Probing Spatial Structure in Pretrained Audio Representations
Pith reviewed 2026-06-28 00:32 UTC · model grok-4.3
The pith
Pretrained audio encoders capture source location details more readily than room acoustics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The SARL benchmark shows that input configuration and training paradigm shape spatial encoding; source factors are consistently easier to decode than room factors; and sensitivity analysis under controlled perturbations shows heterogeneous responses to source and room variation. These results reveal systematic biases in current pretrained audio representations.
What carries the argument
The SARL benchmark, a controlled probing framework that applies linear decoders to pretrained encoders to read out source-level factors (azimuth, elevation, distance, class) and room-level factors (RT60, volume, shape).
If this is right
- Tasks involving room properties will require more than off-the-shelf pretrained encoders.
- Source localization performance will benefit more from existing representations than room classification will.
- Changing input format or training objective will alter the spatial information retained by an encoder.
- Sensitivity to controlled changes can identify which spatial aspects a given model handles well or poorly.
Where Pith is reading between the lines
- The benchmark could be used to guide selection of encoders for applications like augmented reality audio.
- Similar probing could be applied to other audio properties such as temporal dynamics or timbre.
- Extending SARL to multimodal models might show whether adding visual input reduces the observed audio spatial biases.
Load-bearing premise
That linear or simple decoders and controlled perturbations give an unbiased readout of the spatial information actually present in the representations.
What would settle it
Finding uniform decoding accuracy for source and room factors when using nonlinear decoders or alternate perturbation methods on the same pretrained encoders.
Figures
read the original abstract
Pretrained spatial audio encoders are increasingly used as general-purpose representations for perceptual tasks, yet their spatial encoding capabilities remain poorly understood. We introduce the Spatial Audio Representation Learning (SARL) benchmark, a controlled framework for evaluating spatial information in pretrained audio models. SARL probes source-level factors (azimuth, elevation, distance, class) and room-level factors (RT60, volume, shape). Experiments across diverse encoders reveal three patterns: input configuration and training paradigm shape spatial encoding; source factors are consistently easier to decode than room factors; and sensitivity analysis under controlled perturbations shows heterogeneous responses to source and room variation. These results reveal systematic biases in current pretrained audio representations. SARL is released as an open-source benchmark for reproducible evaluation of spatial audio representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Spatial Audio Representation Learning (SARL) benchmark to probe spatial information in pretrained audio encoders. It evaluates source-level factors (azimuth, elevation, distance, class) and room-level factors (RT60, volume, shape) across diverse models, reporting three patterns: input configuration and training paradigm influence spatial encoding; source factors are consistently easier to decode than room factors; and sensitivity analysis under controlled perturbations reveals heterogeneous responses. The authors conclude that these patterns demonstrate systematic biases in current pretrained audio representations, and release SARL as an open-source benchmark.
Significance. If the probing results prove robust to decoder choice and data-construction details, SARL would provide a valuable controlled framework for diagnosing spatial biases in audio representations used for perceptual tasks. The open-source release is a positive contribution to reproducibility in the field.
major comments (3)
- [§4.2] §4.2 (Probing setup): The central claim that source factors are easier to decode than room factors and that the patterns reveal intrinsic biases in the encoders rests on the assumption that the linear or shallow decoders deliver an unbiased readout. No ablation on decoder depth, regularization strength, or comparison against non-linear probes is described, so it remains possible that the reported source-room asymmetry is partly an artifact of probe capacity rather than a property of the representations.
- [§5] §5 (Perturbation analysis): The heterogeneous sensitivity results depend on the controlled perturbations successfully isolating source versus room variation. The manuscript provides no quantitative verification of isolation strength (e.g., correlation between perturbed factors or residual leakage in the synthetic data pipeline), which directly affects whether the observed heterogeneity can be attributed to the encoders rather than benchmark construction choices.
- [§3] §3 (SARL benchmark definition): The claim that input configuration and training paradigm shape spatial encoding is load-bearing for the overall narrative, yet the paper does not report statistical tests (e.g., ANOVA or permutation tests) comparing the three patterns across encoder families while controlling for multiple comparisons.
minor comments (2)
- [Abstract] Abstract: The phrase 'systematic biases' is used without a precise operational definition tied to the three reported patterns; a short clarifying sentence would improve precision.
- Figure captions (throughout): Several figures lack error bars or confidence intervals on the decoding accuracies, making it difficult to assess the reliability of the source-versus-room differences.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify opportunities to strengthen the robustness of our claims, and we outline targeted revisions below.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Probing setup): The central claim that source factors are easier to decode than room factors and that the patterns reveal intrinsic biases in the encoders rests on the assumption that the linear or shallow decoders deliver an unbiased readout. No ablation on decoder depth, regularization strength, or comparison against non-linear probes is described, so it remains possible that the reported source-room asymmetry is partly an artifact of probe capacity rather than a property of the representations.
Authors: We appreciate the referee's point on probe capacity. Linear probes are the conventional choice in representation probing precisely because they measure information that is linearly accessible, which directly supports our narrative about readily encoded spatial factors. To verify that the source-room asymmetry is not an artifact, we will add ablations with 2-layer MLPs, varied L2 regularization, and report the resulting decoding accuracies in the revised manuscript. revision: yes
-
Referee: [§5] §5 (Perturbation analysis): The heterogeneous sensitivity results depend on the controlled perturbations successfully isolating source versus room variation. The manuscript provides no quantitative verification of isolation strength (e.g., correlation between perturbed factors or residual leakage in the synthetic data pipeline), which directly affects whether the observed heterogeneity can be attributed to the encoders rather than benchmark construction choices.
Authors: We agree that explicit verification of isolation is necessary. In the revision we will report Pearson correlations between the target factors before and after perturbation, together with residual leakage statistics computed on the synthetic pipeline, to confirm that source and room variations remain largely independent. revision: yes
-
Referee: [§3] §3 (SARL benchmark definition): The claim that input configuration and training paradigm shape spatial encoding is load-bearing for the overall narrative, yet the paper does not report statistical tests (e.g., ANOVA or permutation tests) comparing the three patterns across encoder families while controlling for multiple comparisons.
Authors: We acknowledge the value of formal statistical support. We will incorporate one-way ANOVA tests with Tukey HSD post-hoc corrections (controlling for multiple comparisons) on the decoding accuracies across encoder families and input configurations, reporting the resulting p-values in the revised manuscript. revision: yes
Circularity Check
No circularity: experimental benchmark with new measurements
full rationale
The paper introduces the SARL benchmark and reports empirical patterns from probing pretrained encoders on source and room factors. No equations, fitted parameters, predictions derived from prior fits, or self-citation chains appear in the derivation of the three observed patterns. Claims rest on new experimental readouts rather than reducing to inputs by construction. This matches the default expectation for non-circular experimental work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Un- like monaural recordings, multichannel signals encode direc- tional, distance, and room-dependent cues that support three- dimensional perception [4]
Introduction Spatial audio plays a central role in immersive media, robotics, embodied AI, and acoustic scene understanding [1, 2, 3]. Un- like monaural recordings, multichannel signals encode direc- tional, distance, and room-dependent cues that support three- dimensional perception [4]. Recent advances in spatially-aware audio models have led to increas...
-
[2]
Related Work Spatial audio modeling has evolved from task-specific local- ization systems toward broader spatial representation learn- ing. Early work on sound event localization and detection (SELD) introduced neural architectures for jointly predicting sound classes and spatial positions from multichannel record- ings [17, 18]. Subsequent research explo...
Pith/arXiv arXiv 2026
-
[3]
The benchmark contains seven tasks covering source-level factors (azimuth, elevation, dis- tance, event) and room-level factors (RT60, volume, shape)
Methodology We evaluate pretrained audio encoders using a controlled prob- ing framework to determine whether spatial factors are en- coded in frozen representations. The benchmark contains seven tasks covering source-level factors (azimuth, elevation, dis- tance, event) and room-level factors (RT60, volume, shape). Spatial scenes are synthesized with ind...
-
[4]
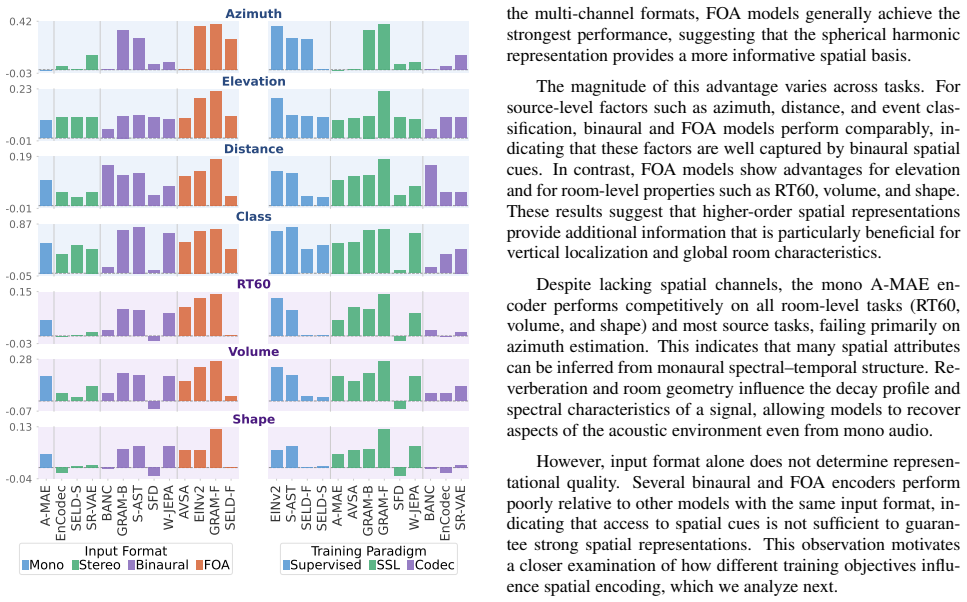
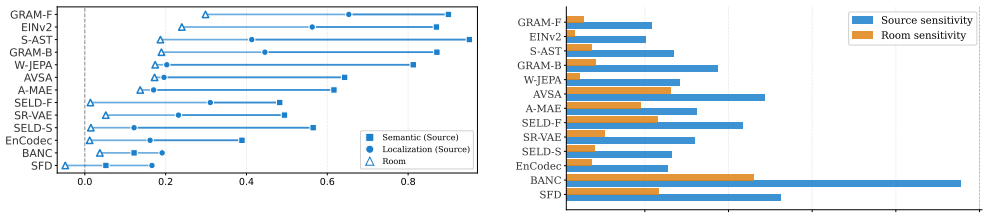
Results We analyze how spatial information is encoded in pretrained au- dio representations from four perspectives: input format, train- ing paradigm, the source–room gap in probing performance, and representation sensitivity. We first examine how input for- mat and training paradigm influence probing performance, a nd then analyze systematic differences ...
-
[5]
Conclusion We introduced a controlled framework for evaluating spatial factor encoding in pretrained audio representations. The study combines a synthetic dataset with independently controllable spatial factors, a unified probing benchmark spanning seven source and room tasks, and a complementary representation sensitivity analysis that measures embedding...
-
[6]
All scientific ideas, experiments, source-code, and conclusions were developed and verified by the authors, who take full responsibility for the manuscript
Generative AI Use Disclosure Generative AI tools were used only for limited language editing and polishing. All scientific ideas, experiments, source-code, and conclusions were developed and verified by the authors, who take full responsibility for the manuscript
-
[7]
Soundspaces: Audio- visual navigation in 3d environments,
C. Chen, U. Jain, C. Schissler, S. V . A. Gari, Z. Al-Halah, V . K. Ithapu, P. Robinson, and K. Grauman, “Soundspaces: Audio- visual navigation in 3d environments,” inEuropean conference on computer vision. Springer, 2020, pp. 17–36
2020
-
[8]
Look, listen, and act: Towards audio-visual embodied navigation,
C. Gan, Y . Zhang, J. Wu, B. Gong, and J. B. Tenenbaum, “Look, listen, and act: Towards audio-visual embodied navigation,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 9701–9707
2020
-
[9]
Learning representa- tions from audio-visual spatial alignment,
P. Morgado, Y . Li, and N. Nvasconcelos, “Learning representa- tions from audio-visual spatial alignment,”Advances in Neural Information Processing Systems, vol. 33, pp. 4733–4744, 2020
2020
-
[10]
Blauert,Spatial hearing: the psychophysics of human sound localization
J. Blauert,Spatial hearing: the psychophysics of human sound localization. MIT press, 1997
1997
-
[11]
Bat: Learning to reason about spatial sounds with large language models,
Z. Zheng, P. Peng, Z. Ma, X. Chen, E. Choi, and D. Harwath, “Bat: Learning to reason about spatial sounds with large language models,”arXiv preprint arXiv:2402.01591, 2024
arXiv 2024
-
[12]
Gram: Spa- tial general-purpose audio representation models for real-world applications,
G. Yuksel, M. van Gerven, and K. van der Heijden, “Gram: Spa- tial general-purpose audio representation models for real-world applications,”arXiv preprint arXiv:2506.00934, 2025
arXiv 2025
-
[13]
Hear 2021: Holistic evaluation of audio representations,
J. Turian, J. Shier, H. R. Khan, B. Raj, B. W. Schuller, C. J. Stein- metz, C. Malloy, G. Tzanetakis, G. Velarde, K. McNallyet al., “Hear 2021: Holistic evaluation of audio representations,”arXiv preprint arXiv:2203.03022, vol. 1, no. 3, p. 5, 2022
arXiv 2021
-
[14]
SUPERB: Speech Processing Universal PERformance Benchmark,
S. wen Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, T.-H. Huang, W.-C. Tseng, K. tik Lee, D.-R. Liu, Z. Huang, S. Dong, S.-W. Li, S. Watanabe, A. Mohamed, and H. yi Lee, “SUPERB: Speech Processing Universal PERformance Benchmark,” inProc. Inter- speech 2021, 2021, pp. 1194–1198
2021
-
[15]
X-ares: A comprehensive framework for assessing audio encoder performance,
J. Zhang, H. Dinkel, Y . Niu, C. Liu, S. Cheng, A. Zhao, and J. Luan, “X-ares: A comprehensive framework for assessing audio encoder performance,”arXiv preprint arXiv:2505.16369, 2025
arXiv 2025
-
[16]
Marble: Music audio represen- tation benchmark for universal evaluation,
R. Yuan, Y . Ma, Y . Li, G. Zhang, X. Chen, H. Yin, Y . Liu, J. Huang, Z. Tian, B. Denget al., “Marble: Music audio represen- tation benchmark for universal evaluation,”Advances in Neural Information Processing Systems, 2023
2023
-
[17]
Overview and evaluation of sound event localization and detec- tion in dcase 2019,
A. Politis, A. Mesaros, S. Adavanne, T. Heittola, and T. Virtanen, “Overview and evaluation of sound event localization and detec- tion in dcase 2019,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 684–698, 2020
2019
-
[18]
The locata challenge: Acous- tic source localization and tracking,
C. Evers, H. W. L ¨ollmann, H. Mellmann, A. Schmidt, H. Barfuss, P. A. Naylor, and W. Kellermann, “The locata challenge: Acous- tic source localization and tracking,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020
2020
-
[19]
The third ‘chime’speech separation and recognition challenge: Dataset, task and baselines,
J. Barker, R. Marxer, E. Vincent, and S. Watanabe, “The third ‘chime’speech separation and recognition challenge: Dataset, task and baselines,” in2015 IEEE workshop on automatic speech recognition and understanding (ASRU). IEEE, 2015
2015
-
[20]
A summary of the reverb challenge: state-of-the- art and remaining challenges in reverberant speech processing re- search,
K. Kinoshita, M. Delcroix, S. Gannot, E. A. P. Habets, R. Haeb- Umbach, W. Kellermann, V . Leutnant, R. Maas, T. Nakatani, B. Rajet al., “A summary of the reverb challenge: state-of-the- art and remaining challenges in reverberant speech processing re- search,”EURASIP Journal on Advances in Signal Processing, vol. 2016, no. 1, p. 7, 2016
2016
-
[21]
Understanding intermediate layers using linear classifier probes,
G. Alain and Y . Bengio, “Understanding intermediate layers using linear classifier probes,”arXiv preprint arXiv:1610.01644, 2016
Pith/arXiv arXiv 2016
-
[22]
Designing and interpreting probes with control tasks,
J. Hewitt and P. Liang, “Designing and interpreting probes with control tasks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (emnlp-ijcnlp), 2019, pp. 2733–2743
2019
-
[23]
Sound event localization and detection of overlapping sources using con- volutional recurrent neural networks,
S. Adavanne, A. Politis, J. Nikunen, and T. Virtanen, “Sound event localization and detection of overlapping sources using con- volutional recurrent neural networks,”IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 1, pp. 34–48, 2018
2018
-
[24]
An improved event-independent network for polyphonic sound event localization and detection,
Y . Cao, T. Iqbal, Q. Kong, F. An, W. Wang, and M. D. Plumbley, “An improved event-independent network for polyphonic sound event localization and detection,” inICASSP 2021-2021 IEEE In- ternational Conference on Acoustics, Speech and Signal Process- ing (ICASSP). IEEE, 2021, pp. 885–889
2021
-
[25]
Wavjepa: Semantic learning unlocks ro- bust audio foundation models for raw waveforms,
G. Yuksel, P. Guetschel, M. Tangermann, M. van Gerven, and K. van der Heijden, “Wavjepa: Semantic learning unlocks ro- bust audio foundation models for raw waveforms,”arXiv preprint arXiv:2509.23238, 2025
arXiv 2025
-
[26]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”arXiv arXiv:2210.13438, 2022
Pith/arXiv arXiv 2022
-
[27]
Banc: Towards efficient binaural audio neural codec for overlapping speech,
A. Ratnarajah, S.-X. Zhang, and D. Yu, “Banc: Towards efficient binaural audio neural codec for overlapping speech,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[28]
Towards a unified representation eval- uation framework beyond downstream tasks,
C. Plachouras, J. Guinot, G. Fazekas, E. Quinton, E. Bene- tos, and J. Pauwels, “Towards a unified representation eval- uation framework beyond downstream tasks,”arXiv preprint arXiv:2505.06224, 2025
arXiv 2025
-
[29]
Masked autoencoders that lis- ten,
P.-Y . Huang, H. Xu, J. Li, A. Baevski, M. Auli, W. Galuba, F. Metze, and C. Feichtenhofer, “Masked autoencoders that lis- ten,”Advances in neural information processing systems, vol. 35, pp. 28 708–28 720, 2022
2022
-
[30]
Stereo sound event localization and de- tection with onscreen/offscreen classification,
K. Shimada, A. Politis, I. R. Roman, P. Sudarsanam, D. Diaz- Guerra, R. Pandey, K. Uchida, Y . Koyama, N. Takahashi, T. Shibuyaet al., “Stereo sound event localization and de- tection with onscreen/offscreen classification,”arXiv preprint arXiv:2507.12042, 2025
arXiv 2025
-
[31]
Soundreactor: Frame-level online video-to-audio generation,
K. Saito, J. Tanke, C. Simon, M. Ishii, K. Shimada, Z. No- vack, Z. Zhong, A. Hayakawa, T. Shibuya, and Y . Mitsufuji, “Soundreactor: Frame-level online video-to-audio generation,” arXiv preprint arXiv:2510.02110, 2025
arXiv 2025
-
[32]
Learning robust spatial representations from binaural audio through feature distillation,
H. S. Bovbjerg, J. Østergaard, J. Jensen, S. Watanabe, and Z.-H. Tan, “Learning robust spatial representations from binaural audio through feature distillation,” in2025 IEEE Workshop on Appli- cations of Signal Processing to Audio and Acoustics (WASPAA). IEEE, 2025, pp. 1–5
2025
-
[33]
Esc: Dataset for environmental sound classifica- tion,
K. J. Piczak, “Esc: Dataset for environmental sound classifica- tion,” inProceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 1015–1018
2015
-
[34]
Musan: A music, speech, and noise corpus,
D. Snyder, G. Chen, and D. Povey, “Musan: A music, speech, and noise corpus,”arXiv preprint arXiv:1510.08484, 2015
Pith/arXiv arXiv 2015
-
[35]
A dataset and taxonomy for urban sound research,
J. Salamon, C. Jacoby, and J. P. Bello, “A dataset and taxonomy for urban sound research,” inProceedings of the 22nd ACM inter- national conference on Multimedia, 2014, pp. 1041–1044
2014
-
[36]
Audiblelight (rc): A controllable, end-to-end api for soundscape synthesis across ray-traced & real- world measured acoustics,
H. Cheston, A. Stepien, J. Azcarreta, A. S. Roman, C. Chen, C. Bilen, and I. R. Roman, “Audiblelight (rc): A controllable, end-to-end api for soundscape synthesis across ray-traced & real- world measured acoustics,” inProceedings of the DMRN+20: Digital Music Research Network Workshop 2025, dMRN+20
2025
-
[37]
Gibson env: Real-world perception for embodied agents,
F. Xia, A. R. Zamir, Z. He, A. Sax, J. Malik, and S. Savarese, “Gibson env: Real-world perception for embodied agents,” in Proceedings of the IEEE conference on computer vision and pat- tern recognition, 2018, pp. 9068–9079
2018
-
[38]
Pyroomacoustics: A python package for audio room simulation and array processing algorithms,
R. Scheibler, E. Bezzam, and I. Dokmani ´c, “Pyroomacoustics: A python package for audio room simulation and array processing algorithms,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.