SAGE-Nav: Leveraging LLM Planning and Alignment Fusion for Hierarchical Scene Graph-Guided Navigation
Pith reviewed 2026-06-25 21:26 UTC · model grok-4.3
The pith
SAGE-Nav pairs large language models with scene graphs to turn abstract goals into reliable robot waypoints and fuse them with live vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
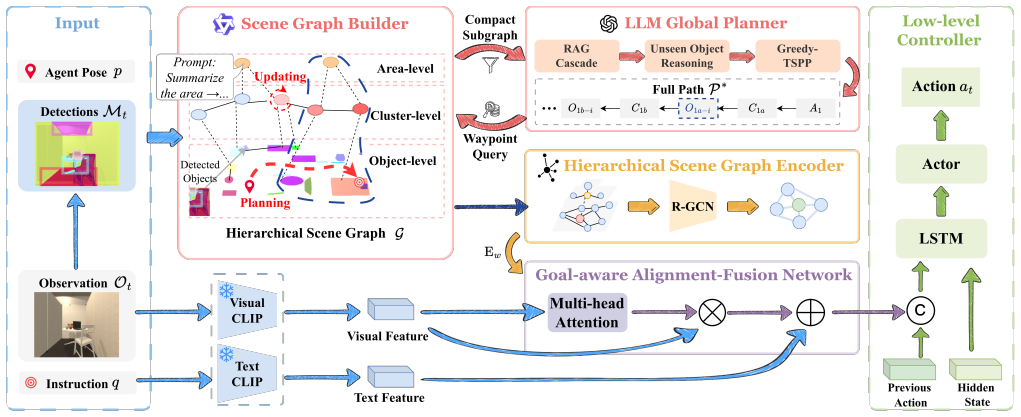
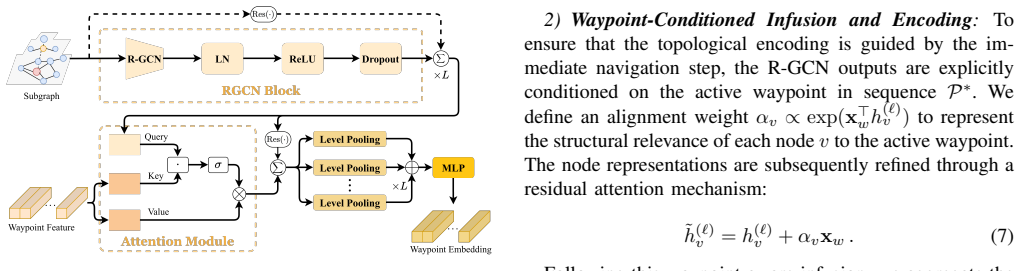
The paper presents SAGE-Nav as a hierarchical navigation system where an LLM acts as a global planner to convert abstract commands into sequences of semantically grounded waypoints. These plans are processed by a Hierarchical Scene Graph Encoder using relational graph convolutions to create embeddings that capture both meaning and layout. A Goal-aware Alignment-Fusion Network then combines these with live sensor data through an adaptive gating system to direct the low-level controller, resulting in better performance on object finding tasks.
What carries the argument
The decoupling of asynchronous global semantic planning from the high-frequency reactive control loop, enabled by the Hierarchical Scene Graph Encoder and Goal-aware Alignment-Fusion Network.
If this is right
- Navigation efficiency improves through structured planning that avoids dead ends.
- Zero-shot generalization to new environments becomes feasible without retraining.
- Control latency stays low, supporting direct transfer to physical robots.
- Dynamic scene graphs provide ongoing updates that keep plans relevant as the agent moves.
Where Pith is reading between the lines
- Such systems might reduce the need for extensive robot training data by relying on pre-trained language knowledge.
- Integration with other sensor types could further enhance robustness in cluttered spaces.
- Similar hierarchies could apply to tasks like object manipulation or multi-robot coordination.
Load-bearing premise
The large language model can consistently turn high-level instructions into waypoints that stay accurate despite incomplete views of the space and changes in the robot's position.
What would settle it
Cases where the language model's waypoints send the robot into blocked areas or loops inside a room it has only partially mapped would show the planning step does not hold.
Figures
read the original abstract
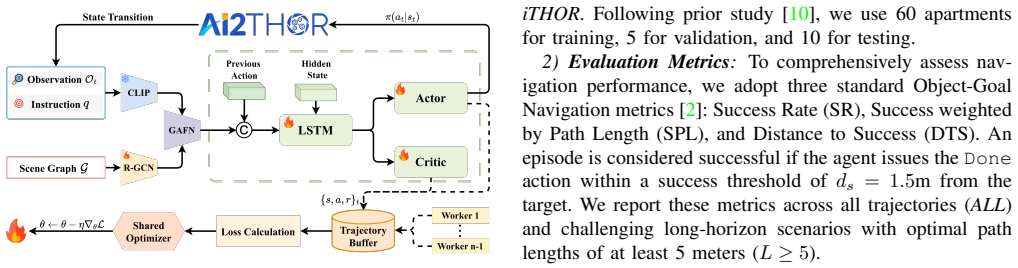
Object-Goal Navigation (ObjNav) requires embodied agents to autonomously locate specified targets using only egocentric visual observations. Existing monolithic methods struggle with long-horizon reasoning and generalize poorly to novel environments. To address these limitations, we propose SAGE-Nav, a novel hierarchical framework that integrates the reasoning capabilities of Large Language Models (LLMs) with dynamic scene graphs. Crucially, it decouples asynchronous global semantic planning from the high-frequency reactive control loop. The LLM serves as a global planner, decomposing abstract instructions into a sequence of semantically grounded waypoints. To translate these plans into dense multi-modal guidance, we design a Hierarchical Scene Graph Encoder (HSGE) that leverages relational graph convolutions to produce structure-aware embeddings preserving both semantic and spatial topology. Furthermore, we develop the Goal-aware Alignment-Fusion Network (GAFN) to dynamically fuse real-time perception with these structural priors. Using an adaptive gating mechanism with an explicit inductive bias, GAFN ensures robust visual-topological alignment for the low-level policy. Extensive evaluations in the i-THOR and RoboTHOR environments demonstrate that SAGE-Nav achieves state-of-the-art performance, delivering substantial gains in navigation efficiency and zero-shot generalization while maintaining the low control latency required for physical robotic deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAGE-Nav, a hierarchical framework for Object-Goal Navigation that decouples asynchronous LLM-based global semantic planning (decomposing natural-language instructions into sequences of semantically grounded waypoints) from a high-frequency reactive control loop. It introduces a Hierarchical Scene Graph Encoder (HSGE) using relational graph convolutions to produce structure-aware embeddings and a Goal-aware Alignment-Fusion Network (GAFN) with adaptive gating to fuse real-time egocentric perception with these priors. Extensive evaluations in i-THOR and RoboTHOR are reported to achieve SOTA navigation efficiency, zero-shot generalization, and low control latency suitable for physical deployment.
Significance. If the central claims hold, the work would represent a meaningful advance in embodied navigation by showing how LLM reasoning can be safely decoupled from reactive control via scene-graph mediation, potentially improving long-horizon performance and generalization without sacrificing real-time constraints. The explicit inductive bias in GAFN and the hierarchical separation are technically interesting design choices that could influence subsequent hybrid LLM-embodied systems.
major comments (1)
- [Abstract] Abstract: The SOTA performance and zero-shot generalization claims rest on the LLM producing a sequence of waypoints that remain reachable and semantically consistent as the agent moves through partially observed scenes. No mechanism for automatic waypoint invalidation detection, consistency checking against new observations, or bounded re-planning latency is described; without such safeguards the claimed decoupling of global planning from the reactive loop cannot be guaranteed and the hierarchical advantage reduces to standard reactive navigation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a point where the abstract could more explicitly support the decoupling claim. We address the comment below and will revise the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The SOTA performance and zero-shot generalization claims rest on the LLM producing a sequence of waypoints that remain reachable and semantically consistent as the agent moves through partially observed scenes. No mechanism for automatic waypoint invalidation detection, consistency checking against new observations, or bounded re-planning latency is described; without such safeguards the claimed decoupling of global planning from the reactive loop cannot be guaranteed and the hierarchical advantage reduces to standard reactive navigation.
Authors: We agree that the abstract does not explicitly mention these safeguards and that this weakens the presentation of the hierarchical decoupling. The full manuscript (Sections 3.2 and 4.2) describes dynamic scene-graph updates from egocentric observations and the GAFN adaptive gating that detects misalignment between planned waypoints and current perception; when misalignment exceeds a threshold the system triggers asynchronous LLM re-planning. Re-planning latency is bounded by running the LLM planner in a separate thread with a fixed timeout. Nevertheless, because these details are not summarized in the abstract, the referee's concern is valid. We will revise the abstract to include a concise statement on dynamic consistency checking via HSGE updates and GAFN gating together with bounded asynchronous re-planning. revision: yes
Circularity Check
No circularity: framework description contains no derivations or self-referential reductions
full rationale
The provided abstract and manuscript description outline a hierarchical navigation system (LLM planner + HSGE + GAFN) with empirical SOTA claims on i-THOR/RoboTHOR. No equations, fitted parameters, predictions, or self-citations appear in the text. No load-bearing step reduces by construction to its inputs, and no uniqueness theorems or ansatzes are invoked. The central claims rest on external evaluations rather than internal derivation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of object goal navigation
J. Sun et al. “A survey of object goal navigation”. In:IEEE Transactions on Automation Science and Engineering22 (2024), pp. 2292–2308
2024
-
[2]
Objectnav revisited: On evaluation of embodied agents navigating to objects
D. Batra et al. “Objectnav revisited: On evaluation of embodied agents navigating to objects”. In:arXiv preprint arXiv:2006.13171 (2020)
arXiv 2006
-
[3]
Object goal navigation using goal-oriented se- mantic exploration
D. S. Chaplot et al. “Object goal navigation using goal-oriented se- mantic exploration”. In:Advances in neural information processing systems33 (2020), pp. 4247–4258
2020
-
[4]
Target-driven visual navigation in indoor scenes using deep reinforcement learning
Y . Zhu et al. “Target-driven visual navigation in indoor scenes using deep reinforcement learning”. In:Proc. IEEE Int. Conf. Robot. Autom.2017, pp. 3357–3364
2017
-
[5]
Visual semantic navigation using scene priors
W. Yang et al. “Visual semantic navigation using scene priors”. In: arXiv preprint arXiv:1810.06543(2018)
Pith/arXiv arXiv 2018
-
[6]
Asynchronous Methods for Deep Reinforcement Learning
V . Mnih et al. “Asynchronous Methods for Deep Reinforcement Learning”. In:ArXivabs/1602.01783 (2016)
Pith/arXiv arXiv 2016
-
[7]
GN0: Toward a Unified Paradigm for Generation, Evaluation, and Policy Learning in Visual-Language Navigation
X. Li et al. “GN0: Toward a Unified Paradigm for Generation, Evaluation, and Policy Learning in Visual-Language Navigation”. In: 2026
2026
-
[8]
Hierarchical object-to-zone graph for object navigation
S. Zhang et al. “Hierarchical object-to-zone graph for object navigation”. In:Proc. IEEE/CVF Int. Conf. Comput. Vis.2021, pp. 15130–15140
2021
-
[9]
Aligning Knowledge Graph with Visual Perception for Object-goal Navigation
N. Xu et al. “Aligning Knowledge Graph with Visual Perception for Object-goal Navigation”. In:Proc. IEEE Int. Conf. Robot. Autom. (2024), pp. 5214–5220
2024
-
[10]
Context-Aware Graph Inference and Generative Adversarial Imitation Learning for Object-Goal Navigation in Un- familiar Environment
Y . Meng et al. “Context-Aware Graph Inference and Generative Adversarial Imitation Learning for Object-Goal Navigation in Un- familiar Environment”. In:IEEE Robot. Autom. Lett.10 (2025), pp. 3803–3810
2025
-
[11]
Temporal Scene-Object Graph Learning for Object Navigation
L. Chen et al. “Temporal Scene-Object Graph Learning for Object Navigation”. In:IEEE Robot. Autom. Lett.10 (2025), pp. 4914– 4921
2025
-
[12]
Vision-Based Navigation With Language-Based Assistance via Imitation Learning With Indirect Intervention
K. Nguyen et al. “Vision-Based Navigation With Language-Based Assistance via Imitation Learning With Indirect Intervention”. In: Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit.2019
2019
-
[13]
Towards target-driven visual navigation in indoor scenes via generative imitation learning
Q. Wu et al. “Towards target-driven visual navigation in indoor scenes via generative imitation learning”. In:IEEE Robot. Autom. Lett.6.1 (2020), pp. 175–182
2020
-
[14]
A New Path: Scaling Vision-and-Language Navigation With Synthetic Instructions and Imitation Learning
A. Kamath et al. “A New Path: Scaling Vision-and-Language Navigation With Synthetic Instructions and Imitation Learning”. In:Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit.2023, pp. 10813–10823
2023
-
[15]
Optimal Scene Graph Planning with Large Language Model Guidance
Z. Dai et al. “Optimal Scene Graph Planning with Large Language Model Guidance”. In:Proc. IEEE Int. Conf. Robot. Autom.(2023), pp. 14062–14069
2023
-
[16]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation
H. Yin et al. “Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation”. In:Advances in neural information processing systems37 (2024), pp. 5285–5307
2024
-
[17]
Unigoal: Towards universal zero-shot goal-oriented navigation
H. Yin et al. “Unigoal: Towards universal zero-shot goal-oriented navigation”. In:Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recog- nit.2025, pp. 19057–19066
2025
-
[18]
Retrieval-Augmented Generation for Knowledge- Intensive NLP Tasks
P. Lewis et al. “Retrieval-Augmented Generation for Knowledge- Intensive NLP Tasks”. In:ArXivabs/2005.11401 (2020)
Pith/arXiv arXiv 2005
-
[19]
Continuously learning, adapting, and improving: A dual-process approach to autonomous driving
J. Mei et al. “Continuously learning, adapting, and improving: A dual-process approach to autonomous driving”. In:arXiv preprint arXiv:2405.15324(2024)
arXiv 2024
-
[20]
LeapV AD: A leap in autonomous driving via cognitive perception and dual-process thinking
Y . Ma et al. “LeapV AD: A leap in autonomous driving via cognitive perception and dual-process thinking”. In:IEEE Transactions on Neural Networks and Learning Systems(2025)
2025
-
[21]
LLM-enhanced Scene Graph Learning for Household Rearrangement
W. Li et al. “LLM-enhanced Scene Graph Learning for Household Rearrangement”. In:SIGGRAPH Asia 2024 Conference Papers (2024)
2024
-
[22]
Learning object relation graph and tentative policy for visual navigation
H. Du et al. “Learning object relation graph and tentative policy for visual navigation”. In:Proc. Eur . Conf. Comput. Vis.2020, pp. 19– 34
2020
-
[23]
Learning to learn how to learn: Self-adaptive visual navigation using meta-learning
M. Wortsman et al. “Learning to learn how to learn: Self-adaptive visual navigation using meta-learning”. In:Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit.2019, pp. 6750–6759
2019
-
[24]
Vtnet: Visual transformer network for object goal navigation
H. Du et al. “Vtnet: Visual transformer network for object goal navigation”. In:arXiv preprint arXiv:2105.09447(2021)
arXiv 2021
-
[25]
Unbiased directed object attention graph for object navigation
R. Dang et al. “Unbiased directed object attention graph for object navigation”. In:Proceedings of the 30th ACM International Con- ference on Multimedia. 2022, pp. 3617–3627
2022
-
[26]
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
A. Rajvanshi et al. “SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments”. In: International Conference on Automated Planning and Scheduling. 2023
2023
-
[27]
CogNav: Cognitive Process Modeling for Object Goal Navigation with LLMs
Y . Cao et al. “CogNav: Cognitive Process Modeling for Object Goal Navigation with LLMs”. In:ArXivabs/2412.10439 (2024)
arXiv 2024
-
[28]
CogDDN: A Cognitive Demand-Driven Navigation with Decision Optimization and Dual-Process Thinking
Y . Huang et al. “CogDDN: A Cognitive Demand-Driven Navigation with Decision Optimization and Dual-Process Thinking”. In:Pro- ceedings of the 33rd ACM International Conference on Multimedia. 2025, 5237–5246
2025
-
[29]
H. Wang et al. “User-Centric Object Navigation: A Benchmark with Integrated User Habits for Personalized Embodied Object Search”. In:arXiv preprint arXiv:2602.06459(2026)
arXiv 2026
-
[30]
Embodied navigation foundation model
J. Zhang et al. “Embodied navigation foundation model”. In:arXiv preprint arXiv:2509.12129(2025)
arXiv 2025
-
[31]
Navid: Video-based vlm plans the next step for vision-and-language navigation
J. Zhang et al. “Navid: Video-based vlm plans the next step for vision-and-language navigation”. In:arXiv preprint arXiv:2402.15852(2024)
Pith/arXiv arXiv 2024
-
[32]
Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks
J. Zhang et al. “Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks”. In:arXiv preprint arXiv:2412.06224(2024)
Pith/arXiv arXiv 2024
-
[33]
AURA: Multi-modal Shared Autonomy for Urban Navigation
Y . Ma et al. “AURA: Multi-modal Shared Autonomy for Urban Navigation”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2026, pp. 18171–18181
2026
-
[34]
DeCoNav: Dialog enhanced Long-Horizon Collaborative Vision-Language Navigation
S. Zhou et al. “DeCoNav: Dialog enhanced Long-Horizon Collaborative Vision-Language Navigation”. In:arXiv preprint arXiv:2604.12486(2026)
Pith/arXiv arXiv 2026
-
[35]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford et al. “Learning Transferable Visual Models From Natural Language Supervision”. In:Proc. Int. Conf. Mach. Learn. 2021
2021
-
[36]
Llama: Open and efficient foundation language models
H. Touvron et al. “Llama: Open and efficient foundation language models”. In:arXiv preprint arXiv:2302.13971(2023)
Pith/arXiv arXiv 2023
-
[37]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning
Q. Gu et al. “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning”. In:Proc. IEEE Int. Conf. Robot. Autom. 2024, pp. 5021–5028
2024
-
[38]
Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation
A. Werby et al. “Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation”. In:First Workshop on Vision- Language Models for Navigation and Manipulation at ICRA 2024
2024
-
[39]
Language-Grounded Hierarchical Planning and Execution with Multi-Robot 3D Scene Graphs
J. Strader et al. “Language-Grounded Hierarchical Planning and Execution with Multi-Robot 3D Scene Graphs”. In:ArXiv abs/2506.07454 (2025)
arXiv 2025
-
[40]
A review of recurrent neural networks: LSTM cells and network architectures
Y . Yu et al. “A review of recurrent neural networks: LSTM cells and network architectures”. In:Neural computation31.7 (2019), pp. 1235–1270
2019
-
[41]
NavRAG: Generating User Demand Instructions for Embodied Navigation through Retrieval-Augmented LLM
Z. Wang et al. “NavRAG: Generating User Demand Instructions for Embodied Navigation through Retrieval-Augmented LLM”. In: Annual Meeting of the Association for Computational Linguistics. 2025
2025
-
[42]
Embodied-RAG: General non-parametric Embodied Memory for Retrieval and Generation
Q. Xie et al. “Embodied-RAG: General non-parametric Embodied Memory for Retrieval and Generation”. In:ArXivabs/2409.18313 (2024)
arXiv 2024
-
[43]
Composition-based Multi-Relational Graph Convolutional Networks
S. Vashishth et al. “Composition-based Multi-Relational Graph Convolutional Networks”. In:ArXivabs/1911.03082 (2019)
arXiv 1911
-
[44]
Attention is all you need
A. Vaswani et al. “Attention is all you need”. In:Advances in neural information processing systems30 (2017)
2017
-
[45]
Ai2-thor: An interactive 3d environment for visual ai
E. Kolve et al. “Ai2-thor: An interactive 3d environment for visual ai”. In:arXiv preprint arXiv:1712.05474(2017)
Pith/arXiv arXiv 2017
-
[46]
Robothor: An open simulation-to-real embodied ai platform
M. Deitke et al. “Robothor: An open simulation-to-real embodied ai platform”. In:Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. 2020, pp. 3164–3174
2020
-
[47]
S. Bai et al. “Qwen2.5-VL Technical Report”. In:ArXiv abs/2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[48]
A Simple Framework for Open-V ocabulary Segmentation and Detection
H. Zhang et al. “A Simple Framework for Open-V ocabulary Segmentation and Detection”. In:2023 IEEE/CVF International Conference on Computer Vision (ICCV)(2023), pp. 1020–1031
2023
-
[49]
Visual navigation with spatial attention
B. Mayo et al. “Visual navigation with spatial attention”. In:Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit.2021, pp. 16898– 16907
2021
-
[50]
Layout-based causal inference for object naviga- tion
S. Zhang et al. “Layout-based causal inference for object naviga- tion”. In:Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. 2023, pp. 10792–10802
2023
-
[51]
Tdanet: Target-directed attention network for object- goal visual navigation with zero-shot ability
S. Lian et al. “Tdanet: Target-directed attention network for object- goal visual navigation with zero-shot ability”. In:IEEE Robot. Autom. Lett.(2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.