie, S. Wan, Y . Luo, X. Wu, P. Zou, C. Zheng, G. Wu, and A. Rudoff, “PLIN: A persistent learned index for non-volatile memory with high performance and instant recovery,”Proc. VLDB Endow., vol. 16, no. 2, pp. 243–255, 2022
2022
-
[10]
Benchmarking learned indexes,
R. Marcus, A. Kipf, A. van Renen, M. Stoian, S. Misra, A. Kemper, T. Neumann, and T. Kraska, “Benchmarking learned indexes,”Proc. VLDB Endow., vol. 14, no. 1, pp. 1–13, 2020
2020
-
[11]
Learned index: A comprehensive experi- mental evaluation,
Z. Sun, X. Zhou, and G. Li, “Learned index: A comprehensive experi- mental evaluation,”Proc. VLDB Endow., vol. 16, no. 8, pp. 1992–2004, 2023
1992
-
[12]
Are updatable learned indexes ready?
C. Wongkham, B. Lu, C. Liu, Z. Zhong, E. Lo, and T. Wang, “Are updatable learned indexes ready?”Proc. VLDB Endow., vol. 15, no. 11, pp. 3004–3017, 2022
2022
-
[13]
Making in-memory learned indexes efficient on disk,
J. Zhang, K. Su, and H. Zhang, “Making in-memory learned indexes efficient on disk,”Proc. ACM Manag. Data, vol. 2, no. 3, p. 151, 2024
2024
-
[14]
From wisckey to bourbon: A learned index for log-structured merge trees,
Y . Dai, Y . Xu, A. Ganesan, R. Alagappan, B. Kroth, A. C. Arpaci- Dusseau, and R. H. Arpaci-Dusseau, “From wisckey to bourbon: A learned index for log-structured merge trees,” inOSDI. USENIX Association, 2020, pp. 155–171
2020
-
[15]
The input/output complexity of sorting and related problems,
A. Aggarwal and J. S. Vitter, “The input/output complexity of sorting and related problems,”Commun. ACM, vol. 31, no. 9, pp. 1116–1127, 1988
1988
-
[16]
External-memory dictionaries in the affine and PDAM models,
M. A. Bender, A. Conway, M. Farach-Colton, W. Jannen, Y . Jiao, R. Johnson, E. Knorr, S. McAllister, N. Mukherjee, P. Pandey, D. E. Porter, J. Yuan, and Y . Zhan, “External-memory dictionaries in the affine and PDAM models,”ACM Trans. Parallel Comput., vol. 8, no. 3, pp. 15:1–15:20, 2021
2021
-
[17]
A parametric I/O model for modern storage devices,
T. I. Papon and M. Athanassoulis, “A parametric I/O model for modern storage devices,” inDaMoN. ACM, 2021, pp. 2:1–2:11
2021
-
[18]
LRU-C: parallelizing database i/os for flash ssds,
B. Lee, M. An, and S. Lee, “LRU-C: parallelizing database i/os for flash ssds,”Proc. VLDB Endow., vol. 16, no. 9, pp. 2364–2376, 2023
2023
-
[19]
Virtual- memory assisted buffer management,
V . Leis, A. Alhomssi, T. Ziegler, Y . Loeck, and C. Dietrich, “Virtual- memory assisted buffer management,”Proc. ACM Manag. Data, vol. 1, no. 1, pp. 7:1–7:25, 2023
2023
-
[20]
ARC: A self-tuning, low overhead replacement cache,
N. Megiddo and D. S. Modha, “ARC: A self-tuning, low overhead replacement cache,” inFAST. USENIX, 2003
2003
-
[21]
Fd-buffer: a buffer manager for databases on flash disks,
S. T. On, Y . Li, B. He, M. Wu, Q. Luo, and J. Xu, “Fd-buffer: a buffer manager for databases on flash disks,” inCIKM. ACM, 2010, pp. 1297–1300
2010
-
[22]
Hierarchical web caching systems: mod- eling, design and experimental results,
H. Che, Y . Tung, and Z. Wang, “Hierarchical web caching systems: mod- eling, design and experimental results,”IEEE J. Sel. Areas Commun., vol. 20, no. 7, pp. 1305–1314, 2002
2002
-
[23]
Why are learned indexes so effective but sometimes ineffective?
Q. Liu, S. Han, Y . Qi, J. Peng, J. Li, L. Lin, and L. Chen, “Why are learned indexes so effective but sometimes ineffective?”Proc. VLDB Endow., vol. 18, no. 9, pp. 2886–2898, 2025
2025
-
[24]
Cdfshop: Exploring and optimiz- ing learned index structures,
R. Marcus, E. Zhang, and T. Kraska, “Cdfshop: Exploring and optimiz- ing learned index structures,” inSIGMOD Conference. ACM, 2020, pp. 2789–2792
2020
-
[25]
Evaluating learned indexes for external memory joins,
Y . Chesetti and P. Pandey, “Evaluating learned indexes for external memory joins,” inACDA. SIAM, 2025, pp. 101–114
2025
-
[26]
Radixspline: a single-pass learned index,
A. Kipf, R. Marcus, A. van Renen, M. Stoian, A. Kemper, T. Kraska, and T. Neumann, “Radixspline: a single-pass learned index,” in aiDM@SIGMOD. ACM, 2020, pp. 5:1–5:5
2020
-
[27]
DILI: A distribution-driven learned index,
P. Li, H. Lu, R. Zhu, B. Ding, L. Yang, and G. Pan, “DILI: A distribution-driven learned index,”Proc. VLDB Endow., vol. 16, no. 9, pp. 2212–2224, 2023
2023
-
[28]
A critical analysis of recursive model indexes,
M. Maltry and J. Dittrich, “A critical analysis of recursive model indexes,”Proc. VLDB Endow., vol. 15, no. 5, pp. 1079–1091, 2022
2022
-
[29]
A fully on-disk updatable learned index,
H. Lan, Z. Bao, J. S. Culpepper, R. Borovica-Gajic, and Y . Dong, “A fully on-disk updatable learned index,” inICDE. IEEE, 2024, pp. 4856–4869
2024
-
[30]
Updatable learned indexes meet disk-resident DBMS - from evaluations to design choices,
H. Lan, Z. Bao, J. S. Culpepper, and R. Borovica-Gajic, “Updatable learned indexes meet disk-resident DBMS - from evaluations to design choices,”Proc. ACM Manag. Data, vol. 1, no. 2, pp. 139:1–139:22, 2023
2023
-
[31]
Why are learned indexes so effective?
P. Ferragina, F. Lillo, and G. Vinciguerra, “Why are learned indexes so effective?” inICML, ser. Proceedings of Machine Learning Research, vol. 119. PMLR, 2020, pp. 3123–3132
2020
-
[32]
Operating system support for database management,
M. Stonebraker, “Operating system support for database management,” Commun. ACM, vol. 24, no. 7, pp. 412–418, 1981
1981
-
[33]
An anomaly in space- time characteristics of certain programs running in a paging machine,
L. A. Belady, R. A. Nelson, and G. S. Shedler, “An anomaly in space- time characteristics of certain programs running in a paging machine,” Commun. ACM, vol. 12, no. 6, pp. 349–353, 1969
1969
-
[34]
Driving cache replacement with ml-based lecar,
G. Vietri, L. V . Rodriguez, W. A. Martinez, S. Lyons, J. Liu, R. Ran- gaswami, M. Zhao, and G. Narasimhan, “Driving cache replacement with ml-based lecar,” inHotStorage. USENIX Association, 2018
2018
-
[35]
The LRU-K page replace- ment algorithm for database disk buffering,
E. J. O’Neil, P. E. O’Neil, and G. Weikum, “The LRU-K page replace- ment algorithm for database disk buffering,” inSIGMOD Conference. ACM Press, 1993, pp. 297–306
1993
-
[36]
2q: A low overhead high performance buffer management replacement algorithm,
T. Johnson and D. E. Shasha, “2q: A low overhead high performance buffer management replacement algorithm,” inVLDB. Morgan Kauf- mann, 1994, pp. 439–450
1994
-
[37]
LIRS: an efficient low inter-reference recency set replacement policy to improve buffer cache performance,
S. Jiang and X. Zhang, “LIRS: an efficient low inter-reference recency set replacement policy to improve buffer cache performance,” inSIG- METRICS. ACM, 2002, pp. 31–42
2002
-
[38]
CFLRU: a replacement algorithm for flash memory,
S. Park, D. Jung, J. Kang, J. Kim, and J. Lee, “CFLRU: a replacement algorithm for flash memory,” inCASES. ACM, 2006, pp. 234–241
2006
-
[39]
A unified approach to the evaluation of a class of replacement algorithms,
E. Gelenbe, “A unified approach to the evaluation of a class of replacement algorithms,”IEEE Trans. Computers, vol. 22, no. 6, pp. 611–618, 1973. [Online]. Available: https://doi.org/10.1109/TC.1973. 5009115
-
[40]
A versatile and accurate approx- imation for LRU cache performance,
C. Fricker, P. Robert, and J. Roberts, “A versatile and accurate approx- imation for LRU cache performance,” inITC. IEEE, 2012, pp. 1–8
2012
-
[41]
A unified approach to the performance analysis of caching systems,
M. Garetto, E. Leonardi, and V . Martina, “A unified approach to the performance analysis of caching systems,”ACM Trans. Model. Perform. Evaluation Comput. Syst., vol. 1, no. 3, pp. 12:1–12:28, 2016
2016
-
[42]
An overview of analysis methods and evaluation results for caching strategies,
G. Hasslinger, M. Okhovatzadeh, K. Ntougias, F. Hasslinger, and O. Hohlfeld, “An overview of analysis methods and evaluation results for caching strategies,”Comput. Networks, vol. 228, p. 109583, 2023
2023
-
[43]
Xindex: a scalable learned index for multicore data storage,
C. Tang, Y . Wang, Z. Dong, G. Hu, Z. Wang, M. Wang, and H. Chen, “Xindex: a scalable learned index for multicore data storage,” in Proceedings of the 25th ACM SIGPLAN symposium on principles and practice of parallel programming, 2020, pp. 308–320
2020
-
[44]
Fiting-tree: A data-aware index structure,
A. Galakatos, M. Markovitch, C. Binnig, R. Fonseca, and T. Kraska, “Fiting-tree: A data-aware index structure,” inSIGMOD Conference. ACM, 2019, pp. 1189–1206
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.